




The Path to Production: LLM Application Evaluations and Observability
As many machine learning teams prepare to deploy large language models (LLMs)) in production, they face significant challenges, such as addressing hallucinations and ensuring responsible deployment. Before tackling these issues, it's crucial to effectively evaluate and identify them.
Recently, at the Unstructured Data Meetup, Hakan Tekgul, the ML Solutions Architect at Arize AI, shared insightful strategies for conducting quick and accurate LLM evaluations. These approaches maintain high answer quality and reliability standards and ensure the delivery of tangible business value.
Watch the replay of Hakan Tekgul’s talk
If you missed the event, don’t worry! Here's a detailed breakdown of Hakan’s presentation.
Transitioning GenAI Demos to Production is Challenging!
Building GenAI applications might seem simple initially, especially with user-friendly tools like LangChain and LlamaIndex that facilitate the creation of demo applications. However, transitioning to fully-fledged products capable of driving tangible business value is challenging. The crux lies in guaranteeing these applications consistently deliver reliable, high-quality outputs in a production environment.
 What is it like to transition from a Twitter demo to a real-world product
What is it like to transition from a Twitter demo to a real-world product
Let's illustrate this challenge with an e-commerce chatbot example. Users interact with this chatbot to plan their vacations.
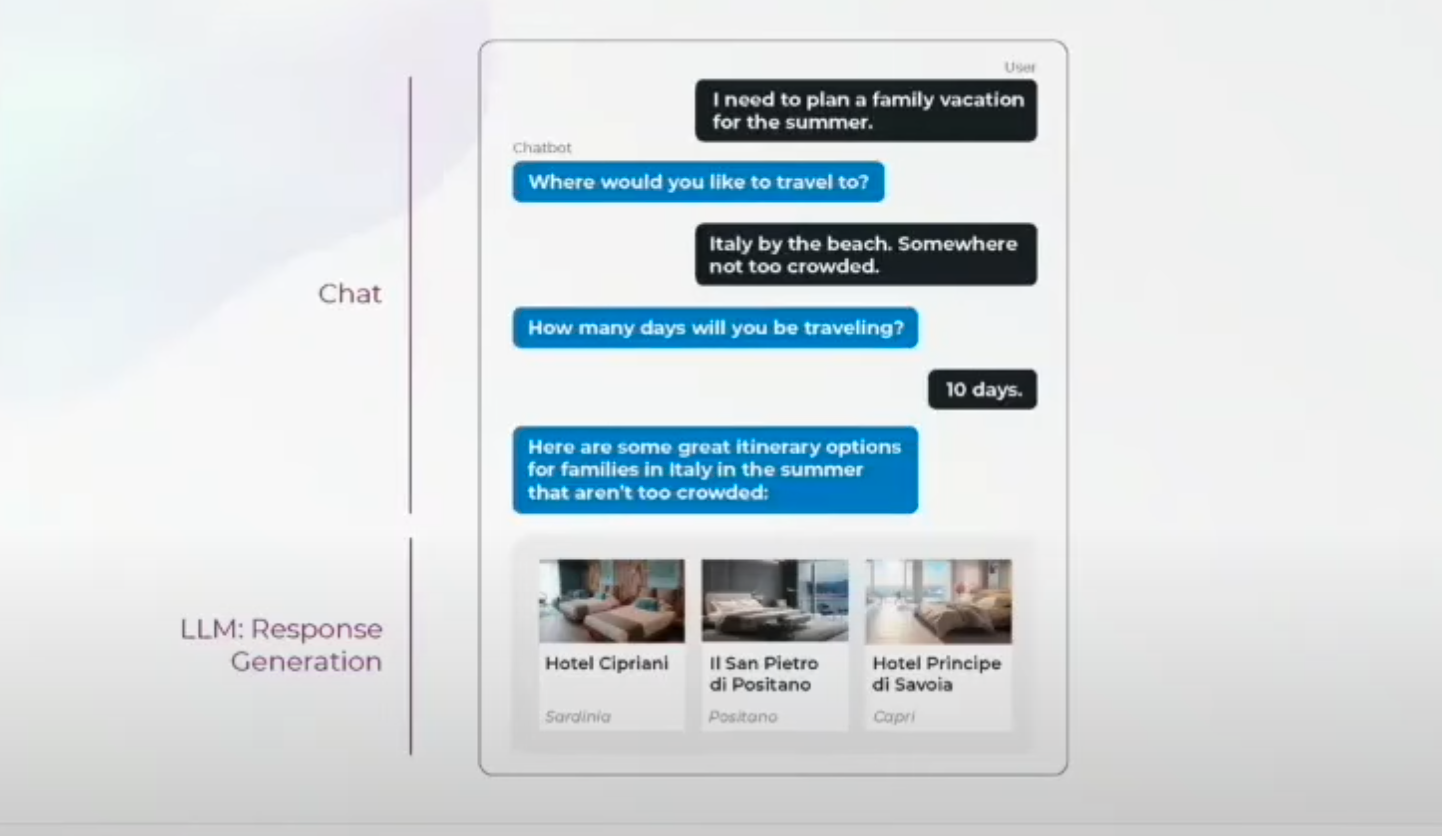 The interface of the e-commerce chatbot
The interface of the e-commerce chatbot
While the application may appear simple from the user's perspective, the workflows behind the scenes are complex. Here are the key steps in this workflow:
Chat Initiation: Users initiate the session by interacting with the chatbot.
Parameter Extraction: The LLM extracts structured parameters from the user's input.
Ranking/Recommendation: The model generates a list of potential vacation destinations based on the extracted parameters.
Embedding Search and Retrieval: The system refines the list by performing a vector search for more relevant information.
Response Generation: The LLM generates a personalized response based on the retrieved data.
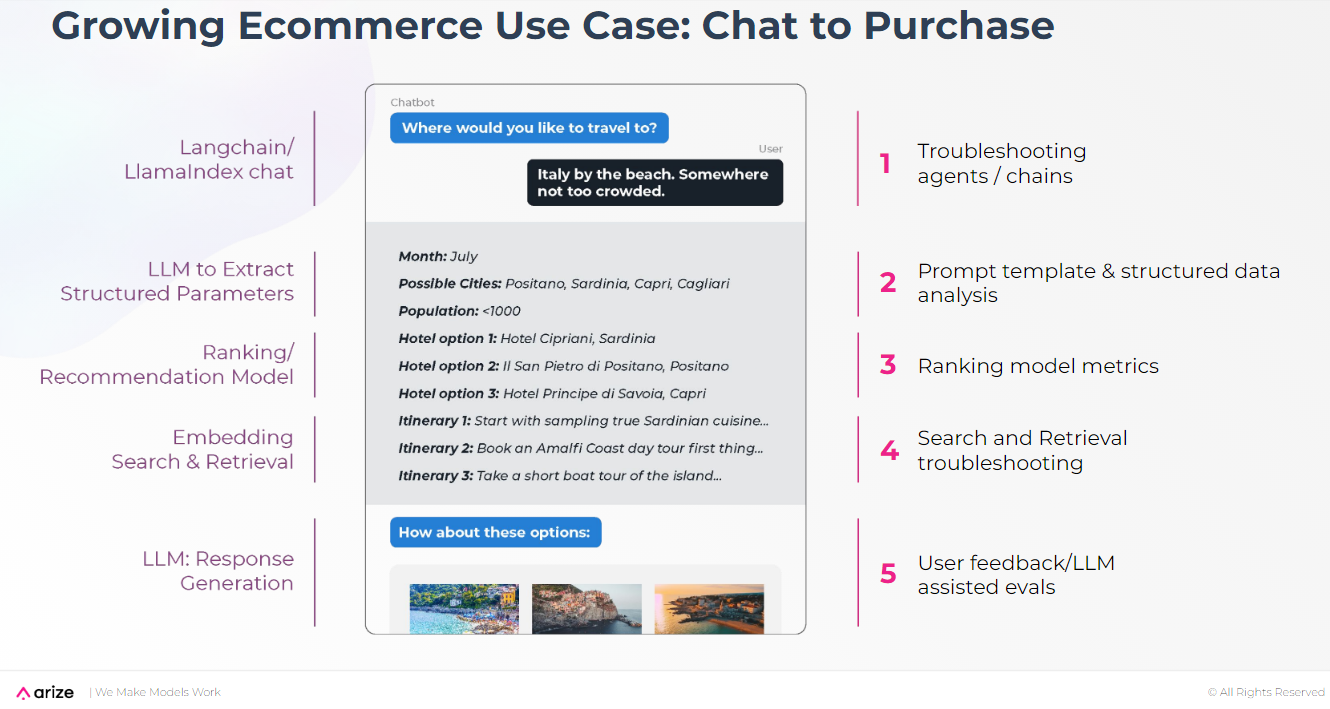 The key steps in the chatbot workflow and potential troubleshooting strategies
The key steps in the chatbot workflow and potential troubleshooting strategies
Each step in this workflow can encounter specific issues. Effective troubleshooting is essential to ensure a seamless user experience and optimal performance. For example, you may need to:
Ensure smooth operation of tools like LangChain and LlamaIndex without errors.
Craft and refine prompts to accurately extract data from users’ input.
Continuously evaluate and optimize the recommendation system.
Enhance the accuracy and relevance of retrieved information.
Troubleshoot the entire system and each component individually.
Utilize feedback to continuously refine and enhance the system.
LLM Observability Comes to the Rescue!
To tackle the challenges outlined earlier, it's crucial to leverage evaluation tools for seamless LLM observability. Five primary facets of LLM observability demand attention to guarantee full visibility of your applications. By adeptly conducting these evaluations, teams can achieve holistic observation of their applications, ensuring reliability and optimal performance.
| Five Pillars of LLM Observability | ||
| Pillar | Description | Common Issues |
| Evaluation | Systematic assessment of LLM outputs using a separate evaluation LLM | Output quality and alignment |
| Spans and Traces | Detailed visibility into workflow breakdowns | Identifying specific failure points |
| Prompt Engineering | Iterative refinement of prompt templates for improved results | Improving response accuracy and relevance |
| Search and Retrieval | Locate and improve retrieved-context | Enhancing retrieval accuracy |
| Fine-tuning | Re-training LLMs on specific data for tailored performance | Aligning with business-specific needs |
In the following sections, we'll explore the LLM Evaluation and the LLM Spans and Traces categories in more detail to highlight their significance in optimizing LLM observability.
LLM Evaluations
LLM Evaluations (LLM Evals) refer to the systematic assessment of your GenAI application’s outputs using a separate LLM as the "judge." Regular evaluations guarantee that the generated content meets quality standards and fulfills user expectations. For instance, a vacation suggestion service employs an evaluation LLM to routinely review recommendations. This evaluation system triggers a review process to update the training data if recommendations become outdated or irrelevant.
Model Evals vs. LLM Evals
Before delving into details, let's compare two similar concepts: model evals and LLM evals.
Model Evals help you select the foundational model for your application and ensure it aligns with the general use cases.
LLM Evals gauge the performance of specific tasks and components within your LLM-based application. LLM evals include retrieval, hallucination, user frustration, Q&A, summarization, and code generation evaluation, as illustrated in the image below.
 Production LLM Evals- Task Performance Measurement | Arize
Production LLM Evals- Task Performance Measurement | Arize
How LLM Evals Work
Assessing the performance of large language models (LLMs) using a judge LLM might seem complex, but it becomes much more manageable with the right tools and methodologies. The Phoenix LLM Evals library is an open-source tool designed to facilitate rapid and straightforward LLM evaluations. This library integrates a judge LLM, evaluation templates, and model parameters into a cohesive framework.
How does this process work? Your input data is fed into the Phoenix library along with the output data generated by your LLM application. The Judge LLM within the library then uses this input and output data, along with a prompt template, to evaluate your system's performance on a specific task.
 LLM Evals- How They Work in General
LLM Evals- How They Work in General
Let's look into the evaluation process. Consider a Retrieval Augmented Generation (RAG) application that retrieves context from a vector database like Milvus and then generates responses based on the user's question and the retrieved context.
When measuring performance in a RAG retrieval task, the input data (user's question) and the output data (reference text) are fed into the Phoenix Library. The Judge LLM uses the Eval Template to assess how well the reference text answers the user's question. For instance, if the user's question is "Find traditional French recipes," and the reference text provides a caramelized onion bread soup recipe, the Eval Template will compare these two to evaluate their relevance.
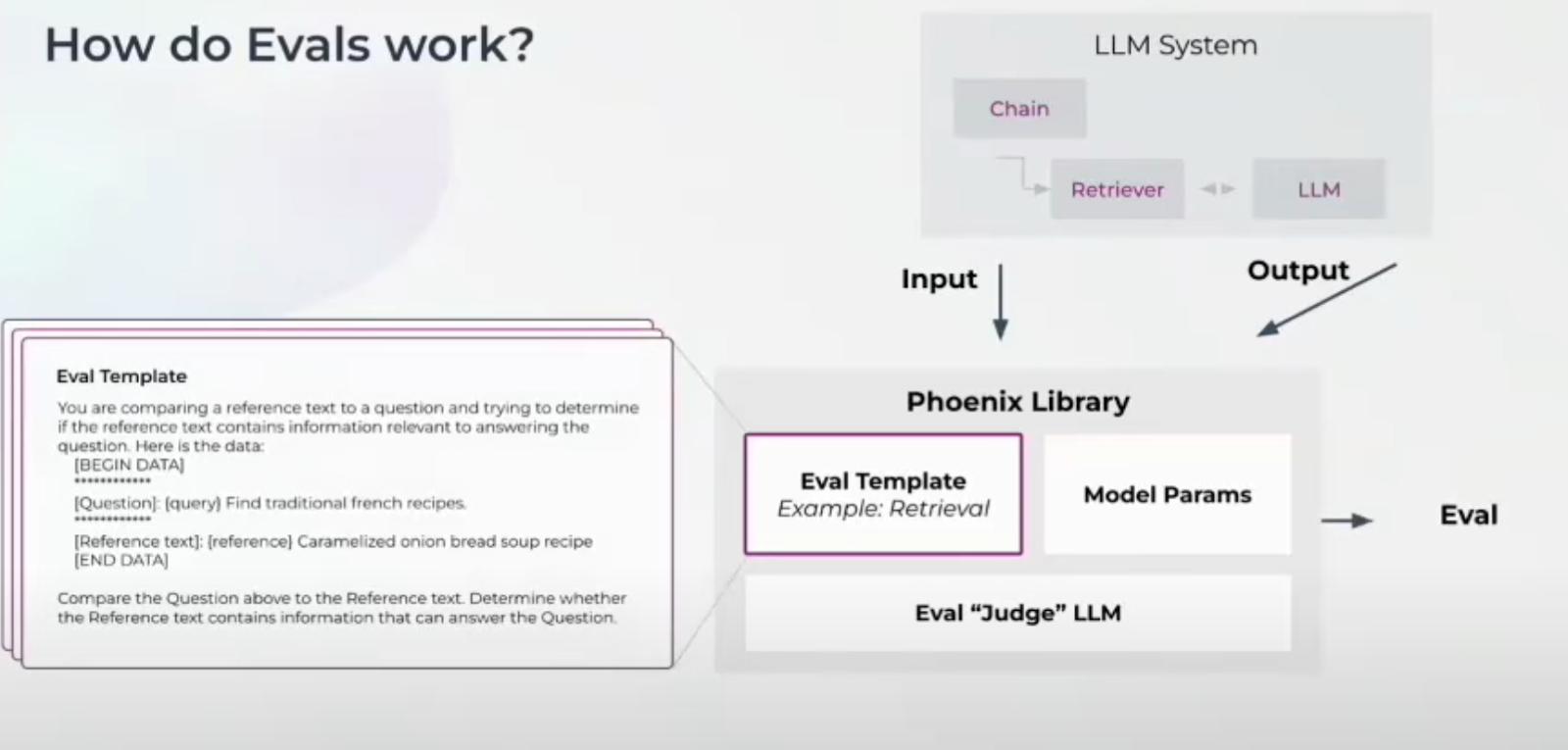 LLM Evals- How They Work in a RAG Use Case
LLM Evals- How They Work in a RAG Use Case
Benchmarking Your LLM Eval Results
We've discussed how the LLM evaluation process works, but how can you be sure it will be effective for your specific use case? The answer lies in benchmarking your evaluation results.
Below are the major steps we take to benchmark the results.
First, we utilize public datasets that include human-labeled answers. These datasets consist of user questions and reference texts, with annotations indicating their relevance. With these well-established datasets, we establish a solid foundation for comparison.
Next, we compare the performance of our prompt templates against the human-provided answers in these public datasets. This step allows us to assess how well our templates identify relevant responses, using human judgment as the benchmark.
Finally, we calculate precision and recall scores to quantify the performance of our prompt templates. Precision measures the accuracy of the relevant results returned by the RAG system, while recall measures the system's ability to retrieve all relevant instances.
These precision and recall scores indicate how effectively our prompt templates perform across a wide range of human-labeled examples. This benchmarking process ensures that the evaluation and the prompt templates are reliable and can be trusted to assess your LLM applications' performance.
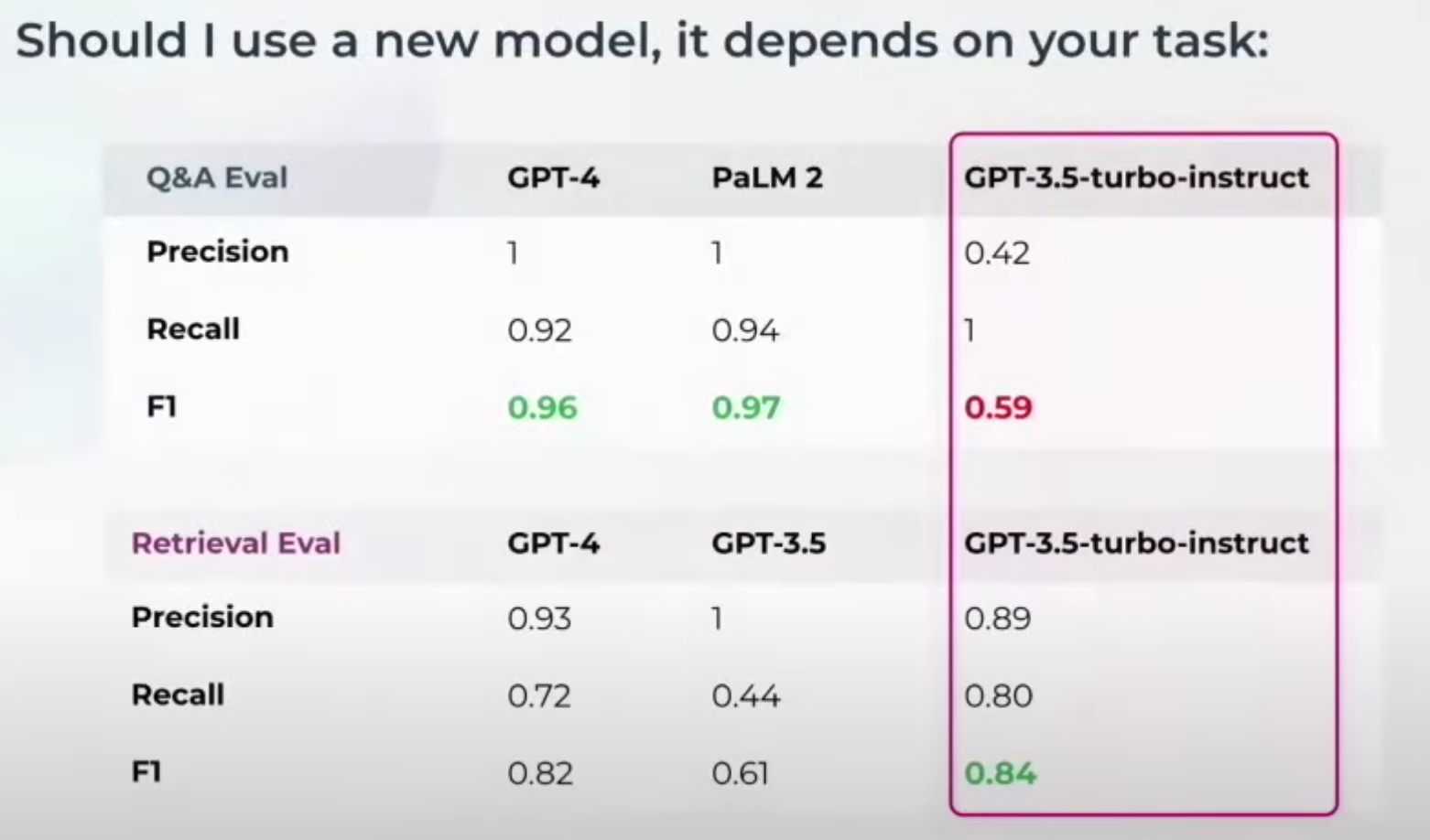
After these measurements, determine which model to use for your Judge LLM. Different tasks might require different judge models. For example, GPT-3.5-turbo-instruct might not perform well on a Q&A correctness eval but does great on the retrieval eval. You might need to switch foundation models if you're evaluating something else. This is why benchmarking is crucial.
After these measurements, the next step is determining which model to use for your Judge LLM. Different tasks might require different judge models. For example, GPT-3.5-turbo-instruct might not perform well on a Q&A correctness evaluation but excels in retrieval evaluations. You might need to switch foundational models to evaluate a different aspect. This flexibility is why benchmarking is crucial.
LLM Spans and Traces
Now we’ve learned how to evaluate your LLM applications as a whole. But how do you evaluate your application interaction component by component? Consider a full chain of retrieval systems built on frameworks like LamaIndex or LangChain. If a Q&A evaluation indicates a wrong answer, you just know the interaction failed, but you still need to determine where. This is where the concept of LLM Spans and Traces comes in.
Various types of Span evaluations can help pinpoint the failure. For example, you can use:
User frustration eval to check the chatbot interaction
Classification eval during attribute extraction
Retrieval eval to assess the retrieval component
Classification eval for the classification process
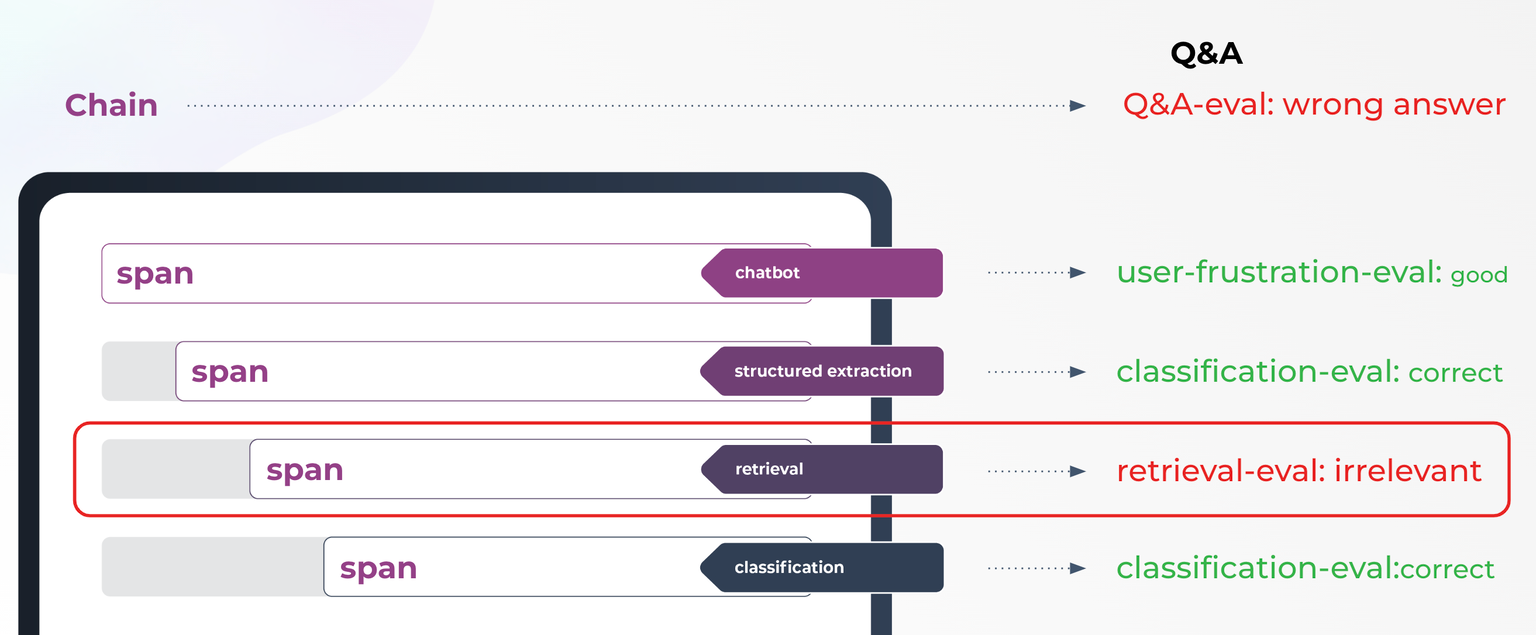 Evals on LLM Spans
Evals on LLM Spans
If there's an issue with the retrieval evaluation, it directly impacts the Q&A correctness. LLM Spans and Traces help visualize and diagnose these issues within your application.
Hakan also shared a demo showcasing how LLM Spans and Traces works. Watch the replay of his talk on YouTube to see more demo details.
Conclusion
Reflecting on Hakan Tekgul's talk, it's clear that deploying LLMs into production is no small feat. The journey from a polished demo to a reliable, business-ready application is fraught with challenges that require attention to detail and a robust observability framework.
Hakan shared two primary LLM evaluation strategies, the LLM Evaluation and the LLM Spans and Traces, and explained how they work with detailed examples. These strategies systematically evaluate LLM applications, ensuring their reliability and effectiveness in real-world use cases.

Keep Reading

Milvus 2.6.x Now Generally Available on Zilliz Cloud, Making Vector Search Faster, Smarter, and More Cost-Efficient for Production AI
Milvus 2.6.x is now GA on Zilliz Cloud, delivering faster vector search, smarter hybrid queries, and lower costs for production RAG and AI applications.

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.

Democratizing AI: Making Vector Search Powerful and Affordable
Zilliz democratizes AI vector search with Milvus 2.6 and Zilliz Cloud for powerful, affordable scalability, cutting costs in infrastructure, operations, and development.