




埋め込みモデルの評価
様々なテキスト埋め込みモデルを評価するために、いくつかの実用的な例を検討する。
シリーズ全体を読む
- 自然言語処理の基礎:トークン、Nグラム、Bag-of-Wordsモデル
- 言語モデルのためのニューラルネットワークとエンベッディング入門
- 疎な埋め込みと密な埋め込み
- 長文のためのセンテンス・トランスフォーマー
- 独自のテキスト埋め込みモデルをトレーニングする
- 埋め込みモデルの評価
- クラス活性化マッピング(CAM):ディープラーニングモデルにおけるより良い解釈可能性
- CLIP物体検出:AIビジョンと言語理解の融合
- SPLADEを発見:スパースデータ処理に革命を起こす
- BERTopicの探求:ニューラル・トピック・モデリングの新時代
- データの合理化次元を減らす効果的な戦略
- All-Mpnet-Base-V2:AIによる文埋め込み機能の強化
- データ分析における時系列の埋め込み
- 学習型スパース検索による情報検索の強化
- BERT(Bidirectional Encoder Representations from Transformers)とは?
- ミクスチャー・オブ・エキスパート(MoE)とは?
*最新更新:8月9日
人工知能は、様々なエンベッディングモデルの性能を評価するために特別に設計されたカスタムQ/Aデータセットを生成する上で重要な役割を果たします。
E5エンベッディングは、自然言語処理における画期的な開発であり、感情分析や機械翻訳などの様々なアプリケーションにおいて、言語理解を変換する能力を強調しています。
エンベッディングモデルの評価入門
過去数回のブログ記事で、今日のdense embeddingモデルのアーキテクチャについて説明し、sentence-transformersライブラリの基本的な使い方について見てきました。sentence-transformers](https://zilliz.com/learn/transforming-text-the-rise-of-sentence-transformers-in-nlp)では、多くの学習済みモデルを利用することができます。しかし、ほとんどすべてが、オリジナルのSBERTモデルと同じアーキテクチャを使用しています。つまり、マスクされた言語モデリングで訓練された変換エンコーダにプールされた特徴量です。
アプリケーションを構築する観点から、適切なテキスト埋め込みモデルを選択することは非常に重要であり、多くの場合、アプリケーション固有のニーズに依存します。このブログでは、モデルを選択するためのいくつかの重要な考慮事項をレビューします。また、Arize PheonixとRAGASを使用して、新しいモデルやオープンソースの埋め込みモデルを含む様々なテキスト埋め込みモデルを、既存のものと比較しながら評価する実践的な例についてもレビューします。
対照学習は、埋め込みモデルの主要な学習方法であり、特にE5モデルのコンテキストにおいて重要です。これは、テキストペアの多様なデータセットを活用し、単語間の意味的類似性を効果的に捕捉する高品質な埋め込みを生成することを可能にします。
重要な考慮事項
今日、ほとんどのアプリケーションは埋め込みを生成するためにOpenAIの埋め込みエンドポイントを使用しています。エンベッディングモデル](https://zilliz.com/learn/what-are-binary-vector-embedding)は、エンベッディングを開始するための優れた汎用的なモデルですが、多くの場合、a)あなたのエンベッディングモデル、またはb)別のオープンソースまたはクローズドソースのモデル](https://zilliz.com/learn/model-providers-open-source-vs-closed-source)に移行することが賢明です。オープンソースモデルは、費用対効果と柔軟性を提供しますが、統合とメンテナンスの複雑さを伴います。
例えば、e5-largeモデルは1024レイヤーのエンベッディングサイズを持ち、これはパフォーマンスに寄与する重要な特徴です。
これらの数値を評価する際には注意が必要です。ベンチマークに適合しすぎるものもあり、あなたのユースケースには理想的でないかもしれません。常に評価しましょう。意味的関係は、Word2VecやBERTのような埋め込みモデルで重要な役割を果たし、より良い言語理解と処理を可能にします。
タスクの種類と複雑さ
埋め込みタスクの複雑さは、埋め込みモデルの選択に大きく影響します。センチメント分析やキーワードマッチングのような単純なタスクは、[MTEB] leaderboard](https://zilliz.com/learn/evaluating-your-embedding-model)上の汎用モデルを使用し、妥当なパフォーマンスを達成することができます。単言語タスクと多言語タスクの両方をサポートする埋め込みモデルは、様々な言語を効果的に扱うことができ、適応性が高い。しかし、特殊な埋め込みを必要とするアプリケーションも多い。例えば、2つのシーケンス:
1."食べよう、クリス" 2."クリスを食べよう"
情報検索の文脈では、非対称タスクを認識することが重要である。非対称タスクでは、最適なモデル性能を確保するために、異なるタイプのクエリに対して正しい接頭辞が必要となる。
1番目と2番目のシーケンスは、余分なカンマを除いてほぼ同じです。そのため、ほとんどの汎用モデルでは、高次元埋め込み空間において、これら2つのシーケンスは互いに非常に近い位置に配置されます。しかし、(「適切さ」を強調するような)特定の用途では、これら2つの配列は、低い類似性を持つ、スペクトルの対極にあるべきです。これをもう一歩進めると、質問応答、言語翻訳、感情分析などのより複雑なタスクでは、タスクの微妙なニュアンスを捉えることができるモデルが必要になる。正解は1つではありません。
テキスト埋め込みタスクの文脈では、対称タスクは'query:'という接頭辞を利用する。これは、意味類似や言い換え検索のようなタスクでは、性能劣化を避けるために極めて重要である。
最適性能のためのモデル性能対コスト
埋め込みモデルの性能と計算効率はトレードオフの関係にあることが多い。様々なモデルが様々な長さの入力データを扱いますが、これは最大文脈長によって定義されます。e5-large](https://zilliz.com/ai-models/multilingual-e5-large)-v2オファーのような高性能モデルは、より「正確」ですが、より多くのパラメータとはるかに高い実行時間を必要とします。これは、リアルタイム性が要求されるアプリケーションや、ハードウェアの性能が限られているアプリケーションにとっては、制限要因となり得ます。入力テキストに正しい接頭辞を使用しないとパフォーマンスが低下し、文章検索や意味的類似性などのタスクにおけるモデルの有効性に影響を与える可能性があります。ユーザーと対面するチャットボットやレコメンダーシステムのようなリアルタイムで高スループットのアプリケーションでは、低遅延で高速な結果が必要です。このような場合、コストを最小化するために、よりコンパクトなモデルを選択することが賢明であることが多い。一方、法律文書や財務文書の限られた社内コーパスを横断するセマンティック検索のような、精度が最優先されるアプリケーションでは、より大きなモデルを使用する方が良い場合が多い。
テキストの領域
アプリケーションのテキストデータで使用される言語のドメイン固有性は、もう一つの重要な検討事項である。BERT やテキスト埋め込みなどの 自然言語処理 (NLP) 方法論は、機械が人間の言語をより正確に解釈し理解できるようにする上で、重要な役割を果たす。多くの埋め込みモデルは一般的な言語データで訓練されており、専門的な語彙や専門用語のニュアンスを捉えられない可能性がある。ドメインに特化したデータセットで訓練または微調整されたモデルは、そのドメイン内のテキストに対して、より正確な埋め込みを提供することができる。患者記録からの医療診断、法律文書の分析、特定の製品の技術サポートなどのアプリケーションでは、ドメイン固有のモデルは、これらの分野で使用される特殊な言語をよりよく理解することで、汎用モデルを大幅に上回ることができます。
query:」や「passage:」のような特定の接頭辞を持つ「入力テキスト」をタスクの種類に応じて適切にフォーマットすることは、モデルの性能に影響するため非常に重要である。正しいラベリングは、パッセージ検索や意味的類似性などのタスクにおいて、性能低下を防ぐために不可欠である。
意味的類似性のための埋め込みテキストの評価
適切な評価ツールがあれば、埋め込みモデルは強力なツールとなる。ada-002のような高度なテキスト埋め込みモデルは、テキストの類似性評価を強化するためにテキストを高次元ベクトルにマッピングすることにより、コード検索を含む様々なアプリケーションにおいて特に効果的である。線形プロービング分類は、特に意味的類似性や文章検索のような、適切な入力フォーマットや接頭辞がモデルの性能に大きく影響するタスクにおいて、この文脈で極めて重要である。このセクションでは、テキスト埋め込みモデルを評価する2つの方法を見ていきます。
アリゼ
Arize AIのPhoenixライブラリは、LLMの評価とモデルの埋め込みを支援する優れた多目的ツールである。特に、高次元埋め込みのログを取り、それを見るための簡単で柔軟な方法を提供する。さらに、様々なトークン制限を持つテキストの処理能力に影響を与える「コンテキストの長さ」を考慮する。READMEによると、"PhoenixはA/Bテストフレームワークを提供し、エンベッディングが時間とともにどのように変化しているか、またモデルの異なるバージョン間でどのように変化しているかを理解するのに役立ちます。"
問題のあるエンベッディングを理解するためにPhoenixを使う簡単な例を見てみましょう。そのために、まず前回のIMDbデータセットを見直します。以前、sentence-transformersライブラリを使って埋め込みを生成したことを思い出してください:
python from datasets import load_dataset from sentence_transformers import SentenceTransformer
IMDBデータセットをロードする
dataset = load_dataset("imdb", split="test")
モデルをインスタンス化する
model = SentenceTransformer("intfloat/e5-small-v2")
def generate_embeddings(dataset): """入力データセットに対する埋め込みを生成する。 """ グローバルモデル return model.encode([row["text"] for row in dataset])
埋め込みを生成する
embeddings = generate_embeddings(dataset)
単語を連続ベクトル空間のベクトルとして表現することで、意味的な関係を捉えやすくなり、単語間の根本的な意味やつながりを保持することで、様々なAIへの応用が容易になる。
これを `pandas` データフレームにロードすることができる:
python
pandasをpdとしてインポートする
# pandasのデータフレームを作成する
df = pd.DataFrame({"embedding": embeddings.tolist()})
df["text"] = [行["テキスト"] for 行 in データセット].
df["label"] = [行["ラベル"] for 行 in データセット].
これをそのままPhoenixで使うことができる:
シェル pip install -U arize-phoenix
パイソン
px として phoenix をインポートする
# スキーマを作成する
schema = px.Schema(
feature_column_names=["text"]、
actual_label_column_name="label"、
embedding_feature_column_names={
"text_embedding": px.EmbeddingColumnNames(
vector_column_name="embedding"、
#link_to_data_column_name="text"、
),
},
)
ds = px.Dataset(df, schema)
session = px.launch_app(primary=ds)
セッション.url
ここで、まず "Schema "オブジェクトを作成します。このスキーマは、各埋め込みに関連するデータを定義します。これが完了したら、アプリを起動する前に、先ほど作成したデータフレームとそのスキーマをPhoenixに指定します。
URLをブラウザで開くと、次のようなGUIが表示される:
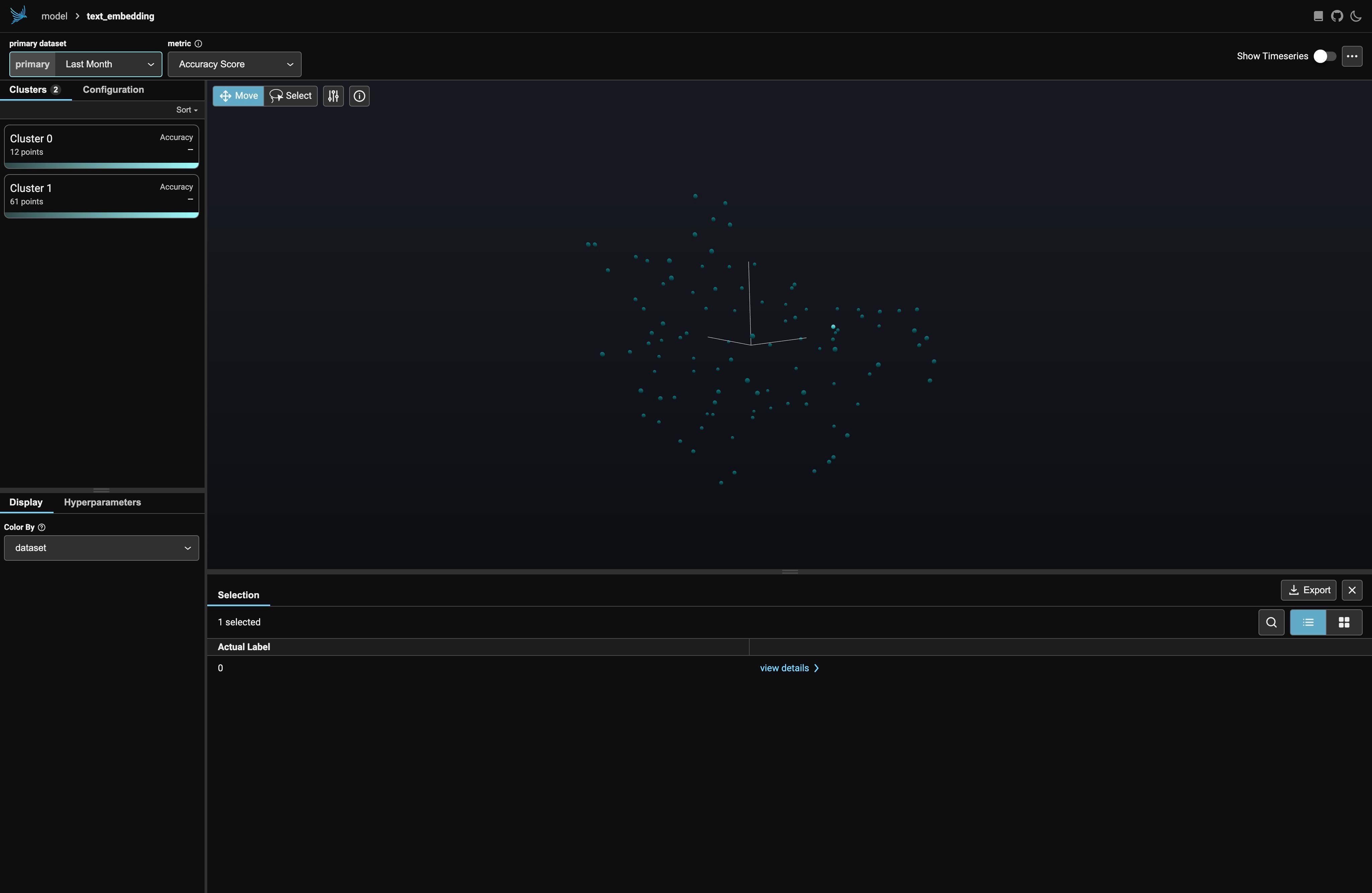
ここでは、IMDBのテストデータセットの最初の100個の要素だけを表示し、さらに映画のレビューではない「謎」の埋め込みも表示しました。その埋め込みは、残りのデータの中では異常値のように見えるかもしれません。実際その通りです:
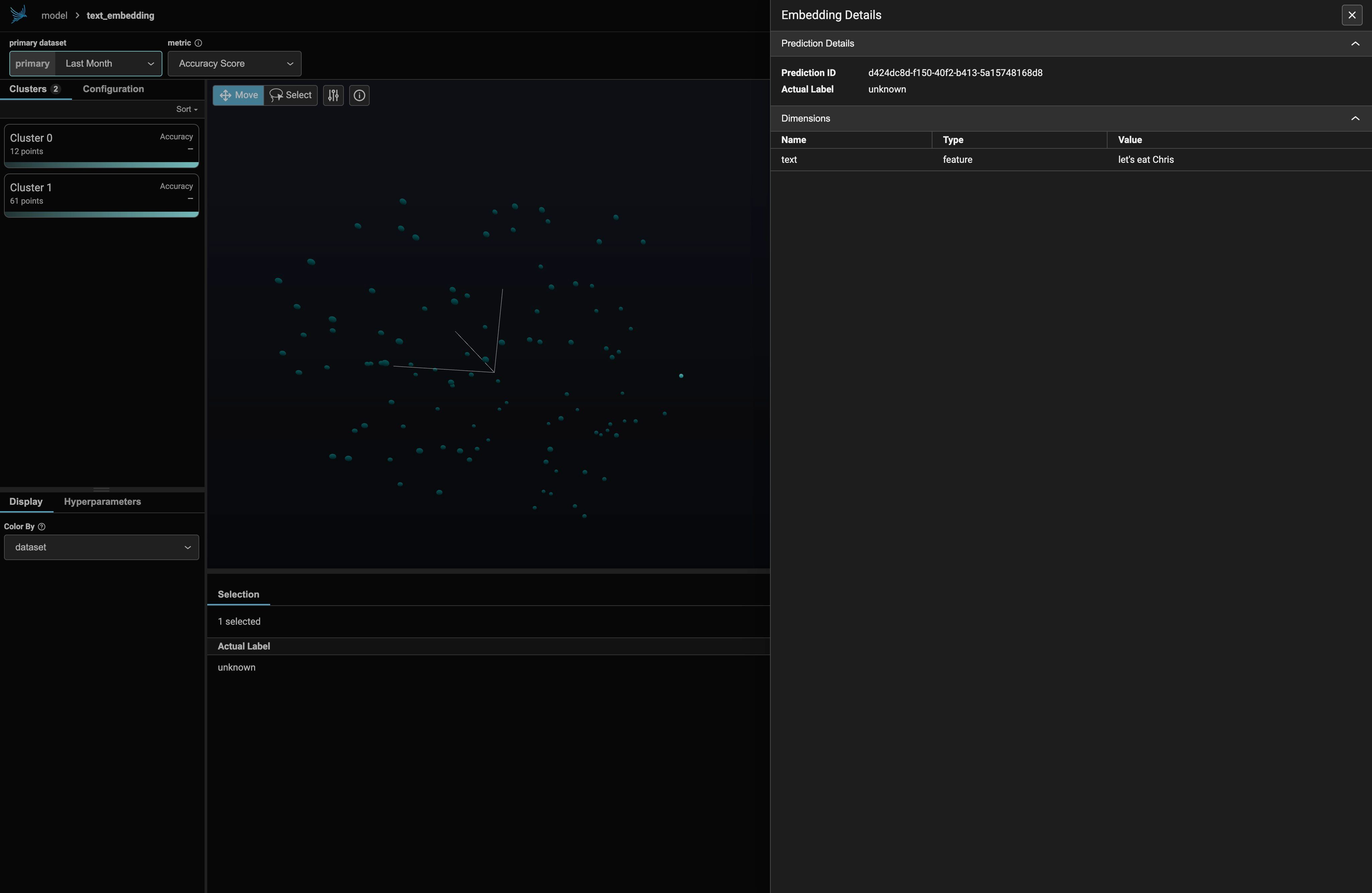
ラガ
Ragas (Retrieval-Augmented Generation ASsessment)は、RAGパイプラインを評価するためのオープンソースライブラリである。変換モデル](https://zilliz.com/glossary/transformer-models)、特にBERTは、双方向からコンテキストを理解する能力で知られており、自然言語処理タスクのパフォーマンス向上につながる。ここでは、これらについて少し詳しく述べるにとどめますが、もっと詳しく知りたい方は、RAGに関する私たちのページ)をチェックしてください。
Massive Text Embedding Benchmark (MTEB)は、テキスト埋め込みモデルの重要な評価基準として機能し、実世界のアプリケーションにおけるパフォーマンスと有効性を検証します。
これらのRAGパイプラインを構築することは、LlamaindexやHaystackのような多くの既存のツールによってサポートされていますが、そのパフォーマンスを測定することは困難です。そこでRagasの出番だ。Ragasは、LLMによって生成されたテキストを評価するツールを提供し、RAGパイプラインがどの程度機能しているかについての洞察を提供します。さらに、RagasはCI/CDプロセスと統合できるように構築されており、定期的なパフォーマンスチェックを行うことで、成果の品質を維持・向上させることができます。
ragasを使って、エンベッディングモデルのパフォーマンスを評価する方法を見てみましょう。別のデータセットを使う必要がありますが、その前にOpenAIのキーを追加して、Ragasが特定のメトリクスに使えるようにしましょう:
python import os os.environ["OPENAI_API_KEY"] = "your-openai-key"
シェル
pip install ragas
python from ragas.metrics import context_recall, context_precision
ここから、埋め込みモデルの品質に関連するメトリクスをインポートする。Huggingfaceデータセットのamnesty_qaデータセットはRagasのために作られたものです。LLMに与えられた質問、真実の回答、LLMからの回答、そして私たちの[埋め込みモデルとベクトル](https://zilliz.com/glossary/vector-embeddings)データベースを使用して取得された関連するコンテキストです。
パイソン
amnesty_qa = load_dataset("explodinggradients/amnesty_qa", "english_v2")
amnesty_qa
DatasetDict({
eval:Dataset({
features:['question', 'ground_truth', 'answer', 'contexts']、
num_rows: 20
})
})
python from ragas import evaluate
result = evaluate( amnesty_qa["eval"]、 メトリクス=[ context_precision、 context_recall、 ], ) 結果
すべてのデータセットのベクトルをベクトルデータベースに格納し、いくつかのサンプル問題を作成し、[以前のブログ](https://zilliz.com/blog/openai-rag-vs-customized-rag-which-one-is-better)で説明したのと同じ挿入と検索のプロセスを実行することで、IMDbデータセットについても同じことができます。
## まとめ
この投稿では、埋め込みモデル、特にオープンソースの埋め込みモデルとe5 large v2を評価するためのハイレベルな戦略について見てきました。単語の埋め込みは、言語モデルを強化し、意味情報の表現を改善するために単語間の統計的関係を利用する、自然言語処理における重要なコンポーネントです。適切なテキスト埋め込みモデルを選択することは、それなりに戦略的な決定です - 各モデルがどのようなデータで、どのようにトレーニングされたかを理解する必要があります。様々なモデルが、品質と適切性という点で異なる出力をもたらすため、特定のランク内で適切な結果を提供する一貫性を達成することが不可欠です。埋め込みを可視化するツール([arise-phoenix](https://zilliz.com/partners/arize-ai)など)や検索システム([ragas]など)を使用することに加えて、解決しようとしている根本的なタスクの要件を注意深く検討することで、埋め込みも最適化することができます。 Frank Liu
Frank LiuFrank Liu is the Director of Operations & ML Architect at Zilliz, where he serves as a maintainer for the Towhee open-source project. Prior to Zilliz, Frank co-founded Orion Innovations, an ML-powered indoor positioning startup based in Shanghai and worked as an ML engineer at Yahoo in San Francisco. In his free time, Frank enjoys playing chess, swimming, and powerlifting. Frank holds MS and BS degrees in Electrical Engineering from Stanford University.
読み続けて

BERTopicの探求:ニューラル・トピック・モデリングの新時代
BERTopicは、トピックの記述に重要な単語を残しながら、トピックを容易に解釈できるようにする新しいトピックモデリング手法である。

データ分析における時系列の埋め込み
時系列データを予測タスクに適したエンベッディングに変換するための一般的な概念や前処理方法など、時系列データについて学ぶ。

BERT(Bidirectional Encoder Representations from Transformers)とは?
BERT(Bidirectional Encoder Representations from Transformers)とは何か、また、その驚くべき性能を実現するために、事前学習と微調整をどのように行っているのかをご紹介します。