CLIP物体検出:AIビジョンと言語理解の融合
CLIPオブジェクト検出は、CLIPのテキスト画像理解とオブジェクト検出タスクを組み合わせ、CLIPがテキストを使用して画像内のオブジェクトを見つけ、識別することを可能にします。
シリーズ全体を読む
- 自然言語処理の基礎:トークン、Nグラム、Bag-of-Wordsモデル
- 言語モデルのためのニューラルネットワークとエンベッディング入門
- 疎な埋め込みと密な埋め込み
- 長文のためのセンテンス・トランスフォーマー
- 独自のテキスト埋め込みモデルをトレーニングする
- 埋め込みモデルの評価
- クラス活性化マッピング(CAM):ディープラーニングモデルにおけるより良い解釈可能性
- CLIP物体検出:AIビジョンと言語理解の融合
- SPLADEを発見:スパースデータ処理に革命を起こす
- BERTopicの探求:ニューラル・トピック・モデリングの新時代
- データの合理化次元を減らす効果的な戦略
- All-Mpnet-Base-V2:AIによる文埋め込み機能の強化
- データ分析における時系列の埋め込み
- 学習型スパース検索による情報検索の強化
- BERT(Bidirectional Encoder Representations from Transformers)とは?
- ミクスチャー・オブ・エキスパート(MoE)とは?
OpenAIは、コンピュータビジョンと自然言語処理を統合するAIの大きなブレークスルーとして、2021年にContrastive Language-Image Pre-training (CLIP)を開発した(Radford et al., 2021)。これまでは、コンピュータは画像や映像の理解に携わり、人間は言語処理と生成に集中していた。CLIPは、画像データを指定することなく、広範な画像と書かれたオンライン説明のセットを使用して、対応するテキスト説明と画像を関連付けるように設計されています。このモデルは自然言語理解を活用し、テキストによる説明を画像の特徴と整合させることで、文脈を手がかりとしたオブジェクトの正確な識別を可能にする。テキストと画像に基づいた変換器の設計は、単一のembedding空間内に完全に収まり、テキスト記述との関連付けを通して画像の解釈を容易にする。このAI革命によって、機械は言葉や書かれたテキストの中のイメージを理解することができる。
以下の図1に示すように、CLIPはデュアルエンコーダーフレームワークを採用し、それらを共有潜在空間にマッピングすることで画像とテキストの対応を確立する。システム内では2つのエンコーダーが同時に学習される。前者は画像用に開発されたVision Transformerで、後者はテキスト用に設計されたTransformerベースの言語モデルである。
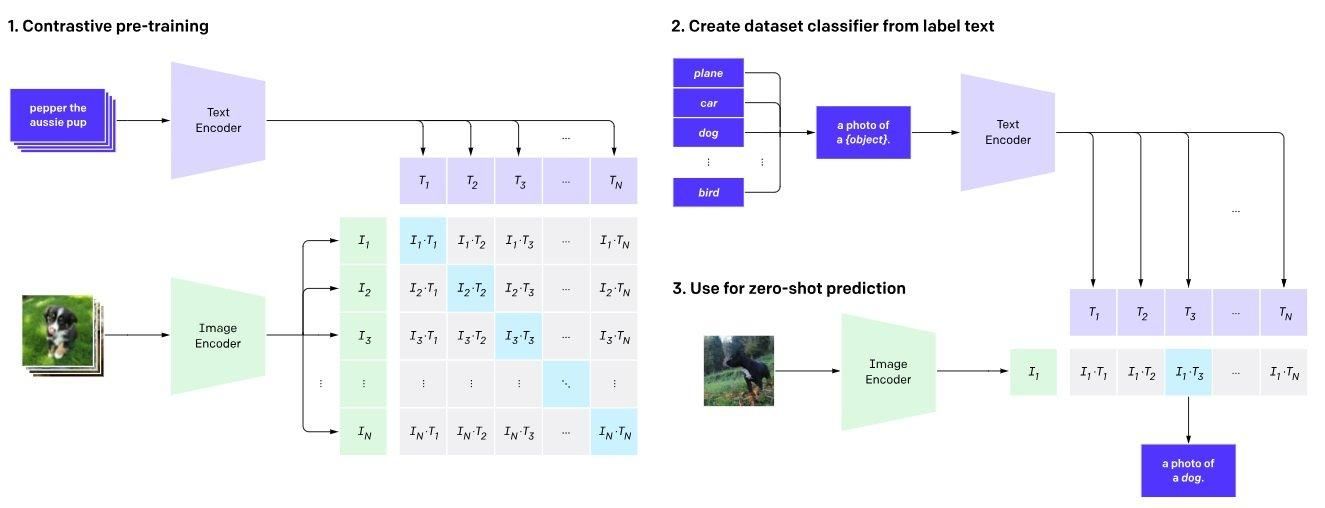
図1.CLIPのアーキテクチャ(Radford et al.)
画像エンコーダー:視覚入力は画像エンコーダーによって詳細に分析される。これは「画像」を入力とし、高次元のベクトル表現を生成する。これを行う一般的な方法は、ResNetのような畳み込みニューラルネットワーク(CNN)アーキテクチャを用いて画像から特徴を抽出することである。
テキスト・エンコーダ: テキスト・エンコーダは、付随するテキスト記述の意味的な意味をエンコードする。したがって、「テキストキャプション/ラベル」入力は、対応する高次元ベクトル表現に変換される。****TransformerまたはBERT](https://zilliz.com/learn/what-is-bert)のような変換器ベースの 構造を頻繁に採用して、テキスト列を分析する。
**共有ベクトル空間2つのエンコーダは、同じベクトル空間内の埋め込みを生成する。CLIPは、テキスト表現と画像表現の比較を容易にし、それらの基本的なつながりに関する知識を得るために、共通の埋め込み空間を利用する。
ステップ1:対照的事前学習CLIPは、何百万もの画像とテキストデータのペアを用いて学習される。モデルは事前学習中に、本物の一致と非一致のペアにさらされ、共有された潜在空間の埋め込みを生成する。
ステップ2:データセットの分類子は、各画像に対して複数のテキスト説明を持つラベルテキストに基づいて生成される。対比的損失関数は、不正確な画像とテキストのペアリングに対してモデルにペナルティを与えるが、潜在空間における正確なマッチングには報酬を与える。これにより、類似した視覚情報とテキスト情報の正確な捕捉が促進される。
ステップ3:学習されたテキスト・エンコーダはゼロショット予測として使用され、新鮮な画像を用いて事前の学習なしに予測を提供する。CLIPは画像とテキスト記述の間の余弦類似度を計算し、正しいペアリング間の類似度を高めるためにエンコーダ設定を調整する。意味的に関連する画像と単語を近くに配置するマルチモーダル埋め込み空間を学習し、ロジット値が最も高いクラスを選択することで投影クラスを決定する。
CLIPのフレームワークの最も一般的なユースケースは、物体検出である。このモデルでは、自然言語クエリを分析することで、画像内の物体を正確に識別することができる。このアプローチは、物体検出に使用される従来のデータセットや、手間のかかるアノテーション技術が不要になることを意味する。CLIPの場合、正確な位置を与え、"信号の右側に青い自転車 "と示すだけで区別できる。
さらに、CLIPは物体識別以外にも使用できる。例えば、ゼロショット学習を行い、学習データセットに含まれていない個人や物体を認識・分類することができる。モデルによって獲得された、事前に訓練された重みの概念的知識に基づいて、意味的な推論や解釈を行う能力は、その汎用性を示している。
CLIPは、テキストと画像の間のギャップを埋めることで、異なるドメインにわたる幅広いアプリケーションを可能にする:
- 画像検索と取得:** CLIPは、テキスト記述を用いた画像検索に使用することができ、画像検索システムの精度と関連性を大幅に向上させる。CLIPはテキストと画像の両方の内容を理解するため、複雑なクエリにマッチする画像を検索することが可能です。
拡張現実(AR)と仮想現実(VR)**:ARおよびVR環境において、CLIPはユーザーとデジタルコンテンツとのインタラクションを強化するために使用することができ、リアルタイムの画像解析と文脈理解を可能にし、ユーザーが見て説明した内容に基づいて関連する情報やアクションを提供することができます。
アートとデザインの支援**:アーティストやデザイナーは、CLIPを使用してテキスト記述に基づいて画像を生成または編集し、言葉を視覚的要素に変換することで創造的プロセスを促進することができます。
医療支援**:医療画像診断において、CLIPの物体検出は、X線、MRI、CTスキャンなどのさまざまなタイプの医療画像に存在する異常の位置を特定するために医師が使用することができます。さらに、テキスト記述により、特定の臓器、腫瘍、奇形を正確に特定することができます。さらに、広域の保健所から、遠隔医療で画像に説明を添えて送ることができるようになった。これにより、医療従事者は、医用画像の分析に深い理解がなくても、十分な情報に基づいた判断ができるようになった。
自動運転支援**:CLIPは、道路沿いの多くの物体を検出することで、自動運転車の視覚を強化する。このシステムは、複雑なシナリオの複雑な説明を読み取る能力があるため、運転中に正しい判断ができる。さらに、CLIPによる物体検知は、自動運転車による歩行者、自転車、道路標識の識別によって安全性を向上させる。この技術は事故を減らし、道路の安全性を向上させるのに役立つ。
金融サービスCLIPを使えば、トレーダーは在庫管理を簡単に合理化でき、過剰在庫や過小在庫といった無駄を減らすことができる。さらに、文字による説明は倉庫内での効果的な商品管理に不可欠であり、サプライチェーン・ロジスティクスにおける商品の容易な識別、追跡、監視を可能にし、同時に品質上の欠陥をチェックし、ユーザー間のより良いコミュニケーションを維持する。
電子商取引の推奨高度な画像処理と言語処理能力により、CLIPはユーザーに個別化された購買体験を提供する。CLIPは、高度な画像処理能力と言語処理能力により、利用者に個別化された購買体験を提供する。
CLIPは様々な条件下で物体を認識することができるため、膨大なラベルデータを必要としません。この柔軟性は、注釈付きデータの入手が困難であったり、時間がかかったりするような状況に理想的である。
CLIPは、新しいオブジェクトを含むかどうかに関わらず、ゼロショット学習タスクをシームレスに扱うことができます。CLIPは、追加トレーニングなしで、様々な環境条件やオブジェクトに対応するために、その設定を難なく適応させます。
CLIPは、画像とそれに対応する説明を含む大規模なデータセットを含む、様々な物体認識技術を用いて学習されました。この進歩により、テキストから簡単に情報を識別できるようになり、AIシステムはより効率的に動作し、貴重な時間を節約できるようになりました。
視覚言語アプリケーションで3D幾何学情報を抽出することは困難であり、リモートセンシングのような特殊な分野ではパフォーマンスが低下する。そのため、リモートセンシングや視覚言語融合タスクなど、さまざまな領域でCLIPの有効性を高めるための具体的なフレームワークや方法論を開発することが不可欠である。
不確実性の下での意思決定は、特に画像認識に関するCLIPの解釈可能性が困難な、ヘルスケアや法的状況のような敏感な分野では、困難である可能性がある。
さらに、CLIPは細かな特徴の理解が狭いため、解釈可能性を難しくしています。
事前学習データはCLIPに影響を与えるバイアスを持つ可能性があり、社会的偏見を増幅する可能性がある。このような倫理的な懸念は、AIアプリケーションがコンテンツや意思決定システムを制御する際に極めて重要になる。偏った結果は、現実に深刻な結果をもたらす可能性がある。
新しいデータでは、ゼロショット学習はCLIPで訓練されたタスクほどうまくいかない。
##物体検出入門
物体検出はコンピュータビジョンの基礎であり、画像や動画内の物体の識別と位置特定を行う。この技術は、医療診断や自律走行車から監視システムまで、無数の用途がある。従来の物体検出アルゴリズムは、ラベル付き画像の膨大なデータセットで学習した機械学習モデルに大きく依存している。しかし、このような膨大なラベル付きデータの取得には、時間とコストがかかることが多い。そこで、ゼロショット物体検出の出番となる。ゼロショット物体検出は、ラベル付けされたデータセット上でモデルを微調整することなく物体を検出することを可能にし、コンピュータビジョンの分野を大きく変える。このアプローチを活用することで、正確な物体検出を達成しつつ、大規模な注釈付きデータセットへの依存を大幅に減らすことができる。
CLIPモデルを理解する
2021年にOpenAIが開発したCLIP(Contrastive Language-Image Pre-training)モデルは、AI技術の大きな飛躍を象徴しています。コンピュータビジョンと自然言語処理を統合することで、CLIPは機械が書かれたテキストのレンズを通して画像を解釈することを可能にする。このモデルはデュアルエンコーダーフレームワークを採用しており、画像とテキストを共有された潜在空間にマッピングし、ロバストな画像-テキスト対応を確立する。この革新的なアプローチにより、CLIPは物体検出、ゼロショット学習、学習データセットに含まれていない個人や物体の認識と分類など、さまざまなタスクを実行できる。視覚データとテキストデータを理解し関連付ける能力により、CLIPはAIの領域で多目的なツールとなる。
CLIPの仕組み
CLIPは、何百万もの画像とテキストデータのペアを訓練するために、対照的な損失関数を活用することによって動作する。学習中、モデルは与えられた画像に対応するテキストの説明を予測するように学習し、その逆も同様である。このプロセスの結果、画像とテキストの両方が表現される共有ベクトル空間が生成され、シームレスな比較と理解が可能になります。物体検出タスクでは、CLIPは画像内の物体を識別するためにテキスト記述を利用することができます。自然言語と画像表現の理解に長けているため、ラベル付けされたデータセットに事前に触れることなく物体を検出できるゼロショット物体検出に特に適しています。この機能は、ラベル付きデータが少ない、あるいは入手が困難なアプリケーションに新たな可能性をもたらします。
CLIPによる物体検出
CLIPによる物体検出は、簡単かつ強力なプロセスである。検出する物体のテキスト記述を提供することで、モデルは画像内の対応する物体を特定することができます。CLIPのゼロショット物体検出機能は、ラベル付けされたデータセット上で微調整することなく物体を検出できることを意味し、ラベル付けされたデータの取得が制限されていたり、高価であったりするシナリオにとって理想的なソリューションとなります。さらに、CLIPの自然言語理解能力により、詳細なテキスト記述に基づいて物体を検出することができるため、さまざまなコンピュータビジョンタスクでの有用性が高まります。このためCLIPは、正確な物体検出が重要な自律走行車から医療用画像処理に至るまで、幅広い用途で価値あるツールとなります。
CLIPを使い始める
環境のセットアップ
CLIPを使い始めるには、必要なツールとリソースを使用して環境をセットアップする必要があります。CLIPライブラリーとその依存関係をインストールすることから始めましょう。効率的な学習と推論のために、互換性のあるGPUがあることを確認します。次に、オブジェクト検出タスクのために、画像データと対応するテキスト記述を準備します。環境がセットアップされたら、CLIPの機能を探索し、様々な物体検出タスクに適用することができます。このセットアップにより、CLIPの高度な画像および言語処理能力を活用できるようになり、わずか数行のコードで画像データから物体を検出し、洞察を得ることができるようになります。
ゼロショット物体検出における結論と今後の課題
CLIPにおけるマルチモーダル学習の継続的な発展は、そのリアルタイムの優れた可能性を浮き彫りにしています。より解釈しやすい高度なモデルの探求は、機械学習エンジニアの主な目標でした。CLIPはまた、画像識別、自然言語処理(NLP)、医療診断、小売などの領域で大きな進歩をもたらしている。得られた印象的な結果のため、CLIPのモデルにおいて、少数ショット学習が汎化能力を高めることができるかどうか、さらに探求する余地がある。説明可能なAIは、モデルを解釈し、それらがどのように機能するかを理解するために使用することができる。また、転移学習技術は、複数のドメインにまたがる適応性と一貫した性能を向上させることができる。
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021, July).自然言語監視からの伝達可能な視覚モデルの学習。In International conference on machine learning (pp. 8748-8763).PMLR.