




RouteLLM: LLM展開におけるコストと品質のトレードオフをナビゲートするオープンソースフレームワーク
RouteLLMはオープンソースのフレームワークで、開発者はコスト、レイテンシ、精度に基づき、タスクを最適なLLMに効率的にルーティングできる。
シリーズ全体を読む
- OpenAIのChatGPT
- GPT-4.0と大規模言語モデルの秘密を解き明かす
- 2024年のトップLLM:価値あるもののみ
- 大規模言語モデルと検索
- ファルコン180B大型言語モデル(LLM)の紹介
- OpenAIウィスパー高度なAIで音声をテキストに変換する
- OpenAI CLIPを探る:マルチモーダルAI学習の未来
- プライベートLLMとは?大規模言語モデルをプライベートで実行 - privateGPTとその先へ
- LLM-Eval:LLMの会話を評価するための合理的なアプローチ
- CohereのRerankerを使いこなし、AIのパフォーマンスを向上させる
- PagedAttentionを用いた大規模言語モデルサービングの効率的なメモリ管理
- LoRAの説明LLMを微調整するための低ランク適応
- 知識の蒸留:妥当性を犠牲にすることなく、大規模で計算量の多いLLMから小規模なLLMへ知識を移行する
- RouteLLM: LLM展開におけるコストと品質のトレードオフをナビゲートするオープンソースフレームワーク
- 検証者-検証者ゲームがLLM出力の可読性を向上させる
- 金魚のように、暗記をするな!ジェネレーティブLLMで暗記を軽減する
- LLMにおけるメニーショット・インコンテキスト学習のパワーを解き放つ
- 双眼鏡でLLMを発見:機械生成テキストのゼロショット検出
AIにおける大規模言語モデル(LLM)の人気と宣伝は、今日否定できない。その多用途性により、LLMは様々な業界やユースケースで実装されるのに特に魅力的です。幸いなことに、ChatGPT、Claude、Mistral、Llama、Qwen、その他多くのLLMが利用可能です。その上、これらのLLMの開発者は、より多くの選択肢を提供するために、一つのモデルファミリーの中にいくつかの亜種を頻繁に発表している。例えば、MetaはLlama 3.2モデルを4つの異なるバリエーションでリリースしている:1Bと3BのテキストのみのLLM、11Bと90BのビジョンLLMです。
利用可能なLLMの数が非常に多いため、特定のユースケースに最適なモデルを選択するのは困難です。多くのシナリオでは、コストと応答品質のバランスをとるために、複数のLLMを利用する必要があるでしょう。そのため、クエリの複雑さに応じて、コストと応答品質を最適化する異なるLLMを柔軟に選択できることは有益です。この記事では、このコンセプトを実現するのに役立つRouteLLMと呼ばれるメソッドについて説明します。それでは、早速始めましょう。
RouteLLMとは?
RouteLLMはオープンソースのフレームワークで、大規模な言語モデル(LLM)のデプロイと管理を簡素化するために設計されています。開発者は、コスト、レイテンシ、精度などの要素に基づいて、タスクを最適なLLMに効率的にルーティングすることができます。OpenAI、Anthropic、FalconやLLaMAのようなオープンソースモデルを含む複数のLLMプロバイダーをサポートすることで、RouteLLMはシームレスな統合とスケーラビリティを保証します。主な機能には、インテリジェントなルーティング、ダイナミックなプロバイダー選択、タスク最適化などがあります。柔軟性を提供し、複雑さを軽減することで、RouteLLMは、多様なアプリケーションで複数のLLMを効果的に活用したいと考えている組織にとって理想的です。
RouteLLMを支える動機
現実のシナリオでLLMを使用する際の最も一般的な制約の1つは、コストです。LLMは様々なタスクを解決する上で非常に強力であるにもかかわらず、クローズドソース、オープンソースを問わず、LLMの実装にはコストがかかることが分かっています。
ChatGPTやClaudeのようなクローズドソースのモデルを使う場合、コストはクエリの数、クエリ内のトークンの数、生成されるトークンの数などの要因に依存します。一方、Llama、Mistral、Qwenのようなオープンソースモデルを使用する場合、コストはGPUの種類や数、LLMがクエリを処理するのに必要な時間などの要因に依存します。
経験則では、LLMのサイズが大きいほど、その運用コストは高くなります。しかし、LLMのサイズは通常、その能力にも対応する。LLMのサイズが大きいほど、その応答品質は高くなる。したがって、性能とコストのトレードオフのシナリオに直面することになる。大きなLLMを選べば、クエリが複雑な場合でも高品質の応答がほぼ保証されるが、高いコストがかかる。小さいLLMを選択した場合は、その逆となる。
図-異なるLLM間のコスト-品質比較.png](https://assets.zilliz.com/Figure_Cost_quality_comparison_between_different_LL_Ms_f9fe8ce8a6.png)
図:異なるLLM間のコスト品質比較 Source._.
もちろん、すべてのクエリの応答品質を保証するために、大きなLLMを選択することもできます。しかし、すべてのクエリのレスポンスを生成するために大きなLLMを使用することは、すべてのクエリが複雑であるとは限らないため、費用の無駄になります。単純なクエリであれば、より小さなモデルで高品質のレスポンスを生成することができます。
この問題を解決するには、クエリの複雑さを分類する方法を実装すればよい。そして、その分類結果に基づいて、レスポンスを生成する適切なLLMを選択します。メソッドがクエリを「複雑」と分類した場合、メソッドはこのクエリを大規模で高価なLLMに送ります。一方、クエリが "単純 "と分類された場合、このクエリは小型で安価なLLMに送られる。
RouteLLMは、このアイデアを実装したメソッドの1つです。この方法では、各クエリはまず、いわゆるルーティング関数によって処理される。このルーティング関数は、コストを最小化しながら応答品質を最適化する目的で、クエリをどのLLMにルーティングするかを決定する。なぜなら、クエリをルーティングする前に、クエリの複雑さとドメインを推測し、候補となるLLMの能力を理解する必要があるからです。次のセクションでは、RouteLLMがこれらの課題にどのように取り組んでいるかについて説明する。
RouteLLMの基本
一般的なLLMルーティングのコンセプトは単純です:N個の異なるLLMが与えられたとき、ルーティング関数のタスクはクエリqをどのLLMにルーティングすべきかを分類することです。したがって、ルーティング関数の最終的な出力は、Nの次元を持つベクトルとなります。
クエリqに対する応答を生成する最適なLLMを見つけるために、ルーティング関数は、コストを最適化しながら応答品質を最大化するように訓練される必要がある。従って、ルーティング関数の学習データは通常(q, li,j)の構造を持つ。ここで、qはクエリを表し、li,jはクエリqに対するLLM iとjの応答を比較した結果得られたラベルである。
図- 一般的なLLMルーティングの視覚化.png](https://assets.zilliz.com/Figure_Visualization_of_LLM_Routing_in_general_1039311c88.png)
図-一般的なLLMルーティングの可視化.png]()LLMルーティングの可視化.png]()
RouteLLMは上記のコンセプトに従ったルーティング手法である。具体的には、そのルーティング関数はクエリの複雑さを分類し、強いモデルか弱いモデルのどちらかにルーティングするように訓練されている。ここでいう強いモデルとは、膨大な数のパラメータを持つ高度なクローズドソースのLLMのことであり、弱いモデルとは通常、より少ないパラメータしか持たないオープンソースのLLMのことである。2つの異なるLLMを扱うだけなので、RouteLLMのルーティング問題は一般的にバイナリルーティングと呼ばれる。
RouteLLMがルーティング関数を学習するために実装している主なコンポーネントは、勝利予測モデルとコスト閾値の2つです。
勝利予測モデル:バイナリ・ルーティングで強いモデルが勝利する確率を予測します。ルーターモデルの出力は、2つの要素を持つベクトルとなります。1つは強いモデルの勝率を表し、もう1つは弱いモデルの勝率を表します。
コスト閾値:ルーティング関数の出力をルーティング決定に変換する。各クエリqに対して、ルーティング決定は以下の式で定義される:
方程式 .png](https://assets.zilliz.com/equation_dbf4d65307.png)
ここで、αは応答品質とコストのトレードオフを制御する閾値である。しきい値が高いほど、コストに厳しくなり、ルーティング機能はレスポンスの質よりもコストを優先させることになります。
推論時間中、クエリqに対するレスポンスは、ルーティング関数の決定に応じて、強モデルか弱モデルのどちらかによって生成される。
RouteLLM の学習プロセス
前のセクションで述べたように、RouteLLMの主な要点は、バイナリ分類問題におけるクエリルーティングのためのルーティング関数を学習することです。しかし、世の中の機械学習問題と同様に、学習プロセスの前にまずデータを収集する必要があります。
RouteLLMの学習データは以下の形式である:q, Ms, Mw, ls,w}_ ここで、qはクエリ、Msは強いモデルからのレスポンス、Mwは弱いモデルからのレスポンス、ls,wは人間の判断による2つのモデル間のレスポンスの好みを表すラベルである。
学習データ収集プロセス
学習データを収集するために、RouteLLMの作者はいくつかのデータ収集技術を実装した。
最初のものは、オンラインのチャットボット・アリーナ・プラットフォームから収集した80Kのデータを使用しています。このデータソースには、クエリ、2人の匿名LLMの応答、ラベルとして機能するユーザーからの2つの応答間のプリファレンス結果が含まれています。
しかし、比較される2つのモデルはランダムであるため、任意の2つのモデルの間で利用可能なラベルの割合は0.1%未満である。この問題を解決するために、著者はチャットボットアリーナリーダーボードでのEloスコアに基づいてモデルを10階層にクラスタリングすることを実装した。階層が高いほど、そのモデルは強い。以下は、これらの階層を視覚化したものである:
 図- Chatbot ArenaデータセットにおけるLLMの10階層へのクラスタリング.png
図- Chatbot ArenaデータセットにおけるLLMの10階層へのクラスタリング.png
図:Chatbot ArenaデータセットにおけるLLMの10階層へのクラスタリング Source ._。
ルーティング関数の学習では、筆者は第1階層のモデルを強モデル、第3階層のモデルを弱モデルとした。また、著者は、MsとMwを表現するために、チャットボット・アリーナ・プラットフォームからのオリジナルの応答を使用せず、与えられたクエリに基づいて応答を再生成したことも重要である。
トレーニング中のルーティング関数の汎化を改善するために、著者はいくつかのデータ増強法も行った:
ゴールデンラベルデータセット:このデータセットは多肢選択式クエリから収集されているため、2つのLLMの応答を客観的に判断、比較することができる。このデータ補強を行うために、著者はMMLUデータセットの検証セットから1.5kの質問を取り出し、2人のLLMからの回答に基づいてラベルls,wを導き出した。
LLM-ジャッジ・ラベル付きデータセット:選好ラベルを得る一般的な方法の1つは、2人のLLMの回答から比較ラベルli,jを導出するために、もう1人の強力なLLMをジャッジとして使うことである。このデータ補強を行うために、著者はNectarデータセットを使用した。このデータセットには、クエリとそれに対応する複数のモデルの応答が含まれている。著者は合計120Kのクエリを選び、選ばれた強いモデルと弱いモデルから対応するクエリの応答を選び、比較ラベルls,wを導出するためにGPT-4を判定に用いた。
RouteLLMはルーティング関数を最適化する4つの異なるアプローチを実装している:類似重み付け(SW)ランキング、行列分解、BERT分類器、因果LLM分類器である。まずSWランキングについて説明する。
最初のルーティングアプローチ - SWランキング
SWランキングの考え方は、2つのモデル(強いモデルと弱いモデル)を、特定のユーザークエリに答えるのに最も適している可能性に基づいてランク付けすることである。学習セットqiの各クエリに対して、類似度スコア(S(q, qi))が計算され、qiが新しいユーザークエリqにどれだけ似ているかを測定する。直感的には、より類似したクエリがランキングに影響を与えるはずです。各トレーニングクエリqiには、現在のクエリqとの類似度に基づいた重みωiが割り当てられます。
クエリ間の類似度を計算するため、クエリはまず埋め込みに変換される必要があります。そのために、OpenAIのtext-embedding-3-smallという埋め込みモデルを使う。
次に、BT(Bradley-Terry)モデルを実装する。このモデルは、強いモデルが弱いモデルに勝つ確率を、そのスコアに基づいて推定する。これは前節で述べた勝敗予測モデルに相当し、このBTモデルは以下の式で強いモデルが勝つ確率を推定する:
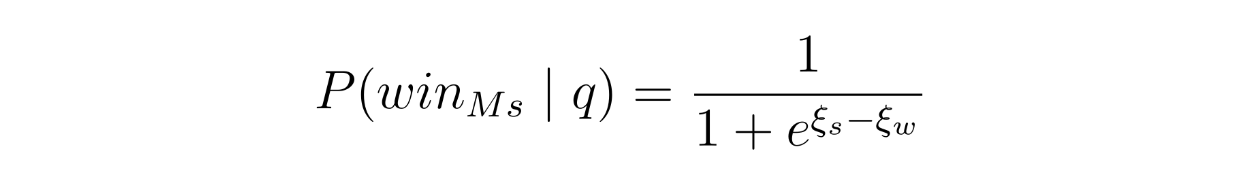 SWランキング - 方程式.png
SWランキング - 方程式.png
ご覧のように、BTモデルは係数ξs(強いモデルの係数)とξw(弱いモデルの係数)に依存しています。これらの係数は学習時に2値のクロスエントロピー損失関数を用いて学習される。各クエリの重みは、各トレーニングクエリが学習プロセスに与える影響にも影響する。
SWランキング-式2.png](https://assets.zilliz.com/SW_Ranking_equation_2_0bdf106266.png)
推論時間中、ユーザーが新しいクエリを提供するとき、モデルを再学習する必要はない。ランキングはその場で計算され、強いモデルが勝つ確率は、学習された係数を用いて、上に示した式で計算することができる。
第二のルーティングアプローチ - 行列因数分解
番目の方法は、推薦システムでよく使われる行列因数分解からヒントを得ている。主な目的は、隠されたスコアリング関数s(M,q)を最適化することです。このスコアは、そのクエリに対するモデルの性能を反映する。もし強いモデル Ms が弱いモデル Mw よりも良いパフォーマンスをする場合、スコアリング関数は確実にする必要があります:
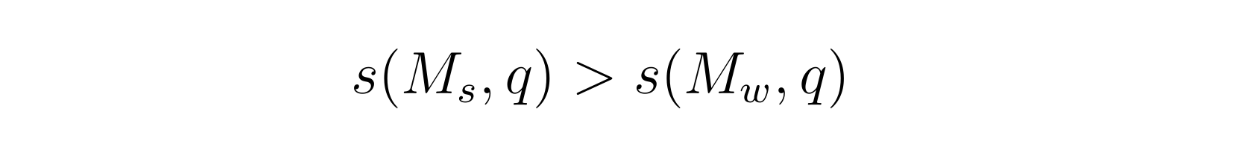 行列因数分解 - equation.png
行列因数分解 - equation.png
したがって、上記の関係を保証するために、強いモデルの勝率は以下の式でモデル化される:
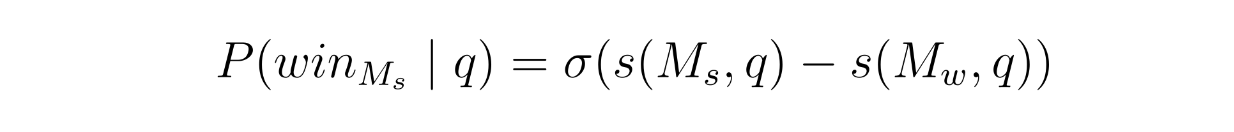 行列因数分解 - 方程式2.png
行列因数分解 - 方程式2.png
ここでσはシグモイド関数である。
この方法を理解するのが難しい場合は、2つの行と多くの列を持つ表を想像してみてください。行は比較されるモデルを表し、列はクエリを表し、各セルはクエリに対するモデルの結果を表します。この方法は、モデルとクエリの表現を組み合わせて与えられたデータからパターンを学習することで、表のセルを埋めようとする。
第3のルーティングアプローチ - BERT分類器
この方法は、与えられたクエリqに対する強いモデルの勝率を予測するためにBERTを利用する。勝率は以下の式でモデル化される:
BERT Classifier - equation.png](https://assets.zilliz.com/BERT_Classifier_equation_a8baa3500b.png)
すでにご存知かもしれませんが、BERT は、ボンネットの下でいくつかのスタックの トランスフォーマ・エンコーダー を使用するモデルです。各入力クエリqに対して、BERTはクエリの最初の位置に特別なトークン[CLS]を付加して処理し、各トークンに対して特定の次元の数値特徴を生成します。
図- BERT アーキテクチャ.png](https://assets.zilliz.com/Figure_BERT_architecture_a898b251cb.png)
図:BERT アーキテクチャ._.
このアプローチは、[CLS]トークンの数値的特徴のみを取り込み、それをロジスティック回帰ヘッドに送り込んでモデル化確率を最適化します。
第4のルーティングアプローチ - 因果的LLM分類器
この方法は、モデルの性能を評価する分類器として Llama 3 8B を利用する。具体的には、強いモデルが弱いモデルよりも良いパフォーマンスを示す勝率を、命令追従の概念を用いて決定する。
ユーザーのクエリは、命令プロンプト(例えば、「クエリqについてモデルMsとMwを比較します。)モデルはこのプロンプトを読み、直接トークンとして出力を予測する。さらに、比較ラベルはモデルの語彙に追加され、ラベルと同様の構造を持つ出力を生成することができる。
RouteLLM メトリクス
上記の4つのアプローチでルーティング関数を学習したら、それぞれのアプローチのパフォーマンスをテストする必要があります。各ルーティング関数の性能を定量化するために、RouteLLMはいくつかの異なるメトリクスを実装しました。
最初のメトリクスは、強いモデルへの呼び出しの割合です。このメトリクスはコスト効率を定量化するのに便利です:
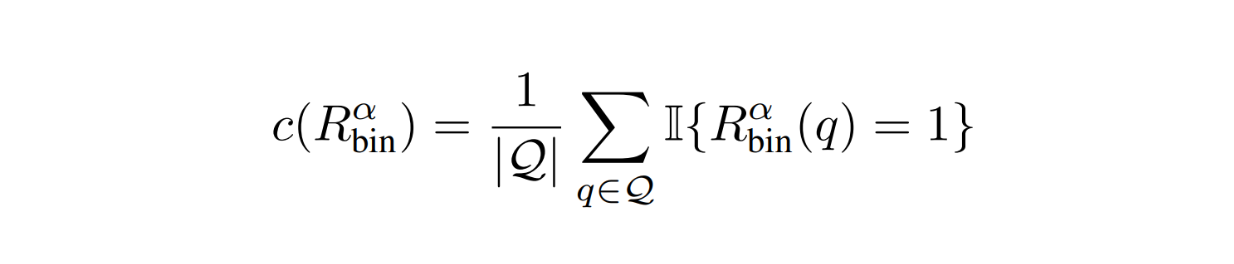 RouteLLMメトリクス - 方程式.png
RouteLLMメトリクス - 方程式.png
コストを最適化するために、通常、このメトリックは可能な限り低くしたい。
2つ目のメトリックは、評価データセットでの平均応答品質です。その名の通り、このメトリクスはルーティング関数を使ったレスポンスの全体的な品質を数値化します。理想的には、このメトリックのスコアをできるだけ高くしたい。
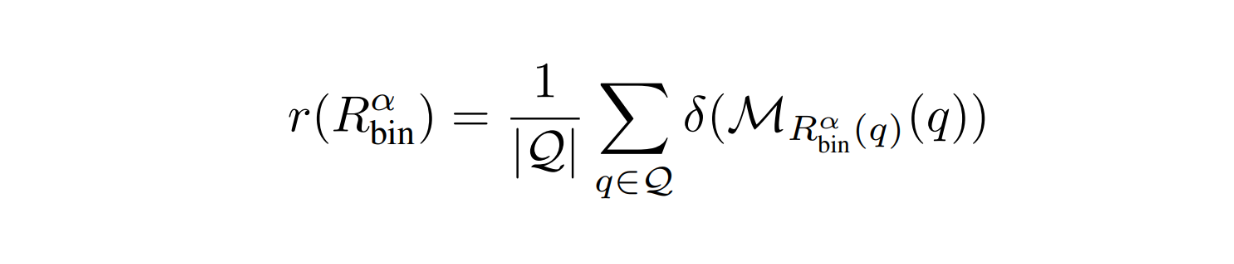 RouteLLMメトリクス - 方程式2.png
RouteLLMメトリクス - 方程式2.png
ルーティング関数を使う以上、応答品質は弱モデルを下限とし、強モデルを上限とする品質の中間になる。そこで著者は、両モデル間の性能差に対するルータの性能を定量化する性能差回復(PGR)という指標も定義しました:
RouteLLMメトリクス-式3.png](https://assets.zilliz.com/Route_LLM_Metrics_equation_3_4fcf8a493a.png)
しかし、上記のメトリックには1つの大きな問題があります。クエリが非常に単純で、ルーターが常に強いモデルにクエリを誘導する場合、PGRメトリックは常に1になります。解決策は、異なるコスト閾値アルファ値でPGRを繰り返し定量化することです。従って、様々なコスト制約が与えられた場合のルーティング関数の平均PGRを得ることができます。
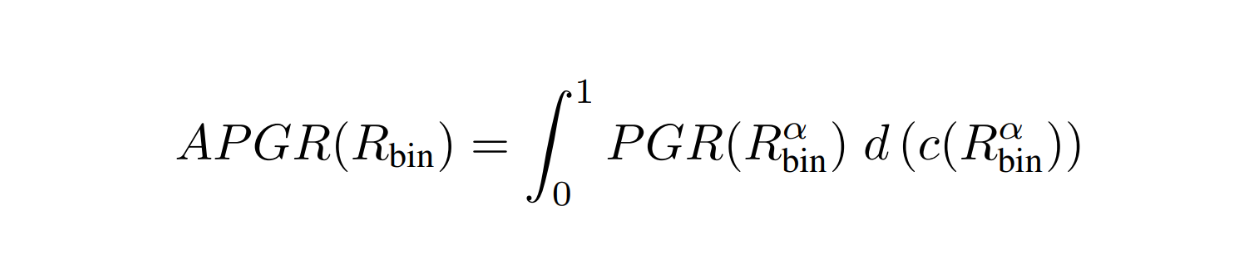 RouteLLMメトリクス - 式4.png
RouteLLMメトリクス - 式4.png
図-GPT-4とMixtral-8x7Bのコストトレードオフ.png](https://assets.zilliz.com/Figure_Routing_performance_cost_trade_off_between_GPT_4_and_Mixtral_8x7_B_0ef7715408.png)
図:GPT-4とMixtral-8x7Bのルーティング性能とコストのトレードオフ Source._.
また、定量化する必要がある重要な指標の1つは、あるレベルのパフォーマンスを達成するために必要なコストです。すでにご存知のように、RouteLLMの主な目標は、コストを最小化しながら応答品質を最適化することです。これを把握するために、著者は**コールパフォーマンスしきい値(CPT)と呼ばれるメトリックを定義しました。
上の可視化画像でわかるように、希望するパフォーマンスレベル(PGR50%)が与えられた場合、CPTは希望するPGRを達成するために必要なストロングモデルへの最小コール数を定量化します。
実験結果
前節の4つの異なる手法でトレーニングした後のルーティング関数のパフォーマンスをテストするために、Chatbot Arena、MMLU、MT Bench、GSM8Kの検証セットを含む複数のデータセットを使用しました。
テストでは、GPT-4-1106-Previewモデルを強いモデルとして使用し、Mixtral 8x7Bモデルを弱いモデルとして使用した。各ベンチマークデータセットにおいて、ルーティング関数は互いに、またランダムなベースラインと比較される。ランダムなベースラインは、特定のコスト制約の下でクエリをランダムにルーティングするルーティング機能を表す。
図-MTベンチにおけるRouteLLMの結果.png](https://assets.zilliz.com/Figure_Route_LLM_results_on_MT_Bench_10fe50528f.png)
図:MTベンチでのRouteLLM結果 ソース._.
ご覧のように、BERT、行列分解、SWランキングアプローチでArenaとLLMジャッジラベル付きデータセットで学習したルーティング関数は、MT Benchデータセットで最高のパフォーマンスを発揮しました。これらは、ランダムなベースラインと比較して、CPT(80%)に到達するためのGPT-4コールをほぼ50%減少させた。
図-MMLU(上)とGSM8K(下)でのRouteLLMの結果.png](https://assets.zilliz.com/Figure_Route_LLM_results_on_MMLU_top_and_GSM_8_K_bottom_2efd56e41f.png)
図:MMLU(上)とGSM8K(下)におけるRouteLLMの結果 Source._.
一方、MMLUデータセットとGSM8Kデータセットでは、Arenaデータセットで訓練されたルーティング関数はすべて、ランダムベースラインと比較して低い結果を示しました。しかし、Arenaデータセットと拡張データセットの両方で訓練したルーティング関数を使用すると、すべてのルーティング関数の性能が向上した。
ここで重要なのは、増強データセットに含まれるのは、訓練データ全体のごく一部に過ぎないということだ。これは、少ないサンプル数でもルーティング関数を微調整できることを示している。
上記の結果では、強いモデルとしてGPT-4を、弱いモデルとしてMixtral 8x7Bを使用しました。強モデルと弱モデルの組み合わせを変えたらどうなるか?これを検証するために、著者はルーティング関数を再トレーニングすることなく、強いモデルと弱いモデルの異なる組み合わせもテストしました。具体的には、Claude 3 Opusを強いモデル、Llama 3 8Bを弱いモデルとして使い、MT Benchデータセットでルーティング関数をテストした。
図-Claude 3 OpusとLlama 3 8Bを使ったMT BenchでのRouteLLMの結果。.png](https://assets.zilliz.com/Figure_Route_LLM_results_on_MT_Bench_with_Claude_3_Opus_and_Llama_3_8_B_7beeed0d4d.png)
図:クロード3オーパスとラマ3 8Bを使ったMTベンチでのRouteLLMの結果 Source._.
ご覧のように、モデルペアを交換しても、ルーティング関数は依然として良い結果を達成しています。この新しいモデルペアの性能も元のモデルペアに匹敵し、追加学習なしでRouteLLMの汎化特性を示しています。
強いモデルとしてGPT-4、弱いモデルとしてMixtral 8x7Bを使用した場合、RouteLLMは、GPT-4への呼び出しを効率的に少なくすることで、CPT50%のMTベンチでランダムなベースラインと比較して約3.66倍、CPT80%で約2.49倍のコスト削減に成功しました。
 図- GPT-4に対する最高性能ルータのコスト削減率.png
図- GPT-4に対する最高性能ルータのコスト削減率.png
図:GPT-4と比較して最も性能の良いルーターのコスト削減率 Source._.
結論
この記事では、RouteLLMという、LLMを本番で使用する際のコストと品質のトレードオフに対する解決策を提供する方法について説明しました。RouteLLMは、複雑性に基づいて強いモデルと弱いモデルの間でクエリをインテリジェントにルーティングすることで、高い応答品質と運用コストのバランスを最適化する。SW Ranking、Matrix Factorization、BERT-based classification、Causal LLM classificationといった様々なルーティングアプローチにより、データセットやモデルの組み合わせに柔軟性と適応性があることが実証されました。
実験結果から、RouteLLMはランダムルーターと比較して、高品質な応答を維持しながら、高価なLLMへの依存を低減する効率性を示しました。これにより、本番環境でLLMを使用する際のコストを削減することができる。
続きを読む
RouteLLM GitHub:lm-sys/RouteLLM: LLMルータのサービスと評価のためのフレームワーク
LoRA (Low-Rank Adaptation)による効率的なLLMファインチューニング](https://zilliz.com/learn/lora-explained-low-rank-adaptation-for-fine-tuning-llms)
大規模言語モデルのための知識抽出: 深い掘り下げ ](https://zilliz.com/learn/knowledge-distillation-from-large-language-models-deep-dive)
セルフホスティングLLMシステムガイド](https://zilliz.com/blog/guide-to-self-hosting-compound-llm-systems)
LLMにおける関数呼び出しの理解](https://zilliz.com/blog/harnessing-function-calling-to-build-smarter-llm-apps)
LoRA (Low-Rank Adaptation)による効率的なLLM微調整](https://zilliz.com/learn/lora-explained-low-rank-adaptation-for-fine-tuning-llms)
LLaVaと視覚命令チューニングの解説 ](https://zilliz.com/blog/llava-visual-instruction-training)
ベクトルデータベースとは何か、その仕組みとは】(https://zilliz.com/learn/what-is-vector-database)
RAGとは ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)



