




大規模言語モデルと検索
ラージ・ランゲージ・モデル(LLM)と検索技術の統合について、ZillizとMilvusによる実際の応用例や進歩を紹介します。
シリーズ全体を読む
- OpenAIのChatGPT
- GPT-4.0と大規模言語モデルの秘密を解き明かす
- 2024年のトップLLM:価値あるもののみ
- 大規模言語モデルと検索
- ファルコン180B大型言語モデル(LLM)の紹介
- OpenAIウィスパー高度なAIで音声をテキストに変換する
- OpenAI CLIPを探る:マルチモーダルAI学習の未来
- プライベートLLMとは?大規模言語モデルをプライベートで実行 - privateGPTとその先へ
- LLM-Eval:LLMの会話を評価するための合理的なアプローチ
- CohereのRerankerを使いこなし、AIのパフォーマンスを向上させる
- PagedAttentionを用いた大規模言語モデルサービングの効率的なメモリ管理
- LoRAの説明LLMを微調整するための低ランク適応
- 知識の蒸留:妥当性を犠牲にすることなく、大規模で計算量の多いLLMから小規模なLLMへ知識を移行する
- RouteLLM: LLM展開におけるコストと品質のトレードオフをナビゲートするオープンソースフレームワーク
- 検証者-検証者ゲームがLLM出力の可読性を向上させる
- 金魚のように、暗記をするな!ジェネレーティブLLMで暗記を軽減する
- LLMにおけるメニーショット・インコンテキスト学習のパワーを解き放つ
- 双眼鏡でLLMを発見:機械生成テキストのゼロショット検出
大規模言語モデル(LLMs)は人工知能の分野を変えた。LLMは膨大な量のテキストデータに対して学習され、人間のような応答を生成する。LLMは、チャットボットから言語翻訳システムに至るまで、様々な用途で目覚ましい汎用性とパワーを発揮している。しかし、その影響が特に顕著な分野は、検索機能の向上である。
情報の量と複雑さが指数関数的に増加し続ける今日のデータ駆動型世界では、高度な検索技術が不可欠だ。Zillizとその代表的なオープンソース製品であるMilvusは、OpenAIのLLMのような生成AIモデルと従来の検索手法との融合を可能にすることで、検索技術を進歩させる上で極めて重要である。Milvusは、多くのベクトル検索アプリケーションに最適なクエリ性能を提供し、大規模な非構造化データを効率的にインデックス化して検索する。Milvusの高度なインデックス作成と検索アルゴリズムは、最新のデータセットの複雑さを処理できるように調整されており、検索アプリケーションでLLMのパワーを活用しようとする組織にとって、Milvusは不可欠なツールとなっています。それでは、LLMが検索とどのように相乗効果を発揮するのか、実際の例をいくつか挙げてみよう。
Milvusによる検索補強型ジェネレーション(RAG)
LLMは、公開されている大量のデータで事前に訓練されているため、テキスト生成のための強力な能力を持っているが、参照するのに十分なデータを持っていないプロンプト(幻覚とも呼ばれる)、またはドメイン固有、専有、またはプライベートな情報の知識が不足しているプロンプトで、でっち上げられた情報を生成するなど、まだ限界がある。MilvusのようなベクトルデータベースはLLMに外部データソースをもたらし、これらの制限を緩和することを目的としている。このようなシステムはRAGと呼ばれている。例えば、Milvusのベクトル検索機能を活用することで、ユーザーは生成モデルを統合して関連するコンテンツ(画像やテキストなど)を生成し、大規模なデータベースから最も類似した結果を素早く見つけることができる。
それでは、Milvus、LlamaIndex、OpenAIを使って、RAGシステムのデモを作ってみましょう。
LlamaIndexは、LLMベースのアプリケーションのためのデータフレームワークであり、より正確なテキスト生成のためにLLMに安全かつ確実に注入するために、プライベートデータやドメイン固有データを簡単に取り込み、構造化し、アクセスすることができる。OpenAIは、人間のようなテキストを生成するように訓練されたLLMです。また、Milvusは信頼性の高いオープンソースのベクトルデータベースです。
実装手順
Zilliz Cloud](https://zilliz.com/cloud)にアクセスし、Starter版で無料サインアップする。その後、クラスタ設定引数(コレクション名、APIキー、URI)をコピーする。その後、Google Colabノートブックを起動し、以下のようにセルに情報を貼り付ける。
# Zillizクラウドのセットアップ引数
COLLECTION_NAME = 'RAG' # 任意のコレクション名
URI = 'https://in03-277eeacb6460f14.api.gcp-us-west1.zillizcloud.com' # Zilliz Cloudから取得したエンドポイントURI
API_KEY = 'あなたのキー' # こちらもZilliz Cloudから取得
現在、大規模な言語モデルと対話する一般的な方法は、図1に示すように、LLMが答えを返すようにプロンプトを入力するチャットインターフェースを使用します。
図1.LLMとのインタラクションのフローチャート](https://assets.zilliz.com/Fig_1_A_flowchart_of_user_interaction_with_an_LLM_fdb98a54f1.png)
しかし、LLMが直面する幻覚、限られたドメイン知識などの課題から、私たちは下図のようなRAGシステムを実装し、より良いパフォーマンスのために外部データを追加します。Colab notebook](https://colab.research.google.com/drive/1aQd1MQJx-ElvrVDqTM9md_Nf-AbHV5uk#scrollTo=lVSHOYnyrn0W)上のコード例を含むフローチャートを分解してみよう。
図2 RAGシステムにおけるLLMとのインタラクションのフローチャート.png](https://assets.zilliz.com/Fig_2_A_flowchart_of_user_interaction_with_an_LLM_in_a_RAG_system_ddf6d62c5d.png)
図2を見ると、ユーザがプロンプトを出す。そして、そのプロンプトはベクトルデータベースに渡され、既存の外部データとの類似性検索が行われる。ここでインデックス作成が行われる。索引付けとは、データをより簡単に、より速く検索できるように整理し、構造化することである。例えば、Milvusは効率的な類似検索のためにフィールド値をソートするためのいくつかのインデックスタイプを提供しています。Zilliz Cloudでは、インデックスがあなたの代わりに作成されます(autoindex)。また、3つのメトリックタイプを提供します:コサイン類似度(COSINE)、ユークリッド距離(L2)、内積(IP)の3つのメトリックがあり、図3のようにZilliz Cloud上で設定したり、Python, NodeJS, Java, Goなどのプログラミング言語を使って設定することができます。
図3 Zilliz Cloudからスキーマを作成する.png](https://assets.zilliz.com/Fig_3_creating_a_schema_from_Zilliz_Cloud_97ad9f05fc.png)
Zillizでクエリ理解を深める
プロンプトと関連データをMilvusに取り込んだら、次のステップは自然言語処理(NLP)機能を活用してクエリ理解を強化することである。例えば、Milvusにはadvanced indexing techniquesが搭載されており、意味的な類似性を検索することができる。ユーザが文書について質問すると、Milvusはベクトル表現に符号化された意味的類似性に基づいて類似文書を検索する。これにより、問い合わせ処理中に関連文書が考慮されることが保証される。以下はZilliz Cloudの説明図である。図4は、Milvusに取り込んだデータの一部を、先ほど共有したコラボ・ノートブックに埋め込んだ例である。図4の内容を参考に、文書の最も関連性の高い部分を照会したいとします。Milvusではベクトル検索ができる。
図4 Zilliz Cloud上でのベクトル類似度検索.png](https://assets.zilliz.com/Fig_4_Vector_similarity_search_on_Zilliz_Cloud_6ac0c67623.png)
ベクトル検索をクリックすると、図5に示すように、Milvusが検索したベクトル表現に符号化された意味的類似性に基づき、上位K個の関連文書を選択することで、ベクトルによるクエリ検索を行うことができ、クエリの理解度を高め、より正確な情報検索を促進することができる。
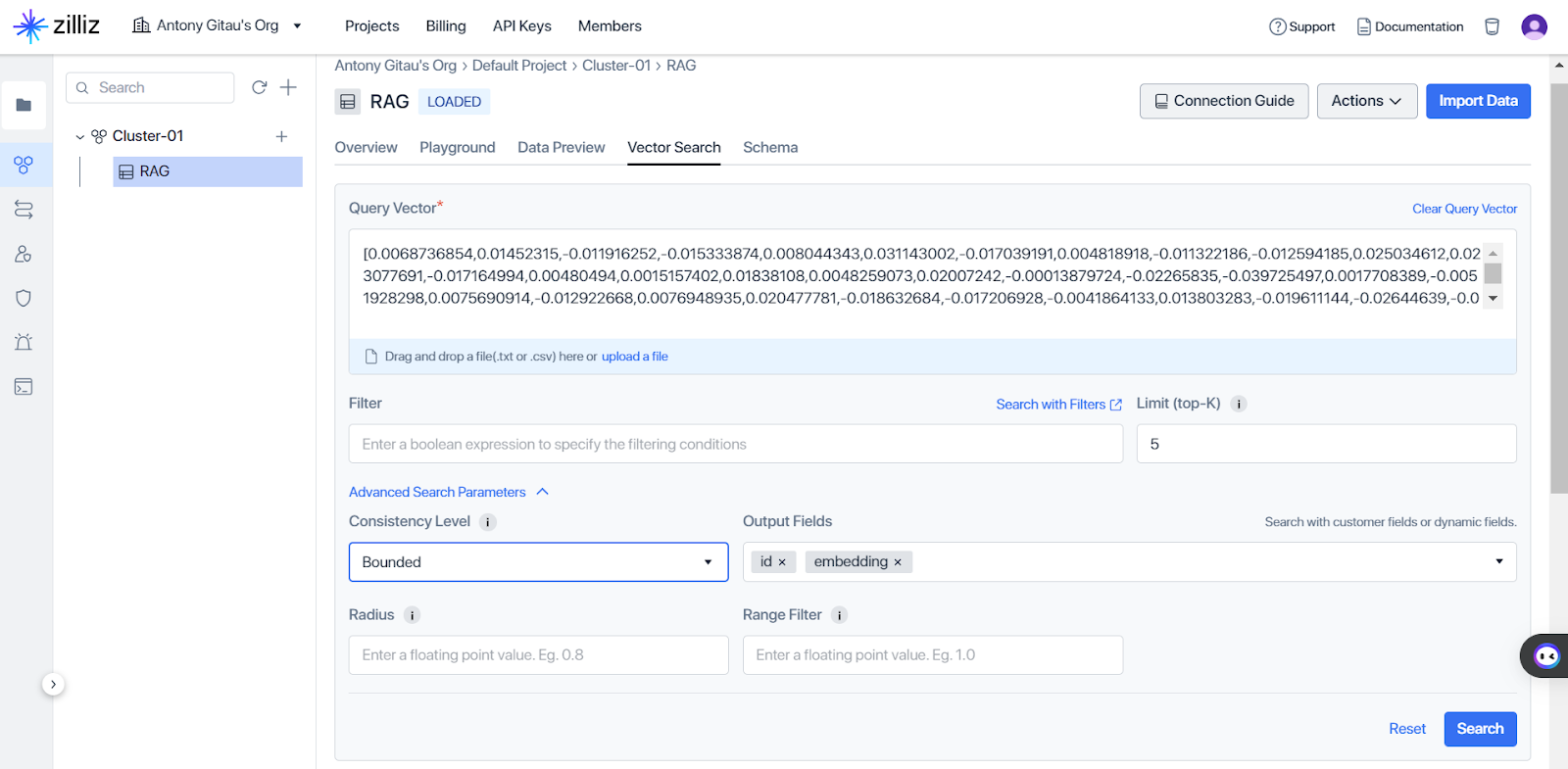 図5 ベクトル類似検索の構成.png
図5 ベクトル類似検索の構成.png
検索を実行した後、Milvusは図6に示すように、最も関連性の高い上位5つの文書を取得することができる。図2で見たように、ベクトル・データベースで起きているベクトル類似性の結果は、ユーザーのクエリをより多くの文脈で補強することにより、クエリを強化する。これは、ベクトルデータベースを持たない図1のセットアップと比較して、より多くの違いを生み出します。このベクトル検索操作は、Milvusのsearchとqueryのドキュメントに記載されているように、Python、Node.js、GO、Javaなど、Zilliz Cloudがサポートするプログラミング言語のいずれかを使用して実行できることに注意することが重要である。
図6 ベクトル検索の結果.png](https://assets.zilliz.com/Fig_6_Results_of_the_vector_search_5086b39af6.png)
Zilliz Technologiesによる検索結果の再ランク付け
先に見たコード例では、検索に単一の文書を使用した。しかし、実世界の多くのケースでは、LLMからより良い回答を得るために、プロンプトを文脈化するために多くの文書を補強することができる。複数の文書がある場合、どの文書を使えばモデルが最も文脈を理解しやすいか、という課題が生じる。そこで、ランキングの考え方が登場する。リランカーは検索結果を評価し、特定のクエリとの関連性を高めるために並び替える。そこで、rerankerは、図7に示すように、最も関連性の高い文書のリストを選択し、それらを使って文脈化されたクエリを作成する。
 図7 リランカーによるRAGの最適化.png
図7 リランカーによるRAGの最適化.png
LLMとMilvusによる検索結果の最適化
リランキング以外にも、Milvusには検索結果を最適化するテクニックがある。LLMでは大量のデータが生成されることが多く、保存や検索に困難が伴うことがあるため、Milvusは量子化や刈り込みなどの圧縮技術をサポートし、検索精度を大きく犠牲にすることなくベクトルの保存容量を削減します。量子化はベクトル成分の精度を下げ、プルーニングは関連性の低い成分を除去し、ストレージと検索効率を最適化します。
ZillizとMilvusのフレームワークと今後の展望
MilvusやLLMベースのアプリケーションのようなベクトルデータベースの将来は、大幅な技術的進歩と産業界の需要の高まりによって決まる。Zilliz](https://zilliz.com/learn/Building-Scalable-AI-with-Vector-Databases-A-2024-Strategy)に掲載されたベクトルデータベースの探求に関する2024年戦略ブログによると、継続的な研究開発努力により、ベクトルデータベース内のアルゴリズム効率、ストレージ最適化、クエリ処理機能が強化され、特殊なハードウェアアクセラレータによって支援される可能性が期待されている。同時に、さまざまな分野でAIの導入が進むことで、スケーラブルなソリューションに対する需要が高まり、ベクトルデータベースはデータ分析と洞察の導出のための極めて重要なツールとして位置づけられる。ベクトル・データベースと、グラフベース・データベースや連合学習フレームワークのような新技術との融合は、より総合的なAI主導の意思決定への期待を抱かせる。さらに、深層学習や強化学習などの機械学習技術の進歩は、ベクトルデータベースの能力をさらに増強し、AIアプリケーションの革新と発見を促進する可能性が高い。
ZillizとMilvusによる検索テクノロジーの進化は、単なる受動的なプロセスではない。テクノロジーの専門家であり研究者である皆さんもその一員なのです。この旅は、高度にパーソナライズされた、マルチモーダルかつインテリジェントな検索体験を可能にし、業界に大きな変革をもたらすでしょう。高度なLLMとスケーラブルなベクトルインデックス機能を活用することで、検索エンジンは、ますます複雑化し相互接続された世界において、情報をナビゲートしアクセスするための不可欠なツールとなるでしょう。この旅に積極的に参加し、最新の開発情報を入手するには、Milvus Discord channel に参加してエンジニアやコミュニティと直接交流してください。
まとめ
本ブログでは、大規模言語モデル(Large Language Models: LLM)の統合による検索技術の強化について、ZillizとMilvusの能力を探ってきました。ZillizのNLPの能力とMilvusの効率的なインデックス作成と検索アルゴリズムを活用することで、検索結果を最適化し、クエリの理解を向上させる方法を見てきた。RAGのコンセプトを通じて、生成AIモデルと従来の検索手法を組み合わせることで、いかに優れた結果をもたらし、ユーザーが関連するコンテンツに迅速かつ正確にアクセスできるかを実証しました。我々は、ベクトル表現の取り込み、保存、検索を容易にするMilvusの役割を強調し、Zillizは意味解析、エンティティ認識、意図分類を通してクエリ理解を豊かにする。
リソース
- Milvusベクトルデータベースとは - The New Stack](https://thenewstack.io/what-is-milvus-vector-database/)
- MilvusとLlamaIndexによる検索補強型生成(RAG)](https://milvus.io/docs/integrate_with_llamaindex.md)
- リランカーによるRAGの最適化: 役割とトレードオフ - Zilliz blog](https://zilliz.com/learn/optimize-rag-with-rerankers-the-role-and-tradeoffs)
- 効果的なRAG:LLMのための高品質コンテンツの生成と評価](https://youtu.be/7dcfB8nXmds)
- 5mのLangChainとMilvusでオープンソースチャットボットを構築する - Zillizブログ](https://zilliz.com/blog/building-open-source-chatbot-using-milvus-and-langchain-in-5-minutes)
- LLMのグラウンディング - マイクロソフトコミュニティハブ](https://techcommunity.microsoft.com/t5/fasttrack-for-azure/grounding-llms/ba-p/3843857)
- Zilliz無料ティアを使ったReadtheDocs検索拡張生成(RAG)](https://github.com/milvus-io/bootcamp/blob/master/bootcamp/RAG/readthedocs_zilliz_langchain.ipynb)
- VectorDBBench: Open-Source Vector Database Benchmark Tool - Zilliz blog](https://zilliz.com/learn/open-source-vector-database-benchmarking-your-way)
- LangChainを使ったベクターデータベースのセルフクエリ - Zillizブログ](https://zilliz.com/blog/using-langchain-to-self-query-vector-database)
- OpenAIのChatGPT - Zillizブログ](https://zilliz.com/learn/ChatGPT-Vector-Database-Prompt-as-code)
- Vector Index Milvus v2.0.xドキュメント](https://milvus.io/docs/v2.0.x/index.md)

読み続けて
知識の蒸留:妥当性を犠牲にすることなく、大規模で計算量の多いLLMから小規模なLLMへ知識を移行する
知識蒸留とは、大規模で複雑なモデル(教師)の知識を、より小規模で単純なモデル(生徒)に転送する機械学習手法である。

RouteLLM: LLM展開におけるコストと品質のトレードオフをナビゲートするオープンソースフレームワーク
RouteLLMはオープンソースのフレームワークで、開発者はコスト、レイテンシ、精度に基づき、タスクを最適なLLMに効率的にルーティングできる。

金魚のように、暗記をするな!ジェネレーティブLLMで暗記を軽減する
金魚の損失技術は、標準的なネクストトークン予測の学習目的を変更することで、LLM出力における学習データの逐語的な再現を防ぐ。