BERTopicの探求:ニューラル・トピック・モデリングの新時代
BERTopicは、トピックの記述に重要な単語を残しながら、トピックを容易に解釈できるようにする新しいトピックモデリング手法である。
シリーズ全体を読む
- 自然言語処理の基礎:トークン、Nグラム、Bag-of-Wordsモデル
- 言語モデルのためのニューラルネットワークとエンベッディング入門
- 疎な埋め込みと密な埋め込み
- 長文のためのセンテンス・トランスフォーマー
- 独自のテキスト埋め込みモデルをトレーニングする
- 埋め込みモデルの評価
- クラス活性化マッピング(CAM):ディープラーニングモデルにおけるより良い解釈可能性
- CLIP物体検出:AIビジョンと言語理解の融合
- SPLADEを発見:スパースデータ処理に革命を起こす
- BERTopicの探求:ニューラル・トピック・モデリングの新時代
- データの合理化次元を減らす効果的な戦略
- All-Mpnet-Base-V2:AIによる文埋め込み機能の強化
- データ分析における時系列の埋め込み
- 学習型スパース検索による情報検索の強化
- BERT(Bidirectional Encoder Representations from Transformers)とは?
- ミクスチャー・オブ・エキスパート(MoE)とは?
膨大なデジタル情報の海を航海する私たちにとって、非構造化テキストデータから意味のある洞察を抽出するツールの必要性は、かつてないほど高まっています。BERTopic は、トピックを生成し、大規模なテキストコーパスのテーマとパターンを前例のない精度と深さで発見するためのニューラルネットワークベースの技術を採用し、この変革の時代の最前線に立っています。
このブログでは、BERTopic のトピック・モデリング技術の複雑さについて、トランスフォーマ・モデルへの依存から、クラスタリングと次元削減への革新的なアプローチまでを紹介します。
BERTopic に入る前に、トピック・モデリングについて学ぶ必要があります。
トピックモデリングは、ドキュメントのコレクション内の潜在的なテーマや「トピック」を発掘するための手法です。文書内のテキストを調査し、トピックの存在を示すパターンや関係を検出する。例えば、人工知能に焦点を当てた文書には、パン作りに焦点を当てた文書とは異なり、「大規模言語モデル」や「ChatGPT」といった用語が含まれる可能性が高い。
トピックモデリングは1990年以来存在し、潜在意味解析(LSA)、潜在ディリクレ割り当て(LDA)、非負行列因数分解(NMF)などの有名な手法がある。しかし、これらの従来の手法は、単語間の意味的関係を提示しないか、与えられた文書群に対して最も代表的なトピックを抽出するのに苦労している。
BERTopicは、トピックモデリングのプロセスを単純化する新しいトピックモデリング手法である。様々な埋め込み技術とクラスベースのTF-IDF(c-TF-IDF)を用いて密なクラスタを作成し、トピックの記述に重要な単語を残したまま、解釈しやすいトピックを作成することができる。様々な密度のクラスタ内の潜在的なトピックを分析し、最も関連性の高いキーワードを持つトピックを抽出することができる。BERTopic は、既存の文書埋め込みベースのトピックモデリング手法を拡張したものであるが、柔軟性と頑健性により、既存のソリューションとは一線を画している。
BERTopicは、4つのステップでトピックモデリングにアプローチします:
文書埋め込み:** BERT(Bidirectional Encoder Representations from Transformers)のような事前に訓練されたtransformer言語モデルを使用して、文書を埋め込みに変換する。
次元削減**:埋め込みを低次元空間に圧縮する。
クラスタリング:**これらの埋め込みをグループ化し、類似文書を1つのカテゴリに集めます。
トピック抽出TF-IDFのクラスベースのバリエーションを使用してトピック名を抽出します。
BERTopic は、入力文書を埋め込みと呼ばれる数値表現に変換することから始めます。BERTopic では、テキストの意味的な本質を捉えることができる最先端の埋め込みモデルを選択することができます。オリジナルのBERTopic論文 Sentence BERT (SBERT)は、様々な文埋め込みタスクにおいてそのロバストな性能から、埋め込みモデルとして採用されました。このモデル、特に全MiniLM-L6-v2モデルは、HuggingFace Hubを通じてアクセス可能である。あるいは、text-embedding-ada-002、text-embedding-small、またはtext-embedding-largeのようなOpenAIの専有モデルは、埋め込みを生成するための他のオプションを表していますが、これらは通常サブスクリプションベースです。
エンベッディングは高次元なので、次のステップのクラスタリングが遅くなるかもしれません。さらに、次元削減は、データをクラスタ化できるかどうかを評価するときに、データを視覚化するのに役立ちます。そのため、埋め込みデータを構築した後、BERTopic はそれらを低次元空間に圧縮します。
このステップで、埋め込み文書ベクトルは、より小さな埋め込み空間に投影され、クラスタリングアルゴリズムが首尾一貫したクラスタを作成できるようになります。次元削減には、主成分分析(PCA)やt-SNE(t-t-distributed stochastic neighbor embeddings)のような多くのソリューションがある。それでも、この論文の著者は、UMAP(Uniform Manifold Approximation and Projection)の使用を推奨している。UMAPは、行列を低次元に射影しながら、局所的・大域的な情報を維持するからだ。
入力埋め込みデータの次元を削減した後、クラスタリングアルゴリズムを適用して文書クラスタを作成することができる。クラスタリング手法が高性能であればあるほど、トピック表現の精度が高まるため、このプロセスは重要である。
密度ベースのクラスタリングアプローチ(DBSCAN)は、様々な密度を持つクラスタを作成できるため、トピックモデリングにより適しており、ここで最も推奨される。BERTopicの論文では、著者は元のDBSCANアルゴリズムの変形である階層密度ベースのクラスタリングアプローチ(HDBSCAN)の使用を推奨している。HDBSCANはDBSCANよりも適している:
事前にトピック数を指定する必要がない。
外れ値を効果的に処理できる。
しかし、完璧なクラスタリングモデルは存在しない。
BERTopic の最後のステップは、各クラスタのトピックを抽出することです。これを行うために、BERTopic は、c-TF-IDF とも呼ばれるクラスベース TF-IDF と呼ばれる TF-IDF の修正バージョンを使用します。
TF-IDF は、Term Frequency, Inverse Document Frequency の略で、文書に対する単語の関連性を定量化するために使用されるアルゴリズムです。クラスベースのTF-IDFでは、クラスタ内のすべての文書が連結され、1つの文書として表現される。文書に対する単語の関連性を特定する代わりに、cTF-IDFはクラスタに対する単語の関連性を反映する。
BERTopic アプローチでは、上記の 4 つの主要なステップに加え、トークン化や、ユーザー固有の要件に基 づく表現の微調整といったオプションのステップも含まれる。
BERTopicライブラリの概要](https://assets.zilliz.com/BER_Topic_overview_aac6c94672.png)
BERTopic ライブラリの概要; 画像ソース
BERTopicとは?
BERTopic は、変換モデルとクラスベースの TF-IDF(c-TF-IDF)を活用して密なクラスターを作成し、トピックの記述に重要な単語を保持しながら、解釈しやすいトピックを可能にする最先端のトピックモデリング手法です。この革新的なアプローチにより、トピック モデリング プロセスが簡素化され、この分野の経験が浅い人でも利用できるようになります。BERTopic は、高レベルのインターフェースとデフォルト設定により、わずか数行のコードで強力なモデルを構築することができます。さらに、幅広いトピック・モデリング技法をサポートしているため、学術研究からビジネス分析まで、さまざまな用途に使用できる汎用性の高いツールとなっています。
BERTopic の仕組み
BERTopic は、主に 3 つのステップを組み合わせて動作します:BERT 埋め込み、c-TF-IDF、およびトピックモデリングです。最初に、BERT エンベッディングを使用して、一連のドキュメントを、テキストの意味的本質を捉える数値表現に変換する。次に、c-TF-IDF を適用して、トピックごとに最も重要な単語を抽出し、単一のカテゴリ内のすべての文書を統一文書として扱う。最後に、BERTopic は、トピックモデリングを採用して、トピックとそれに対応する確率を生成する。この包括的なプロセスにより、BERTopic は、密なクラスタを作成し、解釈しやすいトピック記述を提供することができ、大規模なテキストコーパスの隠れたテーマを発見するための強力なツールとなっている。
BERTopic モデルの主な機能
BERTopic モデルには、トピックモデリングのための強力なツールとなるいくつかの重要な特徴があります:
モジュール性**:BERTopic のモジュール設計により、ユーザーは、独自のトピックモデルを構築し、カスタマイズしたモデルの上 で、いくつかのトピックモデリング技法を試すことができます。この柔軟性により、ユーザーはモデルを特定のニーズや好みに合わせて調整することができます。
トピック表現の微調整**:ユーザーは、KeyBERTInspired、ChatGPT、またはOpenAIの他のモデルのような様々なテクニックを使用して、トピック表現を微調整することができます。この機能により、生成されるトピックは関連性が高く、正確なものとなります。
多言語サポート**:BERTopic は、多言語トピックモデリングをサポートしており、ユーザーは 50 以上の言語に対応するモデルを選択できます。この幅広い言語サポートにより、BERTopic はグローバルなアプリケーションに適しています。
視覚化**:BERTopic は、ユーザーが結果を理解し、解釈するのに役立つさまざまな可視化ツールを提供しています。これらには、トピックの視覚化、ドキュメントの視覚化、およびトピック階層の視覚化が含まれ、すべてモデル化されたトピックに関する貴重な洞察を提供します。
BERTopic の実用的な使用例と応用例
BERTopic は、Meta 社、Microsoft 社、CISCO 社、NVIDIA 社、Amazon 社など、フォーチュン 500 のトップ企業による利用を含め、近年、さまざまな分野や業種で多くの応用が見られます。開発者や組織は、癌研究や音声知覚研究から従業員調査やソーシャルメディアコンテンツの分析に至るまで、様々なユースケースやドメインで BERTopic を使用しています。BERTopic は、データ・クラスターを理解する上で興味深い視点を提供し、様々なドメインにおける分析体験を向上させます。
BERTopic の実際のアプリケーションには、以下のようなものがあります:
多国籍通信会社である Telefonica は、ユーザーエクスペリエンス (UX) を向上させ、有用な顧客情報を明らかにするために、顧客レビューのトピックモデリングと分類に BERTopic を採用しました。
米国国土安全保障省](https://www.dhs.gov/) では、BERTopic は、議論された主要なトピックを特定し、感情を評価することで、従業員調査を分析している。
マクマスター大学](https://mcmaster.ca/)では、"Hi "と言っている人の録音を聞いた参加者の説明を分析することで、声の知覚に基 づいて第一印象を分類する研究プロジェクトで BERTopic を使用しています。
Iodine Software](https://iodinesoftware.com/) は、病院から医師が作成した文書を分析するために BERTopic を使用しています。彼らは、テキスト内のテーマを特定し、医療文書の明確な解釈を保証するために、BERTopicを採用しています。
結果の視覚化と解釈
BERTopic の結果を視覚化および解釈することは、トピックモデルを理解するために非常に重要です。BERTopic は、ユーザーがトピック、文書、およびトピック階層の複雑さを把握するのに役立つさまざまな可視化ツールを提供します。主な可視化ツールには、次のようなものがあります:
トピックの視覚化**:これらの可視化は、ユーザーがトピックとそれに対応する重要な単語を理解するのに役立ち、テキスト データに存在するテーマを明確に示します。
ドキュメントの視覚化**:これらのビジュアライゼーションにより、ユーザは、文書が異なるトピックにどのように分散している かを確認でき、文書とトピックの関係についての洞察を得ることができます。
トピック階層の視覚化**:これらのビジュアライゼーションは、トピックの階層構造を説明し、異なるトピックとサブトピックの 関係を示します。これにより、ユーザはデータ内の広範なコンテキストやつながりを理解することができます。
BERTopic の有効性の評価
BERTopic の有効性を評価することは、BERTopic のパフォーマンスを理解し、改善すべき領域を特定するために 不可欠である。BERTopic を評価するために、以下を含むいくつかの指標が使用される:
トピックの一貫性**:この指標は、各トピック内の単語の類似性と重要性を測定することによって、トピックの一貫性を評価する。トピックの一貫性が高いことは、トピックに意味があり、十分に定義されていることを示します。
トピックの階層**:この基準では、トピックの階層構造を評価し、親トピックと子トピック間の関係と一貫性を調べます。構造化されたトピック階層は、モデルの解釈可能性を高めます。
ドキュメントとトピックの整合性**:この指標は、文書と割り当てられたトピックの間の整合を測定し、文書とトピックのペアの類似性と首尾一貫性を評価する。文書-トピックのアライメントが強いと、トピックが文書の内容を正確に表していることが保証される。
これらのメトリックを評価することで、ユーザーは、BERTopic の有効性を洞察し、最適なパフォーマンスを得るためにモデルを微調整するために必要な調整を行うことができます。
トピックモデリングの課題と考察
トピックモデリングのために BERTopic を使用することは、適切な埋め込みモデルの選択、多言語サ ポート、オフライン実行、遅い推論などの課題をもたらす可能性がある。BERTopic を使用してトピックを生成する際の一般的な問題とその解決策について、より詳細な概要を説明します:
メモリ:BERTopic は、大きなデータセットのトピックをモデリングするときに、メモリ不足の問題に遭遇する傾向があります。その主な原因は、通常 UMAP であり、これは低いメモリフットプリントで実行できる。第二に、トピック抽出段階でかなりの文書トピック分布の計算をスキップし、確率行列を関連性の高いトップKトピックに限定することができる。第三に、潜在的なトピックとみなされる単語の最小頻度を大きな数に設定することで、TF-IDF行列のサイズを小さくすることができる。
速度:BERTopic は、埋め込みフェーズがあるため、より多くの文書コレクションで低速に動作します。アルゴリズムを高速化するには、事前に非同期で並列処理することができます。また、GPUにアクセスできる場合はGPUを使用するか、Google ColabやKaggleの無料ティアを利用することも解決策の1つです。
トピック数:BERTopicは通常多くのトピックを生成するが、これは役に立たない。トピック数を減らす簡単な方法は、最小トピックサイズを設定することである。別のシナリオでは、生成される文書数が非常に少ない場合、データセット内の文書数とその多様性を増やすか、最小トピックサイズを小さくすることができる。
BERTopic では、モデリングステップのコンポーネントを入れ替えたり削除したりすることで、カスタマイズされたトピックモデルを作成することができる。
BERTopicは、GitHubでホストされているオープンソースプロジェクトである。このパッケージは、5,000以上のスターを持ち、フレームワークを始めるための広範なドキュメントを提供している。BERTopicは、各ステップで異なるアルゴリズムを使用するモジュラーアプローチを提供し、独自のカスタマイズされたトピックモデルを構築することができます。
BERTopicでは、基本的に独自のトピックモデルを構築することができる。画像ソース
各段階はビルディングブロックであり、ライブラリは各段階に複数のオプションを提供している。例えば、文書埋め込みに spaCy、次元削減に PCA、クラスタリング手法にK-means for clustering、文書結合に CountVectorizer、最後にトピック抽出に c-TF-IDF を選択すると、エンドツーエンドでカスタマイズされた BERTopic モデルができあがります。
BERTopicを使い始めるには、まずこのパッケージをインストールしてください:
pip install bertopic
pip install bertopic[可視化]をインストールします。
次に、トピックをモデル化したいデータセットをセットアップする。私は20newsgroupデータセットを使っている。
# データを読み込む
from sklearn.datasets import fetch_20newsgroups
docs2 = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))['data'].
docs2
BERTopic モデルを初期化し、トピックを見つける。
# BERTopic モデルの初期化
model = BERTopic(verbose=True,nr_topics=10)
# 潜在トピックを見つけよう
topics, probs = model.fit_transform(docs2)
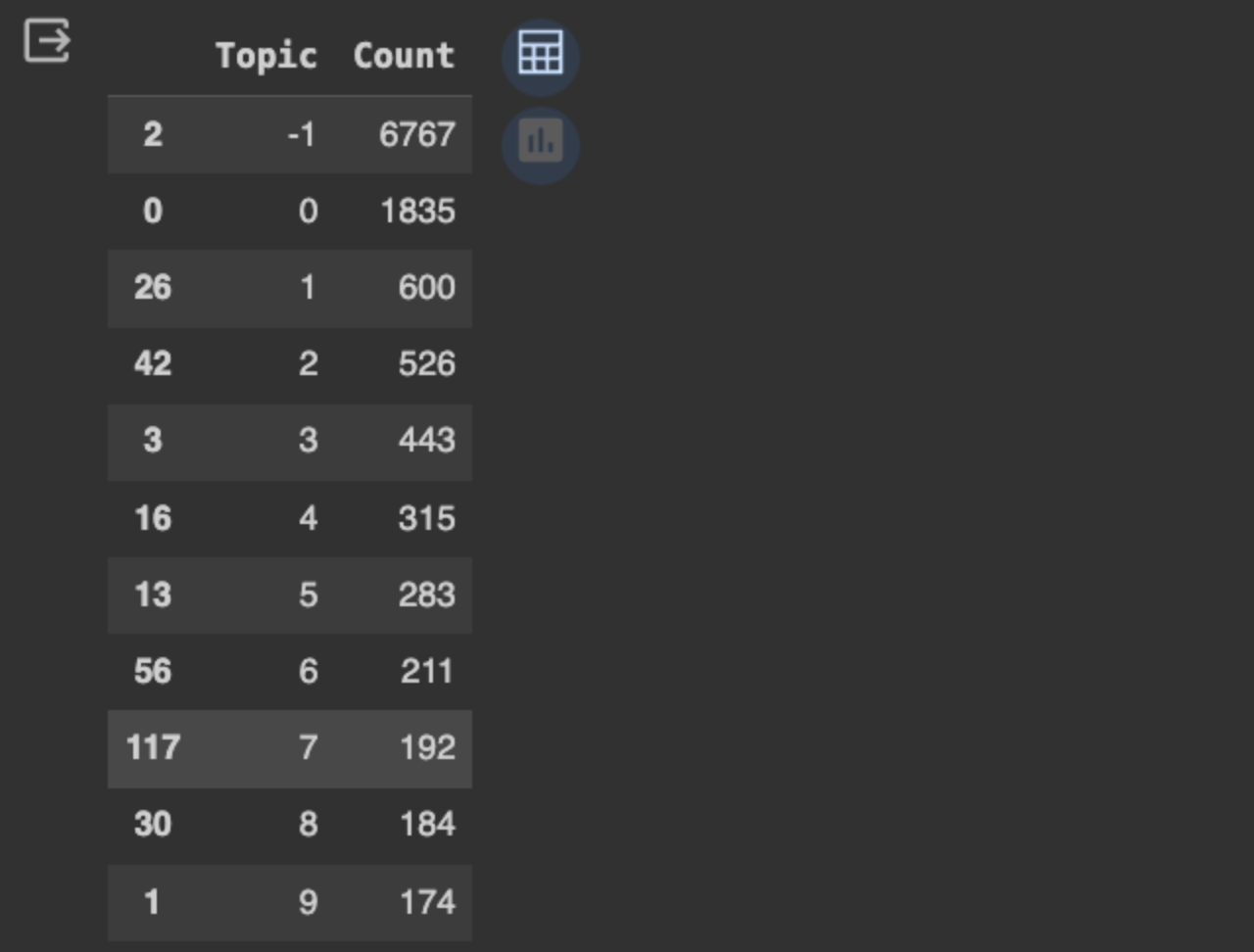
抽出された上位トピックを表示し、1つのトピックを精査して上位の単語を確認し、トピックとその関連文書との関係を理解する。
# トップトピックの選択
model.get=topic+freq().head(11)
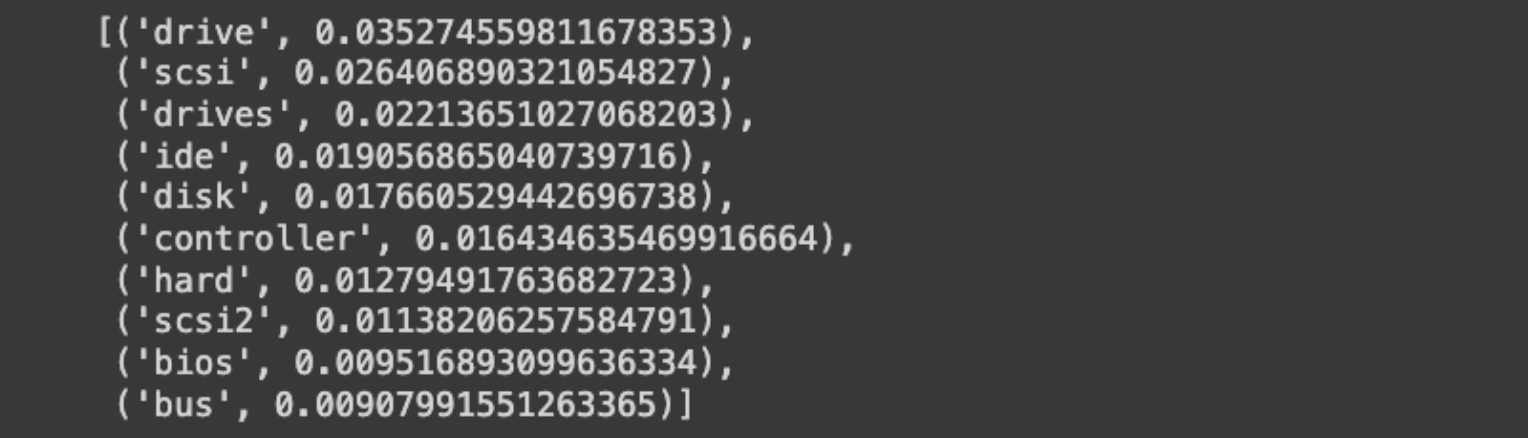
# トピックのトップワードを見てみよう
model/get_topic(3)
BERTopic でサポートされている多くの視覚化を使用して、トピックを視覚化します。クラスタの密度分布を可視化してみましょう:
# トピッククラスターを可視化する
model.visualize_topics()

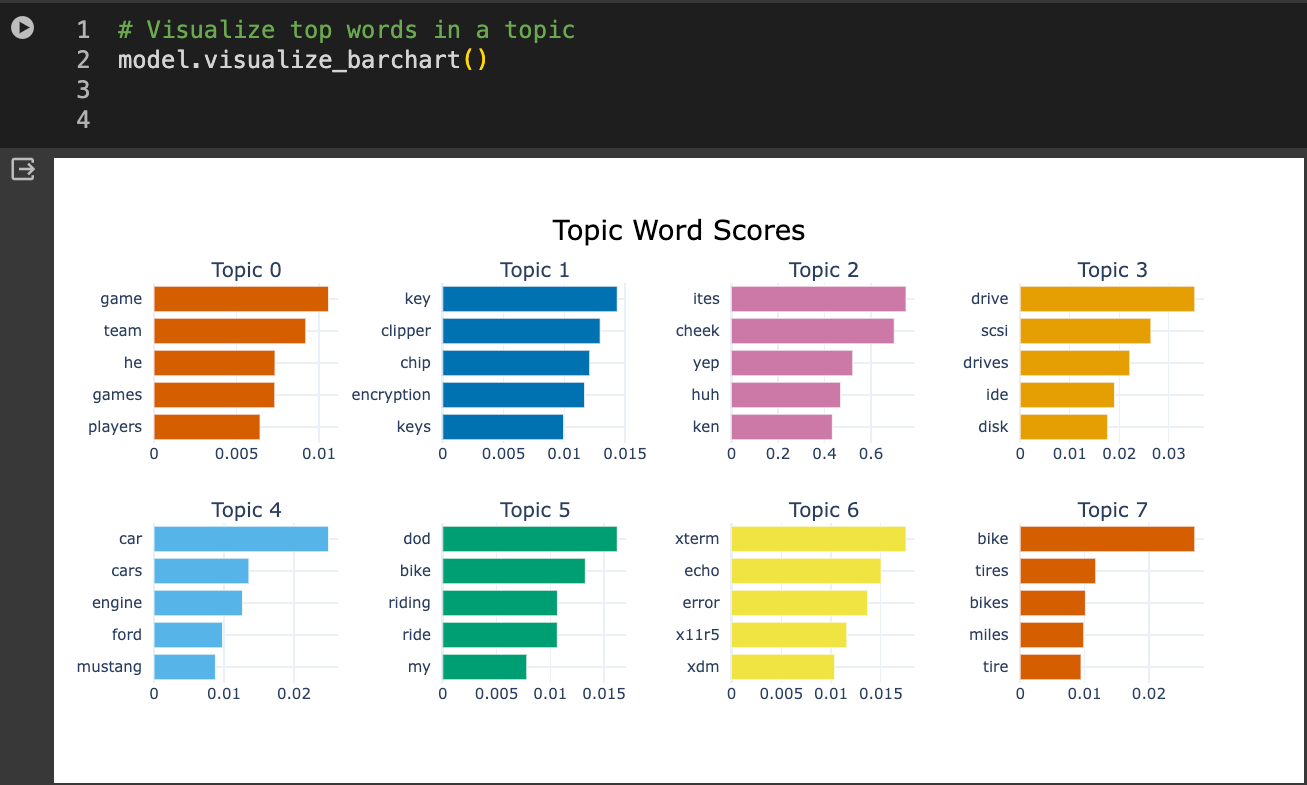
最後に、クラスターやトピック内の上位語を見ることもできる:
# トピック内のトップワードを視覚化する
model.visualize_barchart()
より洗練されたトピックモデリングソリューションを、よりコントロールしやすく構築したい場合は、以下のリソースをチェックしてほしい:
BERTopic Modeling: as you never seen it](https://medium.com/data-reply-it-datatech/bertopic-topic-modeling-as-you-have-never-seen-it-before-abb48bbab2b2)
公式 BERTopic ドキュメント](https://maartengr.github.io/BERTopic/index.html#quick-start)
BERTopic は、大規模なドキュメントのコレクションを理解するのに役立つ、すぐに使えるトピックモデリングを可能にする素晴らしいフレームワークです。BERTopic には、次のような多くの利点があります:
データの前処理が不要。
Gensim、Flair、Spacy、そして現在ではOpenAIやHuggingFaceといった最先端のLLMまで、さまざまな文書埋め込みを試すことができる柔軟性。
モデル化されたトピックを検査・分析するための素晴らしい可視化。
BERTopic は、癌や音声知覚の学術的研究から、従業員のフィードバックやソーシャルメディアモニタリン グのような企業環境における実用的な分析まで、幅広い応用が可能であることから、その重要性と潜在的な影響力は、様々な 分野にわたっていることがわかります。Meta、Microsoft、Amazon などの企業は、すでに BERTopic の力を活用し、業務や戦略を改善しています。
膨大な量のテキストデータを生成し、それに依存し続ける中で、BERTopic のようなツールは、データ分析と知識発見のためのツールキットに不可欠なものとなっています。BERTopic は、高度なトピックモデリングのパワーをより多くの人々に普及させ、この分野の新たな標準を設定し、データ駆動型産業のダイナミックな需要に対応するための継続的な進化と強化を約束します。
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS