




検証者-検証者ゲームがLLM出力の可読性を向上させる
私たちは、LLMが人間が理解しやすく、検証しやすい正確な回答を生成できるようにするためのチェック可能性トレーニングアプローチについて議論した。
シリーズ全体を読む
- OpenAI's ChatGPT
- Unlocking the Secrets of GPT-4.0 and Large Language Models
- Top LLMs of 2024: Only the Worthy
- Large Language Models and Search
- Introduction to the Falcon 180B Large Language Model (LLM)
- OpenAI Whisper: Transforming Speech-to-Text with Advanced AI
- Exploring OpenAI CLIP: The Future of Multi-Modal AI Learning
- What are Private LLMs? Running Large Language Models Privately - privateGPT and Beyond
- LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
- Mastering Cohere's Reranker for Enhanced AI Performance
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- LoRA Explained: Low-Rank Adaptation for Fine-Tuning LLMs
- Knowledge Distillation: Transferring Knowledge from Large, Computationally Expensive LLMs to Smaller Ones Without Sacrificing Validity
- RouteLLM: An Open-Source Framework for Navigating Cost-Quality Trade-Offs in LLM Deployment
- Prover-Verifier Games Improve Legibility of LLM Outputs
- Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
- Unlocking the Power of Many-Shot In-Context Learning in LLMs
- Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
- Teaching LLMs to Rank Better: The Power of Fine-Grained Relevance Scoring
- Everything You Need to Know About LLM Guardrails
- Chain-of-Retrieval Augmented Generation
- Chain of Agents (COA): Large Language Models Collaborating on Long-Context Tasks
大規模言語モデル](https://zilliz.com/glossary/large-language-models-(llms))(LLMs)の開発の背後にある主な目標の1つが、人間が複雑な問題を解決するのを助けることであることは周知の事実である。この目標を達成するために、LLMは多くの場合、数学、コーディング、一般的な質問応答タスクなどのドメインにわたる問題解決スキルを最適化するために、様々なデータで訓練される。LLMの性能を測定するために、我々は訓練とテスト中に様々なタスクに対するLLMの回答の正しさを評価する。
LLMは、より多くのデータを持ち、より長く訓練すればするほど、より高い能力を持つようになり、したがって、その正答率もより高くなるという仮定がある。しかし、LLMが人間の役に立つためには、正しさだけでは十分ではない。LLMの読みやすさ、つまり、私たち人間がLLMの答えを容易に理解し、検証できるかどうかにも注意を払う必要がある。LLMの回答を信頼するためには、LLMの回答を容易に理解する必要がある。
この問題に対処するためには、LLM](https://zilliz.com/glossary/fine-tuning)を正しく理解しやすい回答を提供するように訓練する、あるいは[微調整する]必要があります。この記事では、証明者-検証者ゲーム理論にヒントを得た、有能で分かりやすいLLMを実現するための訓練方法について説明します。それでは、始めましょう!
検証者ゲーム理論の基本
様々なタスクに対して正しい答えを生成できるLLMを持つだけでは十分ではない。LLMの答えは、人間がその妥当性を検証できるように、理解できるものでなければならない。
しかし、実験結果は、LLMの正しさを最適化するためだけにLLMを訓練すると、その答えが人間にとって理解しにくくなることを示している。人間の評価者は、最適化されたモデルの答えを評価するよう求められたとき、最適化されていないモデルの答えを評価するよう求められたときと比較して、時間的制約のある状況で2倍の誤りを犯した。したがって、LLMは正しい答えを生成するだけでなく、理解しやすい、つまり人間にとって読みやすい答えを生成するように訓練する必要がある。
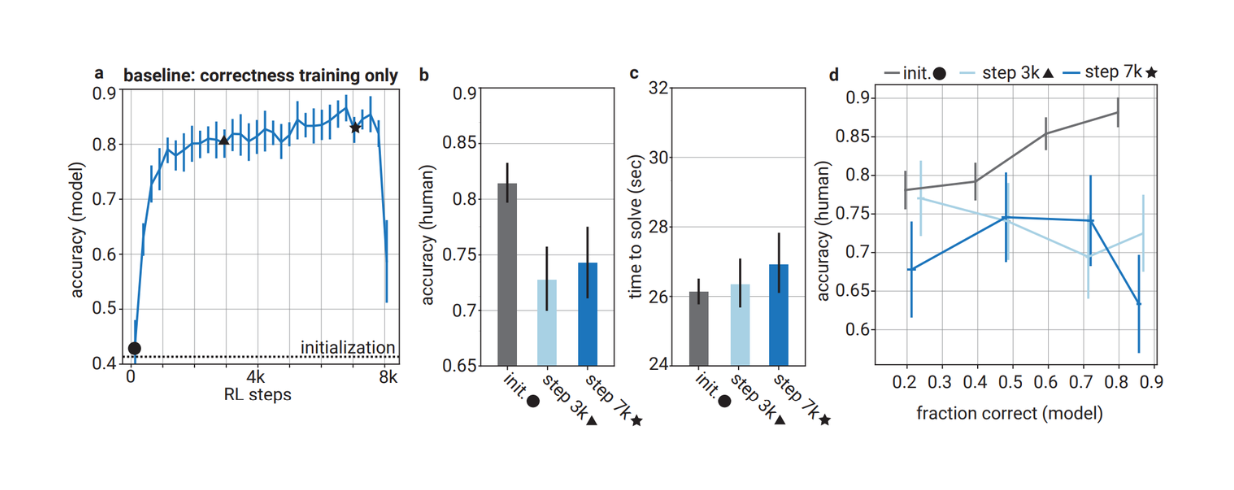 正しさのみに基づいて最適化されたモデルの精度と、人間の評価者が回答を評価したときの精度の比較
正しさのみに基づいて最適化されたモデルの精度と、人間の評価者が回答を評価したときの精度の比較
正しさのみに基づいて最適化されたモデルの精度と、人間の評価者が回答を評価する際の精度の比較_ ソース..
この目標を達成するために、チェック可能性訓練と呼ばれる反復アルゴリズムが提案されている。この方法は、エージェントに理解しやすい問題解決を促すゲーム理論のフレームワークである「検証者-検証者ゲーム」にインスパイアされている。このフレームワークには、「証明者」と「検証者」という2つの主要な構成要素がある。
簡単に言うと、証明者は与えられたクエリに対する答えを生成し、検証者は証明者が生成した答えの正しさをチェックする。証明者はLLM、検証者は人間と考えることができる。
人間の代わりをするために、検証者は証明者よりも小さく、能力の低いモデルで表現される。しかし、証明者も検証者も同じモデル・ファミリーに属する。小さくて能力の低いLLMを検証者に選ぶことには、少なくとも2つの目的がある:
1.1.LLMは人間と比べて拡張性が高く、LLMの出力を判断する能力が高いことが証明されている。
2.人間のフィードバックは、このような高度なシステムでは限界がある。したがって、より小さく、より能力の低いモデルで検証可能な答えを作ることは、最終的には人間にとってより検証可能な答えを作ることにもつながる。
可読性の低いモデルによる正解の例](https://assets.zilliz.com/Example_of_a_correct_answer_from_the_model_with_poor_legibility_7f0e5a39a3.png)
可読性の低いモデルからの正解の例]_ ソース..
チェック能力トレーニングのセットアップ
LLMの出力を人間にとってより読みやすくするために、証明者と検証者は、チェック可能性トレーニングフレームワークで数ラウンドにわたって次々にトレーニングされる。各ラウンドにおいて、検証者はまず、答えの正しさを予測するために、[教師あり学習]を用いて特定の混合データで訓練される。次に、証明者は強化学習で訓練され、報酬は答えの正しさと現在のラウンドの検証者の受け入れ率の組み合わせである。
証明者モデルのトレーニングの間、我々は証明者を2つの役割に分けます:役に立つ役割と卑劣な役割です。親切な証明者は問題に対する正しい解を生成しようとし、卑劣な証明者は「説得力のある」不正解を生成しようとする。したがって、強化学習トレーニングの間、役に立ちそうな証明者は正しく説得力のあるものに対して報酬が与えられ、卑劣な証明者は不正確で説得力のあるものに対して報酬が与えられる。
チェック可能性トレーニングの主な目的は、完全性と健全性という2つの指標を最適化することである。
完全性:どのようなクエリに対しても、役に立つ証明者は正しい答えを生成し、検証者はそれを正しいと認める。
健全性:どのようなクエリに対しても、検証者は卑劣な証明者が生成した不正確だが説得力のある答えを拒否できる。
したがって、検証可能性トレーニング後の完璧な結果は、検証者が役に立つ回答に対して高い想起率(良好な完全性)を持ち、卑劣な証明者による不正確な回答に対して低い誤検出率(良好な健全性)を持つことである。
前のセクションで述べたように、検証可能性のトレーニングは数ラウンドにわたって実行される。各ラウンドでは、検証者を先に訓練してから、証明者モデルを訓練する。このトレーニングの実施において、注意すべき重要なことが2つある:
1.あるラウンドと別のラウンドの違いは、データの混合のみである。前のラウンドの検証モデルと検証モデルの重みは、次のラウンドには引き継がれない。
2.検証者と証明者は、GPT-4ファミリーのような同じモデルファミリーのものでなければならない。これは次のような質問に答えるのに役立つ:「あるシステムは、特定のサイズ、アーキテクチャ、特定のアルゴリズムで訓練された別のシステムを信頼できるか?
GSMデータセットは、一連の問題とそのグランド・トゥルース解答を含んでおり、チェック可能性のトレーニングに使用される。証明者モデルから提案された解が与えられると、正しさのラベルは、それが真実の解と類似していれば1となり、そうでなければ0となる。
異なる訓練ラウンドにまたがる同じプロンプトに対する証明者の応答例](https://assets.zilliz.com/Example_of_prover_responses_on_the_same_prompt_across_different_training_rounds_82f4b66e0b.png)
異なる訓練ラウンドにまたがる同じプロンプトに対する証明者の応答例]_ ソース..
各ラウンドにおいて、検証者はデータのランダムなサブセットに基づいて教師あり学習で訓練され、標準的な勾配降下で最適化される。次に、諺モデルは強化学習で訓練され、そこでは、ポリシーは等確率で役に立つか卑劣な役割のどちらかに条件付けられる。
そして、証明者の報酬は両方の役割の組み合わせとなる。もし証明者の役割が役に立ち、より多くの正解を生成すれば、より高い報酬が得られる。同様に、もしプロバーの役割が卑劣で、より説得力のある不正解を生み出せば、より高い報酬を得ることになる。また、役割に関係なく、検証者が証明者の提案した解に高いスコアを与えた場合、証明者はより高い報酬を得る。この報酬関数は符号付き相対確信度(SRC:Signed Relative Convincingness)と呼ばれる。
SRCの他に、チェック可能性訓練で実験された報酬のバリエーションが2つある:
それはCorrectness-Gated Convincingness (CGC)である:この報酬関数は、役割アライメントをより優先させる。例えば、親切な証明者がより多くの正解を生成し、卑劣な証明者がより多くの不正解を生成する場合、報酬はより高くなる。
反復グッドハーティング(Iterative Goodharting):この報酬関数は説得力をより優先する。検証者が証明者によって提案された解に高いスコアを与えると、証明者はより高い報酬を得る。
SRC報酬関数による検証可能性トレーニング結果
検証者と証明者の両方が、上述の3種類の報酬関数で5ラウンドにわたって訓練される。最初にテストするのは、SRC報酬を用いた訓練ダイナミクスである。
5ラウンドの各ラウンドにおいて、役に立つ証明者と卑劣な証明者は、訓練が進むにつれて検証者に対する説得力を向上させることができる。一方、各ラウンドで役に立つ証明者が生成する正解の割合は、訓練ステップの間に非単調に変化する。
卑劣な証明者は、検証者を納得させる不正解を生成し始める前に、各ラウンドのステップの最初に正解を生成する。各ラウンドの訓練は、卑劣な証明者によって生成された不正解が、親切な証明者によって生成された正解と同じくらい説得力があるとすぐに停止される。しかし、下の視覚化でわかるように、トレーニング・ラウンドが増えるにつれて、卑劣な証明者は不正確で説得力のある解答を生成するのに苦労するようになる。
SRC報酬関数を用いたチェック可能性トレーニングのダイナミクス](https://assets.zilliz.com/Dynamics_of_checkability_training_using_SRC_reward_function_da35a6cee5.png)
SRC報酬関数を使用した検査可能性トレーニングのダイナミクス]_ ソース..
訓練ラウンドが進めば進むほど、検証者を納得させる不正解を生成するのに時間がかかるため、訓練プロセスを停止させるために必要なステップが増える。しかし、この現象の根本的な原因は不明であり、チェッカビリティ訓練中の親切な証明者と卑劣な証明者間の重み共有が原因である可能性がある。そこで、3つの報酬関数を用いて、卑劣な証明者のみと様々な大きさの検証者との間でチェッカビリティ・トレーニングを行った。
SRC報酬関数とCGC報酬関数を用いた各訓練ラウンドでは、卑劣な証明者が95%の不正解を生成し、不正解に対する検証者の平均スコアが親切な証明者の正解スコアと同じになった時点で訓練が停止される。一方、goodharting報酬関数の場合、検証者スコアの最適化が0.2未満の精度に達した時点で学習を停止する。
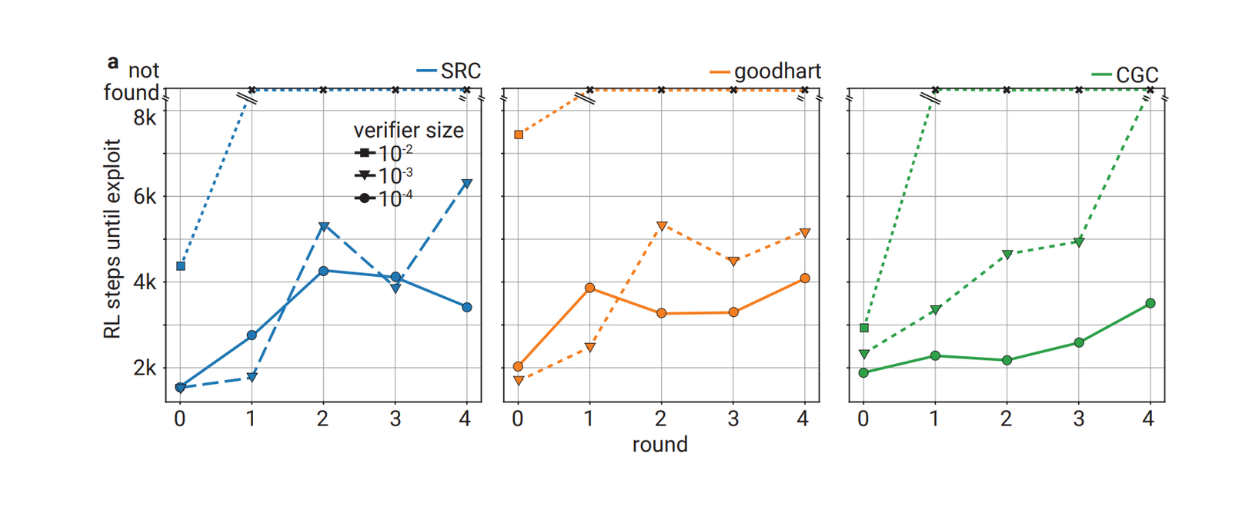 スニーク・オンリー・プローバーが提供する不正解に対する、モデル・サイズの異なる複数の検証器の頑健性
スニーク・オンリー・プローバーが提供する不正解に対する、モデル・サイズの異なる複数の検証器の頑健性
(ソース)(https://arxiv.org/pdf/2407.13692)..
この結果は、以前に見たものと同じような傾向を示している。一般的に、トレーニング・ラウンドに進めば進むほど、狡猾な証明者が検証者を悪用できるようになるには、より多くのステップが必要になります。また、おわかりのように、検証モデルのサイズが大きければ大きいほど、卑劣な証明者が検証モデルを悪用するのが難しくなります。
相対的なサイズが10-2の検証器は、他の2つの小さな検証器よりも悪用が難しい。実際、相対サイズが10-2の検証器は、ラウンド1から、8k強化学習ステップを用いたチェック可能性訓練の最終ラウンドまで、悪用不可能なままである。一方、相対サイズ10-3の検証器は、SRCとgoodharting報酬関数で訓練した場合、依然として利用可能である。それにもかかわらず、この実験により、検証器はチェック可能性訓練を通して不正解に対してより頑健になることが示された。
検証者の動作がわかったところで、次は、卑劣な証明者、特にチェック可能性トレーニングを通して生成される答えの品質に注目しよう。実験の結果、訓練ラウンドに進めば進むほど、卑劣な証明者が生成する不正解はますます微妙になることがわかった。この現象は、GPT-4の妥当性スコアと人間の正確性スコアで確認することができます。
GPT-4による妥当性スコアと、異なる訓練ラウンドにわたって卑劣な証明者によって提供された解答に対する人間の評価者の精度](https://assets.zilliz.com/Validity_score_from_GPT_4_and_the_accuracy_of_human_evaluators_on_answers_provided_by_sneaky_prover_across_different_training_rounds_549ea42fc1.png)
GPT-4の妥当性スコアと、異なる訓練ラウンドにわたって卑劣な証明者によって提供された回答に対する人間の評価者の精度_ ソース..
GPT-4によって生成された妥当性スコアの平均は、異なる訓練ラウンドにわたって増加する。また、人間の契約者が異なるラウンドにわたって卑劣な証明者からの解答を提示された場合、その評価精度は訓練ラウンドに進むほど低下します。このことは、チェック可能性トレーニングを通じて、卑劣な証明者によって生成された不正解がより巧妙になっていくことを物語っている。
 チェック可能性トレーニングが進むにつれて、卑劣な証明者が提供する不正解がより微妙になっていく例
チェック可能性トレーニングが進むにつれて、卑劣な証明者が提供する不正解がより微妙になっていく例
チェッカビリティ訓練が進むにつれて、卑劣な証明者によって提供される不正解がどのように微妙になっていくかの例]_ ソース..
次に、役に立つ証明者について説明します。チェック可能性訓練を通して、役に立つ証明者の精度や正しさは、異なるラウンド間で増加します。しかし、前節で述べたように、この実験の主な目的は、解の正しさだけでなく、人間の評価者にとって読みやすいかどうかもチェックすることである。
これを確認するため、人間の評価者に、各訓練ラウンドで役に立つ証明者モデルによって生成された解を評価してもらった。その結果、正しさが向上する一方で、解の読みやすさも向上していることが示唆された。
下のビジュアライゼーションでわかるように、人間の評価者が役に立つ証明者によって生成された解を評価する精度は、トレーニング・ラウンドを重ねるごとに向上している。それだけでなく、人間の評価者が解をチェックするのにかかる時間も短くなっており、これは役に立つ証明者によって生成された解が人間にとってより読みやすくなっていることを示している。
チェック可能性訓練が進むにつれて、モデルの正しさと人間の評価者の精度が向上する](https://assets.zilliz.com/The_correctness_of_the_model_and_the_accuracy_of_human_evaluators_improve_as_checkability_training_progresses_e567f080ef.png)
チェッカビリティ訓練が進むにつれて、モデルの正しさと人間の評価者の精度が向上する_ ソース..
しかし、正しさと読みやすさの両方について訓練された有用なモデルの精度は、正しさについてのみ訓練されたモデルよりも明らかに低い。これは、答えの読みやすさを向上させるためには、正しさの精度を一定の割合で犠牲にする必要があることを示しています。
他の報酬関数による可読性の学習結果
ここまで、SRC報酬関数を使用したチェック可能性トレーニングの結果を見てきました。次に、前のセクションで述べた他の2つの報酬関数を使ったトレーニング結果を見てみましょう:CGCとIterative Goodhartingです。
CGCは説得力よりも正しさを優先する報酬関数である。従って、親切な証明者が不正確な解を生成した場合、あるいは卑劣な証明者が正しい解を生成した場合、報酬は一定のペナルティとなる。もし彼らが正しければ、報酬は検証者のスコアとなる。
全体的に、CGCを使ったトレーニングのダイナミクスはSRCに比べて悪い。下のビジュアライゼーションでわかるように、卑劣な証明者が検証者を納得させるまでに要するRLステップ数は、異なるトレーニングラウンド間で一貫して増加しません。このような悪いトレーニングダイナミクスのため、CGC報酬を使用したトレーニングでは人間による評価は行われませんでした。
CGC報酬を用いた検証可能性訓練のダイナミクス](https://assets.zilliz.com/The_dynamics_of_checkability_training_using_CGC_reward_function_42688ab629.png)
CGC報酬関数を使用したチェック可能性トレーニングのダイナミクス_ ソース..
CGC以外のもう一つの報酬関数は、反復的なグッドチャートである。この報酬関数には役割が割り当てられておらず、つまり報酬は完全に検証者のスコアに由来する。したがって、正しさよりもむしろ説得力に重点を置く。
訓練ダイナミクスに基づき、検証者はより多くのステップを踏み、訓練ラウンド全体にわたって解を過剰に最適化する。実験結果から、中程度の大きさの検証者(検証者モデルに対して約3x10-3)は、小さい検証者や大きい検証者に比べて、この反復的なグッド・チャート報酬関数を使用したチェック可能性トレーニングから最も利益を得る。
反復グッドチャート報酬関数を用いた検査可能性トレーニングのダイナミクス](https://assets.zilliz.com/The_dynamics_of_checkability_training_using_iterative_goodharting_reward_function_05098f41ef.png)
反復的グッドチャート報酬関数を用いた検査可能性トレーニングのダイナミクス]_ ソース..
しかし、反復グッドハート訓練後の回答を人間の評価者に提示すると、異なる訓練ラウンド間で人間の評価者の精度に顕著な差は見られない。このことは、この報酬関数を使用したチェック可能性トレーニングは、実際には読みやすさを向上させないことを示している。
チェッカビリティ訓練の限界と今後の課題
前のセクションでは、チェック可能性トレーニングがLLMの正しさと人間にとっての読みやすさを向上させるのに役立つことを見てきました。しかし、現在のチェッカビリティ・トレーニングの実装には、いくつかの限界があります。
トレーニングのセットアップでは、モデルの正しさをチェックするために、全ての質問に真正なラベルが必要である。例えば、単純で標準化された解答を含むGSMデータセットは、チェック可能性のトレーニングに使用される。
しかし、標準化されたラベルを持つデータセットを見つけることは現実には非常に困難であり、また、グランドトゥルース解答を収集することは時間とコストがかかる。従って、将来可能性のある研究の1つは、チェッカビリティ学習を教師なし設定に拡張することである。
また、現在のチェッカビリティ訓練は、数学やコーディング問題のような「正解-不正解」が難しい問題に依存している。曖昧さや人間の好みを含むデータでモデルを訓練すると、その性能を定量化することが難しくなる。モデルの最終的な正しさと読みやすさへの影響を見るために、異種セットアップ(すなわち、RLステップ内の早期停止なし)と[ハイパーパラメータチューニング]のさらなる実験が有益であろう。
結論
この記事では、検証者-検証者ゲーム理論にインスパイアされたチェック可能性トレーニングのあらゆる側面について議論した。この訓練アプローチは、LLMが正確な回答を提供し、これらの回答が人間によって理解可能で検証可能であることを保証するための訓練方法を提供する。実験結果は、このアプローチにより、役に立つ証明者の正しさと読みやすさが向上する一方で、卑劣な証明者の不正解がますます微妙になりつつも、ロバストな検証者が検出できるようになることを示している。
その進歩にもかかわらず、検証可能性トレーニングには、標準化されたグランドトゥルースラベルを持つデータセットへの依存や、曖昧な問題領域や主観的な問題領域へのスケーリングの課題など、いくつかの限界がある。これらの課題に対処することは、この手法をより一般的に適用するために重要である。
関連リソース
2024年のトップLLM:価値あるもののみ ](https://zilliz.com/learn/top-llms-2024)
LLM-Eval:LLMの会話を評価するための簡略化されたアプローチ ](https://zilliz.com/learn/streamlined-approach-to-evaluating-llm-conversations)
LoRA (Low-Rank Adaptation)による効率的なLLM微調整 ](https://zilliz.com/learn/lora-explained-low-rank-adaptation-for-fine-tuning-llms)
大規模言語モデルのための知識抽出: 深い掘り下げ ](https://zilliz.com/learn/knowledge-distillation-from-large-language-models-deep-dive)
RouteLLM: LLM導入におけるコストと品質のバランス](https://zilliz.com/learn/routellm-open-source-framework-for-navigate-cost-quality-trade-offs-in-llm-deployment)
RAGとは](https://zilliz.com/learn/Retrieval-Augmented-Generation)
Llama3、Ollama、DSPy、Milvusを使ったRAGの構築](https://zilliz.com/learn/how-to-build-rag-system-using-llama3-ollama-dspy-milvus)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)


