




長文のためのセンテンス・トランスフォーマー
長文テキストのための最新のトランスフォーマーに基づく埋め込みに深く潜る。
シリーズ全体を読む
- 自然言語処理の基礎:トークン、Nグラム、Bag-of-Wordsモデル
- 言語モデルのためのニューラルネットワークとエンベッディング入門
- 疎な埋め込みと密な埋め込み
- 長文のためのセンテンス・トランスフォーマー
- 独自のテキスト埋め込みモデルをトレーニングする
- 埋め込みモデルの評価
- クラス活性化マッピング(CAM):ディープラーニングモデルにおけるより良い解釈可能性
- CLIP物体検出:AIビジョンと言語理解の融合
- SPLADEを発見:スパースデータ処理に革命を起こす
- BERTopicの探求:ニューラル・トピック・モデリングの新時代
- データの合理化次元を減らす効果的な戦略
- All-Mpnet-Base-V2:AIによる文埋め込み機能の強化
- データ分析における時系列の埋め込み
- 学習型スパース検索による情報検索の強化
- BERT(Bidirectional Encoder Representations from Transformers)とは?
- ミクスチャー・オブ・エキスパート(MoE)とは?
#はじめに
前回の投稿では、IMDBデータセットを使ったセンチメント分類の例を説明する前に、意味検索における密埋め込みと疎埋め込みの長所(と短所)について簡単に説明した。具体的には、事前に訓練されたRNN (RWKV)とTF-IDFベクタライザからの埋め込みを使用した。この例では、TF-IDFの方がわずかに良い結果を出した。
この投稿では、長文テキストのための「最新の」変換器ベースの埋め込みを深く掘り下げます。Sentence-BERTアーキテクチャを簡単にカバーし、再びIMDBデータセットの例を使用して、評価異なる変換器ベースの高密度埋め込みモデルを紹介します。
さあ、飛び込みましょう。
文変換器とは何か?
変換から文型変換へ
標準的なフィードフォワードネットワークをリカレントネットワークに変更する方法とともに、ニューラルネットワークの構造をすでに説明した。RNNは時間的相互作用を非常にうまくモデル化する一方で、学習や実際の使用を難しくするいくつかの欠点がある:
- エラーに敏感であること:多くのRNNはteaching forcingによって訓練される。これは、1回のステップでのモデルの予測を次のステップの入力として使用しない訓練戦略である。その代わりに、学習データセットからの実際の出力または予想される出力が使用され、学習が加速され安定するが、推論中にエラーが蓄積される(モデルは間違いを修正するように学習されていないため)。
最近のタイムステップへのバイアス:リカレント・ネットワークは、各タイムステップで情報を処理するために、入力された隠れた状態に依存する。この隠れ状態は無限ではないため、他の理由もあるが、隠れ状態は最近のタイムステップの情報を保持する方向に偏る。LSTM、GRU、その他の特殊なリカレント・ニューラル・ネットワークセルは、この問題に取り組むために開発されたが、成功は限定的であった。
逐次推論***:これはおそらくリカレントネットワークの最大の欠点である。RNNは一度に1トークンずつ情報を出力するため、1つのサンプルに対して学習と推論を並列化するのは難しい。
トランスフォーマー(各トークンの列全体に密な注意を払う、大規模なフィードフォワード型ニューラルネットワーク(unroll RNN)に類似したニューラルネットワークアーキテクチャ)の登場です。トランスフォーマーがどのように機能するのか簡単に説明します。トランスフォーマーの完全なモデルやアーキテクチャを知らない方は、まず原著論文やJay AlammarのIllustrated Transformerのブログ記事をご覧ください。
埋込みに関しては、私たちは、トランスフォーマアーキテクチャのエンコーダスタックにしかほとんど興味がありません。これは、トークンのシーケンスを入力として受け取り、トークン埋込みのシーケンス(入力トークンごとに1つの埋込み)を出力します。最も一般的なエンコーダのみのアーキテクチャは、BERT (Bidirectional Encoder Representations from Transformers)として知られており、様々な自然言語処理および理解タスクで強力な性能を達成するために、エンコーダのみの変換器を事前に訓練する、概念的に単純だが強力な方法である。
BERTは、1つの入力トークンにつき1つの埋め込みを出力することに注意することが重要です。これは、20個のトークンを持つ文に対して、20個の埋め込みが出力されることを意味します!この問題を解決するために、各トークンの埋め込みをプールすることで、平均することができます:
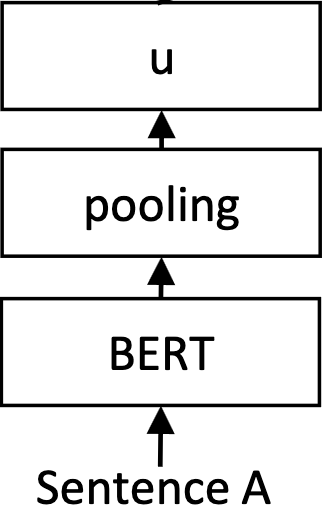 バートプール
バートプール
擬似コードでは次のようになる:
パイソン
outputs = BERT("これは文章です") embedding = np.mean(outputs, axis=0)
ご想像の通り、BERTや他のエンコーダのみの[変換モデル](https://zilliz.com/glossary/transformer-models)は文レベルではなくトークンレベルで学習されるため、これはあまり良い方法ではありません。我々の主な用途は[ 検索](https://zilliz.com/learn/vector-similarity-search)のための類似度スコアであるため、代替案としては、[クロスエンコーダ](https://docs.zilliz.com/reference/python/python/Rerankers-CrossEncoderRerankFunction)アーキテクチャとして知られているものを採用することである。ここでは、2つのシーケンス入力データが単一のBERTモデルに供給され、このモデルは[類似度](https://zilliz.com/glossary/semantic-similarity)スコアを出力する:
類似度](https://assets.zilliz.com/bert_bi_encoder_e412f95292.png)
しかし、このアプローチは信じられないほど非効率的である。入力クエリ文と私のコーパスの100万文の間の類似度を計算するには、このモデルを100万回実行する必要がある!
### SBERTとBERTの比較
**SBERTは、BERTの単純だが強力な修正であり、より意味的に豊かなシーケンスレベルの[テキスト埋め込み](https://zilliz.com/learn/training-your-own-text-embedding-model)を可能にする。BERTとは異なり、SBERTは2つの文の2つのプールされたバージョン間の類似性を最大化するように訓練されており、類似したテキストが互いに対応するようになるため、テキストの分類や[意味検索](https://zilliz.com/glossary/semantic-search)などの様々なタスクのようなアプリケーションで非常に有用である:
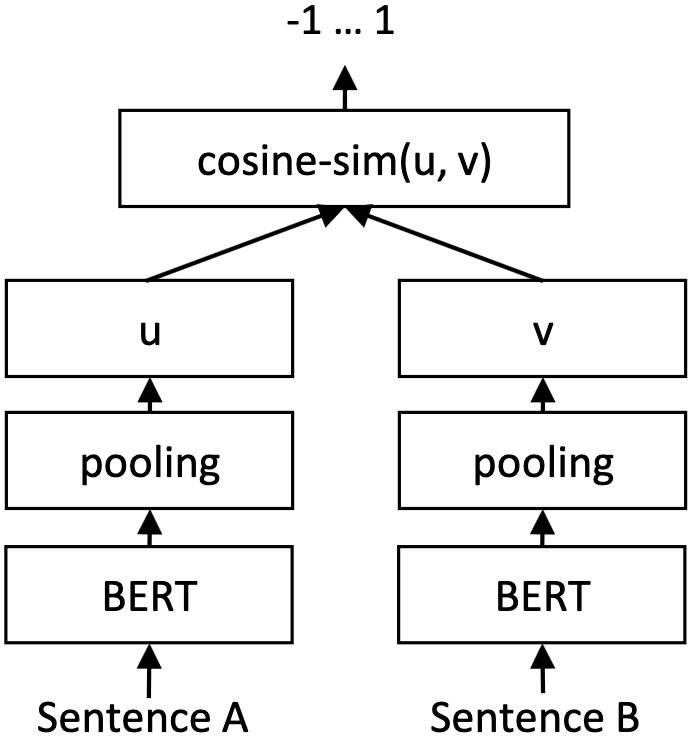
Sentence-BERTは単純だが強力である。[ソース](https://arxiv.org/abs/1908.10084)
上図では、文2が与えられた同一のBERTモデルが、文Aと文Bに対して1回ずつ、計2回実行される。両方の結果はプールされるが、損失関数として使用される文の類似性の[cosine](https://zilliz.com/blog/similarity-metrics-for-vector-search)で、別の微調整ステップが発生する。似たような文ペアのグランドトゥルース値は**1**とラベル付けされ、互いに大きく異なる文は**-1**とラベル付けされる。
SBERT論文は対応する `sentence-transformers` ライブラリと共に2019年にリリースされた。sentence-transformers`には現在、オリジナルを超える多くのモデルが含まれているが、これらはすべて何らかの形でSBERTに基づいている。
この強力なライブラリの使い方の例に飛び込んでみよう。
## 分類の例
前回のブログのIMDBデータセットに戻ってみよう:
python
from datasets import load_dataset
# IMDBデータセットをロードする
train_dataset = load_dataset("imdb", split="train")
test_dataset = load_dataset("imdb", split="test")
SBERT埋め込みを出力するために、generate_embeddings関数を修正しよう。
``python from sentence_transformers import SentenceTransformer
トークナイザーとモデルをインスタンス化する
model = SentenceTransformer("intfloat/e5-small-v2")
def generate_embeddings(dataset): """入力データセットに対する埋め込みを生成する。 """ return model.encode([row["text"] for row in dataset])
訓練とテストの埋め込みを生成する
train_embeddings = generate_embeddings(train_dataset) test_embeddings = generate_embeddings(test_dataset)
HuggingFaceの**transformers**ライブラリとは異なり、**sentence-transformers**は文埋め込み専用であることに注意してください。特に、[**torch.no**](http://torch.no)**_grad()**を指定する必要がない。
前と同じように、これらの埋め込みに対してサポートベクトル分類器を学習してみましょう。
``python
from sklearn.svm import SVC
# 計算された埋め込みとラベル付けされた学習データを使って、線形SVM分類器を学習します。
classifier = SVC(kernel="linear")
classifier.fit(train_embeddings, train_dataset["label"])
from sklearn.metrics import accuracy_score
# テストセットで予測
test_predictions = classifier.predict(test_embeddings)
# 正解率で分類器をスコアリング
accuracy = accuracy_score(test_dataset["label"], test_predictions)
print(f "accuracy: {accuracy}")
センテンストランスフォーマーモデルの全リストはこちらで確認できる:https://huggingface.co/sentence-transformers。
SBERT パフォーマンス
前述のSBERTの論文では、教師なしと教師ありの両方で、SBERTが多くの意味的テキスト類似度(STS)タスクでテストされたことが述べられている。教師なし STS では、SBERT は、SICK-R を除くほとんどのデータセットで、InferSent と Universal Sentence Encoder を上回った。教師ありSTSでは、SBERTはSTSベンチマークで最先端を得た。このモデルは、Argument Facet Similarity(AFS)コーパスのような難易度の高いタスクでもテストされ、標準的な評価では良好な結果を示したが、トピック横断的な汎化では苦戦した。また、SBERTは、ウィキペディアのセクション区別タスクにおいて、従来の手法を大きく上回った。
SBERTの性能をより深く理解するために、異なるプーリング戦略と連結方法の影響を見るためのアブレーション研究が行われた。この研究により、NLI タスクの学習済みデータでは、プーリングの影響は小さいが、連結の影響は大きいことが示された。また、SBERT の計算効率もテストされ、スマートバッチを使用することで、GPU 上の InferSent や Universal Sentence Encoder よりも高速になりました。多くのタスクにわたるこれらのテストとアブレーション研究は、SBERT の能力と設計の選択の全体像を示しており、SBERT は文埋め込みを生成する最先端の手法である。
まとめ
この投稿では、Sentence-BERTを見て、IMDBデータセットを分類するためにsentence-transformersライブラリを使用する方法を示し、意味検索のための文埋め込みについて簡単に話した。今日、多くのSBERTライクなモデルがsentence-transformersライブラリの一部であり、MTEB leaderboardを通じて幅広いベンチマークが利用可能である。
テキスト埋め込みは、あらゆる検索システムのパフォーマンスを向上させる強力な方法であり、あなた自身のデータでそれらをトレーニングすることは、あなたのアプリケーションのパフォーマンスを向上させる強力な方法となります。次のチュートリアルでは、独自のモデルを微調整することで、センテンス・トランスフォーマーについて話を続けます。
その他のリソース
エンベッディングの歴史**|Unstructured Data meetupでの私のtalkをチェックしてください。ここではエンベッディングの歴史、特にMultimodal RAGのためのマルチモーダルエンベッディングを生成するのに役立つセンテンスとビジョンのトランスフォーマーについて説明します!
AIモデルギャラリー**](https://zilliz.com/ai-models)。このギャラリーでは、35-large-v2、all-MiniLM-L12-v2、voyage-large-2などの文型変換モデルを紹介しています!
 Frank Liu
Frank LiuFrank Liu is the Director of Operations & ML Architect at Zilliz, where he serves as a maintainer for the Towhee open-source project. Prior to Zilliz, Frank co-founded Orion Innovations, an ML-powered indoor positioning startup based in Shanghai and worked as an ML engineer at Yahoo in San Francisco. In his free time, Frank enjoys playing chess, swimming, and powerlifting. Frank holds MS and BS degrees in Electrical Engineering from Stanford University.
読み続けて
クラス活性化マッピング(CAM):ディープラーニングモデルにおけるより良い解釈可能性
クラス活性化マッピング(CAM)は、コンピュータビジョンタスクのための畳み込みニューラルネットワーク(CNN)の意思決定を視覚化し理解するために使用される。

CLIP物体検出:AIビジョンと言語理解の融合
CLIPオブジェクト検出は、CLIPのテキスト画像理解とオブジェクト検出タスクを組み合わせ、CLIPがテキストを使用して画像内のオブジェクトを見つけ、識別することを可能にします。

SPLADEを発見:スパースデータ処理に革命を起こす
SPLADEは、スパースデータを処理するために事前に訓練された変換モデルを使用するテクニックです。この投稿では、SPLADEとその利点、そして実際のアプリケーションについて説明します。