




All-Mpnet-Base-V2:AIによる文埋め込み機能の強化
センテンスエンベッディングの発展において重要な役割を果たしたディープラーニングモデルの1つを掘り下げる:MPNet。
シリーズ全体を読む
- 自然言語処理の基礎:トークン、Nグラム、Bag-of-Wordsモデル
- 言語モデルのためのニューラルネットワークとエンベッディング入門
- 疎な埋め込みと密な埋め込み
- 長文のためのセンテンス・トランスフォーマー
- 独自のテキスト埋め込みモデルをトレーニングする
- 埋め込みモデルの評価
- クラス活性化マッピング(CAM):ディープラーニングモデルにおけるより良い解釈可能性
- CLIP物体検出:AIビジョンと言語理解の融合
- SPLADEを発見:スパースデータ処理に革命を起こす
- BERTopicの探求:ニューラル・トピック・モデリングの新時代
- データの合理化次元を減らす効果的な戦略
- All-Mpnet-Base-V2:AIによる文埋め込み機能の強化
- データ分析における時系列の埋め込み
- 学習型スパース検索による情報検索の強化
- BERT(Bidirectional Encoder Representations from Transformers)とは?
- ミクスチャー・オブ・エキスパート(MoE)とは?
自然言語処理(NLP)は急速に発展している分野である。テキスト表現が、テキスト分類、名前付きエンティティ認識、テキスト生成、文書要約、機械翻訳、情報検索など、さまざまな深層学習アプリケーションで使用される重要な概念であることを考えれば、これは驚くべきことではない。深層学習の文脈では、生のテキストを深層学習モデルが理解できる数値形式に変換する必要がある。このテキストの数値表現は、一般的に埋め込みと呼ばれる。
従来のエンベッディングアプローチは、テキストを表現するために、しばしばBag-of-Words(BoW)やn-gramの手法に頼っていた。これらの手法はある程度有効ではあるが、テキストの意味や文脈を捉えることができないことが多い。深層学習技術の進歩に伴い、文埋め込みはこの限界に対処する画期的なアプローチとして登場した。JAXやFlaxなどの効率的なディープラーニングフレームワークは、大規模データセットでの学習プロセスを強化することで、これらの進歩に重要な役割を果たしている。
この記事では、センテンスエンベッディングの発展において重要な役割を果たしたディープラーニングモデルの1つを掘り下げていく:MPNetである。それでは、早速見ていこう!
NLPやAIの黎明期には、Word2VecやGloVeのようなbag-of-wordsやn-gram-based modelが、テキストを埋め込みに変換するための代表的な手法でした。これらのモデルは、個々の単語の意味的な意味は効果的に捉えることができますが、テキスト全体の意味的な意味や文脈的なニュアンスを捉えることができないことがよくあります。
2つの異なる文章における「park」という単語を考えてみよう:「車を車庫に停める」と「一日中公園でくつろぐ」。Word2VecやGloVeでは、"park "という単語は2つの異なる文脈で使われているにもかかわらず、どちらの文でも同じ埋め込みを持つことになる。これは、テキストの意味を推論する際に重大な不正確さにつながる可能性があり、より正確なモデルの緊急の必要性を強調している。さらに、これらのモデルは単語レベルの埋め込みを生成するため、文レベルのテキストを扱う際に問題となる可能性がある。
Sentence Transformers](https://zilliz.com/learn/Sentence-Transformers-for-Long-Form-Text)の登場がこの問題に対処している。その名前が示すように、Sentence Transformersは人気のあるTransformersアーキテクチャをバックボーンとして使用している。Transformerモデル](https://zilliz.com/glossary/transformer-models)のアーキテクチャは、以下に示すように、いくつかのエンコーダ・デコーダ・ブロックから構成されている:
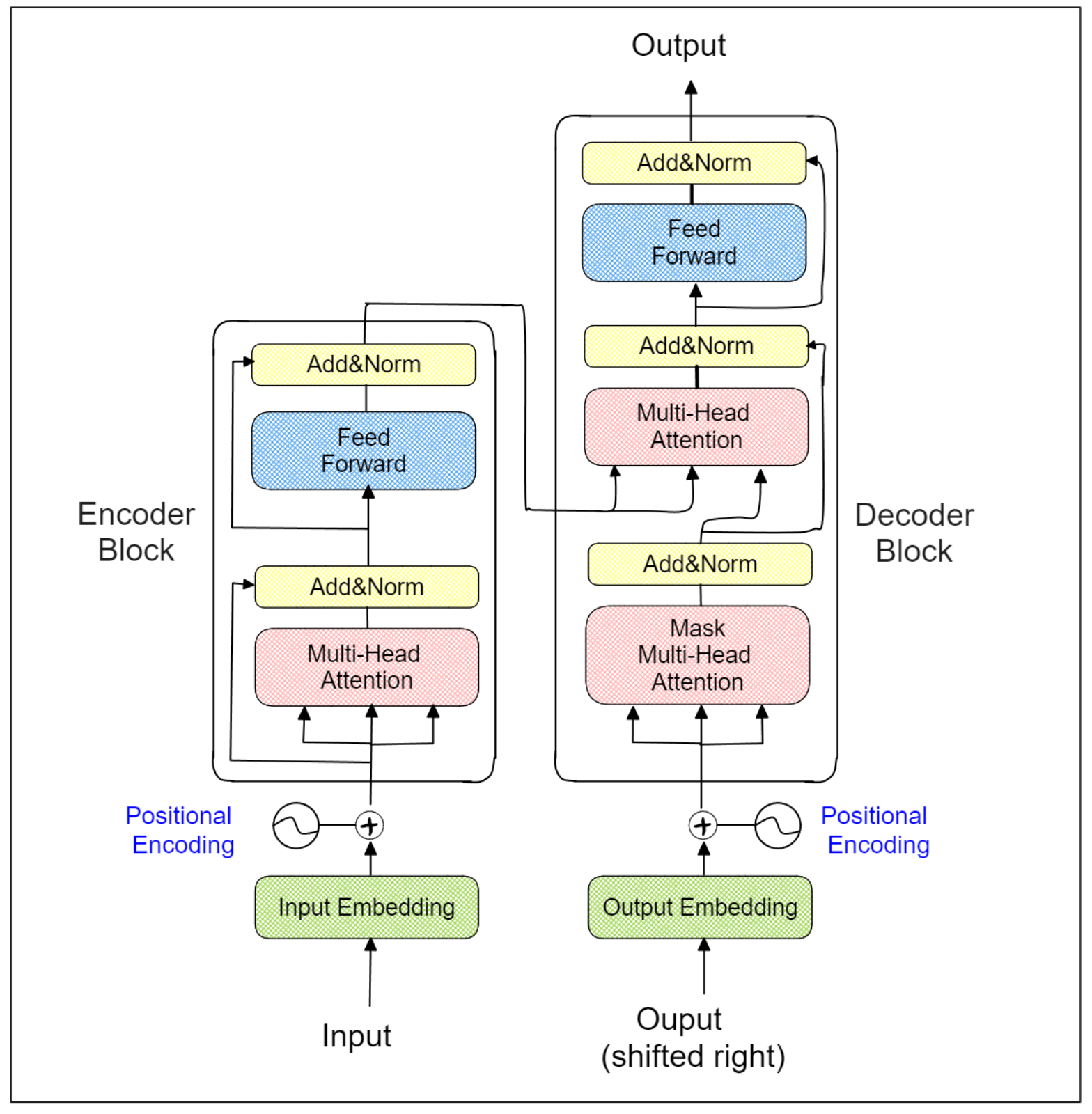 トランスフォーマーのアーキテクチャ.png
トランスフォーマーのアーキテクチャ.png
トランスフォーマーのアーキテクチャ.png
各Transformerエンコーダーブロック内の特殊なマルチヘッドアテンションレイヤーにより、モデルは文全体との関連において各単語(またはトークン)の文脈を学習することができる。このため、センテンス・トランスフォーマーはトランスフォーマーのエンコーダー部分のみをそのアーキテクチャで利用する。Transformersアーキテクチャの助けを借りて、「I park my car in the garage」という文と「I spend the whole day relaxing in a park」という文の中の「park」という単語は異なる形で埋め込まれる。
しかし、Transformersの出力自体は、各単語(またはトークン)の埋め込みであることに変わりはない。したがって、センテンスTransformersは、最後のTransformerエンコーダブロックの上に追加のプーリングレイヤーを使って、入力テキスト全体を表す最終的な集約埋め込みを導きます。
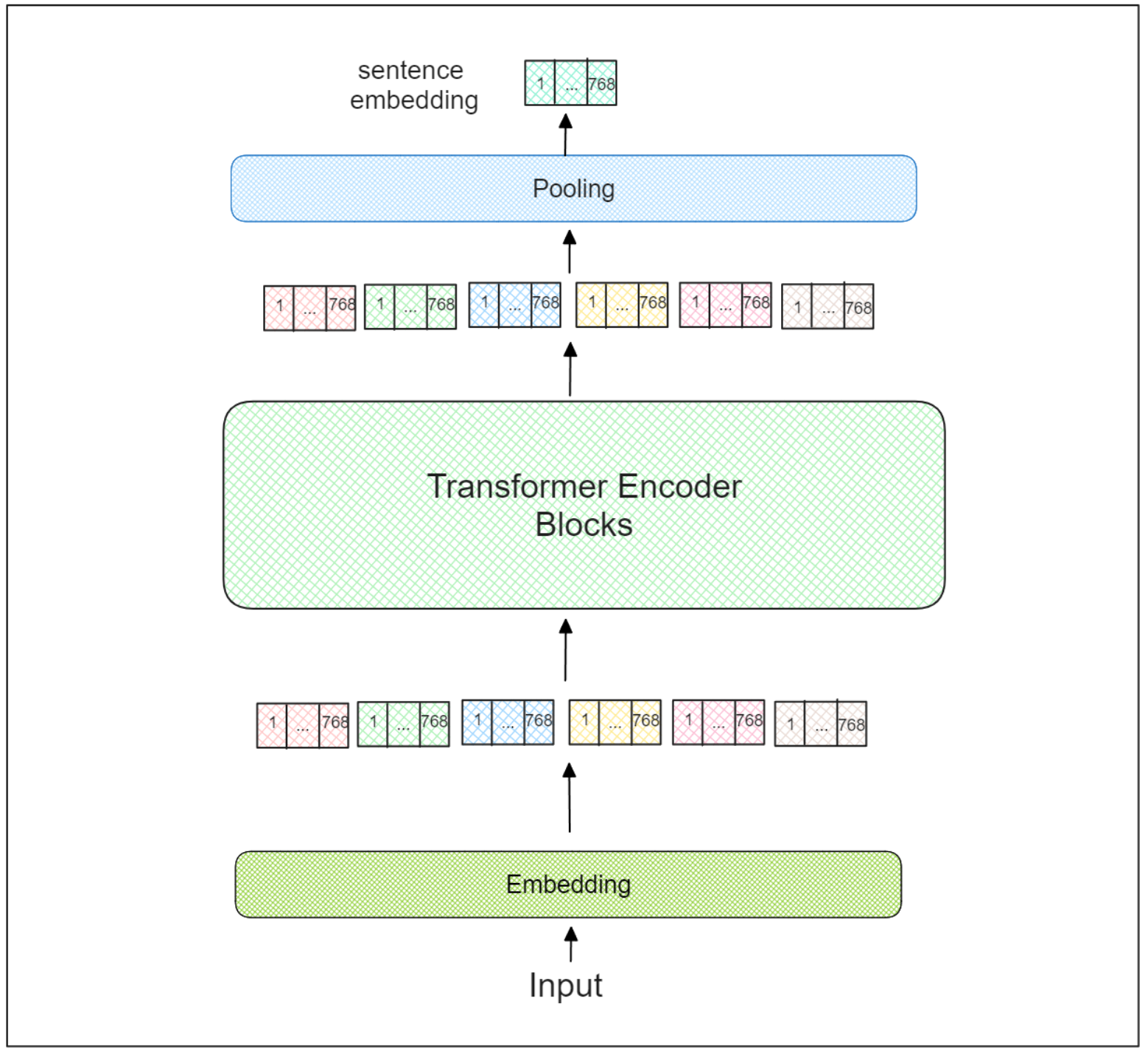 文Transformersアーキテクチャ.png
文Transformersアーキテクチャ.png
センテンストランスフォーマーのアーキテクチャ.png
センテンス・トランスフォーマーには多くの種類があるが、MPNetは最も影響力のあるものの1つである。MPNetは、BERTとXLNetの両モデルの長所を活用すると同時に、両モデルの主な短所にも対処しています。そこで、このモデルを深く掘り下げる前に、BERTとXLNetモデルを高いレベルで理解することが不可欠です。
背景と動機
all-mpnet-base-v2モデルは、長文テキストを扱える効率的かつ効果的な文埋め込みモデルへのニーズの高まりに対応するために開発された。従来のモデルでは、様々な自然言語処理アプリケーションにとって重要な、長文の意味や文脈を完全に捉えることに苦労することが多かった。BERTとXLNetの両方の長所を活用することで、MPNetモデルは双方向情報と自己回帰情報を捕捉し、文埋め込みタスクに理想的な選択肢となります。この組み合わせにより、このモデルは、文のニュアンス的な意味を理解することが最重要である意味検索タスクにおいて優れた性能を発揮する。all-mpnet-base-v2モデルの背後にある動機は、これらの課題に対する堅牢で信頼性の高いソリューションを提供することであり、多様なNLPアプリケーションにおいて高い性能と精度を保証することである。
 BERT事前学習アプローチ.png
BERT事前学習アプローチ.png
MPNetの前身としてのBERTとXLNet
BERTはTransformer-encoderベースのモデルであり、感情分析、名前付きエンティティ認識、質問応答など、多くのタスクで最先端の性能を達成している。BERTで学習手順中の事前学習後学習に適用される重要な技術の1つは、マスク言語モデリング(MLM)である。この手法では、入力トークンのある割合が、ランダムに[MASK]トークンに置き換えられます。そして、この[MASK]トークンを、入力シーケンス全体の文脈から最も可能性の高いトークンと予測することを目的とする。さらに、対照学習の目的を組み込むことで、大規模なデータセットから対になる文をモデルが正確に予測できるようになり、学習方法の有効性を向上させることで、学習プロセスをさらに強化することができる。
BERT事前学習アプローチ.png
BERTの主な欠点は、予測される[MASK]トークンが独立であることである。例えば、あるシーケンスに2つの[MASK]トークンがある場合、1つ目の[MASK]トークンの予測は2つ目の[MASK]トークンの予測に影響を与えないが、1つ目の[MASK]トークンの予測は2つ目の[MASK]トークンの予測に役立つ可能性がある。
上のビジュアライゼーションを見ると、2 番目のトークン x2 の予測は 5 番目のトークン x5 の予測に影響を与えないが、x2 は x5 の予測を強化するのに役立つことは間違いない。しかし、x2は間違いなくx5の予測を強化するのに役立ちます。このため、時には意味のないシーケンス予測になることがあります。一方、XLNetは、BERTの限界を克服するために特別に設計された自己回帰(AR)モデルです。AR アプローチでは、予測されるトークンは常に先行するトークンに依存します。そのため、2 番目の[MASK]トークンの予測は、1 番目の[MASK]トークンの予測を考慮し、BERT におけるトークンの独立予測の問題に対処します。
しかし、ARアプローチにも欠点がある。それは、特定の位置にあるトークンを予測するときに先行するトークンだけを考慮することである。これは、予測されるトークンがシーケンスの末尾にある場合には問題にはならない。しかし、シーケンスの先頭にある場合は、このアプローチの使用は問題となり、XLNetの潜在的な限界が浮き彫りになる。
この問題に対処するため、XLNetは順列言語モデリング(PLM)を導入した。この方法は入力シーケンス全体をランダムに順列化し、順列化されたシーケンスの最後にあるトークンを予測する。
 XLNetプレトレーニングアプローチ.png
XLNetプレトレーニングアプローチ.png
XLNet事前学習アプローチ.png
例えば、(x1, x2, x3, x4, x5)という入力シーケンスが与えられると、(x3, x2, x5, x1, x4)に順列化される。XLNetのタスクは、(x3, x2, x5)からトークンx1を、(x3, x2, x5, x1)からトークンx4を予測することである。
しかし、PLMを導入したからといって、XLNetが完璧なモデルであるとは限らない。Transformer-encoderブロックの本質はその双方向性にあり、つまりモデルは入力シーケンス内のすべてのトークンの位置情報を知っている必要がある。このコンセプトはXLNetが採用しているARアプローチでは完全には実現されておらず、先行するトークンの位置情報しか考慮されていない。
さらに、XLNetで適用されているARコンセプトは、2つの事前学習手順であるイントレーニングとファインチューニングのプロセス間にミスマッチをもたらす。XLNetをテキスト分類のような下流のタスクに使用する場合、入力シーケンス全体の位置情報が最初から利用可能である。
そこで、BERT と XLNet の両方の利点を活用しつつ、それらの限界を回避するために、MPNet と呼ばれる統一モデルが導入された。
MPNetの学習手順を理解する
MLMの利点は入力シーケンス全体の位置情報を考慮できることであり、PLMの利点は自己回帰的アプローチによってマスクされたトークン間の依存関係をモデル化できることである。MPNetはMLMとPLMの長所を組み合わせて動作する。MPNetは文章を密なベクトル空間にマップし、効果的なクラスタリングと意味検索を可能にする。では、MPNetは具体的にどのようにMLMとPLMを組み合わせているのだろうか?
まず、MLMとPLMの両方でマスクされたトークンが融合される。入力シーケンス(x1, x2, x3, x4, x5)を考える。この並びはランダムに並べ替えられ、(x3, x2, x5, x1, x4)となる。
MPNetはシーケンスの右端のトークン(例:x1, x4)をマスクされたトークンとして選択する。そして、マスクされていないトークンを、対応する位置情報(p3, p2, p5, p1, p4)と共に、(x3, x2, x5, [M], [M]) として並べる。学習過程では、ランダムにサンプリングされた他の文の集合を調べることで、データセットからどの文が与えられた文と対になっているかを予測する。
各トークンのMPNet自己アテンション.png
上のビジュアライゼーションに示すように、MPNetはPLMの一般的な特徴である2ストリームの自己注意を利用している。例えば、トークンx4を予測するとき、モデルは(x3+p3, x2+p2, x5+p5)と以前に予測されたトークン(x1+p1)を考慮することができる。このアプローチはMLMに関連する制限を緩和する。
また、MPNet はマスクされたトークンのマスク記号と位置情報(˶[M]+p1,˶[M]+p4)を組み込 んで、各トークンが入力シーケンス全体の文脈と位置情報を見ることができるようにする。例えば、トークン x1 を予測するとき、モデルは(x3+p3, x2+p2, x5+p5)と、(˶[M]+p4)を介してそれに続くマス クトークンを考慮することができる。このアプローチはPLMに関連する制限を緩和する。
MPNetは様々な自然言語推論(NLI)タスクにおいて、BERT](https://zilliz.com/learn/what-is-bert)、 XLNet、RoBERTaといった従来の最先端[モデル]よりも優れた性能を発揮している。MPNetはまた、自己教師付き対照学習アプローチを使用して、広範なデータセットで文埋め込みモデルを学習するために使用されます。
他のモデルと比較したNLIタスクにおけるMPetの性能.png
MPNetの実装
様々なNLIタスクでの性能から、MPNetが文レベルのembedding of textを得るためのSentence Transformersモデルとして使われるようになったのは驚くことではありません。All-MPNet-Base-V2は、約10億のテキストペアで学習された、センテンス埋め込みのための一般的なMPNetモデルです。sentence-transformersと呼ばれる一般的なライブラリを通して、このモデルを使って文埋め込みを生成することができます。
次のセクションでは、自然言語処理で最も人気のあるタスクの1つである情報検索に対応するために、All-MPNet-Base-V2 モデルを使ってテキストから文埋め込みを生成する方法の例を提供します。そのために、sentence-transformersライブラリとPyTorchを利用します。
まず、モデルをロードしましょう。
pip install sentence-transformers
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-mpnet-base-v2")
データベースに複数のテキストがあり、それぞれをAll-MPNet-Base-V2モデルで文埋め込みに変換したいとします。これを行うには、単純に model_encode() 関数を呼び出します。
コーパス = [
「男が食べ物を食べている、
「女の子が赤ちゃんを抱いている、
「男が馬に乗っている、
「女性がバイオリンを弾いている、
]
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
あるクエリのシナリオを考えてみよう:"***男が食卓に座っている。彼は何をしているのですか?情報検索タスクでは、データベース内のテキストのコレクションから最も確率の高い答えを取り出すことが目標となる。
そのために、クエリと各テキストの間の類似度を計算することができる。文の類似度は、sentence-transformersライブラリのcos_sim()メソッドや、scikit-learnのような一般的な機械学習ライブラリを用いて計算することができる。
query = "男性が食卓に座っています。彼は何をしていますか?"
query_embedding = model.encode(query, convert_to_tensor=True)
# 余弦類似度を使用して、コーパスの中からクエリとの類似度が最も高いテキストを見つける
similar_text_idx = util.cos_sim(query_embedding, corpus_embeddings)[0].argmax().item()
print("Query:", query)
print("Most probable answer:")
print(corpus[similar_text_idx])
"""
出力
クエリーある男が食卓に座っている。彼は何をしているのか?
最も可能性の高い答え
男が食べ物を食べている。
"""
これはセンテンスエンベッディングの多くのユースケースのひとつに過ぎない。また、テキスト分類、質問応答、文書要約、文書クラスタリング、チャットボットなどのタスクの解決にも使うことができます。
GPT-4やLLAMAのような強力なLLMモデルが出現して以来、文変換モデルによって生成された文埋め込みは、Retrieval-Augmented Generation ([RAG]テクニック)(https://zilliz.com/learn/guide-to-chunking-strategies-for-rag)を介して、LLMによって行われた予測を補完するために一般的に使用されている。これにより、生成されるレスポンスがクエリに文脈的に関連していることが保証される。
MPNetの事前学習モデルから得られる文埋め込みは一般的に高品質であるが、高度に文脈化されたテキストや外国語のテキストを収集するシナリオもある。このような場合、事前学習されたモデルからの文埋め込みだけでは十分でない可能性がある。
このような状況に直面した場合、1つの解決策は、自分自身でモデルを微調整することです。そのためには、学習データを準備する必要があります。All-MPNet-Base-V2の1つの学習例は、1組のテキストと、その間の類似度をラベルとして構成される。テキストのペア間の類似度は、特定のユースケースに基づいて変化する可能性があります。公式の文型変換ライブラリは、ファインチューニングのための学習データを準備する手順を詳しく説明した包括的なドキュメントを提供しています。All-MPNet-Base-V2モデルを微調整する主な目的は、類似するテキストのペア間の距離を近く保ちながら、非類似のテキストのペアをより遠くに押しやることです。しかし、ユースケースや各テキストのペアをどのようにラベル付けするかに応じて、適切なコスト関数を選択することが重要です。こうすることで、微調整プロセスが特定の目的に沿ったものになります。
どのコスト関数がユースケースに適切かわからない場合は、文型変換ライブラリの公式 ドキュメント を参照してください。そこには、学習データと選択した損失関数を使用してモデルを微調整する方法についてのガイダンスもあります。
MPNetは、BERTとXLNetの長所を組み合わせると同時に、それらの限界に対処したモデルです。その結果、多くの自然言語推論(NLI)タスクでBERTとXLNetの両方を上回ることが多く、テキストから文脈に沿った文埋め込みを生成するための一般的な選択肢となっています。
当初、文埋め込みは主にテキスト分類、質問応答、文書要約意味検索、テキストクラスタリング、情報検索、チャットボットなどの様々な自然言語処理タスクに使用されていた。しかし、強力な大規模言語モデル(Large Language Models: LLM)の登場以来、MPNetからの文埋め込みもLLMが生成する予測を補完するために利用されるようになりました。これにより、クエリに文脈的に関連するLLMからの応答を得ることができる。
本稿がMPNetの基礎的な概要を提供できれば幸いである!
セマンティック検索アプリケーション
all-mpnet-base-v2モデルは、単なるキーワードのマッチングではなく、 文書や文章をその意味に基づいて検索することを目的とした、 意味検索アプリケーションで輝きを放ちます。この能力は、学術論文検索、技術レポート検索、長いウェブページ分析などの分野で特に価値がある。長文のテキストを扱い、高品質の文埋め込みを生成するこのモデルの能力により、複雑な文書の文脈と意味を正確に捉えることができる。さらに、all-mpnet-base-v2モデルは効率的に設計されているため、計算能力が制限される低リソース環境での使用に適している。この汎用性により、幅広い意味検索タスクに対応し、正確で文脈に関連した結果を提供する貴重なツールとなっている。
モデルの評価と性能
all-mpnet-base-v2モデルは、SEB(Sentence Embeddings Benchmark)を含む様々なベンチマークタスクにおいて厳密な評価を受けている。その結果、このモデルはクラスタリングなどのタスクでトップ5のランキングを獲得するなど、目覚ましい成果を上げています。さらに、文対の大規模なデータセットでモデルの微調整を行い、文の類似性タスクでの性能を大幅に向上させた。このファインチューニングにより、文とその意味との対応付けが正確に行えるようになり、文書検索や質問応答などのタスクに非常に有効なモデルとなった。これらのタスクにおけるこのモデルの強力な性能は、その頑健性と信頼性を証明し、文脈に基づく文埋め込みを生成するための主要な選択肢としての地位を確固たるものにしている。
MPNet言語理解を超えて
さて、ここまでMPNetの詳細を見てきたが、BERT、XLNet、RoBERTaと比較してどうなのか気になるだろう。しかし、その結果は素晴らしいものでした!MPNetはさまざまなNLPタスクでテストされ、軒並み好成績を収めています。以下は、MPNet:Song et al. (2020) Masked and Permuted Pre-training for Language Understanding paper:。
GLUEベンチマーク:NLPの十種競技
一般言語理解評価(GLUE)ベンチマークは、NLPタスクの十種競技のようなものです。センチメント分析から質問応答まで、あらゆるモデルをテストします。MPNetはこれらのタスクで平均87.7点を獲得し、RoBERTa(86.4点)、XLNet(84.5点)、BERT(83.1点)を上回りました。
特に印象的なのは、RTE(Recognizing Textual Entailment)のようなタフなタスクでのMPNetのパフォーマンスです。MPNetのスコアは85.2%で、RoBERTaの78.7%を大きく上回っている。これは、MPNetが言語の微妙なニュアンスをよりよく理解していることを示している。
質問応答
与えられたテキストに基づいて質問に答えるタスク(SQuADタスク)に関しては、MPNetが再び勝者となった。SQuAD v2.0では、テキストに答えがないような質問も含まれていますが、MPNetは82.8%の完全一致と85.6%のF1を記録しました。RoBERTaの80.5%と83.7%と比較すると、その違いがお分かりいただけるでしょう。
読解力ゴールへの競争
ReAding Comprehension from Examinations (RACE)データセットは、中学・高校の英語試験に基づいているため、厳しいものです。MPNetの総合スコアは72.0%で、BERT(65.0%)とXLNet(66.8%)を上回った。これは、MPNetが長い文章を理解し推論するのに優れていることを意味する。
MPNetの特徴
なぜMPNetはこれらのタスクでこれほど優れているのだろうか?その答えは、その事前学習方法にある。マスク言語モデリング(BERTで使用)とパーミュート言語モデリング(XLNetで使用)の長所を組み合わせることで、MPNetはより総合的に言語を学習します。
さらに、MPNetの補助的な位置情報を見る機能は、事前学習と微調整のギャップを埋めるのに役立ちます。そのため、MPNetが特定のタスクのためにファインチューニングされたモデルを事前学習した場合、事前学習した知識をより有効に活用することができる。
MPNetは、BERTとXLNetの長所を組み合わせると同時に、それらの限界に対処するモデルです。その結果、多くの自然言語推論(NLI)タスクでBERTとXLNetの両方を上回る性能を発揮することが多く、テキストから文脈に沿った文埋め込みを生成するための一般的な選択肢となっている。
当初、文埋め込みは主にテキスト分類、質問応答、文書要約意味検索、テキストクラスタリング、情報検索、チャットボットなどの様々な自然言語処理タスクに使用されていた。しかし、強力な大規模言語モデル(Large Language Models: LLM)の登場以来、MPNetからの文埋め込みもLLMが生成する予測を補完するために利用されるようになりました。これにより、クエリに文脈的に関連したLLMからの応答を得ることができる。
本稿がMPNetの基礎的な概要を提供できれば幸いである!
セマンティック検索アプリケーション
all-mpnet-base-v2モデルは、単なるキーワードのマッチングではなく、 文書や文章をその意味に基づいて検索することを目的とした、 意味検索アプリケーションで輝きを放ちます。この能力は、学術論文検索、技術レポート検索、長いウェブページ分析などの分野で特に価値がある。長文のテキストを扱い、高品質の文埋め込みを生成するこのモデルの能力により、複雑な文書の文脈と意味を正確に捉えることができる。さらに、all-mpnet-base-v2モデルは効率的に設計されているため、計算能力が制限される低リソース環境での使用に適している。この汎用性により、幅広い意味検索タスクに対応し、正確で文脈に関連した結果を提供する貴重なツールとなっている。
モデルの評価と性能
all-mpnet-base-v2モデルは、SEB(Sentence Embeddings Benchmark)を含む様々なベンチマークタスクにおいて厳密な評価を受けている。その結果、このモデルはクラスタリングなどのタスクでトップ5のランキングを獲得するなど、印象的な結果を残しています。さらに、文対の大規模なデータセットでモデルの微調整を行い、文の類似性タスクでの性能を大幅に向上させた。このファインチューニングにより、文とその意味との対応付けが正確に行えるようになり、文書検索や質問応答などのタスクに非常に有効なモデルとなった。これらのタスクにおけるこのモデルの強力な性能は、その頑健性と信頼性を実証し、文脈に基づく文埋め込みを生成するための主要な選択肢としての地位を確固たるものにしている。



