金魚のように、暗記をするな!ジェネレーティブLLMで暗記を軽減する
金魚の損失技術は、標準的なネクストトークン予測の学習目的を変更することで、LLM出力における学習データの逐語的な再現を防ぐ。
シリーズ全体を読む
- OpenAIのChatGPT
- GPT-4.0と大規模言語モデルの秘密を解き明かす
- 2024年のトップLLM:価値あるもののみ
- 大規模言語モデルと検索
- ファルコン180B大型言語モデル(LLM)の紹介
- OpenAIウィスパー高度なAIで音声をテキストに変換する
- OpenAI CLIPを探る:マルチモーダルAI学習の未来
- プライベートLLMとは?大規模言語モデルをプライベートで実行 - privateGPTとその先へ
- LLM-Eval:LLMの会話を評価するための合理的なアプローチ
- CohereのRerankerを使いこなし、AIのパフォーマンスを向上させる
- PagedAttentionを用いた大規模言語モデルサービングの効率的なメモリ管理
- LoRAの説明LLMを微調整するための低ランク適応
- 知識の蒸留:妥当性を犠牲にすることなく、大規模で計算量の多いLLMから小規模なLLMへ知識を移行する
- RouteLLM: LLM展開におけるコストと品質のトレードオフをナビゲートするオープンソースフレームワーク
- 検証者-検証者ゲームがLLM出力の可読性を向上させる
- 金魚のように、暗記をするな!ジェネレーティブLLMで暗記を軽減する
- LLMにおけるメニーショット・インコンテキスト学習のパワーを解き放つ
- 双眼鏡でLLMを発見:機械生成テキストのゼロショット検出
大規模言語モデル(LLM)は、人間の文章を忠実に模倣したテキストを作成する上で、非常に効果的であることが証明されている。しかし、LLMは学習データを記憶し、逐語的に(元々使われていた単語をそのまま)再現する可能性があり、プライバシー、著作権、セキュリティの懸念につながる。
差分プライバシーやデータ重複排除のような既存のアプローチには、モデルの実用性を損なったり、リソースを大量に消費したりするなどの限界がある。ドロップアウトやノイズ加算のような他の正則化手法は、LLMの記憶化を防ぐには不十分である。
これらの制限を克服するために、Goldfish Lossは、モデルの性能を維持しながら、記憶化を減らすためのシンプルでスケーラブルなアプローチとして提案されています。Goldfish Lossは、正確なトレーニングシーケンスを再現するリスクを最小化することで、LLMの開発と展開において、著作権とプライバシーの遵守を保証するのに役立ちます。
Goldfish Lossは、訓練中にトークンのサブセットを損失計算からランダムに除外することで実装され、モデルに記憶ではなく汎化を強いる。しかし、データ抽出のリスク、特にビームサーチやメンバーシップ推論のような高度な攻撃のリスクを完全に排除することはできない。したがって、Goldfish Lossは、LLMにおける記憶リスクを軽減するための数あるツールの中の1つと考えるべきである。
図-標準モデルは原文(赤)を再生成するが、金魚モデルは再生成しない](https://assets.zilliz.com/Figure_The_standard_model_regenerates_the_original_text_red_while_the_goldfish_model_does_not_96c3a6da63.png)
図:標準モデルは原文(赤)を再生するが、金魚モデルは再生しない。(Source)_
このブログでは、金魚ロスのメカニズム、マスキング戦略、モデル記憶への影響について説明する。包括的な理解については、【金魚ロス論文】(https://arxiv.org/pdf/2406.10209)をご参照ください。
LLM暗記のリスク
大規模言語モデル(LLM)が学習データを記憶し、その後に逐語的に再現することには複数のリスクが伴う。これらのリスクは、著作権の問題とプライバシーの問題に分類することができる。
著作権侵害
LLMは著作権で保護されたコンテンツをそのまま再生することができるため、LLMの提供者と利用者の双方にリスクが生じる。
著作権で保護されたコンテンツを含む出力は、特にそのような素材が商業的に使用されたり、適切な許可なく配布された場合、意図しない法的問題を引き起こす可能性があります。
保護されたコンテンツを再生成できるモデルをホストし、配布することは、未解決の法的課題を提起する。この問題は、コードモデルについて特に懸念される。逐語的なコードの再利用は、商用利用が制限されているオープンソースコードであっても、ライセンス契約に影響を与える可能性があります。
プライバシー侵害
暗記は個人を特定できる情報(PII)や、学習データに含まれるその他の機密データを暴露する可能性があります。推論](https://zilliz.com/blog/embedding-inference-at-scale-for-RAG-app-with-ray-data-and-milvus)の際に、LLMがそのような情報を含む学習データセグメントを複製した場合、重大なプライバシー侵害となる。
金魚の損失アプローチの詳細
Goldfish Lossは大規模言語モデル(LLM)における記憶の問題に対処するテクニックである。標準的なネクストトークン予測の学習目的を変更することで、学習データの逐語的な再現を防ぐことに焦点を当てています。
ここでは、金魚ロスのメカニズムについて順を追って説明します。
1.フォワードパス
標準的なトレーニングと同様に、プロセスはトレーニングバッチ内のすべてのトークンに対するフォワードパスから始まります。モデルは入力シーケンス全体を処理し、後続の各トークンについて予測を生成する。
2.金魚マスクの導入
ゴールドフィッシュ・マスク** Gは、訓練中に入力シーケンスに適用される。このマスクは2値ベクトルである:
値1は対応するトークンが損失計算に使われることを示す。
0はそのトークンが損失計算の際に無視されることを示す。
3.損失計算
次にモデルは、金魚マスクで 1 と指定されたトークンに対してのみ、次のトークン予測損 失を計算します。マスクされたトークン(0 と表示)は除外されます。これにより、モデルはこれらのトークンの予測を学習することができません。金魚ロスの式を以下に示す:
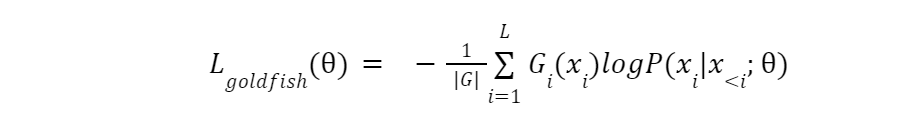 equation.png
equation.png
4.バックワードパス
モデルは計算された損失に基づいて、バックワードパス中にパラメータを更新する。ただし、損失計算に含まれるトークンだけが更新に影響する。除外されたトークンはモデルの学習に影響を与えない。
5.推論への影響
推論中、モデルはシーケンス内のすべてのトークンを予測する必要があります。モデルはこれらの特定のトークンを予測するようにトレーニングされたことがないため、教師なし推測を行うために周囲の文脈の理解に頼らなければならない。このため、モデルは訓練データのシーケンスから乖離せざるを得ず、逐語的な再現の可能性が低くなります。
金魚マスク生成戦略
金魚マスクの生成には様々な戦略がある。
静的マスク
スタティック・マスクは最も単純な方法で、k番目のトークンはすべて削除される。例えば、k=4の場合、4番目のトークンはすべてマスクされる。しかし、この戦略は学習データ中の重複する文章に対してロバストではない。
ランダムマスク
ランダムマスクは各トークンを1/kの確率で削除する。これは学習プロセスにランダム性を導入するものであるが、重複通過の問題には対処できず、暗記の余地を残すものである。
ハッシュマスク
ハッシュマスクは推奨される方法である。ハッシュ関数](https://zilliz.com/learn/mastering-locality-sensitive-hashing-a-comprehensive-tutorial) を使って、先行するトークンの固定長コンテキストウィンドウ h に基づいて、どのトークンを除外(マスク)するかを決定する。これにより、特定のパッセージが学習データに現れるたびに、異なるコンテキストであっても、同じトークンがマスクされるようになる。
ハッシュ関数はh個のトークンのシーケンスを実数にマップする。ハッシュ関数の出力が1/kより小さい場合、対応するトークンはマスクされる。この戦略は、静的マスクやランダムマスクの限界に対処するものである。
コンテキスト幅hの選択は、モデルが何を記憶するかに影響するので重要である。
hが小さすぎると、モデルは重要な短いフレーズを記憶しないかもしれない。
hが大きすぎると、ハッシュ関数が文書の最初のトークンに効かなくなる可能性がある。
推奨される設定の一つは、ハッシュ化の前にテキストを正規化することである。これは、ハッシュ出力に影響を与える可能性のある、異なるタイプの空白やダッシュなどの表現の不一致を避けるのに役立つ。
暗記メトリクス:暗記の度合いを測る
言語モデルがどれだけ学習データを記憶しているかを定量化するために、2つの主要なメトリクスが使用されます。
RougeL Score: このメトリクスはRouge(Recall-Oriented Understudy for Gisting Evaluation)メトリクスファミリーから派生したものです。これは、生成されたテキストとグランドトゥルーステキスト間の最長共通部分配列(LCS)を測定します。スコアは0から1の範囲で、1は完全な記憶であることを示す。これはモデルがグランドトゥルースのシーケンスをそのまま再現したことを意味する。RougeL のスコアが高いほど、より高度に記憶されていることを示す。
Exact Match Rate:**この指標は、生成された配列が対応するグランドトゥルースの配列と完全に一致する割合を計算します。完全一致率100%は、評価された一連の配列が完全に記憶されていることを示す。
これらのメトリクスは、モデルが正確なテキストを複製する、構文的な暗記に重点を置いています。しかし、モデルは、学習データに埋め込まれた知識を学習して保持し、正確な表現を使用することなく、言い換えられたり言い換えられたりした形でそれを再現する、意味的な暗記を示す場合もあります。
意味記憶.png](https://assets.zilliz.com/Semantic_memorization_d308a21ec3.png)
図:意味記憶|出典
BERTScoreは、BERTの埋め込みに基づくスコアである。スコアが高いほど、グランドトゥルースとの意味的類似性が高いことを示す。
Key Training Setups:多様なシナリオにおける金魚ロスの評価
LLMの暗記防止におけるGoldfish Lossの有効性を評価するために、2つの主要なトレーニングセットアップを使用した。これらのセットアップは、モデルサイズ、データセット構成、トレーニング期間が異なり、極端なトレーニング条件と標準的なトレーニング条件でテストされた。
極端な記憶化シナリオ
このセットアップでは、LLaMA-2-7Bモデルを、100個のWikipedia 記事からなる小さなデータセットで100エポック学習させた。金魚ロスk=4は学習データの逐語的記憶を完全に防ぐ。一方、標準的な損失関数で学習したモデルは、100記事のうち84記事を記憶した。この差は、意図的に暗記を促すような極端な条件下でも、暗記を防ぐというGoldfish Lossの有効性を浮き彫りにしている。
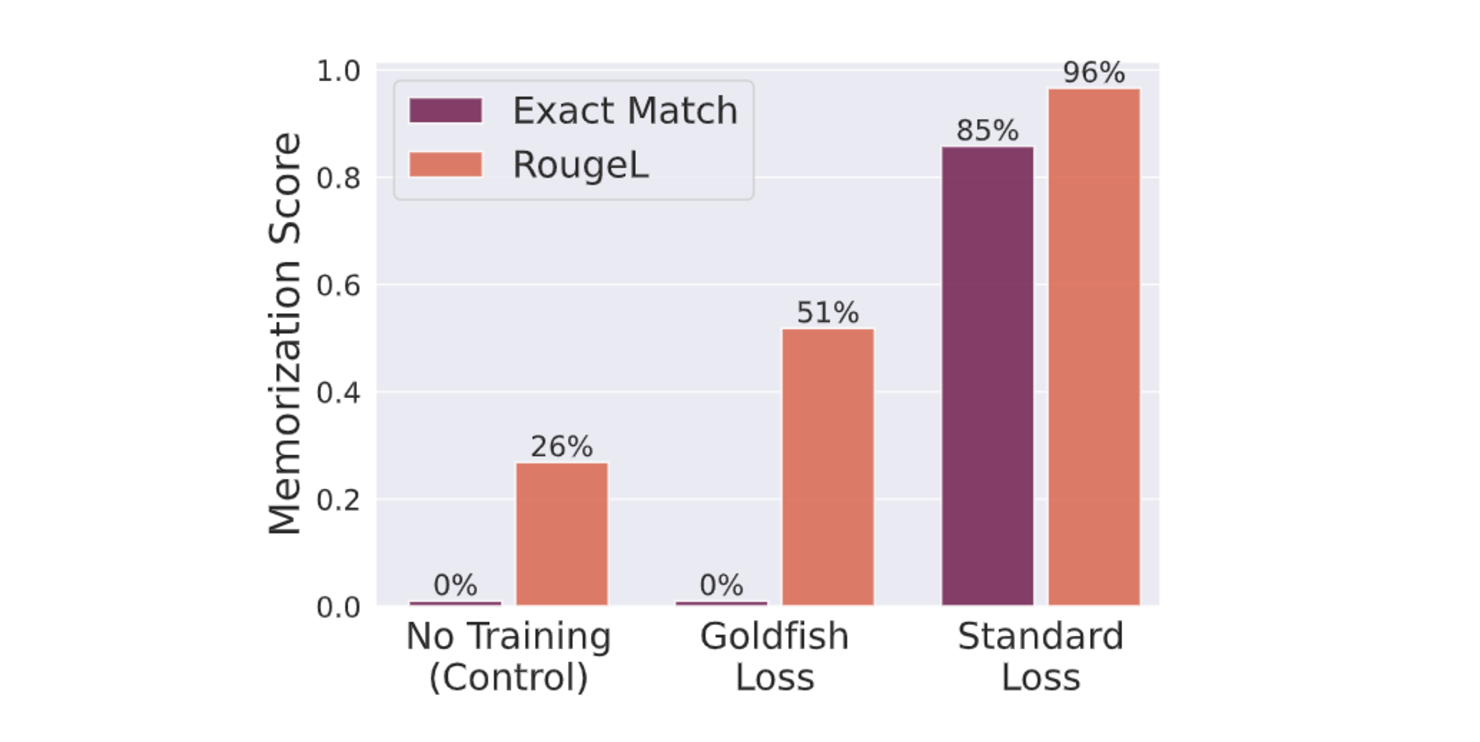 図-訓練における金魚ロスで完全一致とRougeLのスコアの減少が観察された.png
図-訓練における金魚ロスで完全一致とRougeLのスコアの減少が観察された.png
図:訓練で金魚がいなくなると、完全一致とRougeLのスコアが低下する|出典
標準訓練シナリオ
このセットアップでは、より実際のLLMトレーニングに近い条件下で金魚ロスのパフォーマンスを評価します。TinyLLaMA](https://zilliz.com/learn/mastering-locality-sensitive-hashing-a-comprehensive-tutorial)-1.1Bモデルを、より大規模で多様なデータセットでトレーニングする。このデータセットには、RedPajamaのサブセット、大規模なオープンソースの言語モデルdataset、2000のWikipediaのシーケンスのセットが含まれる。
2000のWikipediaシーケンスからなるターゲットセットは、データセットに重複またはそれに近いエントリが含まれることが多い実世界のシナリオをシミュレートするために、学習データ内で意図的に50回繰り返されている。Goldfish Lossで訓練されたモデルは、ターゲット配列で訓練されていない対照モデルと同等のRougeL暗記スコア分布を示した。これは、Goldfish Lossがモデルの実用性を維持しつつ、現実的な訓練シナリオにおいて効果的に暗記を制限することを示している。
図- 学習後の対象文書に対するRougeL暗記スコアの分布](https://assets.zilliz.com/distribution_of_Rouge_L_1ea619df41.png)
図学習後の対象文書に対するRougeL暗記スコアの分布|出典
金魚ロスの影響分析
Goldfish Lossはダウンストリームベンチマークのパフォーマンスとモデルの全体的な言語モデリング能力に大きな影響を与える。さらに、このモデルは敵対的な抽出手法に弱いため、その有効性と信頼性が問われます。
ダウンストリームベンチマーク性能への影響
質問応答、自然言語推論、コモンセンス推論など、様々なベンチマークタスクでGoldfish Lossの影響を評価しました。評価にはHuggingFace Open LLM Leaderboardを使い、モデルを比較した。Goldfish Lossで事前に訓練されたモデルは、コントロールや標準的な損失関数で訓練されたモデルと同様の性能を示した。この結果は、Goldfish Lossがモデルの一般的な言語理解と問題解決能力の学習能力を損なわないことを示している。
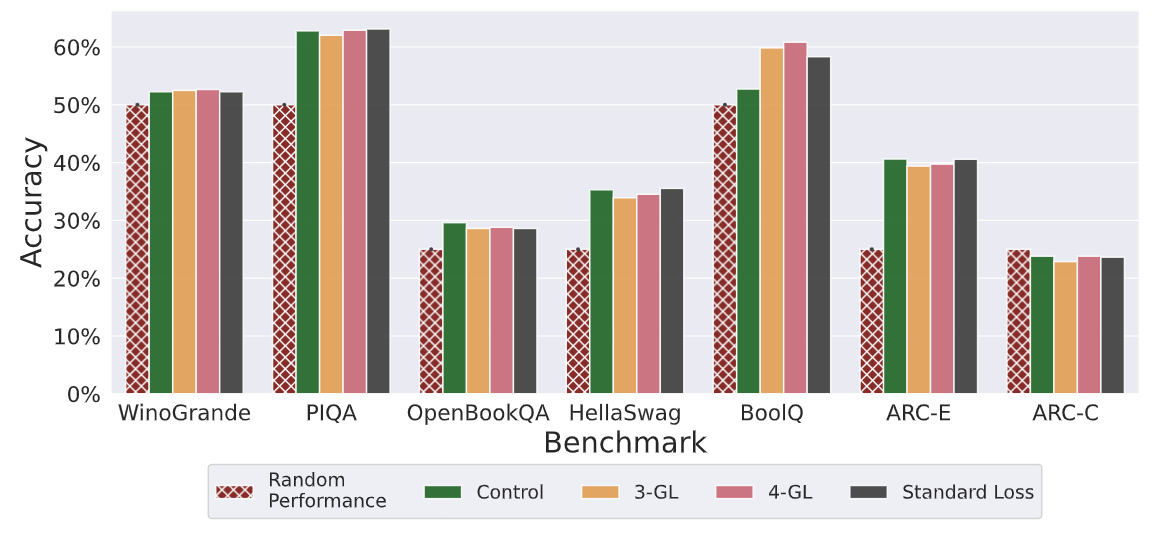 図- ᑘ値の異なるベンチマーク性能は、下流のタスクにおいて一貫性を示した.png
図- ᑘ値の異なるベンチマーク性能は、下流のタスクにおいて一貫性を示した.png
図:異なるᑘ値にわたるベンチマーク性能は下流タスクで一貫性を示した|出典
言語モデリング能力への影響
Goldfish Lossは教師あり学習に使用されるトークン数を効果的に削減し、モデルの言語モデリング能力に影響を与えます。この影響は、事前学習中の検証損失を分析し、Mauveスコアを用いてモデルのテキスト生成品質を評価することで評価される。
検証損失
検証損失曲線の分析から、同じ入力トークン数を考慮した場合、金魚損失モデルは標準損失モデルと比較して学習進行がわずかに遅いことがわかる。しかし、教師付きトークン(損失計算に使われるトークン)の数で比較すると、検証損失曲線は収束する。金魚モデルは、同等の教師付き訓練データが与えられた場合、標準モデルと同等の性能を発揮することができる。
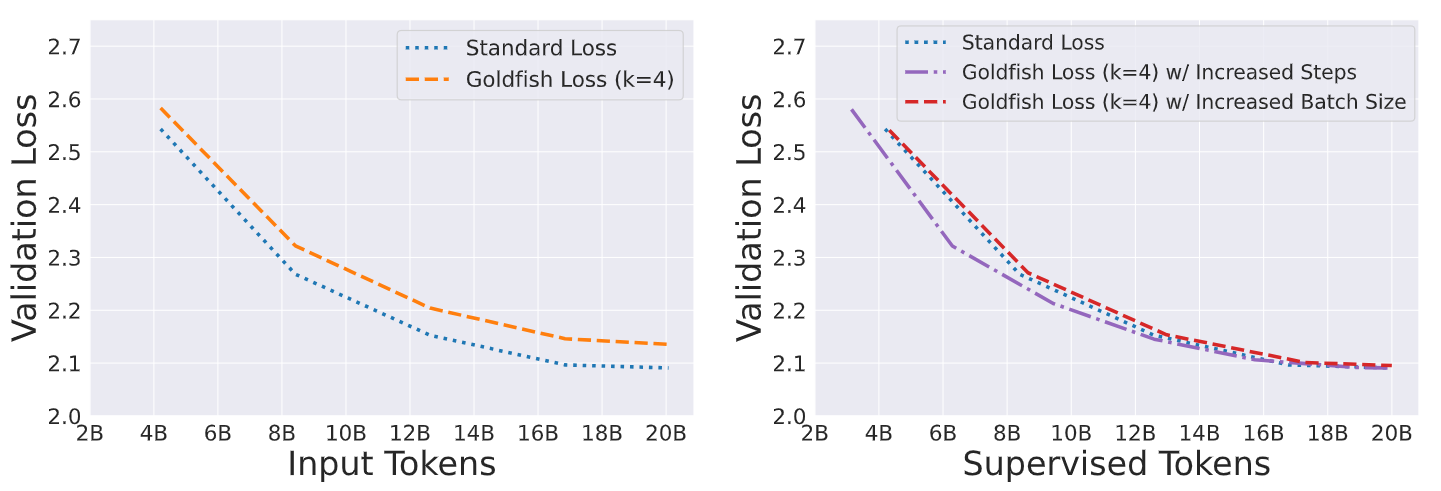 図-プリトレーニング中の検証損失曲線.png
図-プリトレーニング中の検証損失曲線.png
図:プレトレーニング中の検証損失曲線|出典
モーヴスコア
Mauveスコアは、多様性と自然さの観点から実際のテキストと比較することで、生成されたテキストの品質を測定します。これは、文法的に正しく、意味的に健全なテキストを生成するモデルの能力の指標となる。Mauveスコアの評価から、Goldfish Lossで学習したモデルは、標準的な損失やコントロールモデルで学習したモデルと同等の品質のテキストを生成したことがわかる。この結果はさらに、金魚ロスが流暢で首尾一貫したテキストを生成するモデルの能力を著しく妨げるものではないことを示している。
 図-異なるサンプリング戦略の下で、金魚ロスで訓練したモデルのモーブスコア.png
図-異なるサンプリング戦略の下で、金魚ロスで訓練したモデルのモーブスコア.png
図:異なるサンプリング戦略下で金魚の損失で訓練されたモデルのモーヴスコア| 出典
敵対的な抽出方法に対する金魚ロスの回復力の評価
Goldfish Lossは標準的な条件下で効果的に記憶を減らす。しかし、モデルから記憶された情報を抽出する、より高度な方法(敵対的な試み)に対する頑健性もテストされた。つの主要な攻撃戦略が検討された:
メンバシップ推論攻撃(MIAs)
ビームサーチ攻撃
メンバーシップ推論攻撃(MIAs)
MIAsは、特定のシーケンスがモデルのトレーニングデータの一部であったかどうかを判断することを目的としている。これらの攻撃は、モデルが訓練データと未知のデータに遭遇したときに異なる動作をするという観察を利用します。攻撃者は、このような違いを利用することができます:
予測信頼度(損失):***モデルは訓練中に見たトークンに高い信頼度を割り当てるかもしれません。
圧縮性(Zlib Entropy):** 訓練データは未見データよりも予測可能で圧縮可能な出力を生成する傾向があります。
金魚の損失は、標準的な訓練に比べてMIAの有効性を低下させる可能性がある。しかし、これらの攻撃は、特にZlib基準を使用する場合、訓練サンプルの識別において有意な精度を達成することができます。このことは、金魚の損失は逐語的な記憶には抵抗するが、MIAが悪用できる訓練データの痕跡を完全に除去するものではないことを示している。
図-メンバシップ推論攻撃.png](https://assets.zilliz.com/Figure_Membership_inference_attack_7285855ca1.png)
図-メンバーシップ推論攻撃メンバーシップ推論攻撃|出典
ビームサーチ攻撃
この攻撃戦略には、ビームサーチアルゴリズムを使用することが含まれる。これは生成されたシーケンスを繰り返し改良し、モデルの当惑度に基づいて最も可能性の高い候補を選択することで、元のトレーニングサンプルを再構築しようとするものである。金魚の損失は訓練中にトークンのサブセットをマスクするだけなので、攻撃者はマスクされていないトークンと周囲の文脈に関するモデルの知識を利用してビーム探索プロセスを導くことができる。
マスクされたトークンの様々な組み合わせを探索することで、攻撃者はモデルの当惑度を下げるシーケンスを見つけようとする。これは、元の学習サンプルに似ている可能性が高いことを示唆している。マスキング比率が高くなる(↪Ll_1458 が高くなる)と、マスキングされるトークンの数が増えるため、攻撃者はビーム探索中にシーケンスを操作する自由度が高くなる。しかし、低いマスキング比(k=3)のGoldfish Lossはビーム探索攻撃に抵抗した。このことは、攻撃者が訓練サンプルを再構築する能力に大きく影響する。
図- ビームサーチ攻撃.png](https://assets.zilliz.com/Figure_Beam_search_attacks_f4006e435e.png)
図ビームサーチ攻撃|出典
金魚ロスの意味するもの
金魚の損失技術は、単に学習データの逐語的な繰り返しを減らすだけでなく、モデルの学習、パフォーマンス、セキュリティの様々な側面に影響を与えます。
著作権とプライバシー保護の可能性:**金魚ロス技術は、LLMに関連する著作権侵害やプライバシー侵害をめぐる懸念の高まりに直接対応します。この技術により、学習データの逐語的複製の可能性を低減します。クリエイターの知的財産を保護し、機密性の高い個人情報の漏洩を防ぎます。
LLMトレーニング慣行への影響:**金魚ロスの導入は、LLMトレーニング慣行の変更の必要性を示している。開発者は、トレーニングステップ数やバッチサイズを調整することで、トレーニング手順を適応させる必要があるかもしれない。この調整は、損失計算に使用されるトークン数の減少を考慮するために必要である。
包括的なセキュリティ評価の必要性:**大規模言語モデル(LLM)のセキュリティを評価する際には、様々な潜在的な攻撃を考慮する必要があります。金魚の損失のような技術は逐語的暗記のリスクを減らすのに役立ちますが、メンバシップ推論攻撃やビーム検索のような、より高度な脅威からは保護できない可能性があります。このことは、直接的な繰り返しをチェックするだけでなく、徹底したセキュリティ評価の必要性を強調している。
結論と今後の研究の方向性
金魚ロス(Goldfish loss)は、大規模な言語モデルにおける暗記を軽減するためのシンプルかつ効果的な手法である。学習中に選択的にトークンを削除することで、金魚の損失は、機密データを直接再現するリスクを最小限に抑えるのに役立つ。同時に、下流のタスクにおけるモデルの性能をほぼ維持することができる。高度な攻撃から免れることはできませんが、モデルの能力と責任あるデータの取り扱い方法のバランスを取ることが非常に重要です。
金魚ロスに関する今後の研究の方向性
金魚の損失に関する今後の研究には、いくつかの有望な方向性がある。
より大きなモデルへのスケーラビリティ:**言語モデルのサイズが大きくなるにつれて、学習データを記憶する傾向が強くなる。そのため、金魚ロスの利点と限界がモデルサイズによってどのように変化するかを理解することが重要です。このため、数百億から数千億のパラメータを持つ複雑化するLLMにgoldfish lossを適応させ、洗練させる研究が必要である。
金魚ロスの選択的適用:** 学習データの特定の部分、あるいは学習の特定の段階において、金魚ロスを選択的に適用することを探求する。これにより、記憶の軽減とモデルの性能のバランスを最適化することができる。
ロバストハッシング戦略の開発:**金魚ロスの有効性は、特にテキストセグメントがほぼ重複しているシナリオにおいて、ハッシングメカニズムのロバスト性に大きく依存する。繰り返されるコンテンツの一貫したマスキングを保証する高度なハッシュ戦略の開発と評価の研究は重要である。
ハイブリッドアプローチの探求:**金魚の損失と、差分プライバシーやデータサニタイゼーション手法などの他の技術を組み合わせることの潜在的な利点を調査する。これにより、LLMにおける記憶リスクを軽減するための、より強固で包括的なソリューションにつながる可能性がある。
関連リソース
金魚の損失に関する論文金魚のように、記憶するな!生成的LLMにおける暗記の軽減
MAUVEスコア論文:生成モデルのMAUVEスコア:理論と実践
大規模言語モデルと検索](https://zilliz.com/learn/large-language-models-and-search)
MIAの論文大規模言語モデルでメンバーシップ推論攻撃は有効か
2024年のトップLLM:価値あるもののみ](https://zilliz.com/learn/top-llms-2024)
プライベートLLMとは?大規模言語モデルをプライベートで実行する - privateGPTとその先へ](https://zilliz.com/learn/what-are-private-llms)
LLM-Eval: A Streamlined Approach to Evalating LLM Conversations](https://zilliz.com/learn/streamlined-approach-to-evaluating-llm-conversations)
PagedAttentionによる大規模言語モデルの効率的なメモリ管理](https://zilliz.com/learn/efficient-memory-management-for-llm-serving-pagedattention)
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS