ファルコン180B大型言語モデル(LLM)の紹介
Falcon 180Bは、3.5兆のトークンで学習された180Bのパラメータを持つオープンソースの大規模言語モデル(LLM)です。 このブログでそのアーキテクチャと利点を学んでください。
シリーズ全体を読む
- OpenAIのChatGPT
- GPT-4.0と大規模言語モデルの秘密を解き明かす
- 2024年のトップLLM:価値あるもののみ
- 大規模言語モデルと検索
- ファルコン180B大型言語モデル(LLM)の紹介
- OpenAIウィスパー高度なAIで音声をテキストに変換する
- OpenAI CLIPを探る:マルチモーダルAI学習の未来
- プライベートLLMとは?大規模言語モデルをプライベートで実行 - privateGPTとその先へ
- LLM-Eval:LLMの会話を評価するための合理的なアプローチ
- CohereのRerankerを使いこなし、AIのパフォーマンスを向上させる
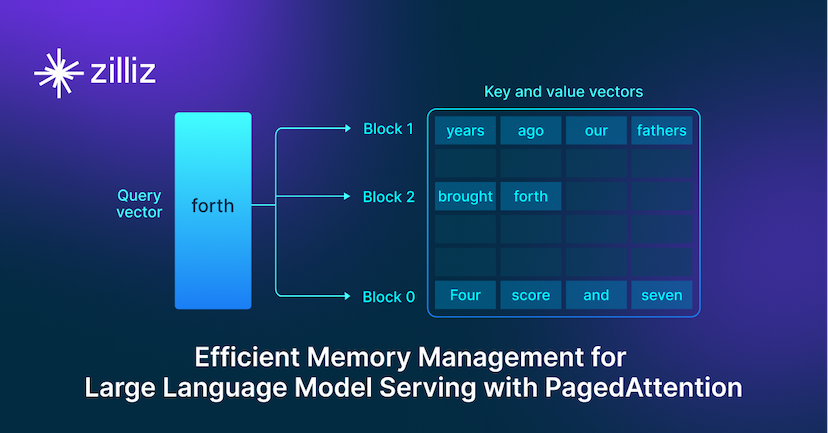
- PagedAttentionを用いた大規模言語モデルサービングの効率的なメモリ管理
- LoRAの説明LLMを微調整するための低ランク適応
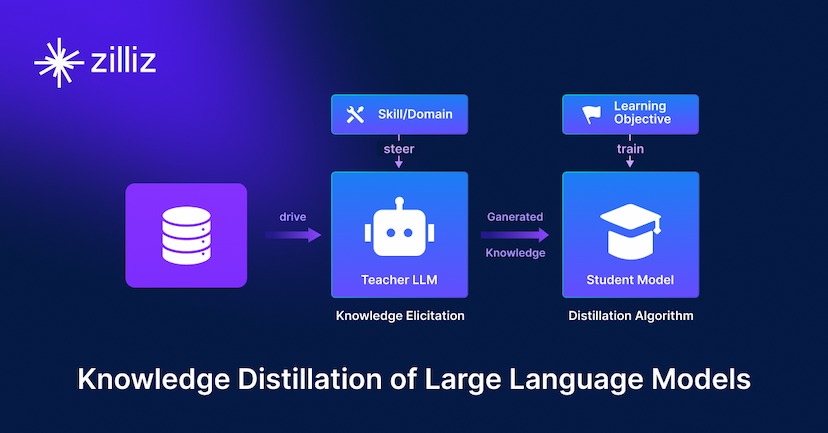
- 知識の蒸留:妥当性を犠牲にすることなく、大規模で計算量の多いLLMから小規模なLLMへ知識を移行する
- RouteLLM: LLM展開におけるコストと品質のトレードオフをナビゲートするオープンソースフレームワーク
- 検証者-検証者ゲームがLLM出力の可読性を向上させる
- 金魚のように、暗記をするな!ジェネレーティブLLMで暗記を軽減する
- LLMにおけるメニーショット・インコンテキスト学習のパワーを解き放つ
- 双眼鏡でLLMを発見:機械生成テキストのゼロショット検出
最新更新:2024年7月31日
ファルコンLLMは、ファルコンマンバ7B、ファルコン2、180B、40B、7.5B、1.3BパラメータのAIモデルを含む生成的LLMです。 ファルコン180Bは、3.5兆のトークンで学習された180Bのパラメータを持つオープンソースの超強力な言語モデルです。このブログでそのアーキテクチャと利点を学んでください。
ファルコンAIとファルコンLLMファミリーの紹介
2000年初頭にGPTイニシアチブが開始された後、世界のAIの状況は爆発的に変化しました。それ以来、いくつかの生成モデルが登場しました。AIが徐々に強力になるにつれ、人間の知能に似てきました。とはいえ、オープンAIコミュニティは、強力な言語モデルに基づくGPTファミリーを閉鎖した。
スケーラブルで強力な生成言語モデルであるFalcon180b AIは、GitHubから無料で提供されており、技術革新研究所によれば「研究と商用利用のためのオープンアクセスモデル」である。Falconシリーズの[大規模言語モデル(LLM)](https://zilliz.com/glossary/large-language-models-(llms))は、大規模言語モデルの開発とデプロイにおける重要な進歩である。このブログでは、Falcon 180Bのモデルアーキテクチャ、データセット、学習戦略、結果としてのパフォーマンスメトリックスなど、Falcon 180Bの主要な側面を凝縮し、詳しく説明します。
ファルコン180Bモデルとそのアーキテクチャ
GPT、Claude、Pi、そして他のよく知られたLLMと同様に、Falconモデルは、スケーラビリティと効率性によって駆動されるいくつかのマクロ的な変更を伴う、自己回帰(デコーダのみ)トランスフォーマーアーキテクチャに依然として基づいています。このセクションでは、Falconのモデルアーキテクチャを詳細に調査し、その特徴や変更点、そしてこれらの変更の背景にある動機に焦点を当てます。この観点から、ファルコンのモデルは、モデルの性能と推論速度の良い中間点を見つけようとしている。
技術革新研究所によって開発されたファルコン40Bは、ファルコンファミリーの中でも重要なモデルであり、その計算効率と様々な用途におけるロバストな性能で知られている。Falcon 180Bは、1,800億個のパラメータを持つより大きなモデルで、3.5兆個のトークンで学習されたオープンソースの大規模言語モデル(LLM)である。これは、公開されている言語モデルの中で最大のもので、そのアーキテクチャはGPT-3に基づいていますが、いくつかの重要な違いがあります。ファルコン180Bの広範なトレーニングは、様々な用途における卓越した言語理解と汎用性を提供します。ファルコン180Bは、研究用と商業用の両方で利用可能で、推論、コーディング、熟達度、知識テストのようなタスクで優れたパフォーマンスを発揮します。
ここでは、ファルコンに採用されたいくつかの重要なアーキテクチャ上の決定を紹介する。
マルチクエリとマルチグループへの注目
ファルコンアーキテクチャの特徴の一つは、マルチクエリーアテンションをマルチグループアテンションに採用し、拡張したことである。このアイデアは、マルチヘッドアテンションメカニズムが強力である一方で、パフォーマンスを犠牲にすることなく効率性を最適化できることを認識したことに由来します。
マルチクエリー・アテンション:この適応は、すべてのヘッドでキーと値を共有することでアテンションメカニズムを単純化し、メモリ消費と計算オーバーヘッドを大幅に削減します。これは特に推論中の大規模モデルにとって有益であり、メモリフットプリントの削減は、より高速で効率的な生成タスクに直結します。
マルチグループアテンション:マルチクエリーアテンションに基づき、ファルコンLLMsはマルチグループアテンションを導入しました。これは分散トレーニング環境のためにモデルをさらに最適化し、並列プロセス間の複雑な同期と通信の必要性を減らします。また、最新のハードウェアアクセラレータにアーキテクチャを合わせることで、多数のGPUにまたがる効率的なスケーリングを実現している。
回転位置埋め込み(RoPE)
ファルコンのモデルは、シーケンス内の位置情報をエンコードするためにRoPEを利用します。これは、Transformersで伝統的に使用されてきた絶対位置vector embeddingsとは異なるものです。RoPEにはいくつかの利点がある:
相対位置情報:RoPEは、シーケンス内のトークンの相対的な位置を埋め込み、シーケンス構造とコンテキストのモデルによる理解を容易にする。これは、言語構造の微妙な理解を伴うタスクに特に有益である。
効率と性能:RoPEは、その洗練された機能にもかかわらず、計算効率が高くなるように設計されており、追加の位置コンテキストが学習や推論の速度を犠牲にすることはない。
活性化関数:GLUを超えるGELU
活性化関数の選択は、モデルが複雑なパターンを学習する上で非常に重要である。GELU(Gaussian Error Linear Unit)は、ディープラーニングモデルにおいてその有効性が実証されていることから選択されました。GELUは非線形活性化を提供し、GLU(Gated Linear Unit)によって課される追加の計算負荷なしに、モデルが従来のReLUよりも複雑な関数を学習することを可能にします。
並列化と効率化
並列アテンションとMLPレイヤー
ファルコンのアーキテクチャは、注意層とMLP(多層パーセプトロン)層の並列処理を採用しています。これらのコンポーネントへのアクセスを並列化することで、ファルコンは逐次処理に関連するボトルネックを最小化し、トレーニング中のフォワードパスとバックワードパスの高速化を可能にします。
線形層にバイアスをかけない
モデルを合理化し、安定性を向上させるために、ファルコンシリーズはリニアレイヤーにおけるバイアスを省いています:
シンプルさと安定性:この単純化により、トレーニング中のパラメータ数と潜在的な不安定性の原因を減らし、モデルのロバスト性と効率性に貢献しています。
アーキテクチャの革新:ファルコンモデルのアーキテクチャ上の革新は恣意的なものではなく、スケーラビリティ、効率性、パフォーマンスという目標に深く動機づけられています。マルチグループアテンションから並列処理レイヤーに至るまで、各設計上の決定はスケーラビリティを念頭に置いてなされています。モデルのサイズが大きくなっても、利用可能なハードウェア上で学習可能かつ効率的であり続けるように、アーキテクチャは作られている。推論の効率性は、特に広範囲な展開を意図したモデルにとって、同様に高い優先順位を取ります。ファルコンのモデルは、マルチクエリーアテンションやRoPEのような最適化を通じてこの問題に対処し、モデルが複雑な生成タスクでもリアルタイムの応答を提供できるようにしている。純粋な性能は落ちますが、ファルコンのアーキテクチャは、様々な自然言語処理(NLP)タスクにおいて性能を維持または向上させるように最適化されており、ファルコンシリーズのモデルが最先端のものと競争力を持つことを保証します。
ファルコンの開発者は、大規模言語モデルの設計に先進的なアプローチを採用しました。革新的なアテンションメカニズム、効率的な位置埋め込み、合理化されたネットワークコンポーネントの組み合わせを通して、ファルコンシリーズのモデルは自然言語処理で何が可能であるかの新しい基準を設定します。
データセットの構成
ファルコンシリーズの言語モデルのために開発されたデータセット構成と重複排除戦略は、モデルの性能と効率を支える重要な開発側面である。
高品質ウェブデータ
ファルコンのモデルは、5000億トークンを超える広範な英語ウェブデータセットを活用しています。このデータセットは、書籍、技術論文、その他の伝統的な「高品質」コンテンツのようなソースからのコーパスを含む従来の必要性に挑戦し、高品質を確保するための厳格なフィルタリングプロセスを通してキュレーションされています。ウェブデータに注目するのは、適切な処理によって、ウェブデータは、優位とまではいかなくても、競争力のあるモデル性能をもたらすことができるというニュアンスからきている。
スケーラビリティと品質の重視
データセットの規模と質は、モデルのトレーニング効率とパフォーマンスを最適化するためにバランスが取られている。ウェブデータを優先するのも戦略的であり、一般的にモデルサイズとともに増大する推論の負担を軽減することを目的としている。事前学習データセットのサイズを大きくすることは、モデルサイズの増加とは異なり、推論コストと切り離されているため、特に有利である。
戦略的構成
データセットの構成は、スケーラブルなデータ収集と処理方法を活用するというファルコンチームのコミットメントの証である。これは、データの質と関連性を優先するプロセスを通じて、英語ウェブの広範な情報を強力なトレーニングデータセットに抽出する包括的なアプローチを反映している。
重複排除戦略
厳格な重複排除
重複排除はファルコンのデータセットの完全性の要である。この戦略では、モデルのトレーニング中にいかなるデータインスタンスも繰り返されないことを厳密に保証するために、2段階の重複排除を行う。このアプローチはデータの繰り返しに伴うモデル性能の低下に対処するものであり、データセットの品質を維持する上で極めて重要である。
動機と実装
重複排除戦略は、データの素朴な繰り返しがモデルのパフォーマンスを低下させ、データセットのスケーリングの持続可能性についての懸念につながることを示す研究によって動機づけられている。ファルコンの重複排除プロセスには、重複を効果的に除去するための洗練されたフィルタリングと識別技術が含まれる。
利点と成果
冗長性を排除することで、ファルコンシリーズは計算資源を節約し、トレーニングプロセスが多様なデータインスタンスに集中することを保証し、モデルが自身のトレーニングデータコーパスから汎化する能力を高める。この重複排除に対する細心のアプローチは、特にゼロショット学習と少数ショット汎化において、モデルの印象的なパフォーマンス指標に大きく貢献しています。
ファルコンモデルの主要な洞察と革新性
ウェブデータ活用における革新:ファルコンのデータセット構成戦略は、最先端の言語モデルを訓練するためにウェブデータを利用する革新的なアプローチを示している。適切にフィルタリングされ、重複排除されたウェブデータは、キュレーションされたデータセットの品質に匹敵するか、それを上回ることができることを実証することにより、Falconシリーズは、大規模言語モデルのデータセット構成における一般的な規範に挑戦している。)ファルコンモデルは研究者や開発者にとって貴重なツールであり、様々な自然言語処理におけるアプリケーションを強化するために不可欠な柔軟性と堅牢な性能を提供する。
**スケーラビリティと効率性ファルコンシリーズの設計哲学は、スケーラビリティと計算効率を優先しています。このアプローチは、データセット処理とモデルアーキテクチャの進歩が、モデル能力の成長を持続的にサポートすることを保証します。
モデル性能への影響:データセットの重複排除はファルコンモデルの性能に直接影響する。データセットの重複排除はファルコンのモデルの性能に直接影響を与える。さらに、ファルコンシリーズのインストラクターモデルは、推論と真実の答えを提供することにおいて強力な有効性を示しており、市場において競争力を持たせ、より良い結果を得るためにユーザー自身がモデルを微調整することを奨励しています。
ファルコンシリーズのデータセット構成と重複排除戦略は、大規模言語モデル開発における最先端のプラクティスを例証するものであり、データ処理におけるイノベーションと、コミュニティ全体および品質と効率性に対する確固たるコミットメントを組み合わせたものです。
まとめ
ファルコンのモデルは、様々なデータセットやタスクにおいて顕著な性能を示し、主にゼロショットや少数ショットの設定においてその強さを示している。ファルコンの設計と学習戦略は、自然言語処理の最先端技術を前進させ、モデルの学習と展開の効率性とスケーラビリティを向上させるモデルを生み出す。
ファルコンシリーズは、データ品質、アーキテクチャの最適化、体系的なトレーニング戦略を重視し、大規模言語モデル開発のための新しいベンチマークを設定します。
これらの強みに加え、ファルコンのモデルはテキスト生成とテキスト生成推論に優れており、高品質で効率的なテキスト生成実行推論プロセスを促進します。また、言語翻訳にも長けており、様々なNLPタスクにおいてその汎用性を発揮します。Hugging Face](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard)が主催するMTEBのリーダーボードで、Falcon 180bが他のモデルに対してどのような結果を出しているか、注目してください。
 Frank Liu
Frank LiuFrank Liu is the Director of Operations & ML Architect at Zilliz, where he serves as a maintainer for the Towhee open-source project. Prior to Zilliz, Frank co-founded Orion Innovations, an ML-powered indoor positioning startup based in Shanghai and worked as an ML engineer at Yahoo in San Francisco. In his free time, Frank enjoys playing chess, swimming, and powerlifting. Frank holds MS and BS degrees in Electrical Engineering from Stanford University.