




OpenAI CLIPを探る:マルチモーダルAI学習の未来
マルチモーダルAI学習は、テキスト、画像、音声など様々なモダリティからの情報を一緒に入力し理解することができ、世界をより深く理解することにつながります。OpenAIのCLIP(Contrastive Language-Image Pre-training)は、テキストと画像データのための一般的なマルチモーダルモデルです。
シリーズ全体を読む
- OpenAIのChatGPT
- GPT-4.0と大規模言語モデルの秘密を解き明かす
- 2024年のトップLLM:価値あるもののみ
- 大規模言語モデルと検索
- ファルコン180B大型言語モデル(LLM)の紹介
- OpenAIウィスパー高度なAIで音声をテキストに変換する
- OpenAI CLIPを探る:マルチモーダルAI学習の未来
- プライベートLLMとは?大規模言語モデルをプライベートで実行 - privateGPTとその先へ
- LLM-Eval:LLMの会話を評価するための合理的なアプローチ
- CohereのRerankerを使いこなし、AIのパフォーマンスを向上させる
- PagedAttentionを用いた大規模言語モデルサービングの効率的なメモリ管理
- LoRAの説明LLMを微調整するための低ランク適応
- 知識の蒸留:妥当性を犠牲にすることなく、大規模で計算量の多いLLMから小規模なLLMへ知識を移行する
- RouteLLM: LLM展開におけるコストと品質のトレードオフをナビゲートするオープンソースフレームワーク
- 検証者-検証者ゲームがLLM出力の可読性を向上させる
- 金魚のように、暗記をするな!ジェネレーティブLLMで暗記を軽減する
- LLMにおけるメニーショット・インコンテキスト学習のパワーを解き放つ
- 双眼鏡でLLMを発見:機械生成テキストのゼロショット検出
人工知能(AI)は変容しつつあり、新しいアプローチであるmultimodal AI学習へのシフトを目の当たりにしている。これらのシステムは、人間と同じように様々なモダリティから情報を入力し、理解することができる。テキスト、画像、音声を一緒に処理することができ、より洗練された世界の理解につながる。
このマルチモーダル学習変換の最前線には、テキストと画像データのモデルであるOpenAIのCLIP(Contrastive Language-Image Pre-training)がある。CLIPモデルは、clip-vit-base-patch32のような変種を含め、「目」と「舌」の両方を使用できるようにすることで、AI学習を推進し、理解の地平を広げてきた。その進歩は、AIが真に世界を理解できる未来を思い描かせる。
OpenAI CLIPとは?
人工知能(AI)において、マルチモーダルAIが注目されている。OpenAI CLIP(対照言語-画像事前学習モデル)は、自然言語と同様に画像を理解することを目的としています。ImageNetのような一般的なデータセットで作成された画像とキャプションのペアを医療や天文学の画像と関連付けるこのコンセプトは、コンピュータビジョンAIモデルのドメイン固有のトレーニングの必要性を減らしています。エンジニアは、OpenAI CLIPがわずか数例で4万人以上の有名な顔の名前を認識できることを示している。
なぜこれがビッグニュースなのか?OpenAI CLIPの作成に使用された連鎖的な関連付けは、教師なしトランスフォーマーモデルに似たモデルを使用して作成された。そのため、画像に猫のような性質が含まれているかどうかを識別するようなことは可能だが、芸術のスタイルのようなサブテキストレベルで動作するものではミスを犯す。芸術は、有名な名画の数々にわたって比喩や含蓄の深さでユニークに知られているからだ。ビジネスや産業の世界は今、単にデータセットを「解明」するだけのシンプルなブラックボックス・モデルから、モデルが正しく「計算」し、基本的なことを誤解していないことを確認したい世界へとシフトし始めている。OpenAI CLIPが成長し続け、多言語化するにつれて、組織は現実世界をよりよく理解できるマルチモーダルAIに飢えている。例えば、日本のFlickrデータで樹木対女性について議論する性別特有のセンチメントを測定する日本のShinrinyokuプロジェクトは、ほとんどがチームが同様のアプローチを使用することによって推進されている。
背景と開発
シマウマとシマウマの写真の関係を描くことができますか?もちろんできる。では、「小さな白黒のシマウマ」というテキストとシマウマの画像はどうだろう?ほとんどのAIモデルは通常、画像やテキストのような単一のデータモダリティで学習されるため、オープンな領域で質問されると、より難しいタスクになる。OpenAI CLIP、特にclip-vit-base-patch32の変種は、文と画像トークンのペアリングを学習するためにマルチモーダル学習を使用する新しいモデルであり、急速にこの分野の主要なソリューションになりました。
従来の視覚モデルの弱点
これは、以下のような従来の手法の弱点をテストし、克服するために構築された:
**コストのかかるデータセット従来、視覚モデルは人間が注釈を付けたデータセットで学習されるが、これは高価で時間がかかる。OpenAIの例では、ImageNetデータセットは、2,000のオブジェクトカテゴリに対して1,400万枚の画像にラベル付けするために、25,000人以上の作業員を要した。
狭い:Imagenetモデルはかなり狭く、1000のImageNetカテゴリしか知らず、それ以上の一般化はできない。
限定的な実世界適用性:伝統的な視覚モデルは、多くの場合、多様な実世界のシナリオと一致しない可能性のある特定のデータセット上で開発され、訓練されており、潜在的に実用的なアプリケーションで最適なパフォーマンスには至りません。
これらの限界を克服するために、OpenAIチームは異なるアプローチを取りました。CLIPモデルは、インターネットから収集された4億の画像とテキストのペアのデータセットで事前に訓練された。モデル・アーキテクチャは、画像エンコーダーとテキスト・エンコーダーの2つの主要コンポーネントで構成されている。これらのエンコーダーは画像とテキストを共有の高次元埋め込み空間にマッピングする。
学習プロセスでは、対照学習アプローチを使用し、モデルは、一致した画像とテキストのペアの埋め込み間の類似度を最大化する一方で、一致しないペアの類似度を最小化するように学習する。この対照的な目的は、共有された埋め込み空間において、視覚表現とテキスト表現を整合させることを学習するのに役立つ。
CLIPの最も注目すべき特徴の一つは、ゼロショット機能である。CLIPは画像と自然言語の説明を関連付けることを学習するため、画像埋め込みとカテゴリ名や説明のテキスト埋め込みを比較するだけで、明示的に学習していない画像を認識し、カテゴリに分類することができる。この機能は、clip-vit-base-patch32のようなモデルで使用されている高度な画像エンコーダによって実現されています。
CLIPのアプローチは、その後のマルチモーダルAIシステムの開発に影響を与えた。テキスト記述から画像を生成する DALL-E のようなモデルは、視覚的表現とテキスト表現を整合させるという同様の原理に基づいている。ビジョン機能を持つGPT-4やLLaVA(Large Language and Vision Assistant)のような最近のシステムは、これらのアイデアをさらに拡張し、視覚的理解を大規模言語モデルとより深く統合している。これらの進歩は、CLIPの画像エンコーダとテキストエンコーダコンポーネントで行われた基礎的な作業の上に構築されていることが多い。
CLIPは幅広いタスクでゼロショットの性能を示したが、特定のタスク用に微調整された特殊なモデルを常に上回るわけではないことは注目に値する。しかし、その柔軟性、ロバスト性、汎用性により、特に新しいカテゴリーやタスクへの適応性が重要な場合、CLIPは多くのアプリケーションにとって強力なツールとなる。CLIPの画像エンコーダーの汎用性は、clip-vit-base-patch32のようなバリエーションに見られるように、この適応性に大きく貢献している。
CLIP のインパクト
CLIP の影響は画像分類だけにとどまりません。CLIPは画像検索のようなタスクにも使用されており、そこではテキストの記述に一致する画像を見つけることができ、さらにテキストから画像へのモデルにおける画像生成のガイドにも使用されています。学習中に見たことのない画像とテキストの間に意味のあるつながりを作り出すその能力は、視覚領域における創造的なアプリケーションや、より直感的な人間とAIとの相互作用の可能性を開く。
対照的な事前トレーニング](https://assets.zilliz.com/Contrastive_pre_training_c651bea7c2.png)
OpenAI CLIPの能力を探求するための重要な動きとして、研究者は、プロンプトエンジニアリング(または自然言語プロンプト)として知られているテクニックを使用して、その長所と短所の両方を紹介した。
CLIPによるゼロショット学習
ゼロショットであるということは、CLIPが新しいオブジェクトを認識し、その特定の例に関するトレーニングなしに新しい接続を生成できることを意味する。DALL-EやStable Diffusionのような一般的な画像生成モデルは、そのアーキテクチャで画像理解をエンコードするためにCLIPを使用しています。
画像生成モデルのアーキテクチャ](https://assets.zilliz.com/Image_Generation_Model_Architecture_6e47413e2b.png)
旧来のSOTA画像分類モデルの能力は、学習させたデータセットに制限されていました。例えば、ImageNetモデルのゼロショット能力は、学習させた1000クラスの分類だけに制限されています。
他の視覚タスクを実行したい場合は、ImageNetモデルに新しいヘッドを取り付け、ラベル付きデータセットを作成し、モデルを微調整する必要があった。しかしCLIPは、微調整やラベル付きデータを必要とせず、様々なコンピュータビジョンタスクにそのまま使うことができる。
CLIPは、余分な学習データを必要とすることなく、数多くの視覚分類タスクを処理するのに十分な汎用性を持っています。CLIPを異なるタスクに利用するには、タスクに関連する視覚概念をテキストエンコーダに知らせるだけでよい。その結果、CLIPは視覚表現に基づいて線形分類器を生成する。驚くべきことに、この分類器の精度と正確さは、完全な監視で訓練されたモデルに匹敵することが多い。
Unsplashは画像のラベル付けにCLIPを使用しています。異なるデータセットからのいくつかのランダムなサンプルで、CLIPの驚くべきゼロショット予測能力のデモを見ることができる。
画像ラベリング](https://assets.zilliz.com/Image_Labeling_3dd3b4c360.png)
CLIP埋め込み画像の効率的なインデックス付け
CLIPを多数の対象クラスや大規模な画像群を持つデータのゼロショットタスクに使用する場合、手作業で行うと計算資源と時間が枯渇する可能性があります。一方、ベクトルデータベース を使えば、クリップ埋め込み に効率的にインデックスを付けることができます。例えば、UnSplash上の膨大な画像コレクションをカテゴリ別にラベリングすることを考えてみましょう。計算された画像embeddingsは、Zillizのような効率的で多様なベクトルストアに保存することができます!各カテゴリラベルの最も類似した画像ベクトルの上位k個を見つける。
大量のゼロショット画像ラベリングにベクトルストアを使用することは、ZillizのようなベクトルストアがCLIPのような強力なマルチモーダルモデルの真の可能性を十分に活用するのに効率的に役立つ数少ないユースケースの1つに過ぎません。私たちは、意味検索や教師なしデータ探索など、他の多くのユースケースにこのコンボの有用性を拡張することができます!
CLIPの実装:ガイド
HugginFaceの事前に訓練されたCLIPモデルを使って、ゼロショット画像分類を行ってみよう。HFハブはかなりの数の様々な事前訓練されたCLIPモデルのバリエーションをホストしています。ここでは、<openai-/clip-vit-bse-patch32>モデルを使い、MS-COCOデータセットからのサンプラーでtransformersライブラリを使った画像分類を行います。
ステップ1.OpenAI CLIP ViT-Baseモデルは、Hugging FaceのTransformersのようなライブラリを使うことで、以下のコードでロードできる:
from transformers import CLIPProcessor, CLIPModel model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32") processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
ステップ2.次に、以下のコードを実行することで、COCOデータセットからいくつかの画像を取得することができる:
from PIL import Image import requests image_1 = Image.open(requests.get("http://images.cocodataset.org/val2014/COCO_val2014.jpg",stream=True).image_2 = Image.open(requests.get('http://images.cocodataset.org/val2014/COCO_val2014_000000555472.jpg',stream=True).raw) images = \[image_1,image_2].
ステップ 3.出力として画像を視覚化するために、以下は視覚的な出力を持つコード・スニペットです:
import numpy as np import cv2 from google.colab.patches import cv2_imshow def visualize(image): image_arr = np.array(image) image_arr = cv2.cvtColor(image_arr, cv2.COLOR_BGR2RGB) cv2_imshow(image_arr) for img in images: visualize(img).

ステップ 4.このステップでは、以下の簡単なコードを実行することで、CLIPを使って画像に対してゼロショット推論を行うことができます:
classes = \['giraffe', 'zebra', 'elephant'] inputs = processor(text=classes, images=images, return_tensors="pt", padding=True) outputs = model(\**inputs) logits_per_image = outputs.logits_per_image probs = logits_per_image.softmax(dim=1)
ステップ5.最後に、画像の棲み分けを得るために、単純に両方の画像の結果をグラフで視覚化することができます。以下のコードは、グラフ付きの画像の出力を生成します:
以下のコードは、グラフ付き画像の出力を生成します: ``` # 両画像の結果を別々のグラフで可視化 import matplotlib.pyplot as plt # フォントファミリとサイズを設定 plt.rc('font', family='serif', size=12) # 両画像とその確率をループ処理 for i in range(2): # 新しい図を作成 plt.figure(figsize=(12, 4)) # ax1 = plt.subplot(1, 2, 1) ax2 = plt.subplot(1, 2, 2) # 1つ目のサブプロットに画像を表示 ax1.imshow(images[i]) ax1.axis('off') ax1.set_title(f "Image {i+1}") # 2つ目のサブプロットに確率の棒グラフを作成 ax2.bar(classes, probs[i].detach().numpy(), color="navy") ax2.set_xlabel('Class') ax2.set_ylabel('Probability') ax2.set_title(f "Probabilities for Image {i+1}") ax2.grid(True) # プロットを表示する plt.show()
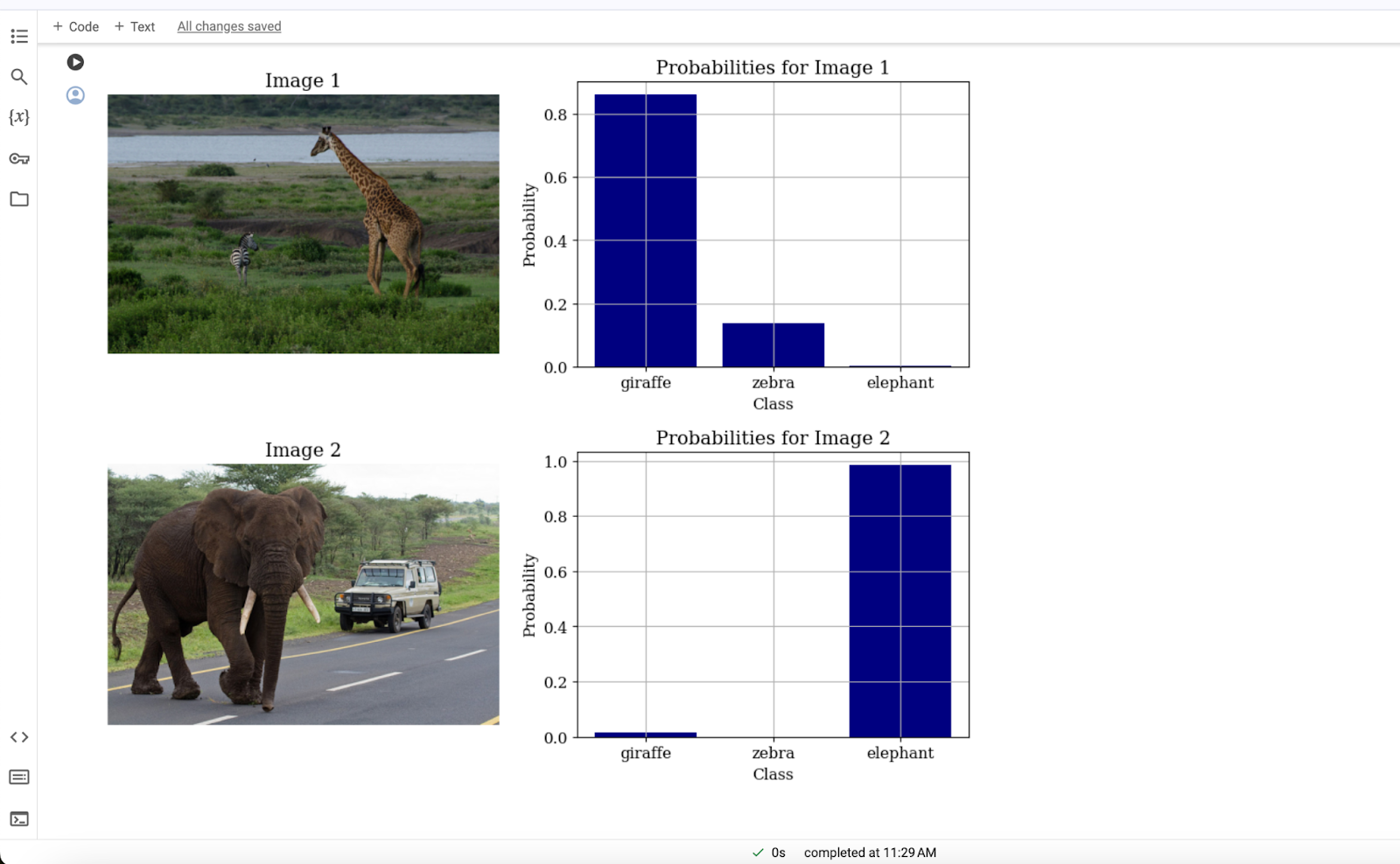
結論
OpenAI CLIPは、マルチモーダルAI学習における革新的なベンチマークである。自然言語処理](https://zilliz.com/learn/introduction-to-natural-language-processing-tokens-ngrams-bag-of-words-models)は、表現力豊かな学習コーパスの利用可能性によりllmsによって進歩したが、CLIPは機械学習における新しいアプローチを示している。これは、クロスモーダルデータのトークンラベルを活用することで、単純なモーダルアーキテクチャをクロストレーニングすることに成功しており、コンピュータビジョン、音声、音声処理領域に焦点を当てた従来の方法論とは対照的である。
CLIPの革新性は、ゼロショット学習とテキストから画像検索への最適化にある。このアプローチにより、このモデルは大規模な事前学習なしに様々な画像分類タスクを実行することができ、この能力は従来のモデルとは一線を画している。テキストから画像への検索時の事前学習プロセスにより、CLIPは多用途でカスタマイズ可能であり、画像検索、医療診断、電子商取引を含む幅広いドメインに適用できる。
CLIPのインパクトは、その直接的な応用にとどまらない。CLIPはAIにおける画期的な進歩への道を開き、安定拡散系列における画像生成モデルなど、その後の技術開発に影響を与えた。機械が視覚情報やテキスト情報をどのように学習し、相互作用するかを変えることで、CLIPは人工知能の技術革新に新たな道を開き、マルチモーダル学習の分野やそれ以外の分野でのエキサイティングな発展を約束した。
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
読み続けて

CohereのRerankerを使いこなし、AIのパフォーマンスを向上させる
検索結果や推薦システムを最適化するための強力なツールであるCohereのRerankerの微調整プロセスに飛び込むことで、AIアプリケーションの可能性を最大限に引き出します。
PagedAttentionを用いた大規模言語モデルサービングの効率的なメモリ管理
PagedAttentionとvLLMは、LLMのサービスにおける重要な課題、特に推論にGPUメモリを使用する際の高いコストと非効率性を解決する。
LLMにおけるメニーショット・インコンテキスト学習のパワーを解き放つ
メニーショット・インコンテキスト学習は、入力コンテキスト内の複数の例を観察することによってモデルが予測を生成するNLPテクニックである。