




ミクスチャー・オブ・エキスパート(MoE)とは?
専門家の混合(MoE):異なるタスクに特化した専門家を選択することで、モデルの効率性と拡張性を向上させるニューラルネットワークアーキテクチャ。
シリーズ全体を読む
- Natural Language Processing Fundamentals: Tokens, N-Grams, and Bag-of-Words Models
- Primer on Neural Networks and Embeddings for Language Models
- Sparse and Dense Embeddings
- Sentence Transformers for Long-Form Text
- Training Your Own Text Embedding Model
- Evaluating Your Embedding Model
- Class Activation Mapping (CAM): Better Interpretability in Deep Learning Models
- CLIP Object Detection: Merging AI Vision with Language Understanding
- Discover SPLADE: Revolutionizing Sparse Data Processing
- Exploring BERTopic: A New Era of Neural Topic Modeling
- Streamlining Data: Effective Strategies for Reducing Dimensionality
- All-Mpnet-Base-V2: Enhancing Sentence Embedding with AI
- Time Series Embedding in Data Analysis
- Enhancing Information Retrieval with Learned Sparse Retrieval
- What is BERT (Bidirectional Encoder Representations from Transformers)?
- What is Mixture of Experts (MoE)?
複雑な問題を解決するために協力し合う専門家チームを想像してみてほしい。それぞれの専門家はユニークなスキルを持ち、チームは効率的にタスクを分担することで比類ない成功を収める。これは、Mixture-of-Experts(MoE)モデルアーキテクチャの基本的な考え方であり、機械学習システム、特にニューラルネットワークを効率的に拡張することを可能にする手法である。MoEは、単一のニューラルネットワークにすべてのタスクを処理させる代わりに、ゲーティング・ネットワークによって、各入力に対してどのエキスパートを活性化させるべきかを決定しながら、複数の専門化された「エキスパート」に作業を分担させる。
モデルが大きく複雑になるにつれ、特にNLPやLLMでは、数十億、あるいは数兆のパラメーターに拡張しても効率と精度を維持することが最大の課題の1つになります。すべての入力に対してすべてのレイヤーとニューロンをアクティブにする従来のモデルは、膨大な計算コストがかかり、推論が遅くなり、多くのメモリを消費する。このような大規模なモデルを、スピードとスケーラビリティが重要な実世界のアプリケーションに展開するのは大変な作業です。
Mixture of Expertsは、一度に少数のエキスパートのサブセットのみをアクティブにすることで、この問題を解決し、パフォーマンスを犠牲にすることなく計算オーバーヘッドを削減します。MoEにおけるこの協調的アプローチは、自然言語処理(NLP)や、OpenAIのGPTのような大規模言語モデル(LLM)において、ますます重要になってきている。そこでは、モデルは効率と精度を維持しながら、数十億のパラメータまでスケールアップする必要がある。
この投稿では、MoEの中核概念、大規模言語モデル、トレーニング、推論、および最新のAIモデルにおけるそれらの役割について説明する。
MoEとは何かとそのコアコンセプト
**簡単に言うと、MoE(Mixture of Experts)とは、入力の異なる部分を処理するために特化したサブモデル、つまり「エキスパート」を動的に選択することによって、モデルの効率性と拡張性を向上させるように設計された高度なニューラルネットワークアーキテクチャです。
エキスパート混合モデルは、3つの主要コンポーネントから構成される:
専門家**:特定のタスクに特化したサブモデル。
ゲートネットワーク**:入力データを関連するエキスパートにルーティングするセレクタ。
疎活性化**:計算効率を最適化するために、入力ごとに少数のエキスパートだけをアクティブにする方法。
エキスパート
MoEアーキテクチャにおけるエキスパートとは、特定のデータやタスクを処理するように訓練された個々のサブネットワーク(ニューラルネットワークまたはレイヤー)のことである。例えば、画像分類タスクでは、あるエキスパートはテクスチャの認識に特化し、別のエキスパートはエッジや形状の識別に特化するかもしれない。このように分割することで、各エキスパートが最適なタイプのデータのみを扱うため、モデル全体がより効果的に問題にアプローチできるようになる。
ゲーティング・ネットワークまたはルーター
ゲーティング・ネットワーク は、どの入力データをどのエキスパートに送るかを決定するセレクタ として機能する。すべての専門家が同時に働くのではなく、ゲーティングネットワークは最も関連性の高い専門家にデータをルーティングする。トークン選択ルーティング戦略のように、ルーティングアルゴリズムは各トークンに最適な1人か2人のエキスパートを選ぶ。例えば、下の画像では、入力トークン1「We」は2番目のエキスパートに送られ、入力トークン2「Like」は1番目のネットワークに送られる。
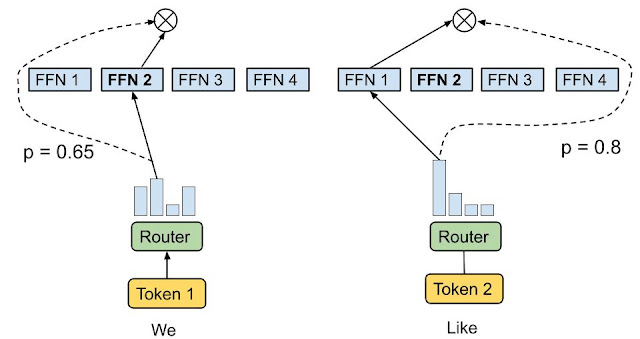
トークンの選択ルーティング|出典
様々なトークン・ルーティング技術が利用可能である。以下はよく使われる方法です。
Top-kルーティング:**これは最も単純な方法である。ゲーティング・ネットワークは、最も高い親和性スコアを持つトップkのエキスパートを選択し、入力データを彼らに送る。
エキスパート選択ルーティング:***データがエキスパートを選択する代わりに、エキスパートがどのデータを最もうまく扱えるかを決定する。この戦略は最良の負荷分散を達成することを目的とし、データをエキスパートにマッピングする様々な方法を可能にする。
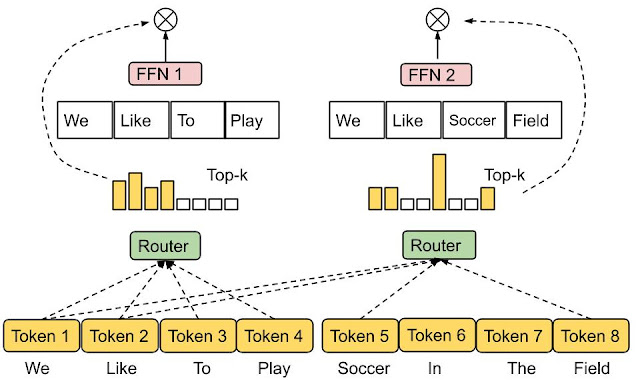
エキスパート・チョイス・ルーティング|出典
スパース活性化
スパース活性化は、Mixture-of-Experts(MoE)モデルの主な利点の1つである。すべての入力に対してすべてのエキスパートまたはパラメータがアクティブになる密なモ デルとは異なり、スパース活性化は、入力データに基づいてエキスパートの小さなサブセットだけがアク ティブになるようにします。この方法では、常に最も関連性の高いエキスパートだけがアクティブになるため、性能を維持しながら計算量を削減することができます。
- スパース・ルーティング:** ゲーティング・ネットワークが入力ごとに少数のエキスパートだけをアクティブにする、スパース・アクティベーションの特殊な手法。
ディープラーニングにおけるMoE:歴史的進化
MoEのルーツは1991年の論文 Adaptive Mixture of Local Expertsにある。この論文は、複雑な問題を部分問題に分割し、それらを複数の特化モデルに割り当てるというアイデアを紹介した。この分割統治戦略は、MoEアーキテクチャの中核となった。
MoEの進化は、さらに2つの重要な研究分野によって形作られた:
コンポーネントとしての専門家:**当初、MoEはサポートベクターマシン(SVM)やガウス過程のようなモデルに適用されていた。しかし、Eigen, Ranzato, and Ilyaによる研究は、deep neural networks内のコンポーネントとしてMoEを統合することによってこのアプローチを拡張し、より大きなモデル内のレイヤーとして機能することを可能にしました。
しかし、Yoshua Bengioの研究は条件付き計算を導入し、入力に基づいてネットワーク構成要素を選択的に活性化または非活性化する。この動的アプローチは、各入力に対してモデルの必要な部分のみが使用されるため、より効率的な計算につながった。
大規模 NLP モデルにおける MoE:GShardとスイッチ・トランスフォーマー
自然言語処理(NLP)におけるMoEの影響は、 GShard や Switch Transformer のようなモデルで確固たるものとなった。2021年、GoogleのSwitch Transformerは1.6兆個のパラメータを持つに至り、MoEが多くの計算を必要とするタスクを処理できることを示した。入力ごとに数人の専門家だけを起動させることで、パラメータ数が増えても効率的なモデルを維持した。
もう1つの大きなマイルストーンは、2017年に Shazeer et al. がSparseely Gated Mixture-of-Experts Layerを導入し、ディープラーニングにおけるスパース活性化を可能にしたことである。これによって、機械翻訳のようなタスクで1,370億ものパラメータを持つモデルが可能になり、入力ごとに最も関連性の高いエキスパートだけを活性化することで、低い推論コストを維持できるようになった。
NLPを超えて:視覚とマルチモーダルモデルにおけるMoE
MoEはNLPを超えている。例えばGoogleのV-MoEアーキテクチャは、コンピュータビジョンタスクにスパースMoEフレームワークを使用し、Vision Transformers (ViT)を使用してエキスパートに特化した画像分類を行う。これにより、画像モデルをテキストモデルのように拡張することができる。
研究が進むにつれて、さまざまなドメインにわたる複雑なタスクへのMoEの適用可能性は、ますます高まっていくでしょう。MoEは、ディープラーニングにおいて、より効率的でスケーラブルな、タスクに特化したモデルを目指す幅広いトレンドの一部であり、最新のAIアーキテクチャの構成要素の1つです。
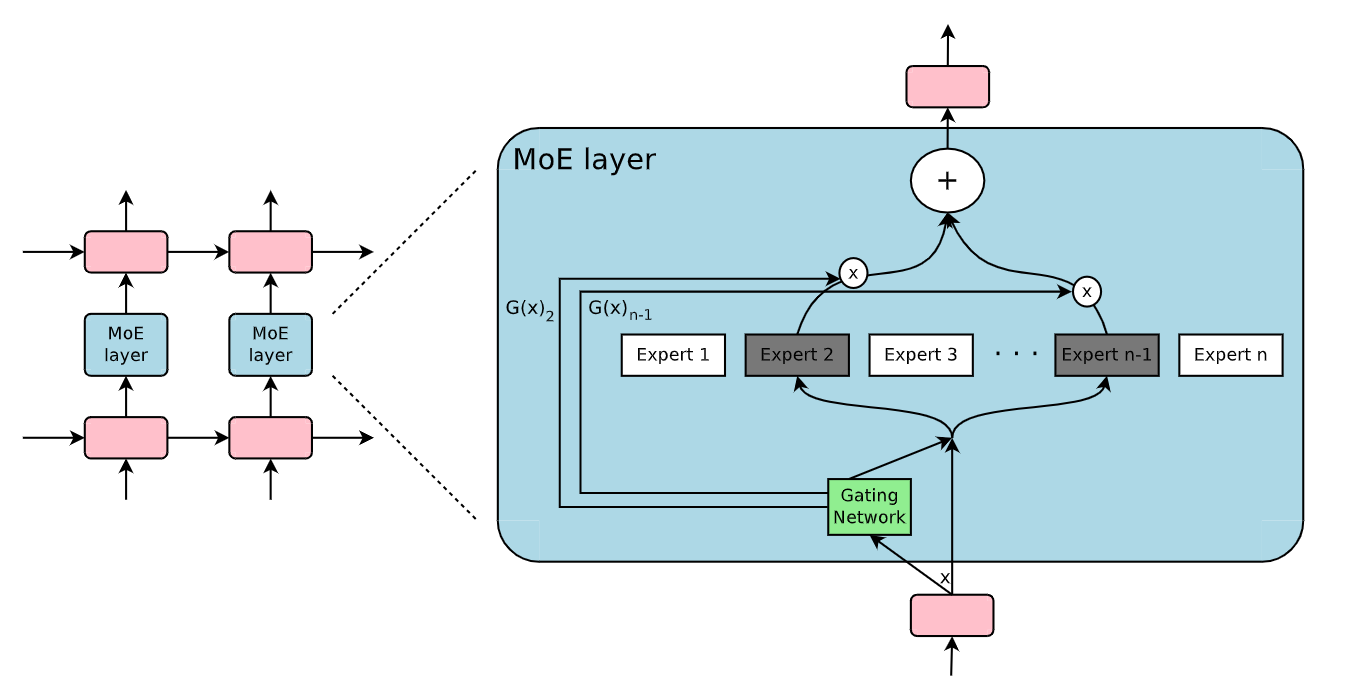
専門家の混合(MoE)層|出典
MoE アーキテクチャの詳細(どのように機能するか)
専門家の混合(Mixture-of-Experts)アーキテクチャは、主に2つのプロセスで運用することができる:
トレーニング
推論
トレーニング
他の機械学習モデルと同様、MoEモデルはデータから学習するが、その学習プロセスは独特である。MoEは、モデル全体を単一のエンティティとして学習するのではなく、個々のコンポーネント(エキスパートとゲーティング・ネットワーク)を個別に学習することに重点を置いている。このようにして、各エキスパートは指定されたタスクに特化するようになり、ゲーティング・ネットワークは入力を適切なエキスパートに効率的にルーティングするように学習する。
専門家のトレーニング
MoE モデル内の各エキスパートは個別の ニューラルネットワーク として扱われ、データまたはタスクのサブセットでトレーニングを受けます。各エキスパートのトレーニングは、モデルが特定のデータサブセットの損失関数を最小化するように学習する、標準的なニューラルネットワークトレーニングプロセスに従う。
例えば、自然言語処理モデルでは、あるエキスパートは、形式的な言語に特化するために、形式的な文書のデータセットで訓練されるかもしれない。これとは対照的に、別の専門家はソーシャルメディア上の会話でトレーニングを受け、インフォーマルなコミュニケーションに習熟する。このように個々に訓練することで、専門家は特定のドメインに高度に精通できるようになる。
ゲートネットワーク訓練
ゲーティングネットワークは、与えられた入力に対して最適なエキスパートを選択する、意思決定者の役割を果たす。このネットワークはエキスパートネットワークと並行してトレーニングされるが、役割は異なる。ゲーティング・ネットワークへの入力は、モデル全体に供給されるのと同じデータであり、テキストや画像などの生データ、またはモデルのタスクに基づく任意の入力を含むことができる。ゲーティング・ネットワークの出力は、どのエキスパートが現在の入力を処理するのに最も適しているかを示す確率分布である。
ゲーティング・ネットワークの学習は通常、教師付きで行われ、学習段階ではラベル付きデータが提供される。ゲーティング・ネットワークは、提供されたラベルに基づいて入力を分類し、正しい専門家に割り当てることを学習する。訓練中、ゲーティング・ネットワークはエキスパートの選択が正確になるように最適化され、MoEモデルの全体的なパフォーマンスが向上する。
共同トレーニング
共同トレーニングフェーズでは、エキスパートモデルとゲーティングネットワークを含むMoE(Mixture of Experts)システム全体がトレーニングを受けます。この戦略により、ゲーティングネットワークとエキスパートの両方が調和して動作するように最適化されます。共同トレーニングにおける損失関数は、個々のエキスパートとゲーティングネットワークからの損失を組み合わせ、両方のコンポーネントが全体的なパフォーマンスに貢献することを保証する。
結合された損失勾配は、ゲーティングネットワークとエキスパートモデルを通じて伝播され、MoEシステムのパフォーマンスを向上させる更新を促進する。
推論フェーズ
推論中、ゲーティング・ネットワークは入力を受け取り、正しい出力を提供する可能性が最も高い上位 k 人のエキスパートを選択する。選択された専門家は入力を処理し、予測を生成する。このようにエキスパートを選択的に活性化することで、MoEは完全連結モデルの数分の一の計算コストで予測を行うことができる。
スパース活性化の威力
MoEの主な利点の1つは、条件計算の概念に由来するスパース活性化の使用である。すべての入力に対してすべてのパラメータが活性化される従来の「密な」モデルとは異なり、MoEは必要なネットワーク部分のみを選択的に活性化します。このアプローチにはいくつかの利点がある:
効率性:** MoEモデルは、最も関連性の高いエキスパートだけを活性化することで、はるかに少ない計算リソースで大量のデータを処理することができます。これは、処理時間とメモリ要件がすぐに法外なものになる可能性のある、自然言語処理で使用されるような大規模モデルにとって特に重要である。注目すべき例として、Mistral 8x7Bがある。これは高品質なスパース混合エキスパートモデル(SMoE)で、8人のエキスパートを持つ混合エキスパートのフレームワークを使用している。各エキスパートは11Bのパラメータと55Bの共有注意パラメータを持ち、モデルあたり合計166Bとなる。興味深いのは、推論中、各トークンに対して2人のエキスパートだけが使用され、AI処理をより効率的で集中的なものにしていることだ。
負荷分散:*** スパース活性化で重要な考慮点の1つは、全てのエキスパートが十分な訓練を受けることを保証することである。少数のエキスパートだけがゲーティング・ネットワークによって一貫して活性化されると、他のエキスパートが十分に活用されないまま、そのエキスパートが過剰に専門化される可能性がある。この不均衡を防ぐために、最新のMoE実装ではNoisy Top-k Gating, Shazeer et al. (2017)のような技術を使用しています。これは、エキスパート選択プロセスに少量の(調整可能な)ノイズを追加することで、すべてのエキスパートによりバランスの取れたトレーニングの配分を保証します。
従来のモデルに対するMoEの利点と課題
利点
ミクスチャー・オブ・エキスパート(MoE)アーキテクチャは、従来のディープラーニングモデルに対していくつかの利点を提供する。
スケーラビリティの向上:** MoEモデルは、スパース活性化により数十億、数兆のパラメータまで容易にスケールし、大規模な計算能力の必要性を低減します。
MoEのユニークな利点の1つは、システム全体を再トレーニングすることなく、既存のモデルに新しいエキスパートを追加できることです。この適応性により、モデルは新しいタスクやドメインに容易に対応できる。
効率性:*** MoEは各入力に対して最も関連性の高いエキスパートだけをアクティブにするので、従来のモデルよりも効率的に多様なタスクを処理できる。そのため、専門家が得意とすることに集中できるため、より迅速で正確な処理が可能になります。
並列処理:** 専門家は独立して作業できるため、効率的な並列処理が可能です。このアプローチにより、学習と推論の時間を短縮することができます。
課題
上記のような利点があるにもかかわらず、MoEモデルにも一定の課題と限界がある。
MoEモデルのトレーニングは、特にゲーティング・ネットワークを管理し、個々の専門家の貢献のバランスをとる上で、困難な場合がある。ゲーティング・ネットワークがエキスパートに適切な重みを効果的に割り当てることを学習し、特定のエキスパートの過剰適合や過小利用を防ぐことが重要である。
通信コスト:*** MoEモデルは、複数のエキスパートとゲーティング・メカニズムを管理するため、学習と推論時に多大なインフラ・リソースを必要とする。さらに、特に様々なデバイスや分散システムにまたがって大規模に展開される場合、通信オーバーヘッドが大きな課題となります。異なるサーバー上の様々なエキスパートからの出力を調整し同期させることは、待ち時間と計算負荷の増加につながります。 ****
エキスパート能力:*** 特定のエキスパートに過負荷がかかるのを防ぎ、バランスの取れた作業負荷を確保するため、各エキスパートが同時に処理できる入力数にしきい値が設定される。一般的なアプローチは、容量係数1.25のトップ2ルーティングを使用することである。これは、入力1つにつき2人のエキスパートが選択され、各エキスパートが通常の容量の1.25倍を処理することを意味する。この戦略では、コアごとに1人のエキスパートを割り当て、パフォーマンスとリソース管理を最適化する。
解釈可能性:**不透明性は、主要なLLMを含め、AIにおいて既に顕著な問題である。専門家の混合(MoE)モデルは、より複雑であるため、これをさらに難しくする可能性があります。単に1つのモデルがどのように意思決定を行うかを見るのではなく、異なる専門家とゲートシステムがどのように連動するかを解明しなければならない。このような複雑さが増すと、モデルがある選択をした理由を理解するのが難しくなります。
MoEの応用
MoEはすでに幅広い用途で使われている。
自然言語処理:** Mixture-of-experts (MoE)モデルは、各タスクを専門家に割り当てることができるため、翻訳、感情分析、質問への回答などの言語タスクに最適です。例えば、OpenAIのGPT-4大規模言語モデルは16人の専門家を持つMoEセットアップを使用していることが報告されているが、OpenAIはその設計の詳細を公式に確認していない。もう一つの例は、マイクロソフトの翻訳APIであるZ-codeである。Z-codeのMoEアーキテクチャは、同じコンピューティングパワーを使いながら、大規模なモデルパラメータをサポートすることを可能にしている。
コンピュータビジョン:** Google's V-MoEsは、Vision Transformers (ViT)に基づくスパースアーキテクチャであり、MoEがコンピュータビジョンのタスクにいかに効果的であるかを示している。MoEモデルは画像処理において、専門化されたエキスパートに異なるタスクを与えることで役立ちます。例えば、ある専門家は、特定の種類のオブジェクト、特定の視覚的特徴、あるいは画像の他の部分に焦点を当てるかもしれない。
マルチモーダル学習:** MoEは、テキスト、画像、音声など、複数のソースからのデータを1つのモデルに組み合わせることができる。このためMoEは、異なるモダリティからのデータを統合する必要があるマルチモーダル検索やコンテンツ推薦のようなアプリケーションに理想的である。
MoEの今後の方向性
今後数年間、MoE(Mixture-of-Experts)の研究は、モデルをより効率的で理解しやすくすることに重点を置くだろう。これには、エキスパートの連携方法の改善や、適切なエキスパートにタスクを割り当てるより良い方法の発見が含まれる。
MoEモデルは、計算コストを最小限に抑えながら、さらに大きなサイズに拡張することができる。これには、増加するエキスパートとデータのサイズに対応するために、学習と推論のフェーズを最適化することが含まれる。タスクを複数のマシンに効率的に分散させ、ボトルネックを減らし、モデルの動作を高速化する分散コンピューティングなどの技術が研究されています。
革新的なルーティングメカニズム:*** もう一つの研究分野は、より効率的なルーティング戦略の開発に焦点を当てている。top-kルーティングのような既存の手法が一般的に使用されている一方で、Expert Choice Routingのような高度な手法は、エキスパートへのタスク割り当てを改善することを目的としています。これにより、より効率的な負荷分散と、タスクとエキスパートのマッチングの改善につながり、モデルが異なる条件下で最適に動作することを保証することができる。
実世界での応用:** MoEモデルは、複雑なタスクを処理する能力があるため、ヘルスケアや自律システムのような実世界の応用において大きな可能性を秘めている。ヘルスケア](https://zilliz.com/learn/the-role-of-vector-databases-in-patient-care)では、パーソナライズされた治療計画に利用でき、自律システムでは物体認識や意思決定のようなタスクに利用できる。
結論
Mixture-of-Experts は強力なモデル・アーキテクチャであり、タスクを専門化されたエキスパートに分担させることで、ニューラルネットワークを効率的にスケールさせることができる。スパース活性化により、MoEモデルは従来のモデルの数分の一の計算コストで膨大なデータセットと複雑なタスクを処理できる。MoEは、学習の複雑さや通信コストの点で課題があるものの、スケーラビリティ、柔軟性、効率性の点で優れているため、最新の AIアプリケーションの選択肢としてますます人気が高まっている。自然言語処理](https://zilliz.com/learn/top-10-natural-language-processing-tools-and-platforms)から コンピュータビジョンや マルチモーダル課題に至るまで、MoEモデルは専門家が異なる分野に特化することを可能にし、速度と精度の両方を向上させることでその価値を証明している。
その他のリソース
MilvusによるChatGPTの強化](https://zilliz.com/learn/enhancing-chatgpt-with-milvus)
知っておくべきマルチモーダルAIモデル・ベスト10](https://zilliz.com/learn/top-10-best-multimodal-ai-models-you-should-know)
マルチモーダル検索拡張生成(RAG)](https://zilliz.com/learn/multimodal-RAG)
LLMOpsを始めよう:より良いAIアプリケーションの構築](https://zilliz.com/blog/get-started-with-llmops-build-better-ai-applications)
ベクターデータベースとは何か、どのように機能するのか](https://zilliz.com/learn/what-is-vector-database)
Retrieval Augmented Generation (RAG)でAIアプリケーションを構築する](https://zilliz.com/learn/Retrieval-Augmented-Generation)
AIエージェントとは何か、知っておくべきこと](https://zilliz.com/glossary/ai-agents)
CLIP物体検出:AIビジョンと言語理解の融合](https://zilliz.com/learn/CLIP-object-detection-merge-AI-vision-with-language-understanding)
Llama3とMilvusを使ったRAG(Retrieval-Augmented Generation)システムの作り方](https://zilliz.com/learn/how-to-build-rag-system-using-llama3-ollama-dspy-milvus)
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
読み続けて

自然言語処理の基礎:トークン、Nグラム、Bag-of-Wordsモデル
この記事では、今日のあらゆる言語モデルを理解するために不可欠な、自然言語処理の基礎について説明します。

All-Mpnet-Base-V2:AIによる文埋め込み機能の強化
センテンスエンベッディングの発展において重要な役割を果たしたディープラーニングモデルの1つを掘り下げる:MPNet。

BERT(Bidirectional Encoder Representations from Transformers)とは?
BERT(Bidirectional Encoder Representations from Transformers)とは何か、また、その驚くべき性能を実現するために、事前学習と微調整をどのように行っているのかをご紹介します。