




RAG Evaluation Using Ragas
This post is written by Christy Bergman, Shahul Es, and Jithin James.
Retrieval is a crucial component of Generative AI systems, and its challenges are particularly evident in Retrieval Augmented Generation (RAG). Retrieval Augmented Generation enhances AI-powered chatbots by generating responses based on extensive data that large language models (LLM) have been trained on. Despite the sophistication of RAG systems, retrieval accuracy remains a significant hurdle, as highlighted by low scores from benchmarks like WikiEval. To overcome these challenges, it's essential to establish a comprehensive evaluation framework and engage in thorough experimentation to fine-tune RAG parameters and achieve optimal performance.
However, before you can do RAG experimentation, you need a way to evaluate which experiments had the best results!
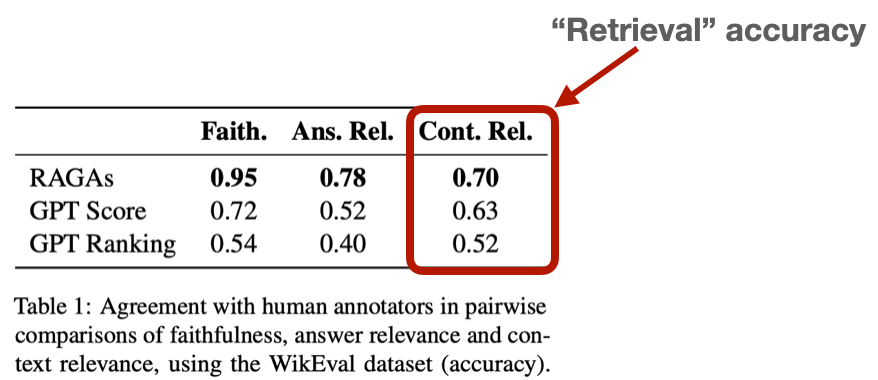
Image source: https://arxiv.org/abs/2309.15217
What is Ragas?
Ragas is a specialized evaluation framework designed to assess the performance of Retrieval Augmented Generation (RAG) systems. It provides a structured approach to evaluate the effectiveness of RAG implementations by leveraging advanced Large Language Models (LLMs) as judges. Ragas focuses on automating the evaluation process, offering scalable and cost-effective solutions for assessing AI-generated responses. The framework aims to address biases and offer continuous, explainable scores for natural language outputs. Ragas simplifies the evaluation of complex RAG systems by providing intuitive metrics and streamlining the process of assessing retrieval quality.
Importance of Evaluating RAG Systems
Evaluating RAG systems effectively is vital for refining AI responses. A robust evaluation framework ensures that experiments produce reliable outcomes and that the AI delivers accurate and contextually appropriate answers. Automating the evaluation process can streamline and accelerate this task, making it more cost-effective and scalable.
Leveraging LLMs as Judges
Using Large Language Models (LLMs) such as GPT-4 for evaluation has gained traction due to their ability to assess various aspects of retrieval quality, including relevance and precision. Although it might seem unusual to have one LLM evaluate another, research indicates that GPT-4 aligns with human evaluations about 80% of the time, which matches the "Bayesian limit" of human agreement. This method automates the evaluation process, offering scalability and reducing costs compared to manual human labeling.
Approaches to LLM-Based Evaluation
There are two primary approaches to using LLMs as judges for RAG evaluation:
MT-Bench uses an LLM to judge only question-answer pairs that are verified as human ground truth. Humans initially vet the questions and answers to ensure the questions are sufficiently complex to make worthy tests before the LLM uses the 80 Q-A pairs to evaluate different Decoders (generative AI components). Paper, Code, Leaderboard.
Ragas is built on the idea that LLMs can effectively evaluate natural language output by forming paradigms that overcome the biases of using LLM as judges directly and providing continuous scores that are explainable and intuitive to understand). Paper, Code, Docs.
The rest of this blog will showcase Ragas, which emphasizes automation and scalability for RAG evaluations.
Evaluation Data Needed for Ragas
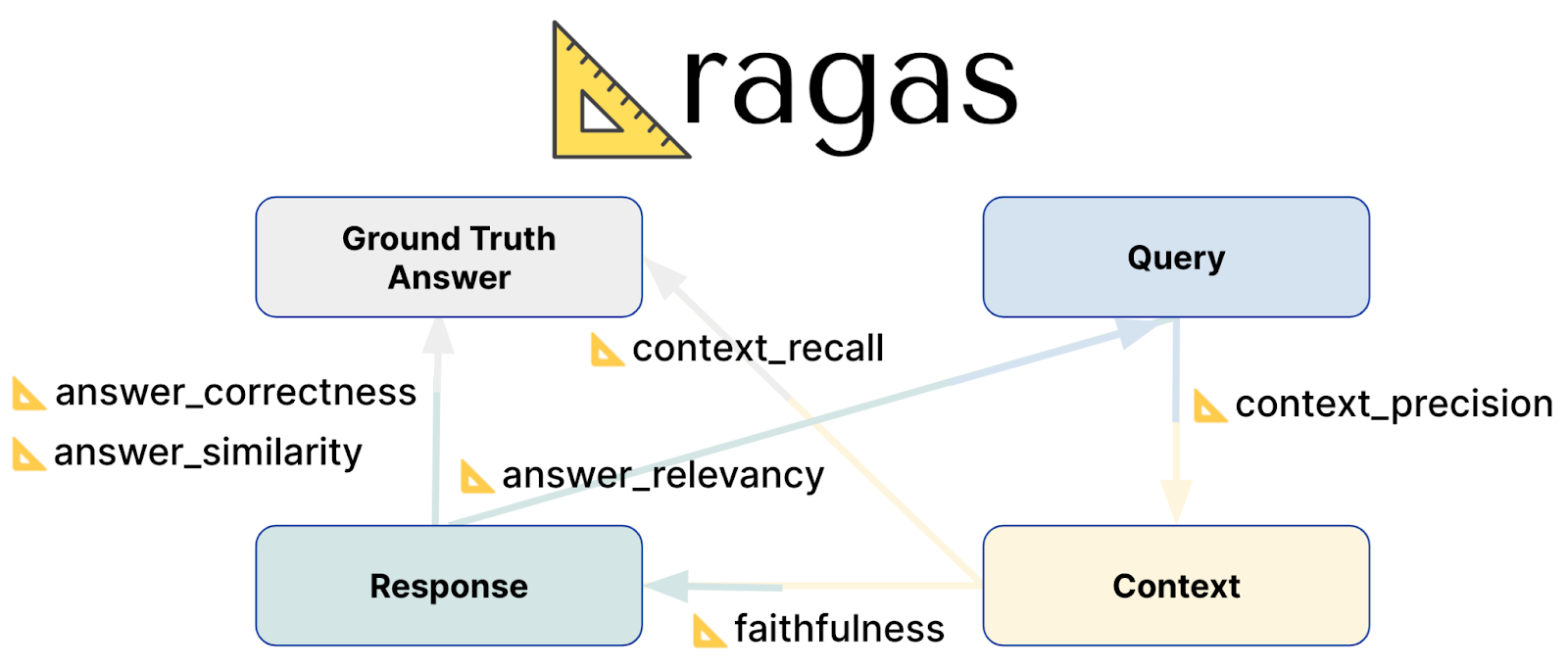
According to the Ragas documentation, your RAG pipeline evaluation will need four key data points.
Question: The question asked.
Contexts: Text chunks from your data that best match the question’s meaning.
Answer: Generated answer from your RAG chatbot to the question.
Ground truth answer: Expected answer to the question.
 Ragas Evaluation Metrics
Ragas Evaluation Metrics
Key Evaluation Metrics
You can find explanations for each evaluation metric, including their underlying formulas, in the documentation. For example, faithfulness. Ragas provides a range of evaluation scores to gauge the effectiveness of RAG systems:
Faithfulness: This score evaluates how accurately the generated answer reflects the information in the provided context. It measures the factual accuracy of the answer, ensuring it aligns with the context from which it is derived. Scores range from 0 to 1, with higher values indicating greater accuracy and consistency.
Answer Relevancy: This answer relevancy metric assesses how well the generated answer responds to the prompt. It focuses on the completeness and relevance of the answer, penalizing incomplete or redundant responses. The relevancy score is derived from the question, context, and answer, with higher scores reflecting better alignment with the prompt.
Context Recall: Context Recall measures how effectively the retrieved context matches the ground truth answer. It calculates the proportion of relevant pieces that were successfully retrieved compared to what was expected. Scores range from 0 to 1, with higher values indicating that a greater portion of relevant context was retrieved.
Context Precision: This metric evaluates whether the most relevant context items are ranked higher than less relevant ones. It checks if all pertinent context chunks appear towards the top of the list. Context Precision is determined using the question, ground truth, and contexts, with higher scores indicating better ranking of relevant information.
Context Relevancy: This context relevance score assesses how relevant the retrieved context is to the question. It measures the degree to which the context matches the intent of the query. The metric ranges from 0 to 1, with higher values showing that the context is more pertinent to the question.
Context Entity Recall: This metric calculates how well the retrieved context captures entities mentioned in the ground truth. It measures the proportion of entities found in both the context and ground truth relative to the total number of entities in the ground truth. Higher scores indicate better capture of important entities in the context.
Details about how these metrics are calculated can be found in their paper.
RAG Evaluation Code Example
This evaluation code assumes you already have a RAG demo. For my demo, I created a RAG chatbot using Milvus Technical documentation and Milvus vector database for retrieval. Full code for my demo RAG notebook and Eval notebooks are on GitHub.
Using that RAG demo, I asked it questions, got the RAG contexts from Milvus, and generated bot responses from an LLM (see the last 2 columns below). Additionally, I provide “ground truth” answers to the same questions (“contexts” column below).
You must install OpenAI, (HuggingFace) dataset, ragas, langchain, and pandas.
# ! pip install openai dataset ragas langchain pandas
import pandas as pd
eval_df = pd.read_csv("data/milvus_ground_truth.csv")
display(eval_df.head())

Convert the pandas dataframe to a HuggingFace Dataset.
from datasets import Dataset
def assemble_ragas_dataset(input_df):
question_list, truth_list, context_list = [], [], []
question_list = input_df.Question.to_list()
truth_list = eval_df.ground_truth_answer.to_list()
context_list = input_df.Custom_RAG_context.to_list()
context_list = [[context] for context in context_list]
rag_answer_list = input_df.Custom_RAG_answer.to_list()
# Create a HuggingFace Dataset from the ground truth lists.
ragas_ds = Dataset.from_dict({"question": question_list,
"contexts": context_list,
"answer": rag_answer_list,
"ground_truth": truth_list
})
return ragas_ds
# Create a Ragas HuggingFace Dataset from the pandas df.
ragas_input_ds = assemble_ragas_dataset(eval_df)
display(ragas_input_ds)

The default LLM model Ragas uses is OpenAI’s gpt-3.5-turbo-16k and the default embedding model is text-embedding-ada-002. You can change both models to whatever you like.
I’ll change the LLM-as-judge model to the pinned gpt-3.5-turbo since OpenAI’s latest blog announced this is the cheapest. I also changed the embedding model to text-embedding-3-small since the blog noted these new embeddings support compression-mode.
In the code below, I’m only using the RAG context evaluation metrics to focus on measuring Retrieval quality of relevant documents.
import os, openai, pprint
from openai import OpenAI
# Save the api key in an env variable.
openai_api_key=os.environ['OPENAI_API_KEY']
# Choose the metrics you want to see.
from ragas.metrics import ( context_recall, context_precision, faithfulness, )
metrics = ['context_recall', 'context_precision', 'faithfulness']
# Change the llm-as-critic.
from ragas.llms import llm_factory
LLM_NAME = "gpt-3.5-turbo"
ragas_llm = llm_factory(model=LLM_NAME)
# Also change the embeddings.
from langchain_openai.embeddings import OpenAIEmbeddings
from ragas.embeddings import LangchainEmbeddingsWrapper
lc_embeddings = OpenAIEmbeddings( model="text-embedding-3-small", dimensions=512 )
ragas_emb = LangchainEmbeddingsWrapper(embeddings=lc_embeddings)
# Change the default models used for each metric.
for metric in metrics:
globals()[metric].llm = ragas_llm
globals()[metric].embeddings = ragas_emb
# Evaluate the dataset.
from ragas import evaluate
ragas_result = evaluate( ragas_input_ds,
metrics=[ context_precision, context_recall, faithfulness, ],
llm=ragas_llm,
)
# View evaluations.
ragas_output_df = ragas_result.to_pandas()
ragas_output_df.head()

You can see the full code for my demo RAG notebook and Eval notebooks on GitHub.
Conclusion
This blog explored into the ongoing challenges of retrieval in Generative AI, with a particular emphasis on Retrieval Augmented Generation (RAG) techniques for advancing natural language AI systems. Effective experimentation is essential for optimizing RAG parameters to fit specific data and use cases, ensuring the best performance. The evaluation of RAG systems can now be greatly enhanced through automation using LLMs as evaluators. We covered the key RAG evaluation metrics and their calculation methods, offering insights into their practical applications. Additionally, an implementation example using the Milvus vector database alongside the Ragas package was highlighted, demonstrating how these tools can be effectively utilized to improve and scale your RAG evaluation frameworks. This approach not only streamlines the evaluation process but also boosts the overall effectiveness of context retrieval in AI-driven solutions. For further exploration, consider investigating real-world applications, addressing challenges, exploring future directions, adhering to best practices, and accessing additional resources to deepen your understanding of evaluating RAG systems and refining your RAG pipeline.

Keep Reading

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.