




XLNet Explained: Generalized Autoregressive Pretraining for Enhanced Language Understanding
XLNet is a transformer-based language model that builds on BERT's limitations by introducing a new approach called permutation-based training.
Read the entire series
- An Introduction to Natural Language Processing
- Top 20 NLP Models to Empower Your ML Application
- Unveiling the Power of Natural Language Processing: Top 10 Real-World Applications
- Everything You Need to Know About Zero Shot Learning
- NLP Essentials: Understanding Transformers in AI
- Transforming Text: The Rise of Sentence Transformers in NLP
- NLP and Vector Databases: Creating a Synergy for Advanced Processing
- Top 10 Natural Language Processing Tools and Platforms
- 20 Popular Open Datasets for Natural Language Processing
- Top 10 NLP Techniques Every Data Scientist Should Know
- XLNet Explained: Generalized Autoregressive Pretraining for Enhanced Language Understanding
Pre-training is a key step in NLP (natural language processing), where models are trained on large datasets to learn general language patterns before being fine-tuned for specific tasks. Two popular methods are autoregressive (AR) models, like GPT, which predict the next word based on past words, and autoencoding (AE) models, like BERT, which mask random tokens and predict them using the surrounding context. While BERT’s masked language modeling (MLM) enables rich contextual learning, the pretraining task doesn't always align perfectly with downstream tasks, leading to potential discrepancies during fine-tuning.
XLNet, introduced in the paper XLNet: Generalized Autoregressive Pretraining for Language Understanding, was developed to address these limitations. By using permutation-based language modeling, XLNet captures bidirectional context without the need for masking, reducing the pretrain-finetune mismatch. Unlike BERT, XLNet can also model dependencies between predicted tokens, leading to better performance on a range of NLP tasks. Additionally, XLNet incorporates Transformer-XL to effectively handle long sequences by retaining long-term context.
As a result, XLNet outperforms BERT on several benchmarks, including SQuAD, GLUE, and RACE. In this blog post, we’ll cover XLNet’s key innovations, how it improves upon earlier models, and what these advancements mean for modern NLP tasks.
Pretraining Challenges in Natural Language Processing
As we have seen, pre-training allows a model to learn general language representations that can be transferred to various downstream tasks like sentiment analysis, question answering, or document summarization. However, the two major approaches, autoregressive (AR) and autoencoding (AE), have limitations that restrict their ability to capture comprehensive language understanding. To understand how XLNet improves upon existing methods, let’s first look at the current approaches for pretraining in NLP, starting with autoregressive models.
Autoregressive Models
Autoregressive models like GPT generate tokens sequentially by predicting each token based only on its preceding tokens. This means that the model can only learn unidirectional context, either left-to-right or right-to-left, which restricts its ability to capture more complex bidirectional relationships between tokens. For example, when predicting a word in the middle of a sentence, an AR model would only rely on the words before the target word, limiting its ability to leverage future information.
Imagine a sentence such as The cat is sleeping on the __. Given this incomplete sentence, an AR model will predict the next word (mat, for example) based only on the words before it. It won’t consider any future words to inform this prediction, which makes it less effective when bidirectional understanding is needed, such as in sentiment analysis or question-answering tasks.
Let’s take a look at the autoregressive language modeling objective function.
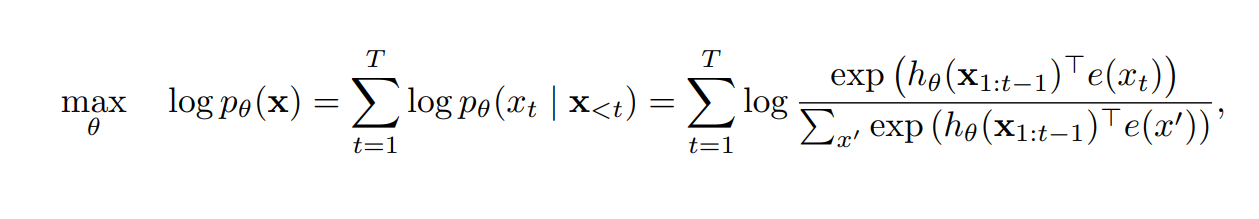 Figure 1- Autoregressive language modeling objective function.png
Figure 1- Autoregressive language modeling objective function.png
Figure 1: Autoregressive language modeling objective function
In the above function, represents the context derived from all tokens preceding the target token. This context is built using neural models like RNNs or Transformers, which process the sequence of previous tokens to generate a hidden state, or context representation, for the current position. The model then uses this context to predict the next token by comparing the context vector to the embeddings of all possible next tokens, , using a similarity measure like dot product. The result is a probability distribution over all potential tokens, with the highest probability token being selected as the prediction. Essentially, this means that the model predicts the next word by looking at only the preceding words, limiting its ability to incorporate information from future tokens, which can be crucial for understanding the full meaning of a sentence.
Autoencoding Models (AE)
Autoencoding models, like BERT, attempt to address the limitation of AR models by introducing masked language modeling (MLM). In MLM, random tokens in the input sequence are masked, and the model is trained to predict these masked tokens based on the surrounding context. This allows BERT to capture bidirectional dependencies, as it considers both the left and right context when predicting a masked word. However, this introduces a pretrain-finetune discrepancy because the [MASK] tokens used during pretraining do not appear in real downstream tasks.
For example, in the sentence The [MASK] brown fox jumps over the lazy dog, BERT is tasked with predicting the missing word quick based on the context provided by both the left and right parts of the sentence. This ability to consider the full bidirectional context is beneficial in understanding complex language tasks, such as determining the sentiment of a sentence. However, during fine-tuning, BERT may underperform in real-world tasks since the [MASK] tokens don’t exist in actual use cases, like chatbots or search engines.
BERT’s masked language modeling objective is expressed below:
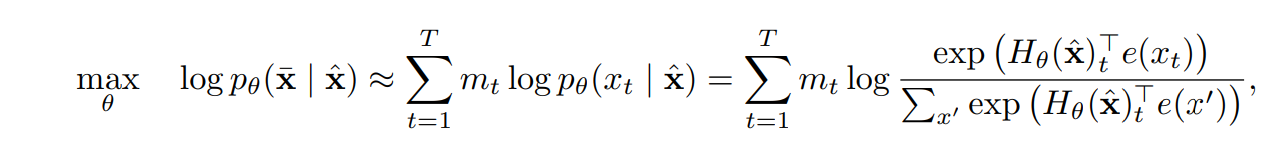 Figure 2- BERT’s masked language modeling objective function.png
Figure 2- BERT’s masked language modeling objective function.png
Figure 2: BERT’s masked language modeling objective function
In the above equation, when , it indicates that the token at position in the sequence is masked and must be predicted by the model. The masked token is replaced by a special token (like [MASK]), and the model is tasked with predicting the original token based on the unmasked surrounding tokens. The sequence refers to the corrupted version of the input sequence, where some tokens are masked. The hidden state representations for the entire sequence, , are computed using a Transformer model, and these representations are used to predict the masked tokens. However, BERT assumes that the masked tokens are independent of each other when being predicted, which can be a simplification because tokens in natural language often depend on one another. Thus, while BERT captures bidirectional context effectively, its prediction strategy for masked tokens does not fully account for inter-token dependencies.
XLNet’s Key Innovations: Overcoming Pretraining Limitations
XLNet introduces permutation-based language modeling, which combines the strengths of both AR and AE models while addressing their respective limitations. Let’s explore the key innovations that make XLNet a powerful pretraining method.
Permutation-Based Language Modeling
The core innovation of XLNet is permutation-based language modeling, where the model predicts tokens in all possible orders rather than in a fixed left-to-right or right-to-left sequence. This allows XLNet to capture relationships between tokens from both past and future contexts without relying on masking tokens. By considering all possible permutations of a sequence, XLNet learns richer token dependencies and avoids the pretrain-finetune mismatch found in BERT.
However, it’s important to note that the permutation only changes the factorization order, not the order of the input sequence itself. The original sequence remains intact, with its corresponding positional encodings. This design choice is crucial because, during fine-tuning, the model will encounter text sequences in their natural order. Thus, a proper attention mask is applied in Transformers to handle the different factorization orders. This ensures that while the model is trained with multiple permutations of the sequence, it will still generalize well when exposed to naturally ordered sequences during fine-tuning.
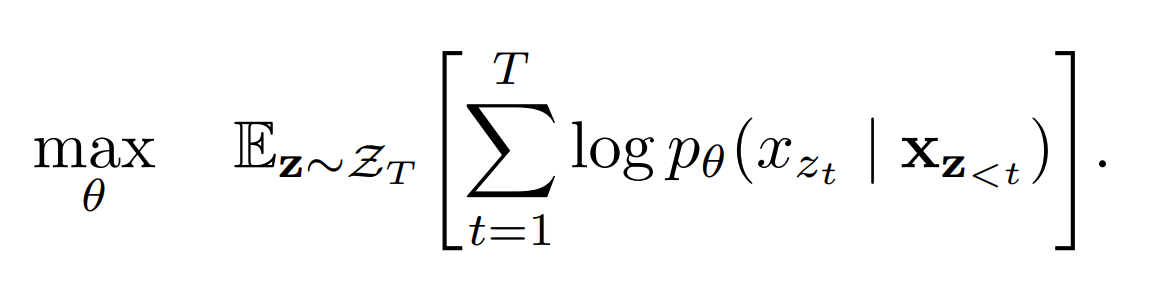 Figure 3- Permutation language modeling objective.png
Figure 3- Permutation language modeling objective.png
Figure 3: Permutation language modeling objective
Where:
represents the set of all possible permutations of the sequence length , meaning that instead of always predicting tokens in a fixed order, XLNet considers every possible rearrangement of the sequence during training.
and denote the t-th element and the first t-1 elements of a permutation , which means the model predicts the token at position based on the tokens in the sequence that come before it in the permutation, regardless of their original order.
By maximizing the likelihood across multiple permutations, XLNet captures relationships between tokens from both past and future contexts. This approach allows XLNet to model bidirectional dependencies more effectively, as it doesn’t assume token independence, making it more flexible than models like BERT that rely on masked tokens.
For example, in the sentence The cat sat on the mat, instead of always predicting the next word in a left-to-right order, XLNet may use permutations like “sat mat The on cat the,” ensuring that the model learns bidirectional dependencies more effectively.
Two-Stream Self-Attention Mechanism
XLNet introduces a two-stream self-attention mechanism to ensure accurate predictions during permutation-based training. In traditional transformers, tokens attend to all other tokens in the input, which can lead to unwanted information leakage. To address this, XLNet splits the self-attention into two streams:
Content Stream: Computes the hidden representation of each token based on the full context.
Query Stream: Generates the prediction for the next token while preventing access to the content of the token being predicted.
These two streams work in tandem to ensure that predictions remain accurate while preserving the integrity of the permutation-based model.
The image below illustrates the Two-Stream Self-Attention Architecture:
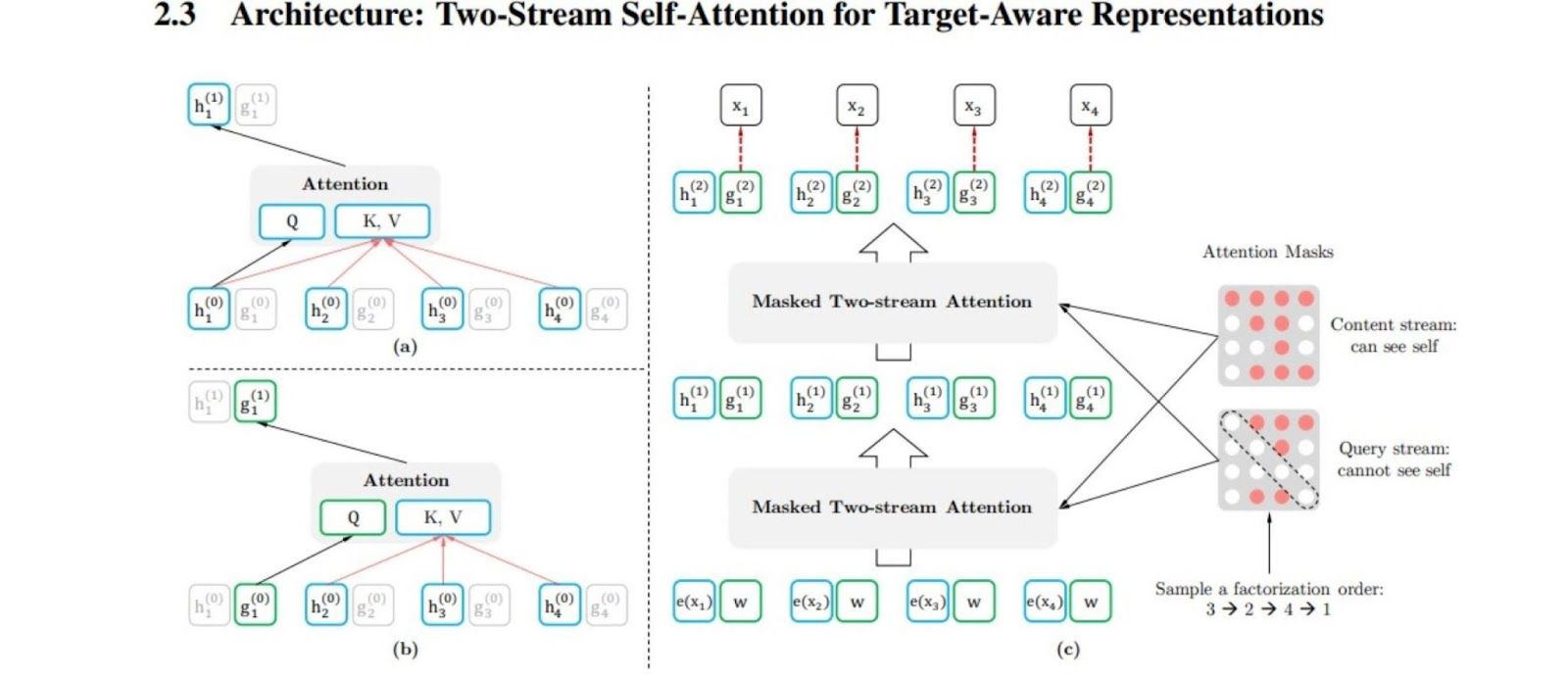 Figure 4- Architecture- Two-Stream Self-Attention for Target-Aware Representations.jpg
Figure 4- Architecture- Two-Stream Self-Attention for Target-Aware Representations.jpg
Figure 4: Architecture: Two-Stream Self-Attention for Target-Aware Representations
The above architecture shows how XLNet’s two-stream attention mechanism separates content and query operations. In the content stream (Figure 1a), tokens attend to one another using traditional attention, allowing the model to gather full contextual information. In contrast, the query stream (Figure 1b) is designed to prevent a token from attending to its own content, which helps ensure that predictions are made without peeking at the current token's value. By keeping the query stream blind to the token being predicted, the model learns more robust predictions.
When XLNet trains on multiple permutations (Figure 1c), the model predicts each token based on different combinations of surrounding tokens. For example, a token in position 3 might be predicted after processing tokens in positions 4, 2, and 1, according to the selected permutation. This training approach ensures that XLNet can model rich bidirectional context and token dependencies in multiple ways, which improves its generalization to downstream tasks.
Transformer-XL for Long-Range Dependencies
One limitation of standard transformers is their fixed context length, which restricts their ability to handle long-range dependencies in text. To address this, XLNet integrates Transformer-XL, which introduces two key improvements:
Segment Recurrence: This mechanism allows the model to carry over hidden states from previously processed segments into the current segment instead of discarding them at the end of each segment. By reusing these hidden states, XLNet can maintain a continuous memory, even when processing long sequences. This enables the model to capture long-term dependencies across different segments, extending its effective memory beyond fixed-length windows.
Relative Positional Encoding: In traditional transformers, each token is assigned an absolute position in the sequence, which the model uses to understand their relationships. However, in XLNet, relative positional encoding focuses on the distance between tokens rather than their fixed positions. This allows the model to better capture the relationships between tokens, regardless of their absolute positions in the sentence, making it more flexible in handling context.
XLNet’s Experimental Results and Benchmark Performance
The combination of permutation-based language modeling and Transformer-XL has enabled XLNet to outperform previous models across multiple NLP benchmarks. Let’s explore some of the key results:
SQuAD 2.0 (Stanford Question Answering Dataset)
On the SQuAD 2.0 benchmark, XLNet achieved an Exact Match (EM) score of 87.9%, compared to BERT’s 80.0%. This demonstrates XLNet’s superior ability to handle complex question-answering tasks, especially those that require understanding long passages and determining whether a question is answerable based on the context.
GLUE Benchmark
The General Language Understanding Evaluation (GLUE) benchmark measures a model’s performance on a wide range of language understanding tasks, including sentiment analysis (SST-2), paraphrase detection (MRPC), and natural language inference (MNLI). Across multiple GLUE tasks, XLNet consistently outperformed BERT, highlighting its versatility in handling various NLP challenges.
RACE Dataset
The RACE reading comprehension dataset, with its exam-style questions, requires models to draw inferences from long passages and integrate information across sentences. XLNet outperforms previous models like BERT by using permutation-based modeling to effectively capture complex dependencies within passages, handling multi-sentence reasoning and inference questions with improved accuracy.
Practical Applications of XLNet in NLP
XLNet’s innovations make it suitable for a wide range of NLP applications:
1. Enhanced Question-Answering Systems
XLNet’s deep contextual understanding makes it a good choice for building sophisticated question-answering systems. Its ability to model bidirectional context and long-range dependencies ensures that it can generate accurate, context-aware answers.
For example, in a customer support chatbot, when a user asks How do I return an item? XLNet can generate a detailed response that takes into account the entire conversation history, providing a more accurate and helpful answer.
2. Text Summarization and Generation
XLNet’s ability to capture long-term dependencies makes it highly effective for tasks like text summarization and generation. By understanding the full context of a document, XLNet can generate concise and coherent summaries of long texts.
For example, If tasked with summarizing a lengthy news article, XLNet can accurately capture the key points while maintaining the original context and coherence.
3. Sentiment Analysis
In sentiment analysis, XLNet’s permutation-based language modeling allows it to capture nuanced relationships between entities and opinions, making it highly effective at extracting emotions from text.
For example, When analyzing product reviews, XLNet can detect subtle sentiments like frustration or satisfaction, even when the language used is indirect or complex.
Beyond its performance in typical NLP tasks, XLNet’s ability to generate dense vector embeddings opens up new possibilities for scalable search and retrieval systems, particularly when integrated with powerful vector databases like Milvus.
Integrating XLNet with Vector Databases for Scalable Search
Beyond its performance in typical NLP tasks, XLNet’s ability to generate dense vector embeddings opens up new possibilities for scalable search and retrieval systems when integrated with powerful vector databases like Milvus.
Vector embeddings capture the semantic meaning of text, making them useful for tasks like document retrieval and recommendation systems.
How Vector Embeddings Work
When XLNet processes a sentence or document, it generates a high-dimensional vector representing the text's meaning in a high-dimensional space. Similar texts will have similar vector representations located closer to each other, allowing for efficient retrieval based on meaning rather than exact keyword matching.
For example, in the sentences, The cat sat on the mat and The dog lay on the rug. While the words differ, their meanings are similar. XLNet generates vector embeddings that place these sentences close to each other in vector space, enabling a search engine to retrieve both sentences when queried with a semantically related phrase.
Key Milvus Capabilities Enhancing XLNet
Milvus is an open-source vector database optimized for storing and querying high-dimensional vectors, such as those generated by XLNet. It is the most popular vector database in terms of GitHub stars. Here’s how Milvus enhances XLNet:
Hybrid Search: Milvus allows combining vector similarity search with traditional filtering, enabling complex queries that consider both semantic similarity and metadata. For example, in a legal document search system, Milvus can retrieve documents that are semantically related to a query while filtering results by case type or jurisdiction.
Efficient High-dimensional Indexing: Milvus uses advanced indexing methods to support efficient querying of high-dimensional vectors, essential for handling XLNet embeddings. This indexing capability ensures fast retrieval, even when searching through billions of vectors.
Scalability: Milvus is designed for horizontal scaling, allowing it to handle billions of vectors. This scalability makes it well-suited for large-scale applications that use XLNet embeddings in production environments.
Real-time Updates: Milvus supports real-time insertion and updates, allowing newly generated XLNet embeddings to be immediately available for querying. This enables systems to stay up-to-date with the latest data without significant downtime.
Future Research Directions for XLNet
As a cutting-edge model, XLNet opens up new possibilities for future research:
Efficient Training Techniques: While permutation language modeling provides significant improvements, it is computationally intensive. Future research could focus on optimizing the training process to reduce the computational cost while maintaining performance.
Domain-Specific Applications: Fine-tuning XLNet for specific industries, such as healthcare or finance, could yield significant improvements in domain-specific language tasks.
Multimodal Extensions: Extending XLNet’s capabilities beyond text to include other modalities, such as images or audio, could lead to more holistic AI systems that understand and reason across multiple data types.
Conclusion
XLNet marks a significant advancement in the field of NLP by overcoming the limitations of both autoregressive and autoencoding models. Its permutation-based language modeling allows it to capture bidirectional context, while Transformer-XL enables it to handle long-range dependencies. These innovations make XLNet highly effective across a range of tasks, from question answering to document retrieval.
Integrating XLNet with Milvus provides exciting new opportunities for building scalable, efficient systems that rely on dense vector embeddings for search and retrieval tasks. As NLP research progresses, XLNet’s impact is likely to grow, paving the way for more powerful and adaptable language understanding systems.
Further Resources
 Denis Kuria
Denis KuriaDenis is a machine learning engineer who enjoys writing guides to help other developers. He has a bachelor's in computer science and loves hiking and exploring the world.
- Pretraining Challenges in Natural Language Processing
- XLNet’s Key Innovations: Overcoming Pretraining Limitations
- XLNet’s Experimental Results and Benchmark Performance
- Practical Applications of XLNet in NLP
- Integrating XLNet with Vector Databases for Scalable Search
- Future Research Directions for XLNet
- Conclusion
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Unveiling the Power of Natural Language Processing: Top 10 Real-World Applications
NLP makes our lives much easier. Learn about the top 10 most popular NLP applications and how they have an impact on our lives.

Everything You Need to Know About Zero Shot Learning
A comprehensive guide to Zero-Shot Learning, covering its methodologies, its relations with similarity search, and popular Zero-Shot Classification Models.

Top 10 Natural Language Processing Tools and Platforms
An overview of the top ten NLP tools and platforms, highlighting their key features, applications, and advantages to help you select the best options for your needs.