




Evaluations for Retrieval Augmented Generation: TruLens + Milvus
This article was originally published in The New Stack and is reposted here with permission.

The increasing popularity of large language models (LLMs) has fueled the rise of vector search technologies, including purpose-built vector databases such as Milvus and Zilliz Cloud, vector search libraries such as FAISS, and vector search plugins integrated with traditional databases.
Increasingly, vector search has become the essential enterprise use case for generative AI in the form of retrieval augmented generation, or RAGs, question-answering applications. This style of construction allows the LLMs to have easy access to a verified knowledge base that they can use as context to answer questions. Milvus is a highly scalable open source vector database purpose-built for this application.
Constructing a RAG
When building an effective RAG-style LLM application, there are many configuration choices to choose from that can significantly affect retrieval quality. Some of these choices include:
Constructing the Vector DB
- Data selection
- Embedding model
- Index type
Finding high-quality data that precisely matches your application’s requirements is critical. The retrieval process might provide irrelevant results if you don’t have the correct data.
After selecting your data, consider the embedding model you use, as it significantly influences the retrieval quality. Even if your knowledge base contains the correct information, the retriever may produce incorrect results if the embedding model needs a semantic understanding of your domain.
Context relevance is a helpful metric for gauging the retrieval quality, and these selections greatly affect it.
Last, index type can have a significant impact on the efficiency of semantic search. This is especially true for large data sets; this choice allows you to trade between recall rate, speed and resource requirements. Milvus supports various index types, such as flat indices, product quantization-based indices and graph-based indices. You can read more about different index types.
Retrieval
- Amount of context retrieved (top k)
- Chunk size
When we get to the retrieval, top k is an often-discussed parameter that controls the number of context chunks retrieved. A higher top k gives us a higher chance of retrieving the needed information and increases the likelihood of our LLM incorporating irrelevant information into its answer. For simple questions, a lower top k is often the most performant.
Chunk size controls the size of each context retrieved. A larger chunk size can be helpful for more complex questions, while smaller chunks are sufficient for simple questions that can be answered with only a tiny amount of information.
For many of these choices, there is no one-size-fits-all. Performance can vary wildly depending on the size and type of data, the LLMs used, your application and more. We need an evaluation tool to assess the quality of these retrievals for our specific use case. This is where TruLens comes in.
TruLens for LLM tracking and evaluation
TruLens is an open source library for evaluating and tracking the performance of LLM apps, such as RAGs. With TruLens, we also gain the ability to use LLMs themselves to evaluate output, retrieval quality and more.
When we build LLM applications, the most important issue on many people’s minds is hallucination. RAGs go a long way toward ensuring accurate information by providing retrieved context to the LLM, but they cannot guarantee it. Evaluations are essential here in verifying the absence of hallucination in our app. TruLens offers three tests for this need: context relevance, groundedness and answer relevance. Let’s review each of these to understand how they can benefit us.
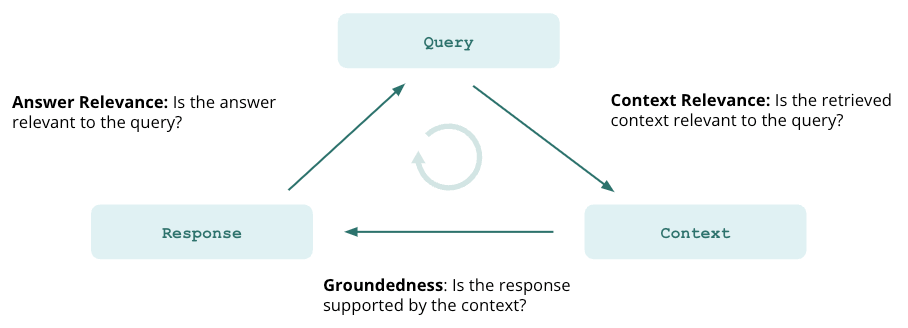
Context relevance
The first step of any RAG application is retrieval; to verify the quality of our retrieval, we want to ensure that each chunk of context is relevant to the input query. This is critical because the LLM will use this context to form an answer, so any irrelevant information in the context could be weaved into a hallucination.
Groundedness
After the context is retrieved, it is then formed into an answer by an LLM. LLMs often stray from the facts provided, exaggerating or expanding to a correct-sounding answer. To verify the groundedness of our application, we should separate the response into separate statements and independently search for evidence that supports each within the retrieved context.
Answer relevance
Last, our response still needs to helpfully answer the original question. We can verify this by evaluating the relevance of the final response to the user input.
Hallucination-free RAGs
By reaching satisfactory evaluations for this triad, we can make a nuanced statement about our application’s correctness; it is verified to be hallucination-free up to the limit of its knowledge base. In other words, if the vector database contains only accurate information, then the answers provided by the RAG are also accurate.
Making it concrete
As we mentioned before, many of the configuration choices for our RAG can have a substantial impact on hallucination. To illustrate this, we’ll build a RAG question-answering application on top of Wikipedia articles on a small set of cities. LlamaIndex will act as the framework for this application.
Follow along with this example in Google Colab.
Load data from Wikipedia
To construct our vector store, we first need to load data. Here, we’ll use a data loader from LlamaIndex to load data directly from Wikipedia.
from llama_index import WikipediaReader
cities = [
"Los Angeles", "Houston", "Honolulu", "Tucson", "Mexico City",
"Cincinatti", "Chicago"
]
wiki_docs = []
for city in cities:
try:
doc = WikipediaReader().load_data(pages=[city])
wiki_docs.extend(doc)
except Exception as e:
print(f"Error loading page for city {city}: {e}")
Set up evaluators
Next, we want to set up our evaluators. Specifically, we’ll use the triad we mentioned earlier: context relevance, groundedness and answer relevance to test for hallucination.
TruLens provides a set of evaluators or feedback functions with prompts useful for this evaluation that use a specific model provider, such as OpenAI, Anthropic or HuggingFace.
# Initialize OpenAI-based feedback function collection class:
openai_gpt4 = feedback.OpenAI()
After we’ve set our model provider, we choose question-statement relevance to use for our first evaluation. For each evaluation in this example, we’ll also use chain-of-thought reasons to better understand the evaluations. This is denoted by the feedback function suffix 1_with_cot_reason.
When we do this, we also need to select which text to pass to our feedback function. TruLens serializes the application, which is then indexed by a JSON-like structure. We will use this index for text selection. TruLens provides a number of helper functions to make this easy:
on_input()automatically finds the main input passed to our LlamaIndex application to use as the first text passed to our feedback function.TruLlama.select_source_nodes()identifies the source nodes used in a LlamaIndex retrieval.
Last, we need to aggregate the relevance for each piece of context into a single score. For this example, we’ll use the max for aggregation to measure the relevance of the most relevant chunk. Other metrics like average or minimum could also be used.
# Question/statement relevance between question and each context chunk.
f_context_relevance = Feedback(openai.qs_relevance_with_cot_reason, name = "Context Relevance").on_input().on(
TruLlama.select_source_nodes().node.text
).aggregate(np.max)
Groundedness is set up similarly, with a slightly different aggregation. In this case, we will take the max groundedness score of each statement, and then the average groundedness score across all statements.
grounded = Groundedness(groundedness_provider=openai_gpt4)
f_groundedness = Feedback(grounded.groundedness_measure_with_cot_reason, name = "Groundedness").on(
TruLlama.select_source_nodes().node.text # context
).on_output().aggregate(grounded.grounded_statements_aggregator)
Answer relevance is the simplest feedback function to set up, since it only relies on input/output. We can use a new TruLens helper function for this — .on_input_output().
# Question/answer relevance between overall question and answer.
f_qa_relevance = Feedback(openai.relevance_with_cot_reason,
name = "Answer Relevance").on_input_output()
Defining the configuration space
Now that we’ve loaded our data and set up our evaluators, it’s time to construct our RAG. In this process, we’ll construct a series of RAGs with different configurations, evaluate each and select the best optimal choice.
As we alluded to earlier, we will limit our configuration space to a few impactful choices for RAGs. We will test index type, embedding model, top k and chunk size in this example; however, you are encouraged to test other configurations such as different distance metrics and search parameters.
Iterating through our selections
After defining the configuration space, we’ll use itertools to try every combination of these choices and evaluate each. Additionally, Milvus gives us a nice benefit of the overwrite parameter. This lets us easily iterate through different configurations without slow teardown and instantiation procedures that can be required with other vector databases.
In each iteration, we’ll pass the index parameter selection to MilvusVectorStore and to our application using the storage context. We’ll pass our embedding model to the service context and then create our index.
vector_store = MilvusVectorStore(index_params={
"index_type": index_param,
"metric_type": "L2"
},
search_params={"nprobe": 20},
overwrite=True)
llm = OpenAI(model="gpt-3.5-turbo")
storage_context = StorageContext.from_defaults(vector_store = vector_store)
service_context = ServiceContext.from_defaults(embed_model = embed_model, llm = llm, chunk_size = chunk_size)
index = VectorStoreIndex.from_documents(wiki_docs,
service_context=service_context,
storage_context=storage_context)
Then, we can construct a query engine using this index — defining top_k here:
query_engine = index.as_query_engine(similarity_top_k = top_k)
After construction, we’ll use TruLens to wrap the application. Here, we’ll give it an easily identifiable name, record the configurations as app metadata and define the feedback functions for evaluation.
tru_query_engine = TruLlama(query_engine,
app_id=f"App-{index_param}-{embed_model_name}-{top_k}",
feedbacks=[f_groundedness, f_qa_relevance, f_context_relevance],
metadata={
'index_param':index_param,
'embed_model':embed_model_name,
'top_k':top_k
})
This tru_query_engine will operate just as the original query engine.
Last, we’ll use a small set of test prompts for evaluation, calling the application to provide a response to each prompt. Because we’re calling the OpenAI API in rapid succession, Tenacity is useful to use here to help us avoid rate limit issues through exponential backoff.
@retry(stop=stop_after_attempt(10), wait=wait_exponential(multiplier=1, min=4, max=10))
def call_tru_query_engine(prompt):
return tru_query_engine.query(prompt)
for prompt in test_prompts:
call_tru_query_engine(prompt)
The results
Which configuration performed the best?
| Index Type | Embedding Model | Similarity Top k | Chunk Size |
|---|---|---|---|
| IVF Flat | text-embedding-ada-002 | 3 | 200 |

Which configuration performed the worst?
| Index Type | Embedding Model | Similarity Top k | Chunk Size |
|---|---|---|---|
| IVF Flat | Multilingual MiniLM L12 v2 | 1 | 500 |

Which failure modes were identified?
One failure mode we observed was retrieval of information about the wrong city. You can see an example of this with the chain-of-thought reasoning below, where context about Tucson was retrieved instead of Houston.

Similarly, we also saw issues where we retrieved context about the correct city, but the context was irrelevant to the input question.

Given this irrelevant context, the completion model went on to hallucinate. It’s important to note here that hallucination isn’t necessarily factually incorrect; it’s just when the model answers without supporting evidence.

Additionally, we even found examples of irrelevant answers.

Understanding performance
By index type
Index type did not have a meaningful impact on performance in terms of speed, token usage or evaluations. This is likely a result of the small size of data ingested for this example, and index type can be a more important selection for larger corpuses.
By embedding model
Text-embedding-ada-002 outperformed the MiniLM embedding model on groundedness (0.72 compared to 0.60 on average) and answer relevance (0.82 compared to 0.62 on average). The two embedding models performed equally well on context relevance.
These improved evaluation scores can be attributed to OpenAI embeddings better suited to Wikipedia information.
Similarity Top K
Increasing top k resulted in slightly improved maximum retrieval quality (measured by context relevance). By retrieving a larger number of chunks, the retriever has more attempts to retrieve high-quality context.
A higher top k also improved groundedness (0.71 compared to 0.62 on average) and answer relevance (0.76 compared to 0.68 on average). By retrieving more context chunks, we provide more evidence for the completion model to make and support claims.
As expected, these improvements come at a cost of much higher token usage (an average of 590 additional tokens per call).
Chunk size
Increasing chunk size diminished the groundedness of our retriever by forcing the inclusion of surrounding text irrelevant to the input question.
On the plus side, a higher chunk size provided more evidence to check against. So when the LLM does make claims, they are more likely to be supported by retrieved context.
Last, increasing chunk size increased the average token usage by 400 tokens per record.
Build a better RAG with TruLens and Milvus
In this post, we learned how to build a RAG with various configurations and parameters, including index type, embedding model, top k and chunk size. The large amount of supported configurations and overwrite support on Milvus enabled this dynamic experimentation. Critically, we also used TruLens to track and evaluate each experiment, identify and explain new failure modes, and quickly find the most performant combination.
To try it yourself. You can check out open source TruLens and install open source Milvus or Zilliz Cloud.

Keep Reading

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.