LoRAの説明LLMを微調整するための低ランク適応
LoRA(Low-Rank Adaptation)は、低ランクの学習可能な重み行列を特定のモデル層に導入することで、LLMを効率的に微調整する手法である。
シリーズ全体を読む
- OpenAIのChatGPT
- GPT-4.0と大規模言語モデルの秘密を解き明かす
- 2024年のトップLLM:価値あるもののみ
- 大規模言語モデルと検索
- ファルコン180B大型言語モデル(LLM)の紹介
- OpenAIウィスパー高度なAIで音声をテキストに変換する
- OpenAI CLIPを探る:マルチモーダルAI学習の未来
- プライベートLLMとは?大規模言語モデルをプライベートで実行 - privateGPTとその先へ
- LLM-Eval:LLMの会話を評価するための合理的なアプローチ
- CohereのRerankerを使いこなし、AIのパフォーマンスを向上させる
- PagedAttentionを用いた大規模言語モデルサービングの効率的なメモリ管理
- LoRAの説明LLMを微調整するための低ランク適応
- 知識の蒸留:妥当性を犠牲にすることなく、大規模で計算量の多いLLMから小規模なLLMへ知識を移行する
- RouteLLM: LLM展開におけるコストと品質のトレードオフをナビゲートするオープンソースフレームワーク
- 検証者-検証者ゲームがLLM出力の可読性を向上させる
- 金魚のように、暗記をするな!ジェネレーティブLLMで暗記を軽減する
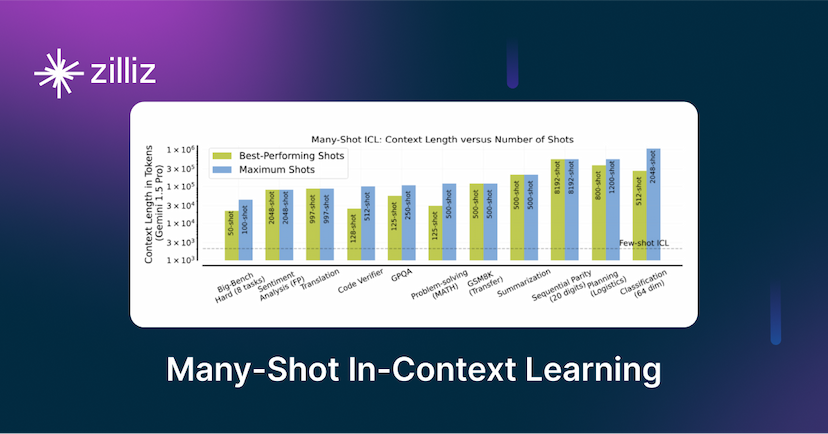
- LLMにおけるメニーショット・インコンテキスト学習のパワーを解き放つ
- 双眼鏡でLLMを発見:機械生成テキストのゼロショット検出
Fine-tuningは、下流のタスクであらゆるディープラーニングモデルのパフォーマンスを最適化するための最も一般的なアプローチです。例えば、BERTモデルの強力な性能をテキスト分類タスクに活用したいとしよう。BERTは大量のデータで学習され、多くのベンチマークデータセットで最先端の性能を達成しているが、我々の特定のデータセットに適用した場合、その性能は最適ではないかもしれない。この場合、微調整を行うことで、我々のデータセットにおけるBERTモデルの性能を最適化することができる。
しかし、ファインチューニングが必要なモデルのサイズが大きくなるにつれて、従来のファインチューニングアプローチの実装はますます困難になります。そこで、LoRA の登場です。
LoRA** (Low-Rank Adaptation)は、低ランクの学習可能な重み行列を特定のモデル層に導入することで、大規模言語モデル(LLMs を効率的に微調整する手法です。これにより、数百億のパラメータを持つ大規模モデルでも微調整が可能になる。この記事では、LoRAとは何か、どのように機能するのかを説明する。まず、そもそもなぜLoRAが必要なのかを探ってみよう。
従来の微調整アプローチの問題点
伝統的なファインチューニングアプローチはシンプルです:事前にトレーニングされたモデルと、ラベル付けされたドメイン固有のデータセットが与えられたら、この特定のデータセットでモデルをトレーニングします。従って、ファインチューニングのプロセスは、教師ありの方法で機械学習モデルをトレーニングすると考えることができる。しかし、ファインチューニングの間、データセット・サイズは巨大である必要はない。データに従って事前学習済みモデルの重みを更新するだけだからだ。
図- ファインチューニングのワークフロー.png](https://assets.zilliz.com/Figure_Fine_tuning_workflow_f45d2f190c.png)
図:微調整ワークフロー
ファインチューニングのプロセスは、基本的に機械学習モデルの教師あり学習と同じであるため、ファインチューニングの速度は少なくとも3つの要因に依存します:ハードウェアの仕様(使用するGPU)、ドメイン固有のデータセットのサイズ、モデルのパラメータ**の数です。ハードウェアの仕様とデータセットのサイズを固定したと仮定すると、ファインチューニングのプロセスは主にモデルのサイズに依存します:モデルのパラメータが多ければ多いほど、ファインチューニングに時間がかかります。
モデルのパラメータが多ければ多いほど、微調整にかかる時間は長くなる。中小規模のディープラーニング・モデルを扱うのであれば、これは大きな問題ではないだろう。しかし、何十億ものパラメーターを持つLLMを微調整しようとすると、そのプロセスは計算とコストの両面で非常に高価になる。そのため、微調整プロセスをより効率的にするソリューションが必要であり、特に現在非常に関連性の高いLLMを扱う場合には、そのようなソリューションが必要となる。
また、前述したように、ファインチューニングの主な目的は、特定のデータセットにおけるモデルの性能を最適化することである。一度ファインチューニングしたモデルの性能は、ファインチューニング時に使用したデータセットと同様の分布を持つ未見のデータを予測する必要がある場合には、良好なものとなる。しかし、もしファインチューニングのデータセットから大きく乖離した未経験のデータがあれば、モデルからの予測は信頼できなくなります。この場合、新しいドメイン固有のデータセットにモデルを再チューニングしなければならない。
ここで、関連性のない2つのドメイン固有のユースケースがあるとします。つまり、それぞれ1つの特定のユースケースにファインチューニングされた2つのモデルになってしまう可能性が高いということです。ベースとなる事前学習済みモデルのサイズがそれほど大きくないのであれば、これは問題ないでしょう。しかし、LLMを使用している場合、同じLLMの複数のバージョンを保存し、それぞれが特定のデータセットで微調整されることは、メモリ管理とストレージの点で非常に非効率的です。
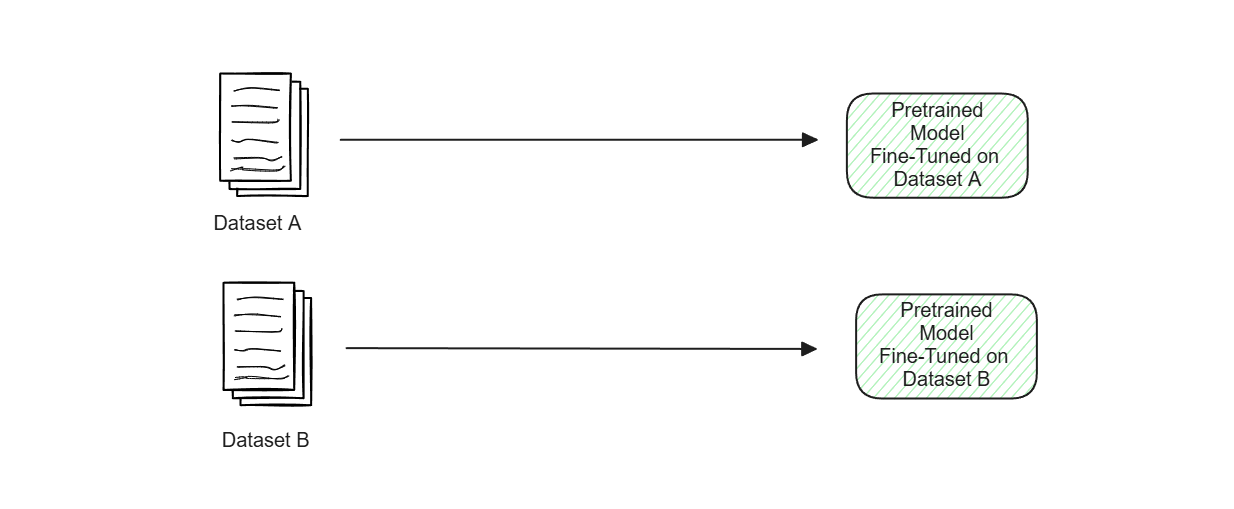 図-2つのドメイン固有のデータセットでファインチューニングされた同じ事前学習済みモデルの2つのバージョン.png
図-2つのドメイン固有のデータセットでファインチューニングされた同じ事前学習済みモデルの2つのバージョン.png
図:2つのドメイン固有のデータセットで微調整された同じ事前学習モデルの2つのバージョン。
したがって、特定のデータで微調整された同じモデルの複数のバージョンを保存する、より良い方法が必要です。次のセクションでは、このような問題に取り組むためのいくつかのアプローチについて説明します。
アダプターと接頭辞チューニングの概念
LoRAが導入される以前、上記のような従来のファインチューニングアプローチに関連する問題を解決するために、いくつかの方法が提案されていた。最初のものは、2019年にHoulsbyらによって導入されたボトルネックアダプター**アプローチである。
ボトルネックアダプターのコンセプトはシンプルだ。ファインチューニングの前に、事前学習したモデルの重みを凍結する。そして、アダプターと呼ばれる、事前学習済みモデルのレイヤー内に、小さな、学習可能なパラメーターのコレクションを導入する。ファインチューニングの間、事前学習済みモデルの全重みの代わりに、これらのアダプタのみを更新する。このアプローチでは、モデル全体の重みの勾配を計算し、各反復でそれらを更新する必要がないため、微調整プロセスが従来のアプローチよりもはるかに高速になります。
図- 通常のファインチューニングとアダプターを使ったファインチューニングの比較.png](https://assets.zilliz.com/Figure_Comparison_between_normal_fine_tuning_vs_fine_tuning_with_adapters_fd227f9ea8.png)
図:通常の微調整とアダプターによる微調整の比較。
さらに、これらのアダプターは簡単に取り外して、事前に訓練されたモデルに挿入することができます。これはアダプタを使用するもう1つの利点です。なぜなら、ドメイン固有のユースケースがいくつかある場合、微調整されたモデルの複数のバージョンを保存する必要はなく、1つの事前学習済みモデルと複数のアダプタを保存することができるからです。ユースケースに応じて、推論中にこれらのアダプタを訓練済みモデルにプラグインすることができます。
Houlsbyによって導入されたボトルネック・アダプタでは、アダプタは2つの通常の密な層と、その間の活性化関数で構成される。最初の密な層は入力をダウンスケールし、2番目の密な層は出力をアップスケールするので、"ボトルネック "と呼ばれる。
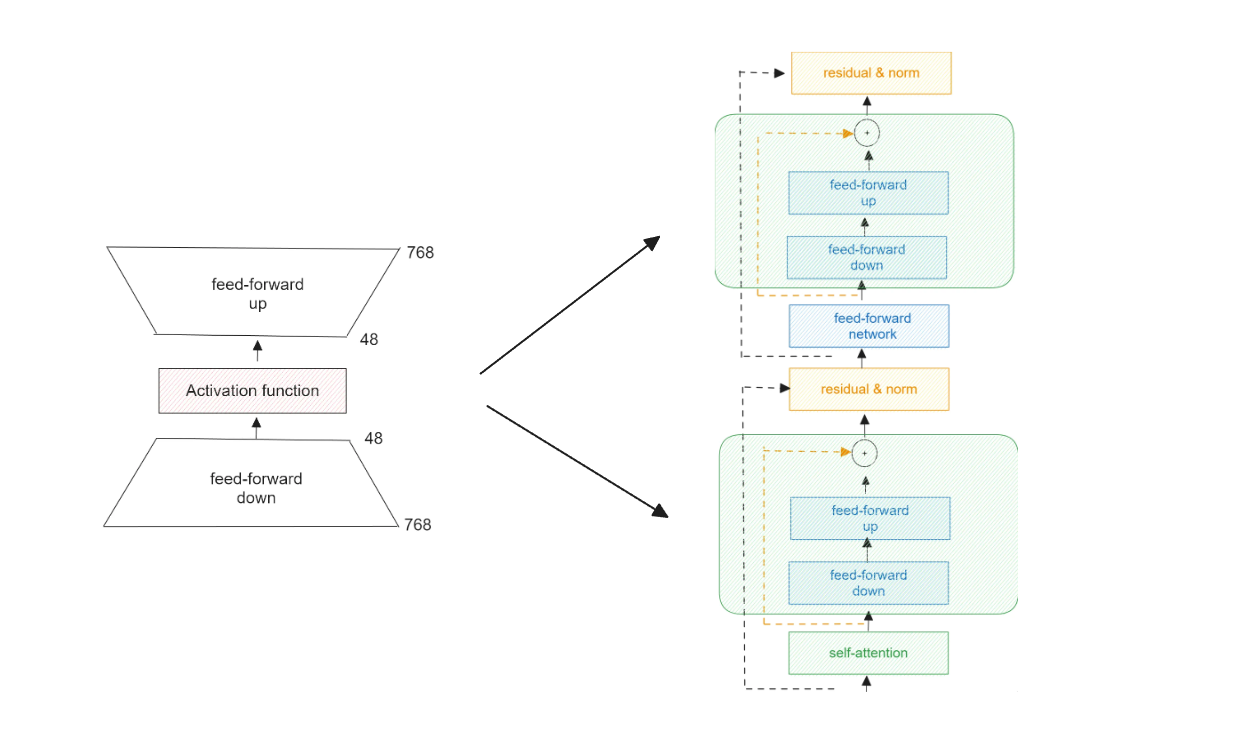 図-ボトルネック・アダプタとHoulsby構成におけるTransformer層への配置.png
図-ボトルネック・アダプタとHoulsby構成におけるTransformer層への配置.png
図:ボトルネック・アダプタとそのトランスフォーマー層への配置(Houlsby構成)。
これらのボトルネックアダプターは、Transformerベースのアーキテクチャを持つモデル内に配置される。Houlsby構成では、各Transformer層内のマルチヘッド注目層と密集層の後に配置される。
Houlsby構成以外にも、一般的な構成がある:Lin、Pfeiffer、AdapterDropである。LinとPfeifferの構成は非常に似ており、各Transformer層内の密な層と正規化層の後にアダプターを配置する。一方、AdapterDropは、Transformer層の一部でアダプターをドロップすることで、手法の効率を向上させる別のアプローチである。
アダプターの主な問題は、アダプターがもたらす余分な計算ステップをバイパスする簡単な方法がないことです。つまり、これらのアダプターを使ったモデルは逐次的にしか処理できず、その結果、モデル推論中の待ち時間が顕著に増加します。
アダプターの適用とは別の解決法として、接頭辞チューニングがあります。接頭辞チューニングでは、「接頭辞」として知られる小さなパラメータセットが導入されます。接頭辞は学習可能な埋め込みで、多くの場合ランダムに初期化されるか、タスク固有の情報に基づいて初期化される。接頭辞は、新しいタスクでモデルがより良いパフォーマンスを発揮できるように導く、追加のプロンプトやコンテキストのような役割を果たします。
接頭辞チューニングの核となる考え方は、アダプタと同じです。事前学習されたモデルの重みを凍結し、接頭辞の埋め込みのみを更新することで、各層の出力を条件付けるタスクに関連した埋め込みを生成するように学習させるのです。
図- 通常の微調整(上)と接頭辞の微調整(下)。.png](https://assets.zilliz.com/Figure_Normal_fine_tuning_top_vs_prefix_fine_tuning_bottom_945ec08321.png)
図:通常の微調整(上)とプリフィックスの微調整(下)_ ソース..
しかし、接頭辞チューニングには少なくとも2つの欠点**があります。第一に、最適化が非常に難しい。第二に、これらの接頭辞のために、モデルの配列長をあらかじめ確保しておく必要があります。その結果、下流タスクの処理に使用できるシーケンス長が減少し、微調整処理後のモデル全体のパフォーマンスに悪影響を及ぼす可能性があります。
LoRAは上記のすべての課題を解決するために導入されたものであり、そのコンセプトについては次のセクションで説明する。
LoRAのコンセプトとその仕組み
LoRAがどのように機能するかを詳しく説明する前に、まず通常の微調整プロセスでモデルの重みがどのように更新されるかを理解する必要があります。
ファインチューニングプロセスは教師あり学習法に似ているため、モデルの重みは、前回の反復の重みを現在の反復の重みの勾配で修正することで更新されます。各重みの勾配は、モデルが学習データを正しく予測するためにどの程度重みを調整する必要があるかを示している。微調整プロセスにおいて、各反復で重みを更新する式は以下のようになる:
方程式1.png](https://assets.zilliz.com/equation_1_bf9c15486a.png)
ここで、Wcurrentは現在の反復の重み、Wpreviousは以前の反復の重み、↪L_1D702↩は学習率、∇Wは重みの勾配である。すべてを簡単にするために、微調整後の重み更新プロセスは以下の式で要約できる:
式2.png](https://assets.zilliz.com/equation_2_590ba8dc9b.png)
ここで、Wは最終的に微調整された重み、W0は事前に学習されたモデルの元の重み、ΔWは微調整プロセスの後に各重みに必要な調整です。説明のために、我々のモデルには9つのパラメータがあり、したがって9つの重みがあるとしよう。重みの更新プロセスは、以下のように2つの行列の形で見ることができます:
図- ファインチューニング後のウェイト更新プロセス(2つの行列の形).png](https://assets.zilliz.com/Figure_Weight_updating_process_after_fine_tuning_in_the_form_of_two_matrices_33bf901854.png)
図:2つの行列による微調整後のウェイト更新過程_図- 2つの行列による微調整後のウェイト更新過程.png
ご想像の通り、モデルが大きくなればなるほど、パラメータは多くなります。モデルのパラメータが多ければ、行列も大きくなり、計算コストも高くなります。
各行列にはランクがあります。行列のランクは、その行列内の線形独立な行または列の最大数を表す。上で可視化した3x3の重み行列を例にとると、各行、各列に以下のような値があるとする:
図- 線形従属列の例(列3は列1に線形従属).png](https://assets.zilliz.com/Figure_Example_of_a_linearly_dependent_column_column_3_is_linearly_dependent_to_column_1_7e7f0623d1.png)
図:線形従属列の例 (列3は列1に線形従属)._.
行列の列3は、列1の各行に5を掛けることで列3を得ることができるので、列1に線形従属であると言える。
LoRAの仮説は、行列から線形に依存する列(この場合は3列目)を何らかの方法で取り除けば、元の行列の情報をあまり失うことなく、本質的に行列の次元を下げることができるというものです。したがってLoRAでは、高次元のフルランクで大きな重み行列を最適化する必要はなく、むしろフルランクの重み行列を低ランクの適応行列に分解します。フルランク元の行列がd x kの次元を持つ場合、行列d x rとr x kを持つ2つの低ランク適応に分解することができます。r_は事前に選択する必要があるハイパーパラメータである。
図- 行列の低ランク適応への分解](https://assets.zilliz.com/Figure_Matrix_decomposition_into_its_low_rank_adaptation_f557be51cb.png)
図:行列の低ランク適応への分解](Figure: Matrix decomposition into its low-rank adaptation.)
上の図に基づき、分解のランクを1とする。おわかりのように、元の重みを更新するために保存するパラメータが少なくなるため(元の行列の9から、行列Aの3+行列Bの3)、微調整計算のパフォーマンスが向上するはずです。想像できるように、元の行列の次元が大きければ大きいほど、それを低ランクの適応行列に分解することで得られる性能利得は高くなります。
ただし、選択するrの値に注意する必要がある。r_の値が低すぎると、元の行列から多くの情報を失うことになる。微調整プロセスにおける重みの更新プロセスは以下の式に従う:
式3.png](https://assets.zilliz.com/equation_3_e7c9717cf5.png)
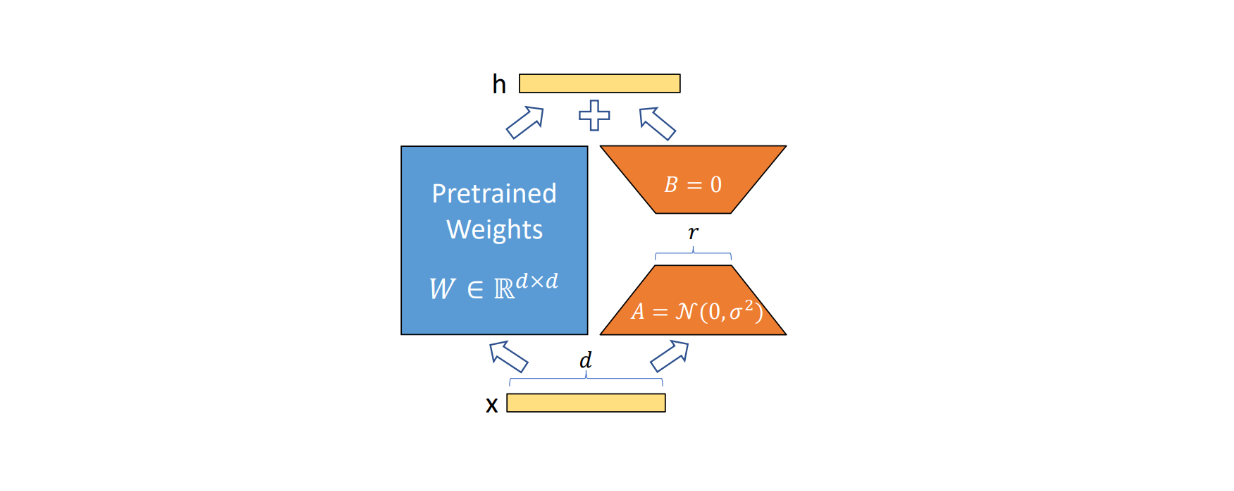 図- LoRA微調整ワークフロー.png
図- LoRA微調整ワークフロー.png
図:LoRA微調整ワークフロー._ ソース..
ここで、Wは更新された重み、W0は元の訓練前の重み、AとBはΔWの低ランク分解である。
B.Aの結果もα/rでスケーリングされる。微調整の過程でいくつかのr値をテストすることにした場合、通常αの値はテストする最初のr値に等しく設定する。
ボトルネックアダプターとは異なり、LoRAは推論時間中に追加的な待ち時間を発生させない。これは、W = W0 + BAで特定のドメイン固有タスクのモデルの重みを明示的に更新できるからである。別のドメイン固有のタスクに切り替える必要があるときは、BAを減算し、異なるB'A'をW0に追加することで、元の事前学習された重みW0を回復できる。また、モデルを微調整するためのプリフィックスチューニングのように、シーケンスに追加のスペースを確保する必要もない。
LoRA による実験結果
LoRAの性能をAdaptersやPrefix tuningのような他の手法と比較するために、論文の著者は、いくつかのベンチマークデータセット上で、これら全ての手法でファインチューニングされた複数のディープラーニングモデルをテストした。
具体的には、通常のファインチューニング手法(FT)、Houlsby(Adpt H)、Lin(Adpt L)、Pfeiffer(Adpt P)、AdapterDrop(Adpt D)、Prefix-embeddingチューニング(PreEmbed)、Prefix-layerチューニング(PreLayer)、バイアスベクトルのみのファインチューニング(BitFiT)、LoRAを用いて、RoBERTa、DeBERTa、GPT-2モデルをファインチューニングした。
図-RoBERTA、DEBERTA、GPT-2における、複数のベンチマークデータセットに対する異なるファインチューニングアプローチのテスト結果。.png](https://assets.zilliz.com/Figure_Ro_BERTA_DEBERTA_and_GPT_2_test_results_with_different_fine_tuning_approaches_on_several_benchmark_datasets_0339dc5b05.png)
図:RoBERTA、DEBERTA、GPT-2のテスト結果と複数のベンチマークデータセットにおける異なる微調整アプローチ_ ソース..
上の表から、LoRAの性能はテストされた全てのモデルで高い競争力を持つことがわかります。また、LoRAのアプローチは、ほぼ全てのベンチマークデータセットにおいて、他のファインチューニング手法を凌駕しています。印象的なのは、LoRAを使うことで、学習可能なパラメータのほんの一部で、通常のファインチューニングと比較して、同等かそれ以上のファインチューニングモデルが得られるということです。
LoRAの能力をさらに検証するために、著者らはWikiSQLやMNLIのようなデータセット上で、約175Bのパラメータを持つGPT-3モデルにもこのアプローチを適用した。LoRAによるモデル微調整後の検証精度は、通常の微調整や他の手法を常に上回っていることがわかる。
図:WikiSQLとMNLIデータセットにおける異なるファインチューニングアプローチでのGPT-3テスト結果](https://assets.zilliz.com/Figure_l_GPT_3_test_results_with_different_fine_tuning_approaches_on_Wiki_SQL_and_MNLI_datasets_4ac937f0d0.png)
図:WikiSQLとMNLIデータセットにおけるGPT-3のテスト結果。_ ソース..
LoRAが強力なモデル微調整手法であることはわかりましたが、どの重み行列にLoRAを適用すべきかという疑問が残ります。現在、ほとんどのLLMはTransformerアーキテクチャに基づいていることから、著者らはGPT-3モデルの各Transformer層内の自己注意モジュールに対してのみLoRA法をテストした。
LoRAは、WikiSQLやMNLIのような前述の同じベンチマークデータセット上で、クエリ(Wq)、値(Wv)、キー重み(Wk)のような、自己注意モジュール内部のいくつかの重み行列に適応された。下の表で実験結果を見ることができる:
図-GPT-3においてLoRAを適用したWikiSQLとMultiNLIの検証精度.png](https://assets.zilliz.com/Figure_Validation_accuracy_on_Wiki_SQL_and_Multi_NLI_after_applying_Lo_RA_to_different_types_of_attention_weights_in_GPT_3_e7a2d79379.png)
図:GPT-3におけるWikiSQLとMultiNLIの検証精度._ ソース..
クエリ重みと値重みの両方にLoRAを適用し、ランクを4にした場合、最適なファインチューニングモデルが得られることがわかります。
前述したように、ランク(r)値は事前に選択する必要があるハイパーパラメータです。問題は、扱う重み行列の最適な固有ランクがわからないことだ。この問題に対処するため、著者らはLoRAをさまざまなr値でテストしました。その結果が下の表である:
図- WikiSQLとMultiNLIにおける異なるランクでの検証精度](https://assets.zilliz.com/Figure_Validation_accuracy_on_Wiki_SQL_and_Multi_NLI_with_different_rank_d1383cc284.png)
図:WikiSQLとMultiNLIの異なるランクにおける検証精度 _ Source..
この結果は、クエリ重み行列と値重み行列の両方にLoRAを適用した場合、r値が1という小さな値でも高い競争力を持つ結果が得られることを示しています。
LoRAの実装
このセクションでは、Hugging Faceライブラリを使ったLoRAの実装例を紹介します。具体的には、簡単なセンチメント分類問題に対して、IMDBデータセット上でBERTモデルを微調整します。Hugging Faceを使ってLoRAを実装するには、PEFTライブラリを使います。必要なライブラリをすべてインストールしましょう:
pip install -q transformers
!pip install -q peft
!pip install -q evaluate
次に、データセットをロードしよう。IMDBデータセットは25,000エントリーで構成されているが、微調整のために小さなサブセット(1,000エントリー)のみを使用する。まず、データセット全体をトークン化し、トークン化されたデータからランダムに1,000エントリーを選択する。
from datasets import load_dataset
from transformers import AutoTokenizer
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
データセット = load_dataset("imdb")
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenized_datasets = dataset.map(tokenize_function, batched=True)
ft_train = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
ft_val = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
それでは、BERT モデルをロードし、LoRA 構成を設定しましょう。LoRA 構成には、rank = 1 と alpha = 1 を使用します。次に、PEFTライブラリからget_peft_modelメソッドを使用して、この構成を使用してLoRA搭載BERTをインスタンス化します。
from peft import LoraConfig, TaskType
from transformers import BertForSequenceClassification
from peft import get_peft_model
lora_config = LoraConfig(
task_type=TaskType.SEQ_CLS, r=1, lora_alpha=1, lora_dropout=0.1
)
model = BertForSequenceClassification.from_pretrained(
'bert-base-cased'、
num_labels=2
)
lora_model = get_peft_model(model, lora_config)
def count_parameters(model):
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
all_params = sum(p.numel() for p in model.parameters())
trainable_percentage = 100 * trainable_params / all_params
return trainable_params, all_params, trainable_percentage
trainable_params, all_params, trainable_percentage = count_parameters(lora_model)
print(f "trainable params:訓練可能なパラメータ: {trainable_params}|| すべてのパラメータ全パラメータ: {all_params}|| trainable%:{{trainable_percentage}}")
# 出力
trainable params:38402 || すべてのパラメータ:108350212 || trainable%:0.03544247795288116
おわかりのように、LoRAを使えば、約38kの重みを更新するだけで済む。これはBERTの総重量の0.035%に相当する。
最後に、モデルを微調整します。メトリクスには標準的な精度メトリクスを使用し、25エポックで微調整を行います。以下は微調整プロセスを実行するコードです。
numpy を np としてインポートする。
import evaluate
import wandb
from transformers import TrainingArguments, Trainer
wandb.init(mode="disabled")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
metric = evaluate.load("accuracy")
training_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch"、
num_train_epochs=25,)
trainer = Trainer(
model=lora_model、
args=training_args、
train_dataset=ft_train、
eval_dataset=ft_val、
compute_metrics=compute_metrics、
)
trainer.train()
結論
LoRAは、LLMを含むあらゆるモデルを微調整するための強力で効率的な手法を提供する。この手法は、従来の微調整手法で発生するモデル重みの保存と計算の課題を解決する。大きな重み行列を低ランクの適応に分解することで、LoRAは、モデルの元の事前訓練された重みを変更することなく、いくつかのドメイン固有のタスクに対してモデルを微調整することを可能にする。
アダプタ、プレフィックスチューニング、さらには完全なファインチューニングのような他のファインチューニング手法と比較して、LoRAは、学習可能な重みのほんの一部だけで、いくつかの最先端のモデルやベンチマークデータセットで優れた性能を達成した。LLMが進化していく中で、LoRAはLLMを微調整するための費用対効果が高くスケーラブルなソリューションとして際立っている。
参考文献
microsoft/LoRA: "LoRA: Low-Rank Adaptation of Large Language Models "の実装であるloralibのコード](https://github.com/microsoft/LoRA)
RAGアプリ構築のベストプラクティス](https://zilliz.com/blog/best-practice-in-implementing-rag-apps)
ColPali: Better Document Retrieval with VLMs and ColBERT Embeddings ](https://zilliz.com/blog/colpali-enhanced-doc-retrieval-with-vision-language-models-and-colbert-strategy)
Distilbert:より小さく、より速く、そして蒸留されたBERT](https://zilliz.com/learn/distilbert-distilled-version-of-bert)
ColBERT: トークンレベルの埋め込みとランキングモデル](https://zilliz.com/learn/explore-colbert-token-level-embedding-and-ranking-model-for-similarity-search)
長文テキストのための文変換器](https://zilliz.com/learn/Sentence-Transformers-for-Long-Form-Text)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
データに適した埋め込みモデルの選択】(https://zilliz.com/blog/choosing-the-right-embedding-model-for-your-data)