




Choosing the Right Embedding Model for Your Data
What are Embedding Models?
Embedding models are machine learning models that transform unstructured data (text, images, audio, etc.) into fixed-size vectors, also known as vector embeddings (sparse, dense, binary embedding, etc.). These vectors capture the semantic meaning of the unstructured data, making it easier to perform various tasks like similarity search, natural language processing (NLP), computer vision, clustering, classification, and more.
There are various types of embedding models, including word embeddings, sentence embeddings, image embeddings, multimodal embeddings, and many more.
Word Embeddings: Represent words as dense vectors. Examples include Word2Vec, GloVe, and FastText.
Sentence Embeddings: Represent entire sentences or paragraphs. Examples include Universal Sentence Encoder (USE) and Sentence-BERT.
Image Embeddings: Represent images as vectors. Examples include models like ResNet and CLIP.
Multimodal Embeddings: Combine different data types (e.g., text and images) into a single embedding space. CLIP by OpenAI is a notable example.
Embedding Models and Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is a pattern in Generative AI in which you can use your data to augment the knowledge of the LLM generator model (such as ChatGPT). This approach is a perfect solution for addressing the annoying hallucination issues of LLMs. It can also help you leverage your domain-specific or private data to build GenAI applications without worrying about data security issues.
RAG consists of two different models, the embedding models and the large language models (LLMs), which are both used in inference mode. This blog introduces how to choose the best embedding model and where to find it based on the type of data and possibly the language or specialty domain, such as Law.
How to Choose the Best Embedding Model for Your Data
Choosing the right embedding model for your data requires understanding your specific use case, the type of data you have, and the performance requirements of your application.
Text Data: MTEB Leaderboard
The HuggingFace MTEB leaderboard is a one-stop shop for finding text embedding models! For each embedding model, you can see its average performance overall tasks.
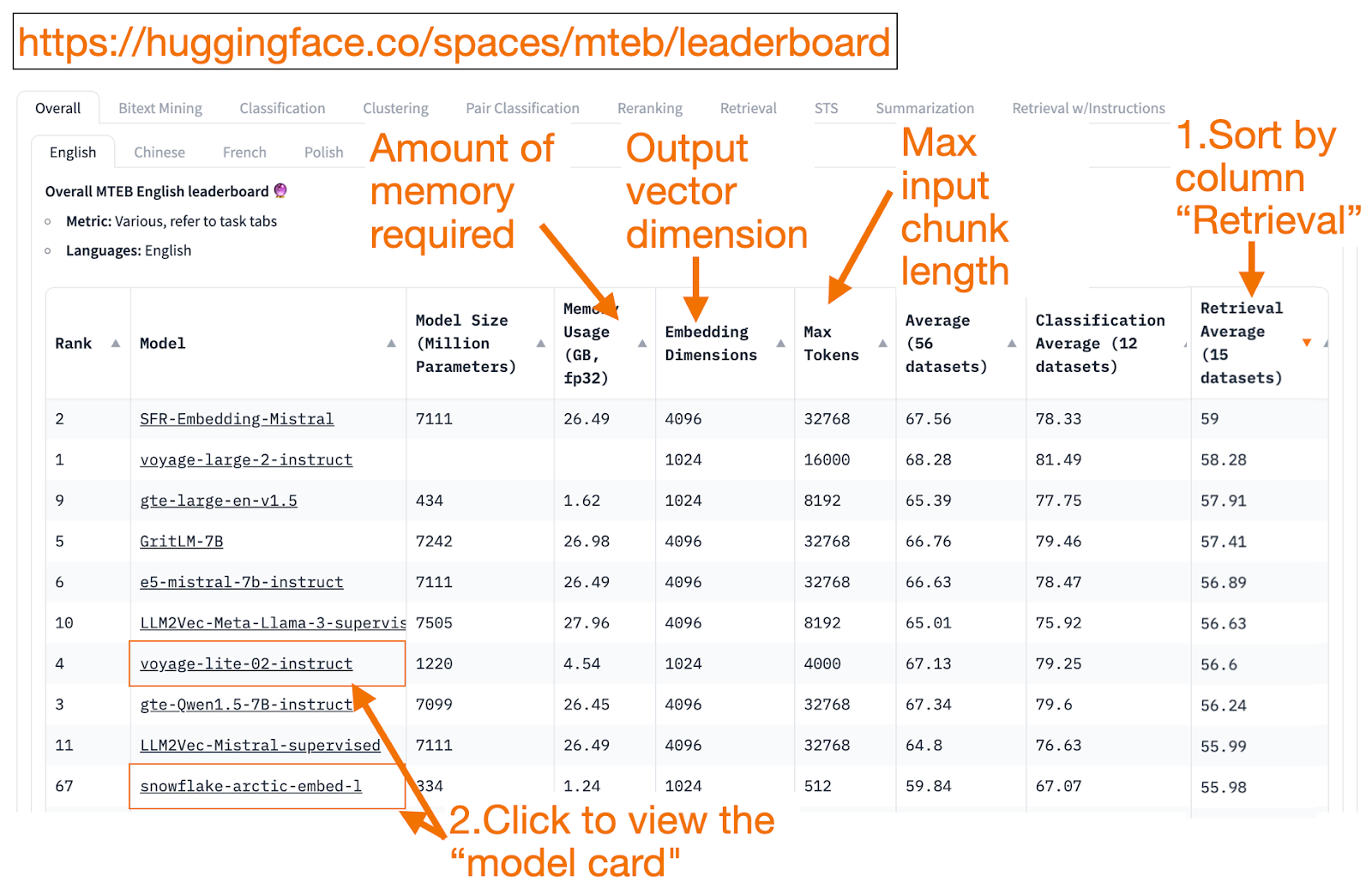
A good way to get started is to sort descending by the “Retrieval Average” column since that is the task most related to Vector Search. Then, look for the top-rated smallest (GB Memory) model.
Embedding dimension is the length of the vector, i.e., the y-part in f(x)=y, the model will output.
Max tokens are the length of the input text chunk, i.e., the x-part in f(x)=y, which you can input into the model.
In addition to the Retrieval task, you can also filter by:
Language: French, English, Chinese, or Polish. For example, task=retrieval and Language=chinese.
Legal. For example, task=retrieval and Language=law, for models fine-tuned on legal texts.
Unfortunately, because the training data has only recently become publicly available, some MTEB entries are overfitted models, ranking deceptively higher than they will realistically perform on your data. This blog from HuggingFace has tips on deciding if you trust a model ranking. Click the model link (called the “model card”).
Look for blogs and papers that explain how the model was trained and evaluated. Look carefully at the languages, data, and tasks the model was trained on. Also, look for models created by reputable companies. For example, on the voyage-lite-02-instruct model card, you will notice other production VoyageAI models listed, but not this one. That is a hint! That model is a vanity overfit model. Do not use it!
In the screenshot below, I would try out the new entry from Snowflake, “snowflake-arctic-embed-1” because it is high ranking, small enough to run on my laptop, and the model card has links to a blog and paper.
 Sceenshot of Snowflake on MTEB Leaderboard
Sceenshot of Snowflake on MTEB Leaderboard
Once you select your embedding model, the nice thing about using HuggingFace models is that you can change your model by changing **model_name** in the code!
import torch
from sentence_transformers import SentenceTransformer
# Initialize torch settings
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# Load the model from huggingface.
model_name = "WhereIsAI/UAE-Large-V1" # Just change model_name to use a different model!
encoder = SentenceTransformer(model_name, device=DEVICE)
# Get the model parameters and save for later.
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Print model parameters.
print(f"model_name: {model_name}")
print(f"EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f"MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH_IN_TOKENS}")

Image Data: ResNet50
Sometimes you want to search for similar images to an input image. Maybe you're looking for more images of Scottish Fold cats? In this case, you would upload your favorite image of a Scottish Fold cat and ask the search engine to find similar images!
ResNet50 is a popular Convolutional Neural Network (CNN) model originally trained in 2015 by Microsoft on ImageNet data.
Similarly, for reverse video search, ResNet50 can still embed videos. Then, a reverse image similarity search is done on the video stills database. The closest video (excluding the input) is returned to the user as the most similar video.
Sound Data: PANNs
Similar to how you might want to reverse image search using an input image, you could also reverse audio clip search based on an input sound bite.
PANNs (Pretrained Audio Neural Networks) are popular embedding models for this task because they are pre-trained on large-scale audio datasets and are good at tasks like audio classification and tagging.
Multimodal Image and Text Data: SigLIP or Unum
In the last few years, embedding models have emerged that are trained on a mix of Unstructured Data: Text, Image, Audio, or Video. Such embedding models capture the semantics of multiple types of Unstructured Data at once in the same vector space.
Multimodal embedding models make it possible to use text to search for images, generate text descriptions of images, or reverse image search from an input image.
CLIP (Contrastive Language-Image Pretraining) from OpenAI in 2021 used to be the standard embedding model. However, practitioners found it hard to use because it needed to be fine-tuned. In 2024, SigLIP, or sigmoidal-CLIP from Google, appears to be an improved CLIP, with reports of good results using zero-shot prompts.
Small model variants of LLMs are becoming popular. Instead of requiring a large cloud computing cluster, they can run on laptops (like my M2 Apple with only 16GB RAM). Small models use less memory, which means they have lower latency and can potentially run faster than large models. Unum offers multimodal small embedding models.
Multimodal Text and/or Sound and/or Video Data
Most Multimodal Text-to-Sound RAG systems use a multimodal generative LLM to convert sound to text first. Once the sound-text pairs are created, the text is embedded into vectors, and you can use your RAG to retrieve text the usual way. For the last step, text is mapped back to sound to finish the loop Text-to-Sound or vice-versa.
Whisper from OpenAI can transcribe speech into text.
Text-to-speech (TTS) from OpenAI can also convert text into spoken audio.
Multimodal Text-to-Video RAG systems use a similar approach to map videos to text first, embed the text, search the text, and return videos as search results.
Sora from OpenAI can convert text to video. Similar to Dall-e, you provide the text prompt, and the LLM generates a video. Sora can also generate videos from still images or other videos.
Summary
This blog touched on some popular embedding models used in RAG applications.
Further Resources
References
MTEB leaderboard, paper, Github: https://huggingface.co/spaces/mteb/leaderboard
MTEB best practices to avoid choosing an overfit model: https://huggingface.co/blog/lyon-nlp-group/mteb-leaderboard-best-practices
Similar-image search: https://milvus.io/docs/image_similarity_search.md
Image-to-video search: https://milvus.io/docs/video_similarity_search.md
Similar-sound search: https://milvus.io/docs/audio_similarity_search.md
Text-to-image search: https://milvus.io/docs/text_image_search.md
2024 SigLIP (sigmoid loss CLIP) paper: https://arxiv.org/pdf/2401.06167v1
Pocket-size Multimodal embedding models from Unum: https://github.com/unum-cloud/uform

Keep Reading

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.