




双眼鏡でLLMを発見:機械生成テキストのゼロショット検出
このブログでは、機械が作成したテキストを検出する必要性の高まり、過去の検出方法、そして新しいアプローチについて説明する:双眼鏡
シリーズ全体を読む
- OpenAIのChatGPT
- GPT-4.0と大規模言語モデルの秘密を解き明かす
- 2024年のトップLLM:価値あるもののみ
- 大規模言語モデルと検索
- ファルコン180B大型言語モデル(LLM)の紹介
- OpenAIウィスパー高度なAIで音声をテキストに変換する
- OpenAI CLIPを探る:マルチモーダルAI学習の未来
- プライベートLLMとは?大規模言語モデルをプライベートで実行 - privateGPTとその先へ
- LLM-Eval:LLMの会話を評価するための合理的なアプローチ
- CohereのRerankerを使いこなし、AIのパフォーマンスを向上させる
- PagedAttentionを用いた大規模言語モデルサービングの効率的なメモリ管理
- LoRAの説明LLMを微調整するための低ランク適応
- 知識の蒸留:妥当性を犠牲にすることなく、大規模で計算量の多いLLMから小規模なLLMへ知識を移行する
- RouteLLM: LLM展開におけるコストと品質のトレードオフをナビゲートするオープンソースフレームワーク
- 検証者-検証者ゲームがLLM出力の可読性を向上させる
- 金魚のように、暗記をするな!ジェネレーティブLLMで暗記を軽減する
- LLMにおけるメニーショット・インコンテキスト学習のパワーを解き放つ
- 双眼鏡でLLMを発見:機械生成テキストのゼロショット検出
大規模言語モデル](https://zilliz.com/glossary/large-language-models-(llms))(LLMs)の進歩により、人間が書いたテキストと機械が生成したテキストを区別することが難しくなっている。これらのモデルがより人間に近い出力を生成するようになったため、かつては初期のモデルに有効であった伝統的な検出方法は時代遅れになりました。多くのアプローチ、特にChatGPTに合わせたアプローチは、学習データに大きく依存しており、異なるモデルやドメイン間で一般化するのに苦労しています。
Binoculars**](https://arxiv.org/pdf/2401.12070)と呼ばれる新しい検出方法は、既存の方法の限界に対処するために開発された。Binoculars]()と呼ばれる新しい検出手法が開発された。この手法は、モデル固有の訓練なしに機械生成テキストを検出するために、複 雑性と交差複 雑性の比を用いた新しいアプローチを導入している。このアプローチはChatGPTだけでなく、複数のLLMからのテキストを正確に検出することができる。
双眼鏡はゼロショット検出において最先端の精度を達成。既存のオープンソースの手法を凌駕し、商用APIと競合するか、凌駕する。高い真陽性率(TPR)と非常に低い偽陽性率(FPR)を誇ります。さらに、Binocularsはプロンプト依存性などの一般的な課題を克服しています。また、パープレキシティとクロスパープレキシティの比率を用いることで、文体の変化や敵対的なテキスト改変に対する頑健性も維持しています。
図:複数の検出器にわたるChatGPT生成テキストの検出](https://assets.zilliz.com/Figure_Detection_of_Chat_GPT_generated_text_across_several_detectors_de15de9268.png)
図:複数の検出器にわたるChatGPT生成テキストの検出|出典
このブログでは、機械生成テキストを検出する必要性の高まり、過去の検出方法、そして新しいアプローチについて説明します:Binocularsです。また、Binocularsがどのように機能するのか、様々なシナリオにおける堅牢性と信頼性についても説明します。包括的な理解については、こちらのBinocular 論文をご参照ください。
なぜ検出方法が重要なのか?
大規模言語モデル(LLM)がより高度になり、広く利用されるようになるにつれて、その潜在的な利点は、悪用された場合の大きなリスクを伴っている。このような課題に対処するためには、信頼性の高い検出方法が不可欠です。例えば
アカデミック・インテグリティの課題:** LLMを盗用したり、学術的な研究を不正に支援するために使用することは、倫理的な懸念を引き起こしている。効果的な検出は、教育機関の信頼性を守ることができる。
誤報と悪意のある利用:**【LLM】(https://zilliz.com/learn/top-llms-2024)が広く利用可能になったことで、悪意のある行為者がボットを作成し、偽のレビューを生成し、ソーシャルメディアで誤報を広めることが可能になった。このような悪用は、確実に検知されることなく、社会的信用を損ない、デジタル・エコシステムに害を及ぼす可能性がある。
バイアスおよび倫理的懸念:***検出方法は、LLMからの偏ったまたは有害な出力を発見し、減らすのに役立ちます。これにより、より倫理的なAIの導入に貢献することができる。
従来のLLM検出の問題点
従来のLLM検出方法には第一の問題がある。統計的シグネチャや特定の言語モデルに特化した学習データに依存している。そのため、ゼロショット設定では効果がない。主な課題は以下の通り:
モデル固有のトレーニング:** 従来の検出器の多くは、ChatGPTのような特定の言語モデルからのデータでトレーニングされています。これは、トレーニングされていない他のLLMからのテキストを識別するのに苦労することを意味します。この適応性の欠如は、LLMの数が増えるにつれて重大な制限となります。
Lack of** Generalization: 伝統的なアプローチは、異なるテキストドメインや言語間での汎化に失敗することが多い。エッセイのような特定のタイプのテキストで訓練された検出器は、他のタイプのテキストでは性能が低いかもしれない。例えば、ニュース記事や異なる言語のテキストでは苦戦するかもしれない。
誤検出: **従来の方法では、高い誤検出率が生じる可能性がある。特に英語を母国語としない人が書いたテキストは、機械が作成したものとして誤ってラベル付けされることが多い。この誤認識は、テキストがドメイン外のソースから来た場合により頻繁に起こる。
新しいモデルに適応できない:**既存の手法は、モデル固有の学習データに依存するため、新しいモデルに適応できないことが多い。
Binoculars法は、ターゲットLLMからの学習データを必要としないゼロショット・アプローチにより、これらの制限を克服します。どのように機能するかを探ってみよう。
双眼鏡の仕組み二眼式アプローチ
Binocularsメソッドでは、テキストを分析するために2つのモデルを使用します。LLMと "パフォーマー"LLM。パープレキシティ(テキストがモデルにとってどの程度驚くべきものであるか)とクロスパープレキシティ(あるモデルの予測が別のモデルにとってどの程度驚くべきものであるか)を比較することで検出スコアを計算する。このメカニズムにより、Binocularsはソースモデルからの特定の学習データがなくても、機械が作成したコンテンツを識別することができます。
Binocularsがどのように機能するか、ステップバイステップで説明します:
トークン化
トークン化は、文字列をトークンに変換するプロセスです。与えられた文字列Šはまずトークンに変換される。これらのトークンはインデックスxのリストとして表現され、各インデックスxiは言語モデルの語彙↪L_1D4↩の特定のエントリに対応します。語彙ᵉは1から𝑛までの整数の定義済みセットで、トークンをモデルが使用する数値表現にマッピングします。
パープレキシティの計算
まず、このメソッドは「オブザーバー」LLM(M1とする)を使って、入力文字列𝑠の対数プレプレキシティ(log-PPL)を計算する。これは与えられたテストが言語モデルにとってどれだけ「驚き」であるかを測定する。
複雑度が高いほど、そのテキストは予測可能性が低いか、モデルにとって驚くべきものであることを示します。
パープレキシティが低いほど、モデルはそのテキストに自信があり、機械が生成したコンテンツと関連していることを示す。
しかし、プロンプトの影響により、当惑度だけでは不十分である。数学的には、log perplexity (log PPL)は与えられたシーケンス内のすべてのトークンの平均負の対数尤度として定義される:
(https://assets.zilliz.com/log_perplexity_log_PPL_246e300e8b.png)
ここで
- L は ↪Ll_1D460 のトークン数。
- Y=M1(x)=M1(T(s))は、トークン列に対してモデルM1によって予測される語彙上の確率分布である。
交差複雑度の計算
次に、このメソッドは、「パフォーマー」LLM M2 を使って同じテキストのネクストトークン予測を生成することを含む、交差当惑度(X-PPL)を計算する。次に、「オブザーバー」LLM M1に従って、これらの予測の当惑度を計算する。これはsのトークン化で動作するときのM1とM2の出力間のトークンごとの平均クロスエントロピーである:
(https://assets.zilliz.com/cross_perplexity_X_PPL_04f6c4bc5e.png)
双眼スコア
Binoculars法の核となるのはBinocularsスコアであり、これは対数プレプレキシティと対数クロスプレプレキシティの比である。このスコアは以下のように計算される:
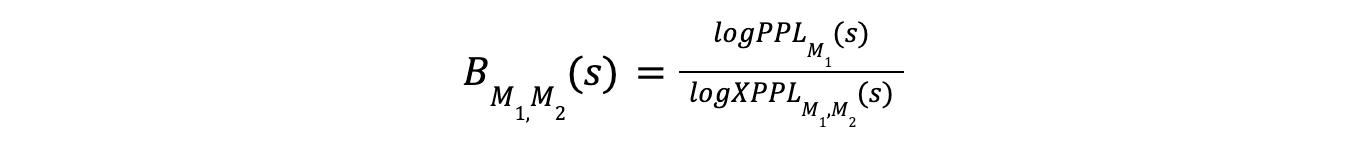
ここで
分子のlogPPLM(s)は、文字列がオブザーバー・モデルに対してどれだけ驚くべきものであるかを測定する。
分母logXPPLM1,M2(s)は、M1を観察したとき、演奏者モデルM2のトークン予測がどれだけ驚くかを測定する。
比率は正規化された尺度を提供する。これは、perplexityまたはcross-perplexity単独よりも、人間が生成したテキストと機械が生成したテキストを区別するのに効果的である。
"カピバラ問題 "への対応
双眼スコアの分母にクロス・パープレキシティを使用することは、"カピバラ問題 "に対処するための正規化因子として機能する。この問題とは、プロンプトが当惑度に大きな影響を与えるという事実を指す。プロンプトは、機械が驚くほど複雑なテキストを生成する原因となり、人間が書いたテキストと間違われるような高い当惑度スコアにつながる可能性がある。
検出
双眼鏡は文字列内のトークンが意外なものであるかどうかを、当惑度と交差当惑度の比を見て判断する。この判定は、同じ文字列に作用するLLMの期待されるベースライン当惑度との相対関係で行われる。
この方法は、人間が生成したテキストは、observerモデルの予想から乖離する可能性が高いという考えに基づいている。対照的に、performerモデルの予測は、2つのLLMがどちらかが人間に対してよりも互いに似ていることを考慮すると、より一致する。Binocularsのスコアが低いほど、機械が作成したテキストである可能性が高く、スコアが高いほど、人間が書いたテキストである可能性が高いことを示しています。
実験セットアップ:データ、ベースライン、評価指標
様々なシナリオにおけるBinocularsのパフォーマンスを検証します。まず、Binocularsがどのようにテストされ評価されたのか、その主な詳細を確認しましょう。これには、使用したデータセット、検出しきい値の調整プロセス、比較のためのベースライン手法の選択などが含まれる。
データセットの作成:***機械が作成したテキストを検出するBinocularsの能力を評価するため、CC News、CNN、PubMedから入手した人間が書いたサンプルを使ってデータセットを作成した。
各人間サンプルの最初の50トークンをプロンプトとして使用。このプロンプトは、LLaMA-2-13BとFalcon-7Bを用いて、最大512トークンの機械生成テキストを生成した。
その後、元の人間のプロンプトは削除され、機械生成テキストのみがデータセットに使用された。
領域外閾値の調整:***検出器は、極めて低い偽陽性率(FPR)を維持しながら、その真陽性率(TPR)に基づいて評価された。
閾値は、複数の参照データセットからの訓練分割を組み合わせて決定された。この閾値は、テキストを機械生成か人間が書いたものかに分類するのに役立つ。すべての参照データセットはChatGPTを使って生成された。
閾値は、選択されたすべてのデータセットにわたる精度を用いて最適化された。固定のグローバル閾値を使用して、機械と人間のテキストを分離した。特に断りのない限り、各文書は512トークンの接頭辞を使って評価された。
ベースライン詳細:** ベースライン手法は、ポストホック、アウトオブドメイン(ゼロショット)、ブラックボックス検出のシナリオにおける適用可能性に基づいて選択された。
選択されたベースラインには、Ghostbuster、市販のGPTZero、DetectGPT、Fast-DetectGPT、DNA-GPT.が含まれる。
Binocularsとの公平な比較のため、すべてのベースラインの「ドメイン外」バージョンを使用した。
DetectGPTでは、LLaMA-2-13Bモデルをスコアリングに使用し、LLaMA-2-13Bを使用して生成されたデータセットであっても、マスク充填にはT5モデルを使用した。
Fast-DetectGPTでは、GPT-J-6BとGPT-Neo-2.7Bを参照モデルとスコアリングモデルとして使用した。
DNA-GPTでは、接尾辞予測にgpt-3.5-turbo-instruct APIを用いた。
双眼鏡の一次評価指標
機械生成テキストの検出器としてのBinocularsメソッドの性能は、いくつかの主要なメトリクスを使って評価されます:
低い偽陽性率(FPR)での真陽性率(TPR):** この測定基準は、検出器が機械生成テキストをどの程度識別できるかを測定するため重要です。また、人間のテキストを機械生成と誤ってラベル付けする可能性も最小限に抑えます。この評価では、低FPR(例えば0.01%)におけるTPRに明確に焦点を当てています。
精度と再現率:** これらのメトリクスは、多言語環境、特に低リソース言語における検出器のパフォーマンスを評価します。Precisionは、機械生成としてラベル付けされたすべてのテキストのうち、正しく識別された機械生成テキストの割合を示し、Recallは、実際に機械生成されたすべてのテキストのうち、正しく識別された機械生成テキストの割合を測定します。
F1-Score:**F1-Scoreは、領域外の閾値を使用してモデルのパフォーマンスを評価するために使用されます。F1-Scoreは、できるだけ多くの機械生成テキストを識別しながら(リコール)、識別されたものがほとんど正しいことを保証する(精度)バランスをとる単一の値を提供します。
多様なシナリオにおける双眼鏡の検出性能
ゼロショットLLM検出器としてのBinoculars法は、複数のドメインとシナリオにわたって評価された。評価の目的は、特に既存の検出手法と比較した場合のBinocularsの精度と信頼性を示すことである。
ChatGPT検出におけるBinocularsベンチマーク性能
Binoculars法はニュース記事、創作文のサンプル、学生のエッセイを含むデータセットを使って評価されます。これらのデータセットはChatGPTによって作成された同数の人間が書いたサンプルと機械が作成したサンプルでバランスが取られています。双眼鏡は機械生成テキストと人間が書いたテキストを高い精度で分離する。真陽性率(TPR)は90%以上、偽陽性率(FPR)はわずか0.01%です。この性能はChatGPTデータに対する訓練なしで達成されており、ゼロショット能力を示している。
BinocularsはGPTZeroのような商用システムと、Ghostbuster、DetectGPT、Fast-DetectGPT、DNA-GPTなどのオープンソース検出器の両方を凌駕しています。これらのベースライン検出器の中には、ChatGPT出力を検出するために特別に調整されたものさえあります。
図:ChatGPTからの機械生成テキストの検出](https://assets.zilliz.com/Figure_Detection_of_machine_generated_text_from_Chat_GPT_97ef4bfcff.png)
図:ChatGPTからの機械生成テキストの検出|ソース
さらに、Binocularsの検出性能は情報量が多いほど向上し、少ないトークン数でも検出できることを示している。
図:文書サイズが検出性能に与える影響](https://assets.zilliz.com/Figure_Impact_of_document_size_on_detection_performance_74f70bff05.png)
図:文書サイズが検出性能に与える影響|出典
様々なLLMの検出 (ChatGPTを超えて)
BinocularsはChatGPTだけでなく、LLaMA-2やFalconといった他のLLMにも検出機能を拡張しています。Binocularsはモデル固有の修正を必要とせず、これらのモデルで生成されたテキストを検出する精度を維持します。
対照的に、ChatGPT用に調整されたGhostbusterのような他の検出器は、LLaMA-2のような他のLLMからのテキストを確実に検出するのに苦労しています。BinocularsはLLaMA-2世代を検出する際、他の方法よりも低いFPRで高いTPRを達成する。
図:LLaMA-2-13B世代の検出](https://assets.zilliz.com/Figure_Detecting_L_La_MA_2_13_B_generations_6377e87d27.png)
図:LLaMA-2-13B世代の検出|出典
野生の双眼鏡:信頼性と堅牢性
Binocularsの信頼性は異なる言語やドメインを含む多様なテキストソースで評価された。BinocularsはMulti-generator、Multi-domain、Multi-lingual (M4)データセットを使い、ドメイン間で効果的に汎化することができる。これらのドメインにはArxiv、Reddit、Wikihow、Wikipediaが含まれます。また、ウルドゥー語、ロシア語、ブルガリア語、アラビア語など、様々な言語でも優れた性能を発揮する。
図:M4データセットから様々なドメインにおけるChatGPT生成テキストの検出](https://assets.zilliz.com/Figure_Detection_of_Chat_GPT_generated_text_in_various_domains_from_M4_Dataset_2805c8e5f0.png)
図:M4データセットから様々なドメインにおけるChatGPT生成テキストの検出|出典
双眼鏡はこれらのドメインや言語において精度が高く、人間が書いたテキストを機械生成と誤認識する可能性が低い。
図:様々な生成モデルのサンプルに対するBinocularsのパフォーマンス](https://assets.zilliz.com/Figure_Performance_of_Binoculars_on_samples_from_various_generative_models_9420fbc82c.png)
図:様々な生成モデルのサンプルに対するBinocularsの性能|出典
しかし、低リソース言語では再現率が低く、機械生成テキストを検出できない可能性がある。
図:Binocularsの低いリコール ](https://assets.zilliz.com/Figure_Binoculars_low_recall_1dd42b7969.png)
図:双眼鏡の低リコール|出典
重要なのは、Binocularsは英語を母国語としない人が書いたテキストのバリエーションを扱えることです。非ネイティブの英文を機械が作成したものとして誤分類することの多い多くの市販の検出器とは異なり、Binocularsは一貫した精度を示しています。Binocularは、非ネイティブが書いたオリジナルのエッセイでも、文法補正されたものでも、同じように優れた性能を発揮します。
図:Binocularsのスコア分布](https://assets.zilliz.com/Figure_Distribution_of_Binoculars_scores_1eaf32cdc5.png)
図:双眼鏡の得点分布|出典
暗記テキストのパフォーマンス
Binocularsの動作は、名言のような記憶されたテキストに遭遇した場合にも評価される。パープレクシティに基づく検出器では、暗記された例は機械的に生成されたものとして分類されるかもしれませんが、Binocularsはこの種のデータで良好な性能を発揮します。
例えば、合衆国憲法は機械生成の範囲内のスコアを得たが、他の有名なテキストは人間が書いたものとして正しく識別された。ボブ・ディランの2曲、"Blowin' In The Wind "と "To Fall In Love With You "は、その知名度に関係なく、正確に人間が書いたとラベル付けされている。このことは、Binocularsが当惑度だけに頼らず、よりロバストな検出アプローチを持っていることを示している。
図:LLMが記憶している可能性の高いテキストサンプル ](https://assets.zilliz.com/Figure_Text_samples_likely_to_be_memorized_by_LL_Ms_40bf66af7c.png)
図:LLMが記憶しやすいテキストサンプル|出典
プロンプティング戦略の変更による影響
Binocularsは異なるプロンプティング戦略を用いても効果的であり続ける。Open Orcaデータセットを使用すると、BinocularsはGPT-3生成サンプルの92%、GPT-4生成サンプルの89.57%を検出できる。カール・セーガンのスタイルで書いたり、ロボットのような言い回しを避けたり、あるいは海賊のような口調を採用するなど、プロンプトが定型化された場合でも、この手法は精度を維持する。
図:修正したOpen-Orcaのサンプルプロンプト](https://assets.zilliz.com/Figure_Open_Orca_sample_prompt_with_modifications_8be9537698.png)
図:Open-Orcaのサンプルプロンプトを修正したもの| 出典
海賊版のような出力は最も大きな影響を与えますが、検出器の感度をわずかに低下させるだけです。これはBinocularsが生成テキストの文体の変化に強いことを示している。
図:システム・プロンプトを変更した場合の検出 ](https://assets.zilliz.com/Figure_Detection_with_modified_system_prompts_e0b5b197d9.png)
図:システム・プロンプトを変更した場合の検出|出典
ランダム性の処理
Binocularsにおけるランダム・トークンの影響も評価された。Binocularsはランダムなトークンの並びを人間が書いたものとして自信を持ってスコア付けする。これは訓練されたLLMがこのようなランダムなシーケンスを生成する可能性が極めて低いためである。
ランダムなトークン列に対するBinocularsのスコアは閾値の人間側に位置する。これは、このようなシーケンスが言語モデルによって生成される可能性は、人間によって生成される可能性よりもさらに低いことを示しています。
図:ランダムなトークン列の結果 ](https://assets.zilliz.com/Figure_Random_token_sequence_result_906bbf077d.png)
図:ランダムトークン列の結果|出典
双眼鏡の重要な意義
Binoculars法は重要な意味を持ち、これまでの手法の多くの制限を克服する強固なアプローチを提供する。
ゼロショット検出:** BinocularsはテストされるLLMの特定の学習データを必要とせず、機械が生成したテキストを検出できる。これは重要な利点であり、追加訓練なしで新しい言語モデルや未見の言語モデルにこの手法を適用できる。
領域横断的な堅牢性:** Binoculars法は異なるテキストソースや言語間で効果的であり、検出への一般化可能なアプローチを示している。この方法は狭い範囲に限定されず、様々なテキストタイプに適用されるため、これは重要です。
モデルにとらわれない:**この手法は単一のLLMの検出に限定されません。モデル特有の修正を加えることなく、様々な最新のLLMからテキストを識別することができます。機械が生成したテキストのソースが不明であったり、多様であったりする様々なアプリケーションに適用できる。
カピバラ問題への対処:**双眼鏡は、機械が生成したテキストを検出する際にプロンプトが含まれる場合の課題を、当惑度と交差当惑度を比較することで克服した。これにより、プロンプトがテキスト生成に強く影響する場合に、素朴な当惑度に基づく検出が失敗するという問題に対処している。
結論と今後の研究の方向性
Binoculars法は、ゼロショット検出を用いて機械生成テキストを検出する新しいアプローチを導入している。Binoculars法は、複 雑度と交差複 雑度の比に基づいてBinocularsスコアを計算する。この手法はモデルに依存せず、特別な修正を必要とせずに様々なLLMからテキストを検出することができる。そのため、実世界のシナリオに適応可能なツールとなる。
Binocularsは低い偽陽性率を達成しており、これは人間が書いたテキストをAIが作成したものと誤分類するリスクを最小限に抑えるために重要である。効果的ではあるが、予測を説明しない「ブラックボックス」の手法であり、それを回避しようとする意欲的な試み(敵対的攻撃)がある場合には、完全に効果があるとは限らない。
双眼鏡の今後の研究の方向性
Binoculars法を改善し、その限界に対処するための将来の研究方向がいくつかあります:
低リソース言語:** 今後の研究分野の1つは低リソース言語での検出性能の向上です。現在の方法では、これらの言語での再現性が低い。より強力な多言語モデルを使用することで、このような状況における機械生成テキストの検出を改善できる可能性がある。
会話以外のテキスト領域:*** ソースコードのような会話以外のテキスト領域における手法の性能を評価するために、さらなる研究が必要である。
敵対的な攻撃:** 双眼鏡は敵対的な設定では限界を示す。これは敵対的攻撃に対する防御に関する追加研究の必要性を示している。
モデルの組み合わせ:**今後の研究では様々なモデルの組み合わせが検討される可能性がある。これは、双眼鏡のパフォーマンスを向上させるために最も効果的な観察者とパフォーマーのモデルを特定するのに役立つかもしれません。
関連リソース
双眼鏡の論文双眼鏡でLLMを発見:ゼロショットの検出
機械生成テキスト](https://arxiv.org/pdf/2401.12070)
DetectGPT論文:確率曲率を用いた機械生成テキストのゼロショット検出
ゴーストバスター論文大規模言語モデルによるテキストのゴーストライト検出
大規模言語モデルと検索](https://zilliz.com/learn/large-language-models-and-search)
LLM-Eval: A Streamlined Approach to Evalating LLM Conversations](https://zilliz.com/learn/streamlined-approach-to-evaluating-llm-conversations)
LLM-Eval: LLMの会話を評価するための合理的なアプローチ]() Be like a Goldfish, Don't Memorize!生成的LLMにおける暗記を軽減する
PagedAttentionによる大規模言語モデルサービングの効率的なメモリ管理](https://zilliz.com/learn/efficient-memory-management-for-llm-serving-pagedattention)
GPT 4.xのポテンシャルを最大限に引き出すファインチューニング・テクニック](https://zilliz.com/learn/maximizing-gpt-4-potential-through-fine-tuning-techniques)
ゼロショット学習について知っておくべきこと](https://zilliz.com/learn/what-is-zero-shot-learning)
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
読み続けて

OpenAI CLIPを探る:マルチモーダルAI学習の未来
マルチモーダルAI学習は、テキスト、画像、音声など様々なモダリティからの情報を一緒に入力し理解することができ、世界をより深く理解することにつながります。OpenAIのCLIP(Contrastive Language-Image Pre-training)は、テキストと画像データのための一般的なマルチモーダルモデルです。
知識の蒸留:妥当性を犠牲にすることなく、大規模で計算量の多いLLMから小規模なLLMへ知識を移行する
知識蒸留とは、大規模で複雑なモデル(教師)の知識を、より小規模で単純なモデル(生徒)に転送する機械学習手法である。

RouteLLM: LLM展開におけるコストと品質のトレードオフをナビゲートするオープンソースフレームワーク
RouteLLMはオープンソースのフレームワークで、開発者はコスト、レイテンシ、精度に基づき、タスクを最適なLLMに効率的にルーティングできる。