




Will Retrieval Augmented Generation (RAG) Be Killed by Long-Context LLMs?
Pursuing innovation and supremacy in AI shows no signs of slowing down. Recently, Google revealed Gemini 1.5, a mere two months after the debut of Gemini, their latest large language model (LLM) capable of handling contexts spanning up to an impressive 10 million tokens. Simultaneously, OpenAI has taken the stage with Sora, a robust text-to-video model celebrated for its captivating visual effects. The face-off of these two cutting-edge technologies has sparked discussions about the future of AI, especially the role and potential demise of Retrieval Augmented Generation (RAG).
In this blog, we’ll explore the intricacies of Gemini’s long-context capabilities, limitations, and impact on the evolution of Retrieval Augmented Generation techniques. Most importantly, we’ll discuss whether RAG is on the verge of demise and how to optimize RAG systems.
Understanding Gemini's Long-Context Capability
While the allure of Sora's visual effects catches more attention, I am more interested in Gemini and its accompanying technical report, spanning over 50 pages and exploring Gemini's long-context and multimodal capabilities testing. According to this report, Gemini 1.5 Pro supports ultra-long contexts of up to 10 million tokens and multimodal data processing, enabling Gemini to interact seamlessly with diverse data, from an entire book and massive document collections to extensive code libraries and a one-hour movie.
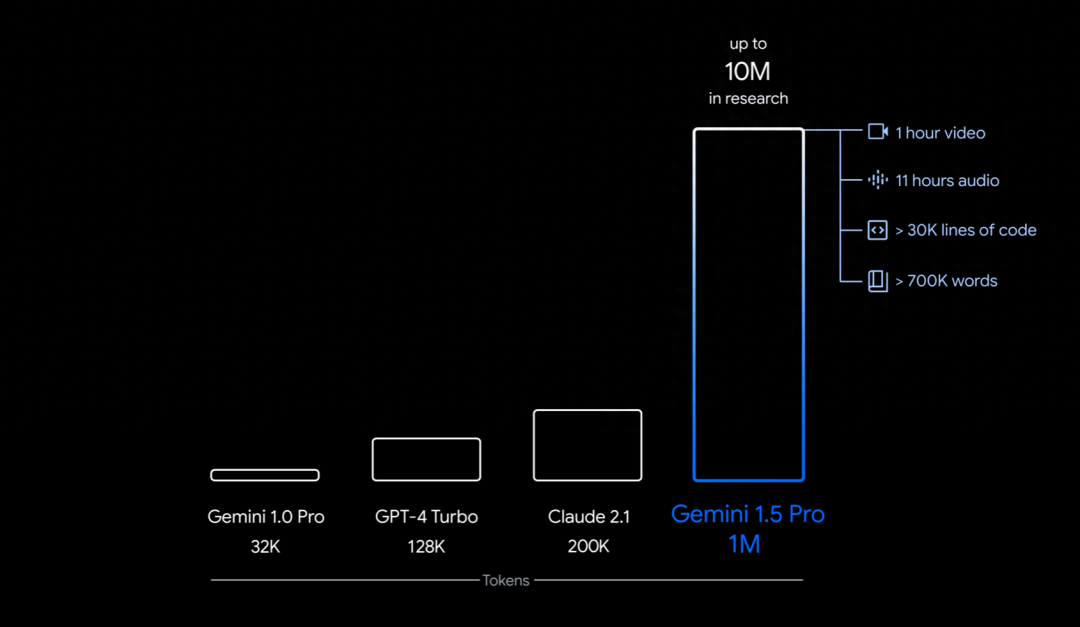
Gemini 1.5 Pro supports ultra-long contexts of up to 10M tokens. Image source: https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/
Retrieval Stability and Accuracy
This report introduces a "needle-in-a-haystack" evaluation method to test and compare the retrieval ability of Gemini 1.5 Pro and GPT-4. In this test, Google inserts text segments (the "needles") at different positions of a lengthy document (the "haystack"), and Gemini and GPT need to find and name relevant documents to retrieve them.
The testing results show that Gemini 1.5 Pro achieves 100% recall from up to 530,000 tokens and maintains over 99.7% recall from up to 1M tokens. Even with a super long document of 10M tokens, the model retains an impressive 99.2% recall rate. While GPT-4 handles less than 128,000 tokens excellently, Gemini is more proficient in handling more extended contexts. These results underscore Gemini's excellent information retrieval, stability and accuracy in exceptionally lengthy contexts up to 10M tokens.
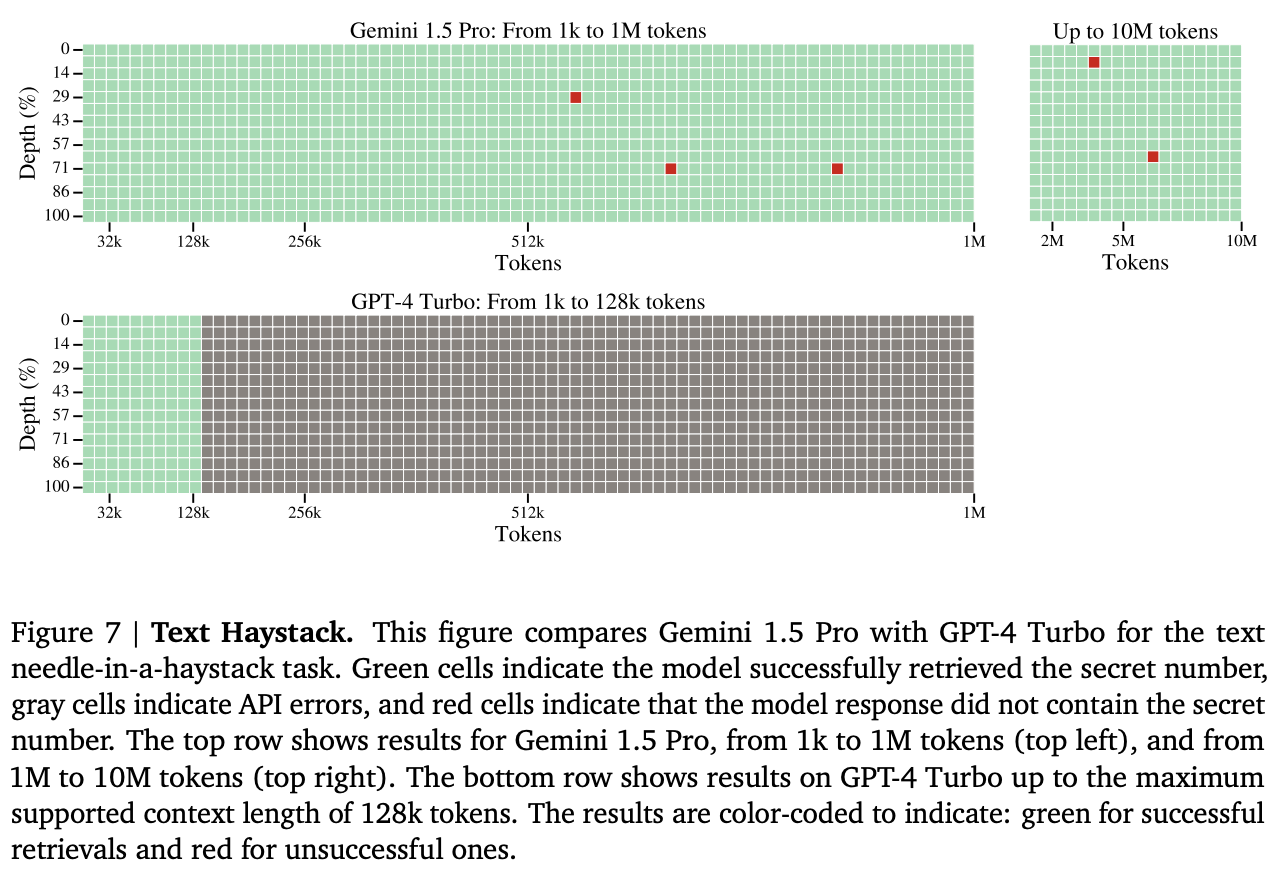
Image Source: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
Question Answering
In addition to testing Gemini's retrieval ability, Google evaluates its question-answering ability provide context. In this test, Google uses the book Les Misérables (710,000 tokens) as the context and asks Gemini 1.5 Pro, Gemini 1.0 Pro, and Anthropic's Claude 2.1 to answer questions about the book.
Because Gemini 1.0 Pro and Claude 2.1 support a smaller context length than 710,000 tokens, they must leverage the retrieval augmented generation (RAG) technique to access Top-K's most relevant passages (up to 4,000 tokens) from the book as their context. Gemini has a larger context window, so it refers to the whole book as its context. This test also compares the three models' performance on the 0-shot setup with nothing provided as contexts.
The testing results show that Gemini 1.5 Pro outperforms other RAG-powered LLMs in answering questions, showcasing its dominance in understanding and processing giant text collections. This test also reveals that the retrieval augmented generation technique often struggles to resolve reference expressions and reasoning across data sources with long-distance dependencies.
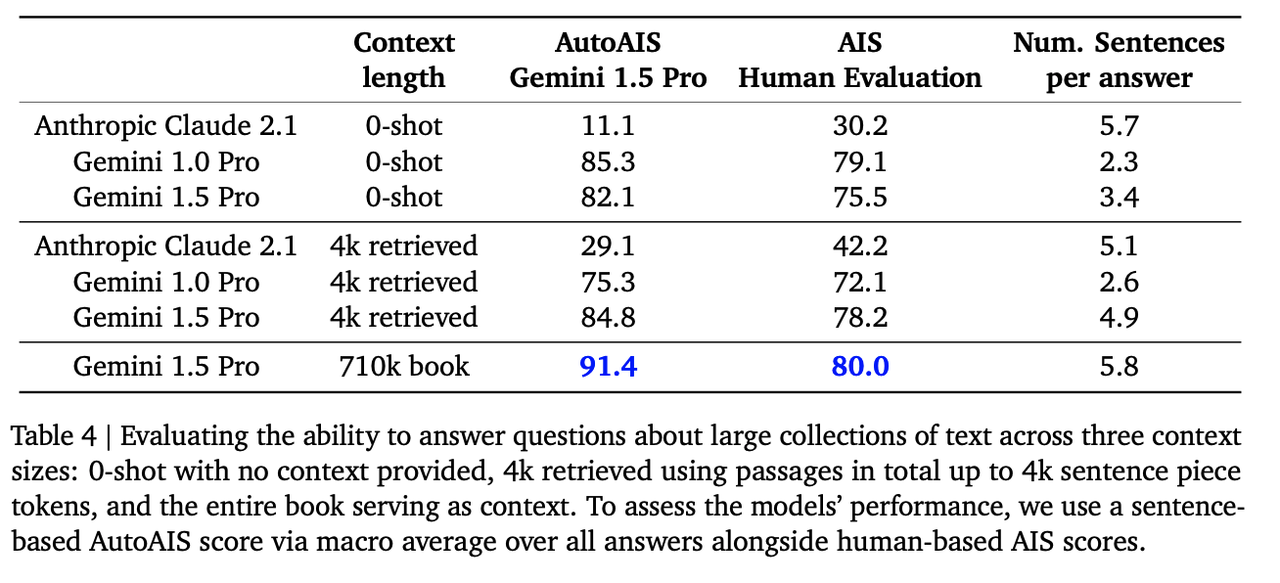
Image Source: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
Will Long-context LLMs Kill RAG?
The retrieval augmented generation framework, incorporating a vector database, an LLM, and prompt-as-code, is a cutting-edge technology that seamlessly integrates external knowledge sources to enrich an LLM's knowledge base for precise and relevant documents and answers. It is a proven solution that effectively addresses fundamental LLM challenges such as hallucinations and lacking domain-specific knowledge.
Witnessing Gemini's impressive performance in handling long contexts, some voices quickly predict RAG's demise. For example, in a review of Gemini 1.5 Pro on Twitter, Dr. Yao Fu boldly stated, "The 10M context kills RAG."

Is this assertion true? From my perspective, the answer is “NO.” The development of the RAG technology has just begun and will continue to evolve. While Gemini excels in managing extended contexts, it grapples with persistent challenges encapsulated as the 4Vs: Velocity, Value, Volume, and Variety.
LLMs’ 4Vs Challenges
Velocity: Gemini faces hurdles in achieving sub second response times for extensive contexts, evidenced by a 30-second delay in responding to 360,000 contexts. Despite optimism about LLMs’ computational advancements, speedy responses at the sub second level when retrieving long contexts remain challenging for large transformer-based models.
Value: The value proposition of LLMs is undermined by the considerable inference costs associated with generating high-quality answers in long contexts. For example, retrieving 1 million tokens of datasets at a rate of 1.50 for a single request. This cost factor renders such high expenditures impractical for everyday utilization, posing a significant barrier to widespread adoption.
Volume: Despite its capability to handle a large context window of up to ten million tokens, Gemini's volume capacity is dwarfed when compared to the vastness of unstructured data. For instance, no LLM, including Gemini, can adequately accommodate the colossal scale of data found within the Google search index. Furthermore, private corporate data will have to stay within the confines of their owners, who may choose to use RAG, train their own models, or use a private LLM.
Variety: Real-world use cases involve not only unstructured data like lengthy texts, images, and videos but also a diverse range of structured data that may not be easily captured by an LLM for training purposes such as time-series data, graph data, and code changes. Streamlined data structures and retrieval algorithms are essential to process such varied data efficiently.All these challenges highlight the importance of a balanced approach in developing AI applications, making RAG increasingly crucial in the evolving landscape of artificial intelligence.
Strategies for Optimizing RAG Effectiveness
While retrieval augmented generation has proven beneficial in reducing LLM hallucinations, it does have limitations. In this section, we’ll explore strategies to optimize retrieval augmented generation effectiveness to strike a balance between accuracy and performance to make RAG systems more adaptable across a broader range of applications.
Enhancing Long Context Understanding
Conventional retrieval augmented generation techniques often rely on chunking for vectorizing unstructured data, primarily due to the size limitations of embedding models and their context windows. However, this chunking approach presents two notable drawbacks.
- Firstly, it breaks down the input sequence into isolated chunks, disrupting the continuity of context and negatively impacting embedding quality.
- Secondly, there's a risk of separating consecutive information into distinct chunks, potentially resulting in incomplete retrieval of essential information.
In response to these challenges, emerging embedding strategies based on LLMs have gained traction as efficient solutions. They boast better embedding capability and support expanded context windows. For instance, SRF-Embedding-Mistral and GritLM7B, two best-performing embedding language models on the Huggingface MTEB LeaderBoard, support 32k-token-long contexts, showcasing a substantial improvement in embedding capabilities. This enhancement in embedding unstructured data also elevates RAG’s understanding of long contexts.
Another effective approach to tackle the challenges above is the recently released BGE Landmark Embedding strategy. This approach adopts a chunking-free architecture, where embeddings for the fine-grained input units, e.g., sentences, can be generated based on a coherent long context. It also leverages a position-aware function to facilitate the complete retrieval of helpful information comprising multiple consecutive sentences within the long context. Therefore, landmark embedding is beneficial to enhancing the ability of RAG systems to comprehend and process long contexts.
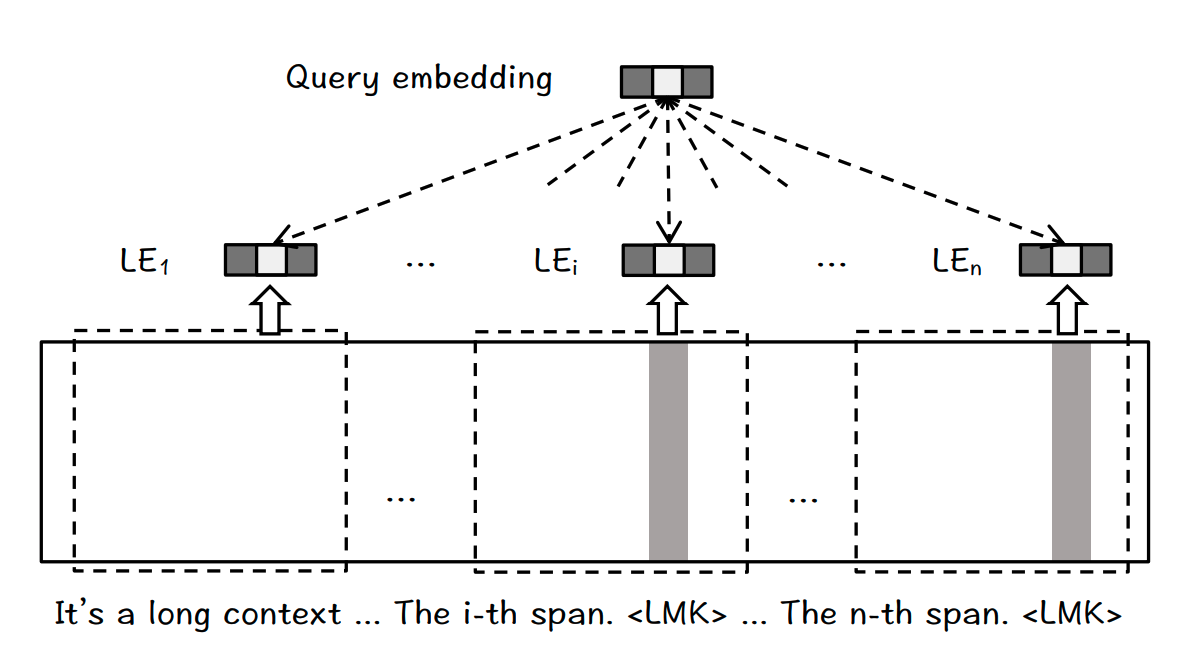
The architecture for landmark embedding. Landmark (LMK) tokens are appended to the end of each sentence. A sliding window is employed to handle the input texts longer than the LLM’s context window. Image Source: https://arxiv.org/pdf/2402.11573.pdf
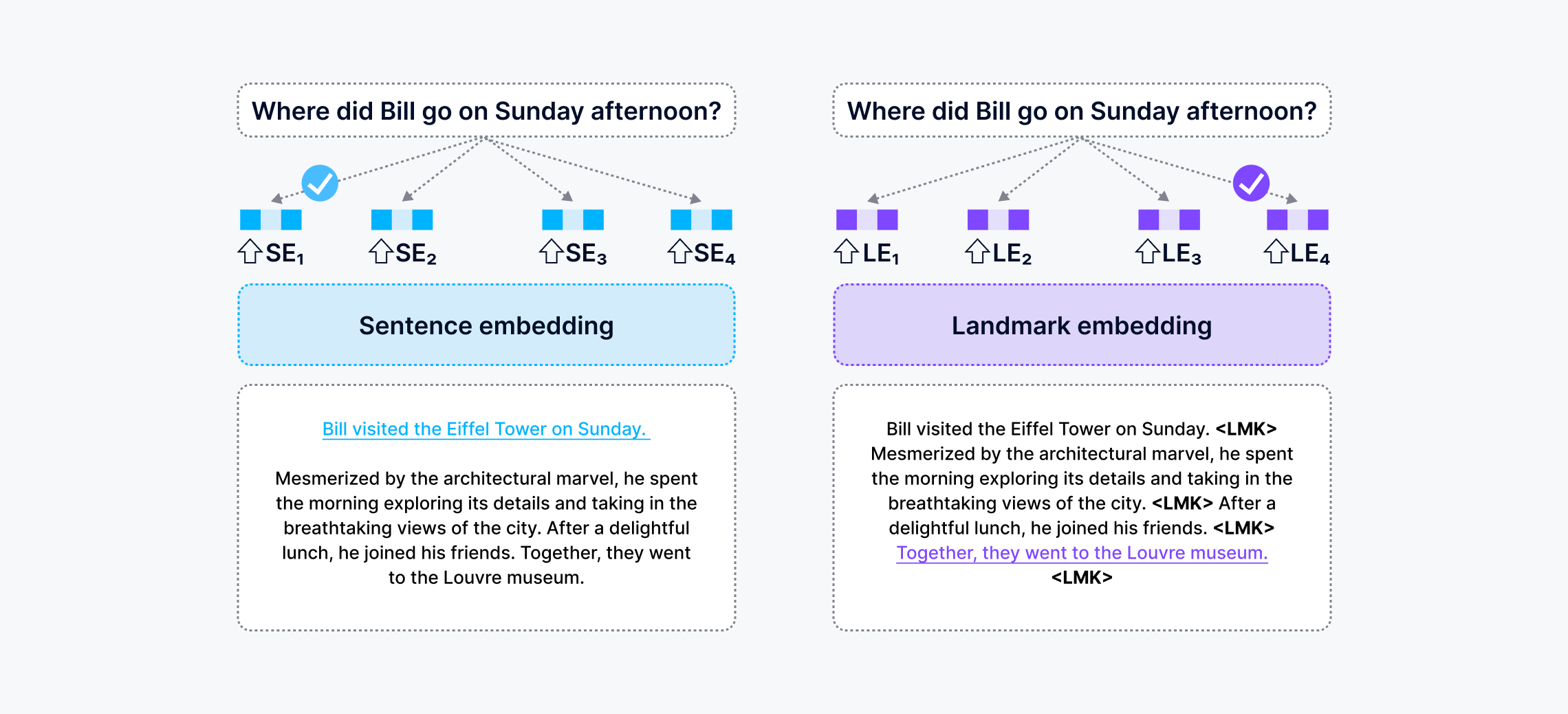
This diagram compares the Sentence Embedding and Landmark Embedding methods in helping RAG apps answer questions. The former works with the chunked context, which tends to select the salient sentence. The latter maintains a coherent context, which enables it to select the right sentence. The sentences highlighted in blue and purple are answers retrieved by the two embedding methods, respectively. The RAG system that leveraged Sentence embedding gave the wrong answer, while the Landmark embedding-based RAG gave the correct answer. This image is adapted from: https://arxiv.org/abs/2402.11573
Utilizing Hybrid Search for Improved Search Quality
The quality of retrieval augmented generation responses hinges on its ability to retrieve high-quality relevant information. Data cleaning, structured information extraction, and hybrid search are all effective ways to enhance the retrieval quality. Recent research suggests sparse vector models like Splade outperform dense vector models in out-of-domain knowledge retrieval, keyword perception, semantic search, and many other areas.
The recently open-sourced BGE_M3 embedding model can generate sparse, dense, and Colbert-like token vectors within the same model. This innovation significantly improves the retrieval quality of vector database by conducting hybrid retrievals across different types of vectors. Notably, this approach aligns with the widely accepted hybrid search concept among vector database vendors like Zilliz. For example, the upcoming release of Milvus 2.4 promises a more comprehensive hybrid search of dense and sparse vectors.
Utilizing Advanced Technologies to Enhance RAG’s Performance
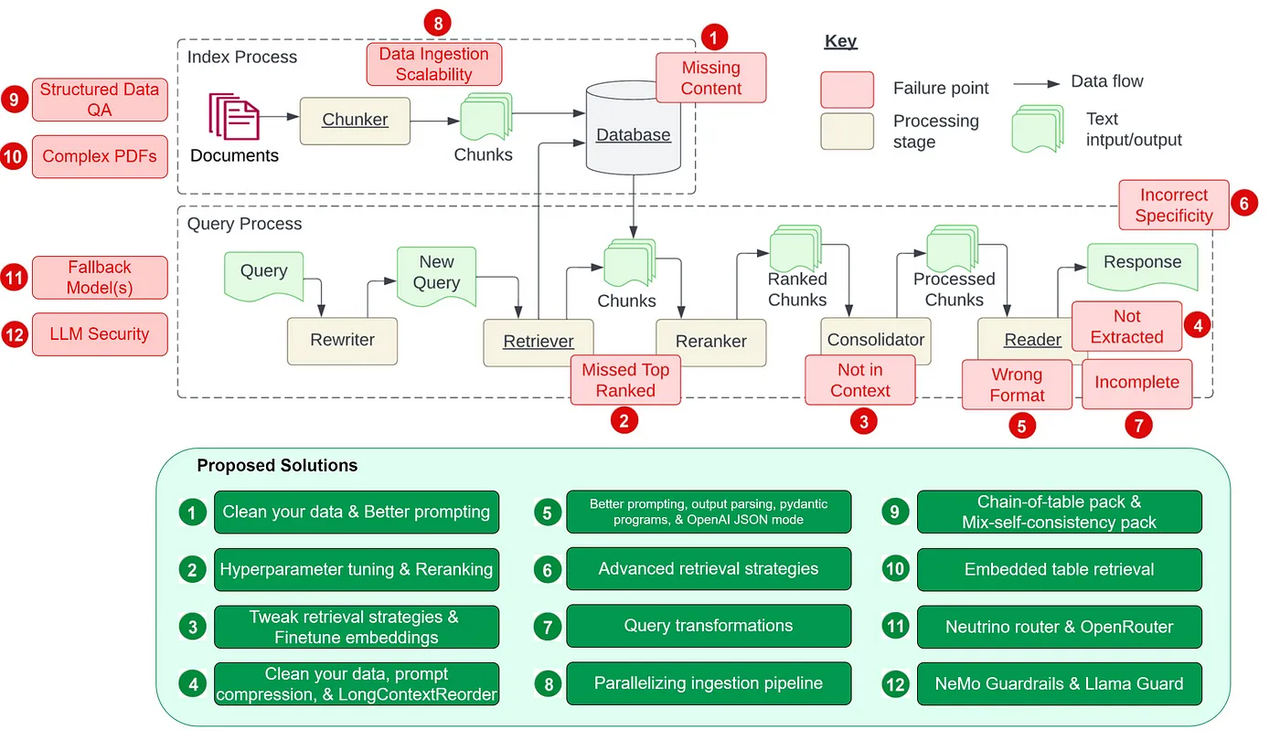
In this diagram, Wenqi Glantz listed 12 pain points in developing a RAG pipeline and proposed 12 corresponding solutions to address these challenges. Image source:https://towardsdatascience.com/12-rag-pain-points-and-proposed-solutions-43709939a28c
Maximizing RAG capabilities involves addressing numerous algorithmic challenges and leveraging sophisticated engineering capabilities and technologies. As highlighted by Wenqi Glantz in her blog, developing a RAG pipeline presents at least 12 complex engineering challenges. Addressing these challenges requires a deep understanding of ML algorithms and utilizing complicated techniques like query rewriting, intent recognition training data,, and entity detection.
Even advanced models like Gemini 1.5 face substantial hurdles. They require 32 calls to achieve a 90.0% accuracy rate in Google's MMLU benchmark tests. This underscores the nature of maximizing performance in RAG systems.
Vector databases, one of the cutting-edge AI technologies, are a core component in the RAG pipeline. Opting for a more mature and advanced vector database, such as Milvus, extends the capabilities of your RAG pipeline from answer generation to tasks like classification, structured data extraction, and handling intricate PDF documents. Such multifaceted enhancements of vector databases contribute to the adaptability of RAG systems across a broader spectrum of application use cases.
Conclusion: RAG Remains a Linchpin for the Sustained Success of AI Applications.
Large language models are reshaping the world, but they cannot change our world’s fundamental principles. The separation of computation, memory, and external data storage has existed since the inception of the von Neumann architecture in 1945. However, even with single-machine memory reaching the terabyte level today, SATA and flash disks still play crucial roles in different application use cases. This demonstrates the resilience of established paradigms in the face of technological evolution.
The RAG framework is still a linchpin for the sustained success of AI applications. Its provision of long-term memory for Large language models proves indispensable for developers seeking an optimal balance between query quality and cost-effectiveness. In deploying generative AI by large enterprises, RAG is a critical tool for cost control without compromising response quality.
Just like large memory developments cannot kick out hard drives, the role of RAG, coupled with its supporting technologies like the vector database, remains integral and adaptive. It is poised to endure and coexist within the new data ever-evolving landscape of AI applications and information retrieval.

Keep Reading

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.