




Retrieval Augmented Generation with Citations
When you get responses from your large language model (LLM) apps, do you want to know where that response came from? That’s the power of citations or attributions. In this tutorial, we will look at why it’s important to include citations, how you can get citations from a high level, and then take a dive into a code example!
Why cite your Retrieval Augmented Generation (RAG) sources?
Retrieval Augmented Generation is a technique used with LLM apps to supplement their knowledge. One of the primary weaknesses of LLMs in general is their lack of either up to date or domain specific knowledge. There are two main solutions to this: fine-tuning and retrieval augmented generation.
Here at Zilliz and other companies like OpenAI, we propose RAG as the superior option for fine-tuning for fact-based retrieval. Fine-tuning is more expensive and requires much more data; however, it is a good option for style-transfer. RAG uses a vector database such as Milvus to inject your knowledge into your app.
Instead of asking the LLM about your product or docs, you can use a vector database as your truth store. This ensures that your app returns the correct knowledge and doesn’t hallucinate as an attempt to make up for the lack of data. As you start to add more documents and use cases, it becomes more and more important to know where that information lies.
This is where citations and attributions come in. When you get a response from your LLM app, you want to know how it got that information. Getting responses back with citations or attributions shows you which piece of text/where in the text your response came from. As we have more and more data, this becomes critical to determining trustworthy answers.
How can you cite your RAG sources?
LLMs have boosted the popularity of adjacent tools, such as vector databases like Milvus. It’s also given rise to frameworks such as LangChain and LlamaIndex. As part of this rise in popularity, retrieval augmented generation has become an essential app, especially when it comes to information retrieval on your internal data.
In addition to retrieving data, many people have realized that adding citations to your retrieved data makes your app more robust, more explainable, and provides more context. So, how do you do that? There are many ways you can do this. You can store the chunks of text inside your vector database if it supports metadata like Milvus, or you can use a framework like LlamaIndex. This tutorial will cover how to do RAG with citations using LlamaIndex and Milvus.
Retrieval Augmented Generation with sources example
Let’s dive into the code. To do this tutorial, you need to pip install milvus llama-index python-dotenv. The milvus and llama-index libraries are for the core functionality while python-dotenv is for loading your environment variables such as your OpenAI API key. In this example, we scrape some data about different cities from Wikipedia and do a query with citations on that.
We import some necessary libraries and load up our OpenAI API key. We need seven submodules from LlamaIndex. In no particular order: OpenAI to access an LLM, CitationQueryEngine for creating the citation query engine, and MilvusVectorStore to use Milvus as a vector store. In addition, we also import VectorStoreIndex to use Milvus, SimpleDirectoryReader for reading in local data, and StorageContext and ServiceContext to give the vector index access to Milvus. Finally, we use load_dotenv to load up our OpenAI API key.
from llama_index.llms import OpenAI
from llama_index.query_engine import CitationQueryEngine
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
ServiceContext,
)
from llama_index.vector_stores import MilvusVectorStore
from milvus import default_server
from dotenv import load_dotenv
import os
load_dotenv()
open_api_key = os.getenv("OPENAI_API_KEY")
Scraping some test data
Let’s start off our project by first having some data to work with. For this example, we scrape some data from Wikipedia. Actually, we are scraping the same data as we did for building a multi-document query engine. The below code pings Wikipedia’s API for the pages mentioned in the wiki_titles list. It saves the result into a text file locally.
wiki_titles = ["Toronto", "Seattle", "San Francisco", "Chicago", "Boston", "Washington, D.C.", "Cambridge, Massachusetts", "Houston"]
from pathlib import Path
import requests
for title in wiki_titles:
response = requests.get(
'https://en.wikipedia.org/w/api.php',
params={
'action': 'query',
'format': 'json',
'titles': title,
'prop': 'extracts',
'explaintext': True,
}
).json()
page = next(iter(response['query']['pages'].values()))
wiki_text = page['extract']
data_path = Path('data')
if not data_path.exists():
Path.mkdir(data_path)
with open(data_path / f"{title}.txt", 'w') as fp:
fp.write(wiki_text)
Setting up your vector store in LlamaIndex
Now that we have all our data, we can set up the app logic for our RAG with citations app. Starting out, the first thing that we need to do is spin up a vector database. In this example, we use Milvus Lite to run it directly in our notebook. Then we use the MilvusVectorStore module from LlamaIndex to connect to Milvus as our vector store.
default_server.start()
vector_store = MilvusVectorStore(
collection_name="citations",
host="127.0.0.1",
port=default_server.listen_port
)
Next, let’s create the contexts for our index. The service context tells the index and retriever what services to use. In this case, it’s passing in GPT 3.5 Turbo as the desired LLM. We also create a storage context so the index knows where to store and query for data. In this case, we pass the Milvus vector store object we created above.
service_context = ServiceContext.from_defaults(
llm=OpenAI(model="gpt-3.5-turbo", temperature=0)
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
With all of this set up, we can load the data that we scraped earlier and create a vector store index from those documents.
documents = SimpleDirectoryReader("./data/").load_data()
index = VectorStoreIndex.from_documents(documents, service_context=service_context, storage_context=storage_context)
Querying with citations
Now we can create a Citation Query Engine. We give it the vector index we built earlier and parameters about how many results to return, and the chunk size of the citation. That’s all there is to set up the citation, and the next step is to query the engine.
query_engine = CitationQueryEngine.from_args(
index,
similarity_top_k=3,
# here we can control how granular citation sources are, the default is 512
citation_chunk_size=512,
)
response = query_engine.query("Does Seattle or Houston have a bigger airport?")
print(response)
for source in response.source_nodes:
print(source.node.get_text())
When we query, the response looks something like this.
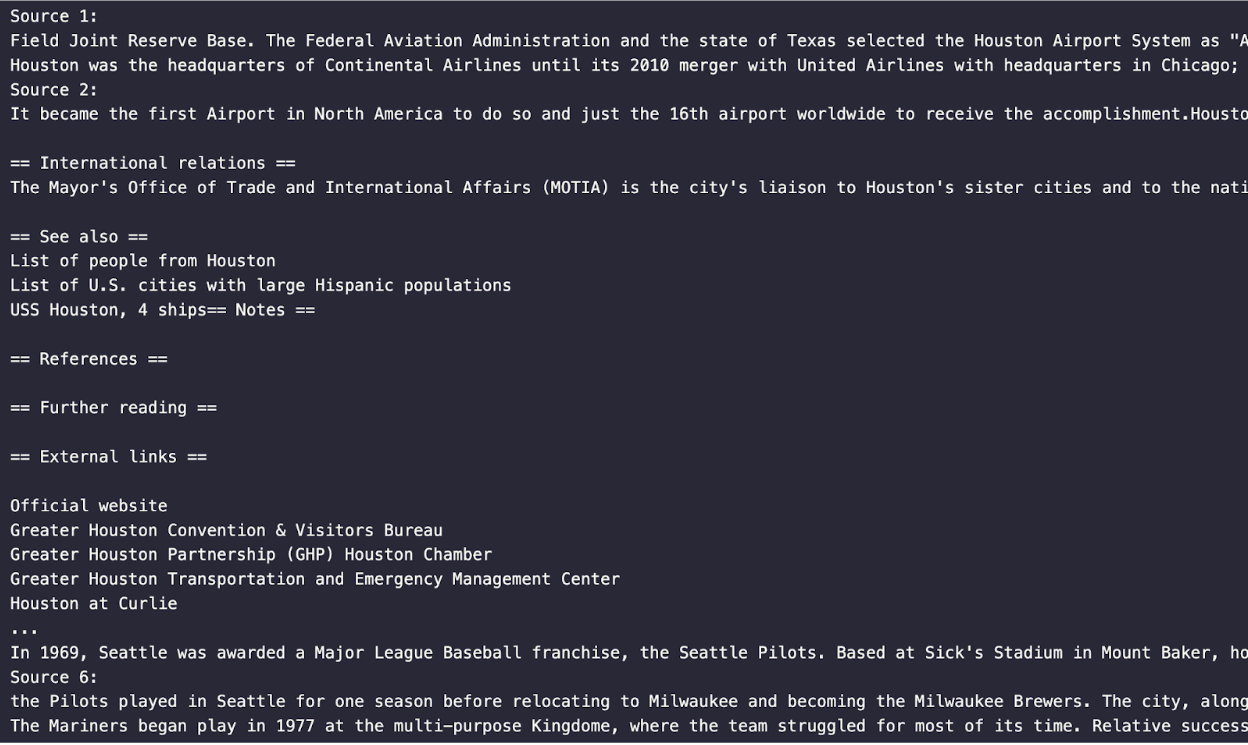 Querying with citations
Querying with citations
Summary
In this tutorial, we learned how to do retrieval augmented generation with citations (attributions). Retrieval augmented generation is a type of LLM application many enterprises want to build. In addition to retrieving and formatting your information in a digestible format, we also want to know where the information comes from.
We can build this type of RAG application using LlamaIndex as our data router and Milvus as our vector store. We started by scraping some data from Wikipedia to show how this works. Then, we spin up an instance of Milvus and make a vector store instance in LlamaIndex. From there, we put our data into Milvus and used LlamaIndex to keep track of the attributions and citations using a citation query engine. We can then query that query engine and get responses, including where in the text and what text we are drawing our answer from.

Keep Reading

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.