




Improving Information Retrieval and RAG with Hypothetical Document Embeddings (HyDE)
HyDE (Hypothetical Document Embeddings) is a retrieval method that uses "fake" documents to improve the answers of LLM and RAG.
Read the entire series
- Mastering LLM Challenges: An Exploration of Retrieval Augmented Generation
- Key NLP technologies in Deep Learning
- Exploring the Frontier of Multimodal Retrieval-Augmented Generation (RAG)
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- How to Enhance the Performance of Your RAG Pipeline
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- Pandas DataFrame: Chunking and Vectorizing with Milvus
- How to build a Retrieval-Augmented Generation (RAG) system using Llama3, Ollama, DSPy, and Milvus
- Improving Information Retrieval and RAG with Hypothetical Document Embeddings (HyDE)
- Building RAG with Milvus Lite, Llama3, and LlamaIndex
- Enhancing RAG with RA-DIT: A Fine-Tuning Approach to Minimize LLM Hallucinations
- Top 10 RAG & LLM Evaluation Tools You Don't Want To Miss
In recent years, dense retrievers powered by neural networks have emerged as a modern alternative to traditional sparse methods based on term frequency in information retrieval. These models have obtained state-of-the-art results on datasets and tasks where large training sets are available. However, extensive labeled datasets are not always available or suitable due to restrictions on use. Moreover, these datasets often do not encompass the full spectrum of real-world search scenarios, limiting their effectiveness.
Zero-shot methods, therefore, aim to transcend these limitations by enabling retrieval systems that can generalize across tasks and domains without relying on explicit relevance supervision. Performing document retrieval without prior training on task-specific data can minimize the training overhead and lower the cost of dataset creation.
This blog will cover the details of a zero-shot retrieval method, Hypothetical Document Embeddings (HyDE), which outperforms unsupervised and fine-tuned dense retrievers. Later, the blog will also implement the HyDE method using OpenAI and the Milvus vector database.
What are Hypothetical Document Embeddings (HyDE)?
HyDE, or Hypothetical Document Embeddings, is a retrieval method that uses "fake" (hypothetical) documents to improve the answers generated by large language models (LLMs).
Specifically, HyDE uses an LLM (GPT-3.5 was used in the original implementation) to create a hypothetical answer to a query. This answer is turned into a vector embedding and placed in the same space as real documents. When you search for something, the system finds real documents that best match this hypothetical answer, even if they don't match the exact words in your search. HyDE aims to capture the intent behind your query, ensuring that the retrieved documents are contextually relevant.
The HyDE retrieval offers several benefits:
Zero-Shot Retrieval: It effectively retrieves relevant documents without needing relevant labels or prior training on specific datasets.
Generative Approach: Generating hypothetical documents captures relevance patterns even if the details are inaccurate.
Versatility: It performs well across various tasks, such as web search, question answering, and fact verification, and supports multiple languages.
The upcoming section will detail the in-depth workings of HyDE.
How the HyDE Approach Works
Before jumping to the working of HyDE, let’s see what problem it solves:
Problem: In traditional dense retrieval methods, we typically encode queries and documents into single-vector representations—embeddings. Then, we conduct data retrieval by searching for the approximate nearest neighbors (ANN) in this high-dimensional vector space.
Dense retrieval models, generally based on neural networks like transformer-based encoders, aim to produce fixed-dimensional vectors for semantically related entities, such as queries and documents. Using architectures like siamese networks, these models are trained to minimize distances between similar pairs (positives) and maximize distances between dissimilar pairs (negatives), often employing triplet loss. Here’s the triplet loss:
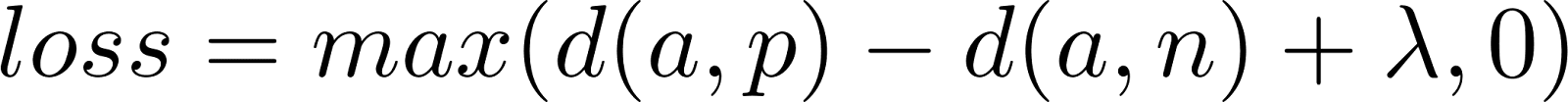 The triplet loss formula.png
The triplet loss formula.png
The triplet loss formula
Where a is an anchor, p is a positive, n is a negative, d is a distance function, and λ is a margin value to ensure sufficient distance between negative examples.
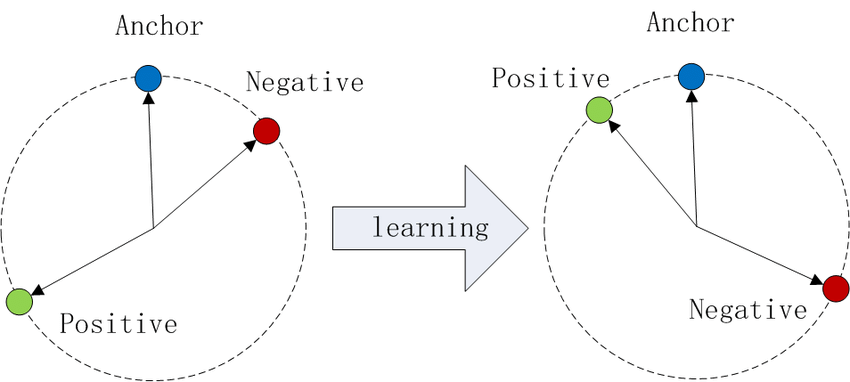 Fig 1- Illustration of Triplet Loss in Cosine Similarity.png
Fig 1- Illustration of Triplet Loss in Cosine Similarity.png
Fig 1: Illustration of Triplet Loss in Cosine Similarity
The main challenge of these dense retrieval systems is the requirement of extensive labeled datasets, often in pairs of query and document (q,d),which is labor and cost-intensive. Another challenge is that single-vector representations cannot capture different aspects of the queries and documents in relevance matching.
Solution: The HyDE solution combines the strengths of generative large language models (LLMs) and contrastive encoders. At the core of HyDE is generating hypothetical answers to queries using a large language model; these answers are then embedded into a vector space. This approach allows for effective retrieval of actual documents based on their similarity to the generated hypothetical documents, bypassing the need for task-specific training data. Let’s see the architecture and understand it step-by-step:
 Fig 2- Illustration of HyDE model.png
Fig 2- Illustration of HyDE model.png
Fig 2: Illustration of HyDE model
Here is the breakdown of the architecture:
- Query Input:
The process begins with feeding the query into an instruction-following large language model (LLM), such as GPT-3.5.
The model is instructed to generate a hypothetical document that answers the query.
- Generate Hypothetical Document:
The LLM produces a document as a hypothetical answer to the query.
This generated document captures the essence of relevance despite potentially containing factual errors.
- Embedding the Hypothetical Document:
The hypothetical document is encoded into a vector embedding using a contrastive encoder.
The encoder simplifies the text by removing unnecessary details and keeping the essential meaning.
- Search and Retrieval:
The vector embedding of the hypothetical document is used to search against pre-encoded real document embeddings in the corpus.
Documents are retrieved based on their similarity to the hypothetical document’s vector.
Following the process, the most similar real documents are returned as the retrieval results.
Next, let’s implement HyDE in Python.
Step-by-Step Guide for Implementing HyDE in Python with Milvus
I break down this guide into the following steps:
1. Setup and Imports
First, we import the necessary libraries and set up our environment. The code uses the OpenAI library to access the GPT-3.5 API, which serves as our LLM, and pymilvus to interact with the Milvus vector database for document storage and similarity search. Additionally, we import standard libraries such as json and numpy.
from openai import OpenAI
from pymilvus import MilvusClient
import json
import numpy as np
2. Setting Up Milvus
Milvus is a vector database optimized for billion-scale vector similarity search, storing, and querying high-dimensional vectors. Here, we connect to Milvus and create a new collection named hyde_retrieval to store our document embeddings.
# Set up OpenAI GPT-3.5
openai_client = OpenAI()
# Connect to Milvus
client = MilvusClient("milvus_demo.db")
Using text-embedding-ada-002 from the OpenAI, we will set the dimensions to 1536.
# Create a Milvus collection
if client.has_collection(collection_name="hyde_retrieval"):
client.drop_collection(collection_name="hyde_retrieval")
client.create_collection(
collection_name="hyde_retrieval",
dimension=1536)
3. Data
We define a dummy corpus of documents to demonstrate the retrieval process. This corpus includes several sample texts.
# Dummy corpus of documents
corpus = [
"It usually takes between 30 minutes and two hours to remove a wisdom tooth.",
"The COVID-19 pandemic has significantly impacted mental health, increasing depression and anxiety.",
"Humans have used fire for approximately 800,000 years.",
"Milvus is a cloud based database for vector storage."
]
4. Embedding Module
This section defines a function get_embeddings to obtain vector embeddings for the corpus documents using OpenAI's embedding model (text-embedding-ada-002). These embeddings are crucial for vector-based similarity search. Note that the original HyDE implementation used the Contriever model for embeddings.
def get_embeddings(texts, model="text-embedding-ada-002"):
response = openai_client.embeddings.create(
input=texts,
model=model
)
embeddings = [data.embedding for data in response.data]
return embeddings
After defining the embedding generation module, we will encode the corpus documents and insert them into Milvus.
vectors = get_embeddings(corpus)
data = [
{"id": i, "vector": vectors[i], "text": corpus[i]}
for i in range(len(vectors))
]
client.insert(collection_name="hyde_retrieval", data=data)
5. Chat Module
We create a function generate_hypothetical_document that leverages GPT-3.5 to generate a hypothetical document based on a query. This document captures the essence of the query, providing context for similarity search.
# Function to generate a hypothetical document using GPT-3.5
def generate_hypothetical_document(query):
response = openai_client.chat.completions.create(
model="gpt-3.5-turbo-0125",
messages=[{"role": "system", "content": "Write a document that answers the question:"},
{"role": "user", "content": f"{query}"}],
max_tokens=100
)
return response.choices[0].message
6. HyDE Module
The core of our HyDE implementation involves generating a hypothetical document for a given query, embedding this document, and performing a similarity search in Milvus to retrieve the most relevant real documents from the corpus.
# Function to perform HyDE-based retrieval
def hyde_retrieve(query):
hypo_doc = generate_hypothetical_document(query)
hypo_embedding = get_embeddings(hypo_doc)
results = client.search(collection_name="hyde_retrieval",data=hypo_embedding)
return [corpus[results[0][i]['id']] for i in range(len(results[0]))]
7. Results
Finally, we test our implementation with an example query and print the retrieved documents.
# Example query
query = "What is Milvus?"
retrieved_docs = hyde_retrieve(query)
print("Retrieved Documents:", retrieved_docs)
Here are the results from the retrieval:
Retrieved Documents: ['Milvus is a cloud based database for vector storage.', 'The COVID-19 pandemic has significantly impacted mental health, increasing depression and anxiety.', 'Humans have used fire for approximately 800,000 years.', 'It usually takes between 30 minutes and two hours to remove a wisdom tooth.']
We start by setting up the environment and the Milvus vector database, defining our corpus, obtaining embeddings using OpenAI's embedding model, generating hypothetical documents with GPT-3.5, and performing similarity searches to retrieve relevant documents. This approach effectively bridges the gap between queries and document retrieval by generating contextually relevant hypothetical answers.
How HyDE Improves Retrieval Augmented Generation (RAG) Applications
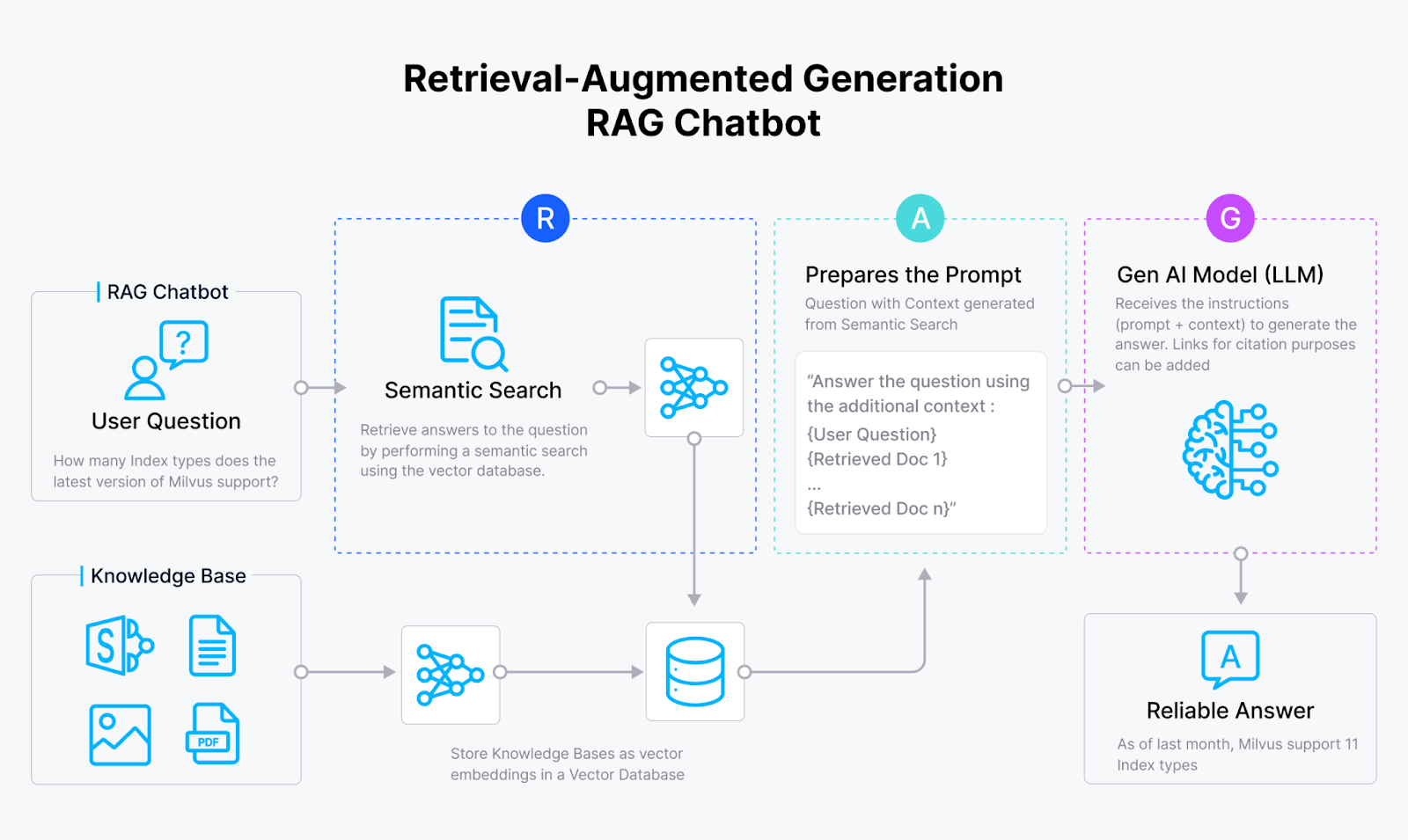
The Retrieval Augmented Generation (RAG) integrates generative LLMs with conventional information retrieval systems. This approach allows LLMs to generate contextually informed responses, explanations, or instructions in natural languages. A basic RAG (comprising a vector database like Milvus, an embedding model, and an LLM) is often easier to implement, but its performance and accuracy in real-world applications depend upon optimizing the retrieval element.
 RAG chatbot.png
RAG chatbot.png
Fig 3: A basic architecture of RAG
RAG utilizes two core components: a generator, typically an LLM, and a retriever akin to a vector database. Here’s how HyDE improves RAG pipelines:
Generating Hypothetical Documents: HyDE’s innovation lies in generating a hypothetical document based on the query and retrieving documents based on it. So, instead of directly relying on retrieved documents from the corpus, HyDE uses this generated document to capture the essence of relevance.
Answering Hard Questions: When encountering a vague or contextually ambiguous question, deriving a precise answer can be tricky. HyDE improves it by enriching the query with more context with the help of LLM.
Optimizing Document Queries: Since most databases contain answers rather than questions, it makes sense to use a hypothetical answer as the query for documents.
Experiments demonstrated the improvements in performance, robustness, and versatility:
Improved Performance: HyDE consistently outperforms classical BM25 and unsupervised Contriever across various datasets and metrics, e.g., nDCG@10, recall.
Robustness: HyDE remains competitive even against fine-tuned models on richly supervised tasks like TREC DL19/20.
Versatility: It demonstrates strong performance across both web search and low-resource tasks, providing significant gains over baseline models.
Multilingual Capabilities: It shows enhanced results in multiple languages, outperforming mContriever in languages such as Korean and Japanese.
Efficiency: HyDE enhances retrieval quality without requiring extensive fine-tuning, making it an effective and efficient choice for diverse retrieval tasks.
The HyDE for the RAG pipeline can do more harm than good if its limitations are unknown. The next section will shed light on it.
Challenges and Limitations of HyDE
Hypothetical document retrieval comes with some challenges and limitations. Here are a few of them:
Knowledge Bottleneck: HyDE-generated documents may contain factual errors and are not real, which could affect the accuracy of retrieval results. For example, this approach may be ineffective if the topic is completely new to the language model. It could result in more frequent instances of generating incorrect information.
Multilingual Challenge: Multilingual retrieval poses several additional challenges to HyDE. The small-sized contrastive encoder gets saturated as the number of languages scales. Meanwhile, generative LLM faces an opposite issue: with languages not as high-resource as English or French, the high-capacity LLM can get under-trained.
Researchers are actively addressing these challenges, tackling ambiguous queries, improving task-specific instructions, and exploring the integration of HyDE with fine-tuned encoders to achieve better performance. Other research on zero-shot involves search agents and hybrid environments, focusing on agent-based query refinement and integrating hybrid retrieval systems.
Conclusion
To wrap up, let's recap the key points discussed:
HyDE enables zero-shot retrieval by generating hypothetical documents.
HyDE combines generative LLMs and contrastive encoders for effective retrieval.
HyDE outperforms traditional and some fine-tuned models across various tasks.
HyDE improves RAG pipelines by optimizing document queries and handling vague questions.
HyDE significance is also important for natural language processing (NLP) as it finds relevant documents without prior training or labels. It uses hypothetical documents to capture relevance and excels in tasks like web search and question answering across multiple languages. This article also presents a simple step-by-step implementation of HyDE in Python using OpenAI and Milvus.
To learn more details about HyDE, read this academic paper.
Additional Resources
Here are some further exploration resources to feed the brain:
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- What are Hypothetical Document Embeddings (HyDE)?
- How the HyDE Approach Works
- Step-by-Step Guide for Implementing HyDE in Python with Milvus
- How HyDE Improves Retrieval Augmented Generation (RAG) Applications
- Challenges and Limitations of HyDE
- Conclusion
- Additional Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Mastering LLM Challenges: An Exploration of Retrieval Augmented Generation
This RAG handbook explores its advantages, the challenges it can address, & why its the preferred choice for elevating the performance of gen AI apps.

Key NLP technologies in Deep Learning
An exploration of the evolution and fundamental principles underlying key Natural Language Processing (NLP) technologies within Deep Learning.

Pandas DataFrame: Chunking and Vectorizing with Milvus
If we store all of the data, including the chunk text and the embedding, inside of Pandas DataFrame, we can easily integrate and import them into the Milvus vector database.