




クラス活性化マッピング(CAM):ディープラーニングモデルにおけるより良い解釈可能性
クラス活性化マッピング(CAM)は、コンピュータビジョンタスクのための畳み込みニューラルネットワーク(CNN)の意思決定を視覚化し理解するために使用される。
シリーズ全体を読む
- Natural Language Processing Fundamentals: Tokens, N-Grams, and Bag-of-Words Models
- Primer on Neural Networks and Embeddings for Language Models
- Sparse and Dense Embeddings
- Sentence Transformers for Long-Form Text
- Training Your Own Text Embedding Model
- Evaluating Your Embedding Model
- Class Activation Mapping (CAM): Better Interpretability in Deep Learning Models
- CLIP Object Detection: Merging AI Vision with Language Understanding
- Discover SPLADE: Revolutionizing Sparse Data Processing
- Exploring BERTopic: A New Era of Neural Topic Modeling
- Streamlining Data: Effective Strategies for Reducing Dimensionality
- All-Mpnet-Base-V2: Enhancing Sentence Embedding with AI
- Time Series Embedding in Data Analysis
- Enhancing Information Retrieval with Learned Sparse Retrieval
- What is BERT (Bidirectional Encoder Representations from Transformers)?
- What is Mixture of Experts (MoE)?
クラス活性化マッピング法の重要性とは?
ディープラーニングモデルは、複雑なタスクにおいて従来の機械学習手法を凌駕することが多い。しかし、ディープラーニングモデルには解釈可能性という重大な制約がある。
ディープラーニングモデルの予測は、解釈が難しいことで有名です。この透明性の欠如は、モデルの決定の背後にある理由を理解することを困難にし、その結果、信頼性を低下させる。研究者たちはこの問題に対処するために、コンピュータ・ビジョン・タスクのための畳み込みニューラルネットワーク(CNNs)の意思決定プロセスを可視化し理解するための強力な手法であるクラス活性化マッピング(Class Activation Mapping: CAM)を含む、いくつかの手法を提案している。
この記事では、CNNにおけるクラス活性化マッピングの重要性を探り、CAMの背後にある理論を学び、コードで実装する方法を学びます。それでは、早速始めましょう!
なぜクラス活性化マッピング(CAM)が必要なのか?
畳み込みニューラルネットワーク(CNN)は、画像分類、画像セグメンテーション、物体検出、物体位置特定、姿勢推定など、様々なコンピュータビジョンタスクを解決するために一般的に応用されている。
畳み込みニューラルネットワークモデルが画像中のアイテムを検出する方法 ](https://assets.zilliz.com/CNN_a9f471bd85.png)
しかし、CNNを含む深層学習ネットワークは、ブラックボックスとして認識されることが多い。入力データを与えると、学習されたタスクに基づいて予測を行う。CNNは通常、複雑な相互作用を持つ複数の層で構成されているため、その意思決定プロセスを理解することは非常に困難である。
一方、すべての機械学習モデルにおいて、その信頼性を確保するために解釈可能性は非常に重要である。CNNの文脈では、予測を行う際にモデルが画像の正しい領域に焦点を当てているかどうかを検証することが重要です。
自律走行システムを開発するとしよう。道路上の物体を識別するために画像分類モデルを構築するとする。そして、車両はモデルによって予測された物体に基づいて行動する。このような状況では、予測時にモデルが画像の関連領域を正しく識別できるようにすることが重要です。
クラス・アクティベーション・マッピングは、この問題に対処するために考案された初期の手法である。これにより、モデルの予測に影響を与える画像の領域を調査することができる。
ヒートマップ:クラス活性化マップは、シマウマと車の周りの領域が、他の画像部分よりも重要であることを強調する](https://assets.zilliz.com/zebra_vs_car_dab2e14642.png)
上のヒートマップに示すように、クラス活性化マップを実装することで、ゼブラと車の周りの領域が他の画像部分よりも重要であることが強調されます。ヒートマップの強度は、モデルの予測における領域の重要度に対応します。したがって、この方法はモデルの透明性と信頼性を向上させます。
クラス活性化マッピング(CAM)とは?
クラス・アクティベーション・マッピングがどのように機能するかに入る前に、CNNベースのモデルの典型的なアーキテクチャーを復習しておこう。CNNベースのモデルは、下図のように複数の畳み込み層で構成されている。入力画像が各畳み込み層を通過するにつれて、その次元は減少し、特徴の数は増加する。
CNNモデルの仕組み](https://assets.zilliz.com/class_activation_map_bddbc380cf.png)
最後の畳み込み層を通過した後、各特徴マップ内の値はグローバル平均プーリング層(GAP)を使って集約される。GAP層に続いて、各特徴マップは1つのスカラー値で表現される。次に、これらの値は最後のフィードフォワード層に供給され、モデルの予測を生成する。
最後の畳み込み層の仕組み ](https://assets.zilliz.com/camp_diagram_e7f0bdf239.png)
では、このプロセスからどのようにしてクラス活性化マップを導き出すのだろうか?
CNNベースのモデルの予測は最後のフィードフォワード層で生成される。この層の中で、各特徴マップの値は特定のクラスに対してその重みを掛け合わされ、そして合計され、そのクラスの最終的な値が得られる。各特徴の重みの背後にある直感は次のとおりである:
重み > 0 の場合、対応する特徴は、入力画像が特定のクラスに属する可能性を高めます。
重み = 0 の場合、対応する特徴量に影響はありません。
重み < 0 の場合、対応する特徴量は、入力画像が特定のクラスに属する可能性を低下させます。
その結果、モデルの予測は、特徴量の重み付け合計が最も大きいクラスに対応します。
フィードフォワード層の仕組み】(https://assets.zilliz.com/diagram_2_c5164acbd9.png)
予測されるクラスに対する各特徴マップの重みを得ることができれば、畳み込みニューラルネットワークモデルの予測における重要性を評価することができます!
予測されたクラスに対する各特徴マップの重みを得たら、次のステップは簡単です。まず、最後の畳み込み層(グローバル平均プーリング層の前)から特徴マップをフェッチする。次に、各特徴マップに対応する重みを掛ける。最後に、これらの乗算結果を合計して、最終畳み込み層の特徴マップの次元と一致する1つの行列を得ます。
上の図を使って説明しよう。我々のモデルが、入力画像がクラスAに属すると予測したとする。我々の目標は、この予測に影響を与えた画像の領域を特定することである。
CAMを計算する:
1.クラスAに対する各特徴マップの重みを取得し、(w1, クラスA)、(w2, クラスA)、(w3, クラスA)、(w4, クラスA)とする。
2.また、最後の畳み込み層から特徴マップを得る必要がある(上の図では、これは4×4×4の次元の特徴に対応する)。
最後に、各特徴マップの重み付き和を計算し、下図のような行列を得ます:
各特徴マップの重み付き和の計算](https://assets.zilliz.com/diagram_3_2cee36d7e5.png)
行列の中で高い値を持つ領域は、モデルの予測にとって重要である。最後のステップでは、この行列を入力画像の元の次元にアップスケールします。視覚化では、前節で示したように、高い値を持つ領域がより目立つようになる。
クラス活性化マッピングの実装
このセクションでは、PyTorchを使ってゼロからCAMを実装します。つまり、CAMを生成するプロセス全体を抽象化するような高レベルのライブラリには頼りません。もちろん、代わりにTensorFlowを使うこともできる。しかし、TensorFlowを使いたい場合は、以下のチュートリアルでTensorFlowのAPIに従っていくつかの点を調整する必要があります。
まず、実装に必要なすべてのライブラリをインポートしましょう。
np として numpy をインポートします.
import cv2
from torchvision import models, transforms
from torch.nn import functional as F
numpyライブラリは、最終的なCAMを得るために特徴マップの重み付き和を計算するために使用される。一方、OpenCVは画像の前処理に使用され、torchvisionはコンピュータビジョンタスクのための一般的な事前学習済みモデルにアクセスできるライブラリです。
今回の実装で使用するモデルはResNet18である。名前が示すように、これは18の畳み込み層で構成され、1,000の異なるクラスを含むImageNetデータベースの100万以上の画像で学習されています。それでは、事前に訓練されたモデルをロードしてみよう。
model = models.resnet18(pretrained=True)
model = model.eval()
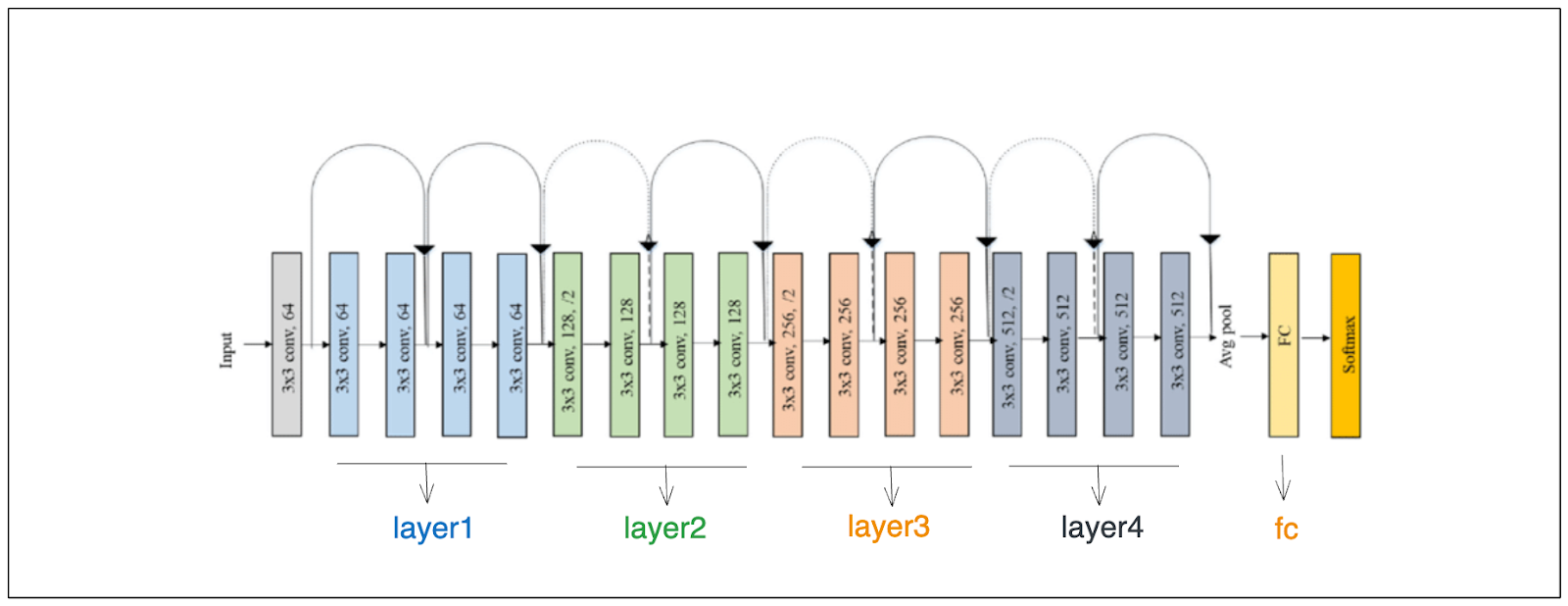 ResNet18の仕組み
ResNet18の仕組み
上の図からわかるように、ResNet18の18の畳み込み層は、GAP層と最後のフィードフォワード層の前に4つのブロックに分かれている。前節で既にお分かりのように、CAMを計算するためには、GAP層の前に最終畳み込み層からの特徴マップを格納する必要がある。
保存したい特徴マップは、基本的に「layer4」と名付けられた4番目のブロックの出力である。layer4'の出力を保存する一つの方法は、PyTorchのregister_forward_hookメソッドを使うことです。このメソッドはフォワードパスの間に特定のレイヤーからの中間結果を保存します。
# 最後の畳み込み層で特徴マップを格納する関数を定義する
activation = {} # アクティベーション
def getActivation(name):
# フックのシグネチャ
def hook(model, input, output):
activation[name] = output.detach()
リターンフック
model.layer4.register_forward_hook(getActivation('final_conv'))
次に、画像のパスを指定して入力画像を読み込みましょう。
# この例では、犬の画像を使用します。
image_path = "path_to_your_image.png" です。
 犬の画像
犬の画像
この例では、シルキーテリア犬の画像を使います。我々の目標は、この画像に対するモデルの予測を見つけ、モデルの予測に影響を与える画像内の領域を特定することである。
注意すべき重要な点は、ResNet18は224 x 224の寸法と、特定の平均値と標準偏差値を持つ画像で事前にトレーニングされていることです。したがって、まず画像のサイズを変更し、次にImageNetデータセットの平均と標準偏差に従って正規化することで、画像を変換する必要があります。
さらに、OpenCVを使って画像を読み込むとき、画像のデフォルト・チャンネルはBGR形式です。したがって、同様にRGBに変換する必要があります。
# データ変換パイプラインを定義する: resize => tensor => normalize
transforms = transforms.Compose(
[transforms.ToPILImage()、
transforms.Resize((224, 224))、
transforms.ToTensor()、
transforms.Normalize()
mean=[0.485, 0.456, 0.406]、
std=[0.229, 0.224, 0.225].
)
]
)
image = cv2.imread(image_path)
orig_image = image.copy()
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB).
height, width, _ = image.shape
次に,ResNet18 モデルを使って,入力画像に対するフォワードパスを行います.最後に、予測されたクラスのインデックスを取得します。
# 画像変換を適用する
image_tensor = transforms(image)
# バッチ次元を追加
image_tensor = image_tensor.unsqueeze(0)
# モデルの前方通過
出力 = model(image_tensor)
# 予測されたクラスのidxを得る
class_idx = F.softmax(outputs).argmax().item()
print(class_idx) # 出力:201
ここにあるImageNetデータのラベルマッピングを参照すると、インデックス201がシルキーテリアに対応していることがわかります。これはモデルの予測が正しいことを意味する。CAMの役割は、モデルがシルキーテリアと予測するために重要な画像の領域を強調することです。
前のセクションで述べたように、CAMを計算するには2つのものを取り出す必要があります:
最後の畳み込み層からの特徴マップ。
最後のフィードフォワード層から学習された各特徴マップの重み。
最終的な畳み込み層から特徴マップを取得するのは簡単で、すでにregister_forward_hookを実装しているからだ。同様に、最後のフィードフォワード層から各特徴の重みを取得するのも簡単だ。ResNet18では'fc'と呼ばれるフィードフォワード層の名前を指定するだけです。
# 最後の畳み込み層で特徴マップを取得する
conv_features = activation['final_conv'] # 最終畳み込み層の特徴マップを取得する。
# 最後のフィードフォワード層で学習した重みを取得する
weight_fc = model.fc.weight.detach().numpy()
さて、いよいよCAMを計算しよう。CAMを求めるには、特徴マップの重み付き和を計算する必要があります。これは基本的に重みと特徴マップの間のドット積です。
その後、CAMを非正規化し、入力画像の次元に合わせてアップサンプルする必要がある。そうすることで、CAMの結果を元画像の上に重ね合わせ、ヒートマップの視覚化を生成することができる。
def calculate_cam(feature_conv, weight_fc, class_idx):
# クラス活性化マップを生成する upsample to 224x224
size_upsample = (224, 224)
bz, nc, h, w = feature_conv.shape
cam = weight_fc[class_idx].dot(feature_conv.reshape((nc, h*w)))
cam = cam.reshape(h, w)
cam = cam - np.min(cam)
cam_img = cam / np.max(cam)
cam_img = np.uint8(255 * cam_img).
output_cam = cv2.resize(cam_img, size_upsample).
return output_cam
# クラス活性化マッピングを生成します.
class_activation_map = calculate_cam(conv_features, weight_fc, class_idx).
最後に、モデルを可視化する関数、つまりCAMと元の入力画像を重ね合わせる関数を以下のメソッドで作成しましょう:
def visualize_cam(class_activation_map, width, height, orig_image):
heatmap = cv2.applyColorMap(cv2.resize(class_activation_map,(width, height)), cv2.COLORMAP_JET).
result = ヒートマップ * 0.3 + orig_image * 0.5
cv2.imshow(result).
cv2.waitKey(0)
# 結果を可視化します.
visualize_cam(class_activation_map, width, height, orig_image).
CAMの結果を視覚化する](https://assets.zilliz.com/car_and_dog_8f4c23c0cb.png)
クラス活性化マッピング(CAM)の改良
クラス活性化マッピングは、特にコンピュータビジョンのタスクにおいて、AIの解釈可能性が急速に発展するきっかけとなった初期の手法である。現在、CAMの精度と柔軟性を向上させるために、GradCAMやGradCAM++など、CAMに基づく多くの手法が提案されている。
すでにご存知のように、クラスアクティベーションマッピングを使用するには、特定のアーキテクチャを持つモデルを使用する必要がある。具体的には、GAP(Global Average Pooling)層を使って、最後の畳み込み層から特徴マップを集約する必要がある。もしモデルが最後にGAPレイヤーを持たない場合、CAMを実装するにはモデルのアーキテクチャを変更する必要がある。
GradCAMはこのアプローチを一般化し、モデル内のGAPレイヤーを不要にすることで、クラス活性化マップを生成するためにどのようなCNNベースのアーキテクチャでも使用できるようにする。
さらに最近、GradCAMの拡張としてGradCAM++と呼ばれる手法が提案された。この方法は、特に1つの画像内で複数のオブジェクトが予測に影響を与えるような場合に、モデルの予測をより視覚的に説明する。
GradCAMやGradCAM++についてもっと知りたい方は、それらの公式研究論文を参照することをお勧めします。
Grad-CAM:Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization](https://arxiv.org/abs/1610.02391)
Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks.
クラス活性化マップのまとめ
この記事では、クラス・アクティベーション・マッピングについて知っておくべきことをすべて説明した。まず、ディープラーニングモデルの予測を解釈することの重要性と、クラス・アクティベーション・マップがこの点でどのように役立つかを説明しました。次に、ヒートマップを生成し、モデルの予測に大きな影響を与える領域を視覚化するCAMの基礎的なプロセスについて学びました。最後に、CAM生成プロセスの包括的な理解を確実にするため、高水準ライブラリに頼らずにゼロからCAMを実装した。
この記事が、クラス・アクティベーション・マッピング、あるいは一般的な説明可能AIを使い始めるのに役立つことを願っている。CAMは、畳み込みニューラルネットワークに基づくモデルの予測を解釈するためのわかりやすい手法であり、説明可能なAIを始めたばかりの方には最適なエントリー・ポイントです。
続きを読む
ヴィジョン・トランスフォーマー(ViT)とは](https://zilliz.com/learn/understanding-vision-transformers-vit)
画像検索のための画像埋め込み ](https://zilliz.com/learn/image-embeddings-for-enhanced-image-search)
ONNXとMilvusを用いた画像検索のためのAIモデルの組み合わせ ](https://zilliz.com/blog/combine-ai-models-for-image-search-using-onnx-and-milvus)
コンピュータビジョンデータをより良く理解するためのベクトル探索の利用](https://zilliz.com/blog/use-vector-search-to-better-understand-computer-vision-data)



