




Massive Text Embedding Benchmark (MTEB)
Massive Text Embedding Benchmark (MTEB)
Text embeddings are often tested on a small number of datasets from just one task, which doesn't show how well they work for other tasks. It's not clear if the best embeddings for Semantic Textual Similarity (STS) work equally well for tasks like clustering or reranking. This makes it hard to see progress in the field, as new models and embeddings are commonly evaluated and constantly proposed without consistent testing.
To address this issue, researchers have created the Massive Text Embedding Benchmark (MTEB). MTEB covers 8 embedding tasks across 58 datasets in 112 languages. The researchers tested 8 embedding tasks covering 33 models on MTEB, making it the most complete benchmark for text embeddings so far.
They found that no single embedding method is best for all tasks. This suggests that a universal text embedding method that works best for all embedding tasks hasn't yet been developed, even when scaled up. This also highlights the importance of doing your due diligence to pick the embedding models that best suits your requirements.
MTEB comes with open-source code, a public leaderboard, and a fun MTEB Arena to vote on things like which models retrieves the better document, does better clustering etc. both on the Hugging Face website. This benchmark will help the community test new methods consistently and track improvements in text embedding technology.
Background and Motivation
Text embeddings have become a key part of many Natural Language Processing (NLP) tasks. These embeddings turn words, sentences, or documents into number representations that capture their meaning. They're used in various applications like machine translation, named-entity recognition, question answering, sentiment analysis, and summarization.
Over the years, researchers have created many datasets and benchmarks to test these embeddings. Some well-known ones include SemEval, GLUE, SuperGLUE, Big-Bench, WordSim353, and SimLex-999. These typically focus on evaluating standard and contextual word embeddings.
However, there are still some gaps in how text embeddings are evaluated:
Few benchmarks cover both word and sentence embeddings.
Many evaluations focus on specific NLP tasks, not on how well the embeddings capture the overall meaning of text.
Existing benchmarks often don't consider how embeddings might be used in real-world applications.
There's a need for a comprehensive benchmark, that can evaluate a wide range of text understanding tasks. This benchmark should be useful for both NLP researchers and people working on practical applications. The Massive Text Embedding Benchmark (MTEB) aims to fill this gap.
Text Embeddings
A text embedding is a way to represent text as a list of numbers. These numbers can represent a single word, a sentence, or even a whole document. The list is usually hundreds of numbers long.
Text embeddings are used in many NLP tasks. For words, they're used in things like spell checking and finding word relationships. For longer texts, they're used in tasks like figuring out the sentiment of a piece of writing or generating new text.
There are many different ways to create text embeddings. Some popular methods include:
Language model-based methods like ULMFit, GPT, BERT, and PEGASUS
Methods trained on various NLP tasks, like ELMo
Word-based methods like word2vec and GloVe, which are often used in computer vision research
Researchers have created lots of different embeddings - there are at least 165 to compare. They've also made 15 different tools (like decision trees and Random Forests) to help understand the strengths and weaknesses of these embeddings.
However, there's no standard way to compare all these different embeddings. This is a problem that the Massive Text Embedding Benchmark (MTEB) tries to solve.
Design and Implementation of the Massive Text Embedding Benchmark
MTEB was designed with several important goals in mind:
Diversity: MTEB tests embedding models on many different tasks. It includes 8 different types of tasks, with up to 15 datasets for each. Out of the 58 total datasets, 10 work with multiple languages, covering 112 languages in total. The benchmark tests both short (sentence-level) and long (paragraph-level) texts to see how models perform on different text lengths.
Simplicity: MTEB is easy to use. Any model that can take a list of texts and produce a list of number representations (vectors) can be tested. This means many different types of models can be compared.
Extensibility: It's easy to add new datasets to MTEB. For existing tasks, you just need to add a file that describes the task and points to where the data is stored on Hugging Face. Adding new types of tasks requires a bit more work, but MTEB welcomes contributions from the community to help it grow.
Reproducibility: MTEB makes it easy to repeat experiments. It keeps track of different versions of datasets and software. The results in the MTEB paper are available as JSON files, so anyone can check or use them.
These features make MTEB a comprehensive and flexible tool for evaluating text embedding models across tasks covering a total wide range of tasks and languages.
Tasks and Evaluation in Massive Text Embedding Benchmark
Massive Text Embedding Benchmark includes 8 different types of tasks to test embedding models. Here's a simple breakdown of each task:
Bitext Mining: Find matching sentences in two different languages. The main measure is F1 score.
Classification: Use embeddings to sort texts into categories. The main measure is accuracy.
Clustering: Group similar texts together. The main measure is v-measure.
Pair Classification: Decide if two texts are similar or not. The main measure is average precision.
Reranking: Order a list of texts based on how well they match a query. The main measure is MAP (Mean Average Precision).
Retrieval: Find relevant documents for a given query. The main measure is nDCG@10.
Semantic Textual Similarity (STS): Measure how similar two sentences are. The main measure is Spearman correlation.
Summarization: Score machine-generated summaries against human-written ones. The main measure is also Spearman correlation.
For each task, MTEB uses the embedding model to turn texts into vector embeddings. Then it uses methods like cosine similarity or logistic regression to perform the task and calculate scores.
MTEB includes many datasets for each task, covering different languages and text lengths. This helps to test how well embedding models work in various situations.
By using these diverse tasks and datasets, the Massive Text Embedding Benchmark provides a comprehensive way to evaluate and compare different text embedding models.
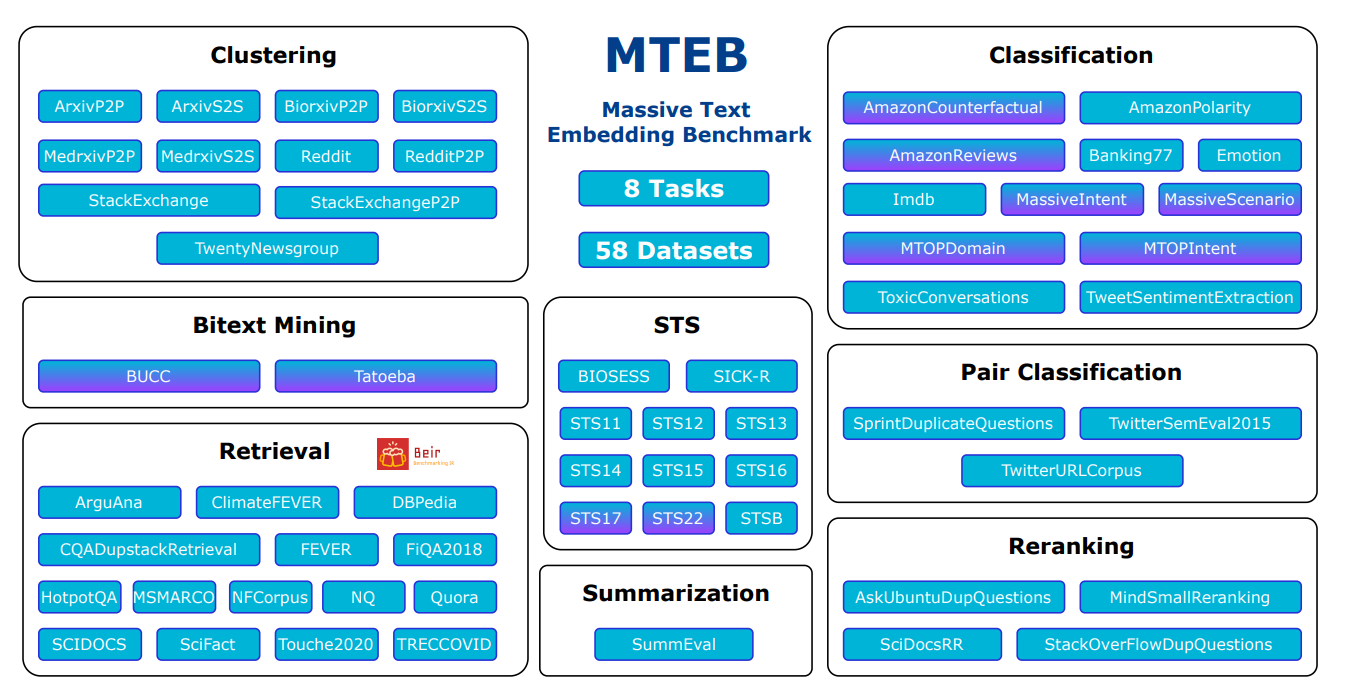 Overview of tasks and datasets in MTEB
Overview of tasks and datasets in MTEB
Source: MTEB: Massive Text Embedding Benchmark
Datasets in the Massive Text Embedding Benchmark
The Massive Text Embedding Benchmark uses many different datasets to test particular text embedding method and models. These datasets are grouped into three main types based on the length of the texts being compared:
Sentence to Sentence (S2S): This is when one sentence is compared to another. For example, in Semantic Textual Similarity tasks, the goal is to figure out how similar two sentences are.
Paragraph to Paragraph (P2P): This involves comparing longer pieces of text. MTEB doesn't set a limit on how long these can be, leaving it up to the models to handle longer texts if needed. Some tasks, like clustering, are done both as S2S (comparing just titles) and P2P (comparing titles and content).
Sentence to Paragraph (S2P): This is used in some retrieval tasks, where a short query (sentence) is compared to longer documents (paragraphs).
MTEB includes 56 different datasets. Some of these datasets are similar to each other:
Some use the same underlying text data (like ClimateFEVER and FEVER).
Datasets for similar tasks (like different versions of CQADupstack or STS) tend to be alike.
The S2S and P2P versions of the same dataset are often similar.
Datasets about similar topics (like scientific papers) tend to be alike, even if they're for different tasks.
By using such a wide range of datasets, MTEB can test how well embedding models work with different types of text and different tasks. This helps give a more complete picture of each model's strengths and weaknesses.
Models in the initial benchmarking of Massive Text Embedding Benchmark
For the first round of testing with MTEB, the researchers looked at models that claim to be the best and ones that are popular on the Hugging Face Hub. This meant they tested a lot of transformer models. They grouped the models into three types to help people choose the best one for their needs:
Fastest Models: Models like Glove are very fast, but they don't understand context well. This means they don't score as high on MTEB overall.
Balanced Models: Models like all-mpnet-base-v2 or all-MiniLM-L6-v2 are a bit slower than the fastest ones, but they perform much better. They offer a good mix of speed and quality.
Highest Performing Models: Big models with billions of parameters, like ST5-XXL, GTR-XXL, or SGPT-5.8B-msmarco, do the best on MTEB. But they can be slower and need more storage. For example, SGPT-5.8B-msmarco creates embeddings with 4096 numbers, which takes up more space.
It's important to note that how well a model does can change a lot depending on the specific task and dataset. The researchers suggest checking the MTEB leaderboard to see which model might work best for single task and your specific needs.
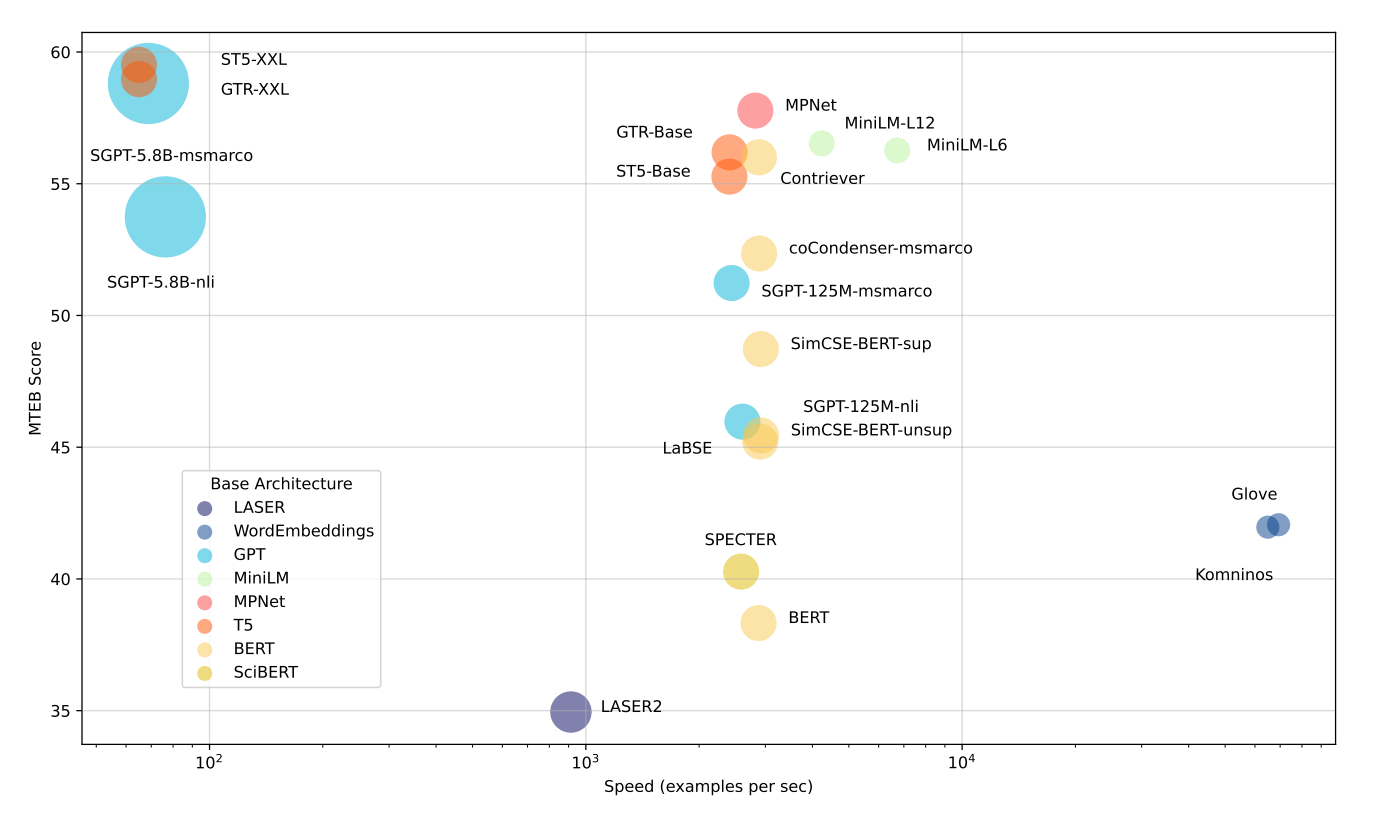 Results of the benchmarks of the inital test
Results of the benchmarks of the inital test
Source: MTEB: Massive Text Embedding Benchmark
This approach to testing gives a clear picture of the trade-offs between speed and performance in different embedding models, helping users make informed decisions based on their specific requirements. If you'd like to try it yourself, there is a great blog on Huggigng Face that walks you through benchmarking any model that produces vector embeddings.
When to use the Massive Text Embedding Benchmark
MTEB is a tool for testing how well text embedding models work on many different tasks. It's useful in several situations:
Testing Your Model: If you've made a new embedding model, you can use MTEB to see how it compares to other models. You can add your results to the public leaderboard, which helps you see how your model stacks up against others.
Picking the Right Model: Different models work better for different tasks. MTEB's leaderboard shows how models perform on various tasks, helping you choose the best model for your specific needs.
Helping to Improve MTEB: MTEB is open source and therefore open for anyone to contribute. If you've created a new task, dataset, way of measuring performance, or model, you can add it to MTEB. This helps make the benchmark even better.
Research: If you're studying text embeddings, MTEB gives you a thorough way to test models. It can show you what the best current models can do and where there's room for improvement.
By providing a standard way to test models on many tasks, MTEB helps researchers and developers understand and improve text embedding technology. It's a valuable tool for anyone working with or studying text embeddings.
How to use the Massive Text Embedding Benchmark leaderboard
First of all, Don't Be Misled by MTEB Scores!
MTEB is a useful tool, but it's important to understand its limitations. While it shows scores, it doesn't tell you if the differences between scores are meaningful. Many top models have very close average scores, which come from many different tasks, but there's no information about how much these scores vary. The top model might look better, but the difference might not be important. Users can get the raw results to check this themselves. Some researchers have found that several top models in certain language benchmarks are actually equally good, statistically speaking. Instead of just looking at average scores, it's better to focus on how models perform on tasks similar to the intended use case. This might provide more insight into how a model will work for a specific application than the overall score. It's not necessary to study the datasets in detail, but knowing what kind of text they contain is beneficial. This information is usually available from the dataset's description and a quick look at some examples. The Massive Text Embedding Benchmark is a helpful tool, but it's not perfect. It's important to think critically about the results and how they apply to specific needs. Rather than simply picking the model with the highest overall score, it's better to look deeper to find the best model for the task at hand.
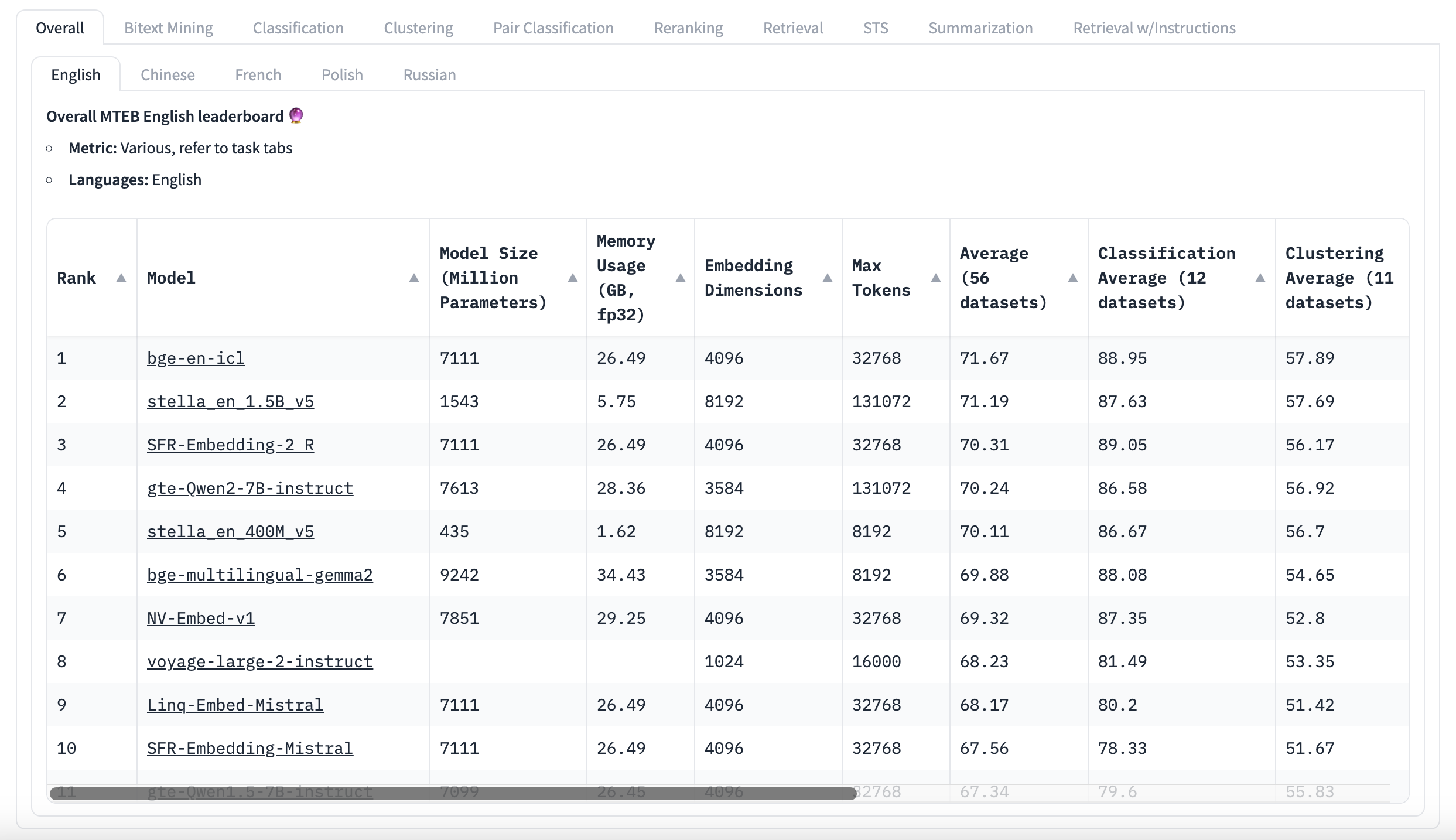 MTEB Leaderboard English
MTEB Leaderboard English
Remember to Consider Your Application's Needs
There's no one-size-fits-all model for every task. That's why the Massive Text Embedding Benchmark exists - to help you choose the right model for your specific needs. When looking at the Massive Text Embedding Benchmark leaderboard, it's important to think about what your application requires. Here are some things to consider:
Language: Does the model support the language you're working with?
Specialized vocabulary: If you're working with financial or legal texts, you'll need a model that understands field-specific terms.
Model size: Think about where you'll run the model. Will it need to fit on a laptop?
Memory use: How much computer memory can you spare for the model?
Maximum input length: How long are the texts you'll be working with?
Once you know what's important for your task, you can sort various models on the MTEB leaderboard based on these features. This makes it easier to find a model that not only performs well but also fits your practical requirements.
By considering both performance and practical needs, you can choose a model that works best for your specific situation.
The Zilliz AI Model resource
Now that you have chosen your text embedding model from the Massive Text Embedding Benchmark, let's put it to work to create text embeddings to store and retrieve in open source Milvus or Zilliz Cloud. On the Zilliz website, you can find the AI Models page that lists some of the more popular multimodal and text embedding models.
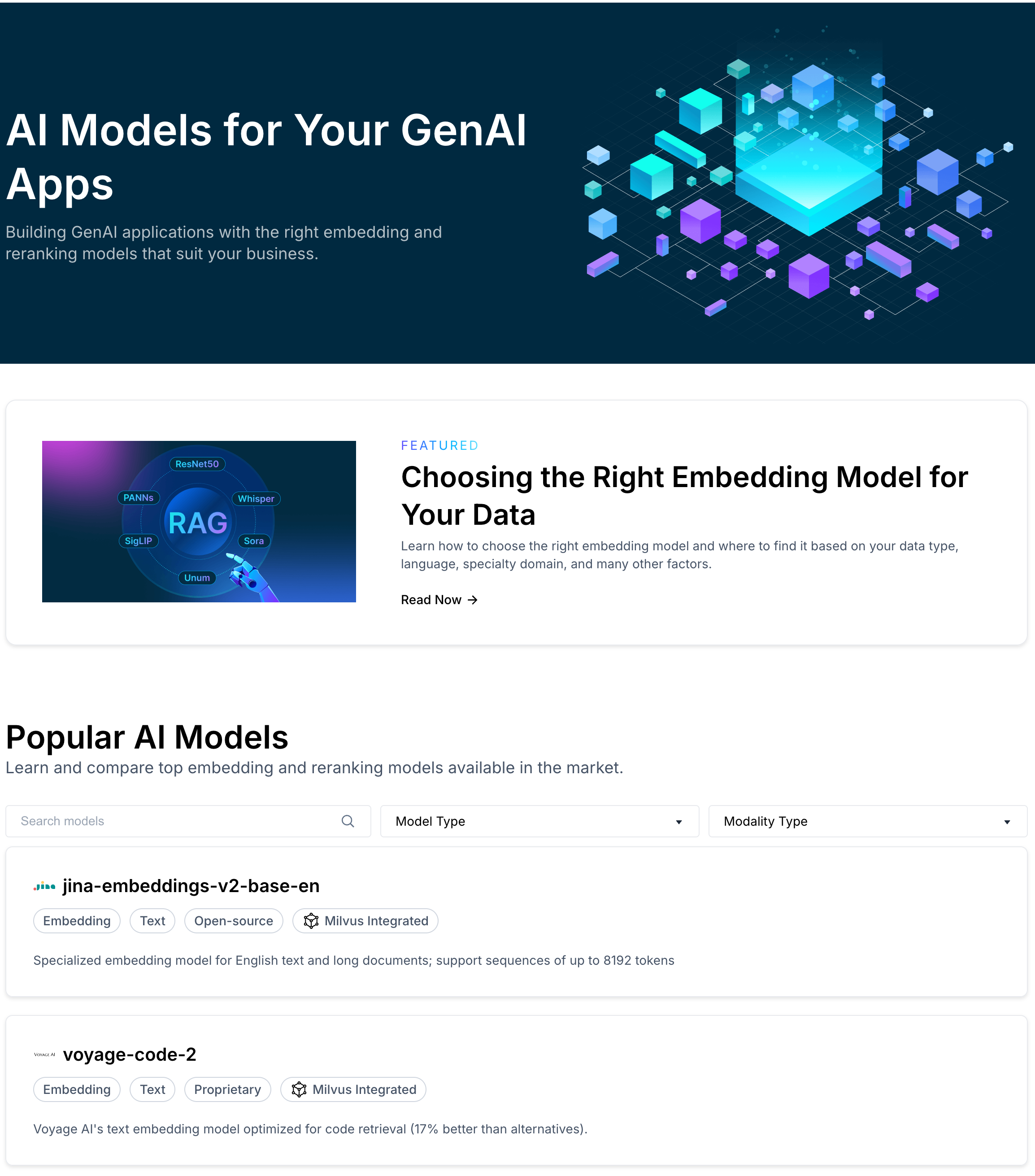 Zilliz AI Model page
Zilliz AI Model page
Once you select a model on this page, you can see that there are a few detailed instructions on how to create the vector embeddings using the various SDKs, PyMilvus, and more.
Conclusion
The Massive Text Embedding Benchmark (MTEB) is a significant step forward in evaluating text embedding models. It addresses the limitations of previous benchmarks by covering a wide range of tasks, languages, and text lengths. MTEB's design focuses on diversity, simplicity, extensibility, and reproducibility, making it a valuable tool for both researchers and practitioners in the field of Natural Language Processing.
MTEB's most comprehensive benchmark approach, testing models across 8 different tasks and 58 datasets, provides a more complete picture of a model's capabilities than previous benchmarks. It reveals that no single embedding method excels at all tasks, highlighting the importance of choosing the right model for specific applications.
When using MTEB, it's crucial to look beyond the overall scores and consider the specific needs of your application. Factors such as language support, specialized vocabulary, model size, memory use, and maximum input length should all play a role in the decision-making process.
While MTEB is a powerful tool, it's important to use it critically. The differences in scores between top models may not always be statistically significant, and performance can vary greatly depending on the specific task and dataset.
As an open-source project, MTEB welcomes contributions from the community, allowing it to grow and adapt to the evolving needs of the field. This collaborative approach ensures that MTEB will continue to be a relevant and valuable resource for evaluating and improving text embedding technology.
By providing a standardized way to evaluate text embedding models across a wide range of tasks and languages, MTEB is helping to drive progress in the field, ultimately leading to better and more versatile text embedding models for various applications.
References
Muennighoff, Niklas and Tazi, Nouamane and Magne, Lo{\"\i}c and Reimers, Nils. "MTEB: Massive Text Embedding Benchmark" arXiv 2022
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff. "C-Pack: Packaged Resources To Advance General Chinese Embedding" arXiv 2023
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaeddine Abdessalem, Tanguy Abel, Mohammad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, Maximilian Werk, Nan Wang, Han Xiao. "Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents" arXiv 2023
Silvan Wehrli, Bert Arnrich, Christopher Irrgang. "German Text Embedding Clustering Benchmark" arXiv 2024
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, Luca Soldaini. "FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions" arXiv 2024
Dawei Zhu, Liang Wang, Nan Yang, Yifan Song, Wenhao Wu, Furu Wei, Sujian Li. "LongEmbed: Extending Embedding Models for Long Context Retrieval" arXiv 2024
Kenneth Enevoldsen, Márton Kardos, Niklas Muennighoff, Kristoffer Laigaard Nielbo. "The Scandinavian Embedding Benchmarks: Comprehensive Assessment of Multilingual and Monolingual Text Embedding" arXiv 2024
- Background and Motivation
- Text Embeddings
- Design and Implementation of the Massive Text Embedding Benchmark
- When to use the Massive Text Embedding Benchmark
- How to use the Massive Text Embedding Benchmark leaderboard
- The Zilliz AI Model resource
- Conclusion
- References
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free