




ColPali: Enhanced Document Retrieval with Vision Language Models and ColBERT Embedding Strategy
Retrieval Augmented Generation (RAG) is a technique that combines the capabilities of large language models (LLMs) with external knowledge sources to enhance response accuracy and relevance. A common application of RAG is extracting content from sources like PDFs, as these files often contain valuable data but are challenging to search and index. The difficulty lies in the fact that important information may be overlooked depending on the tool used for extraction. For example, text embedded within images might not be detected during extraction, making it impossible to retrieve later.
ColPali, a document retrieval model, addresses this issue with its novel architecture based on Vision Language Models (VLMs). It indexes documents through their visual features, capturing textual and visual elements. By generating ColBERT-style multi-vector representations of text and images, ColPali encodes document images directly into a unified embedding space, eliminating the need for traditional text extraction and segmentation.
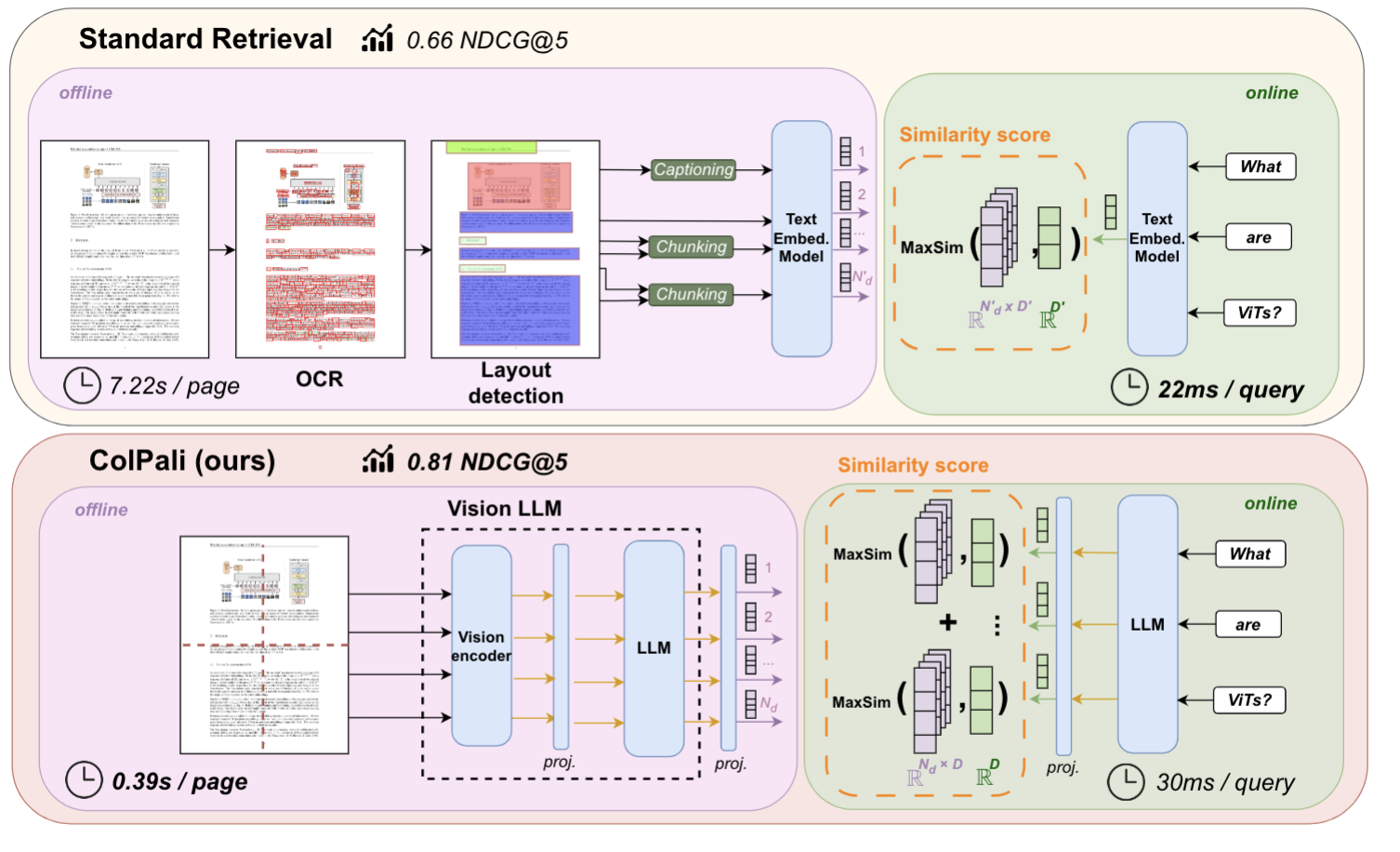 Figure: Standard Retrieval Pipeline vs. ColPali Pipeline for PDF retrieval
Figure: Standard Retrieval Pipeline vs. ColPali Pipeline for PDF retrieval
The image above is from the ColPali paper, where the authors argue that a regular PDF retrieval pipeline usually includes multiple steps: text extraction using OCR, layout detection, chunking, and embedding generation. ColPali simplifies this process using a single Vision Language Model (VLM) that takes a screenshot of the page as input.
ColPali integrates tools beyond traditional RAG systems, so it’s important to understand some of these concepts first. Before discussing the details of ColPali, let’s learn vision language models and late interaction models.
What are Vision Language Models (VLMs)?
Vision Language Models (VLMs) are multimodal models that learn from both images and text simultaneously. They take image and text inputs and generate text outputs and are part of the broader category of generative models.
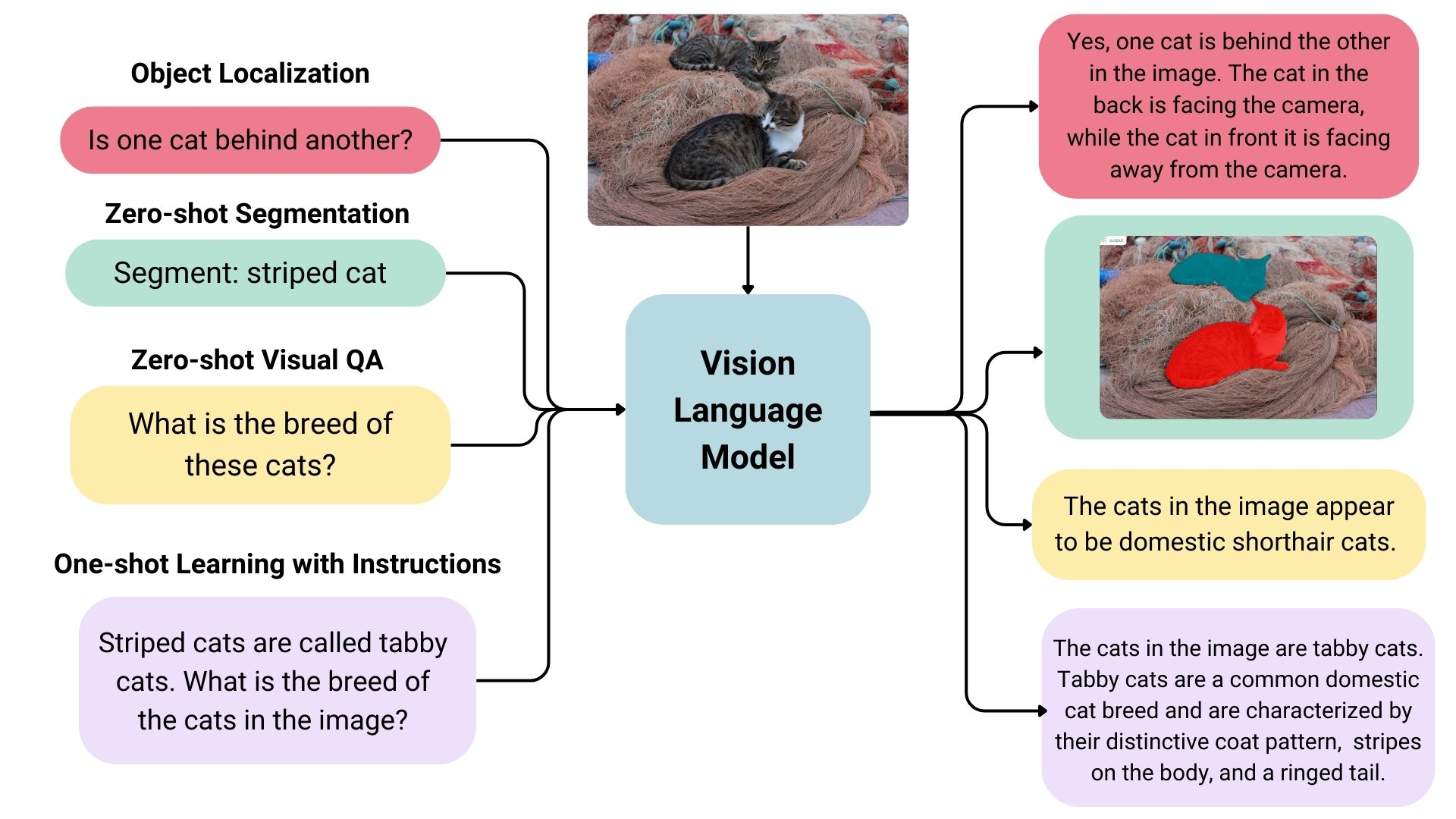 Example of a VLM
Example of a VLM
ColPali leverages VLMs to align embeddings of text and image tokens acquired during multimodal fine-tuning. Specifically, it uses an extended version of the PaliGemma-3B model to produce ColBERT-style multi-vector representations. The authors chose this model because it has a variety of checkpoints fine-tuned for different image resolutions and tasks, including OCR for reading text from images.
ColPali is built upon Google’s PaliGemma-3B model, which was released with open weights. This model was trained using a diverse dataset—63% academic and 37% synthetic data from web-crawled PDF pages, enhanced with VLM-generated pseudo-questions.
What are Late Interaction Models?
Late Interaction models are designed for retrieval tasks. They focus on token-level similarity between documents rather than using a single vector representation. By representing text as a series of token embeddings, these models offer the detail and accuracy of cross-encoders while benefiting from offline document storage's efficiency.
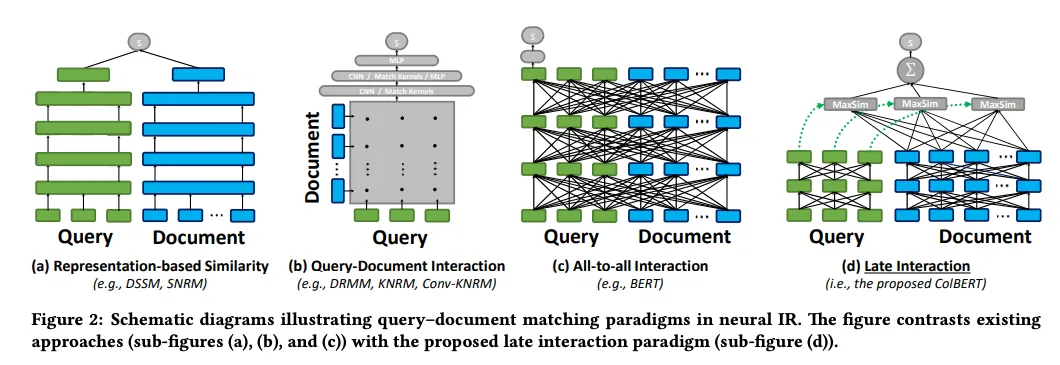 Figure 2: Schematic diagrams illustrating query–document matching paradigms in neural IR
Figure 2: Schematic diagrams illustrating query–document matching paradigms in neural IR
Figure 2: Schematic diagrams illustrating query–document matching paradigms in neural IR. | Source
With this understanding of Late Interaction Models and Vision Language Models, we can now explore how ColPali combines these elements for enhanced document retrieval.
What is ColPali and How Does It Work?
ColPali is an advanced document retrieval model designed to index and retrieve information directly from the visual features of documents, particularly PDFs. Unlike traditional methods that rely on OCR (Optical Character Recognition) and text segmentation, ColPali captures screenshots of each page and embeds entire document pages into a unified vector space using VLMs. This approach allows ColPali to bypass complex extraction processes, improving retrieval accuracy and efficiency.
Below are key steps during its workflow:
Document Procesing
- Creating images from PDFs: Instead of extracting text, creating chunks, and then embedding them, ColPali directly embeds the screenshot of a PDF page into a vector representation. This step is like taking a picture of each page rather than attempting to extract its content.
- Splitting images into grids: Each page is then divided into a grid of uniform pieces called patches. It's divided into a 32x32 grid by default, resulting in 1024 patches per image. Each patch is represented as a 128-dimensional vector. You can think of it as one image with 1024 "words" describing those patches.
Embedding Generation
- Processing image patches: ColPali transforms these visual patches into embeddings through a Vision Transformer (ViT), which processes each patch to create a detailed vector representation.
- Aligning visual and text embeddings: To match visual information with the search query, ColPali converts the query text into embeddings in the same vector space as the image patches. This alignment allows the model to directly compare and match visual and textual content.
- Query processing: The model tokenizes the query, assigning each token a 128-dimensional vector. It uses prompts like “Describe this image
” to ensure the model focuses on the visual elements, allowing seamless text and visual data integration.
Retrieval Mechanism
ColPali uses a late interaction similarity mechanism to compare the query and document embeddings at query time. This approach allows detailed interaction between all the image grid cell vectors and the query text token vectors, ensuring a comprehensive comparison.
The similarity is computed using a "sum of maximum similarities" approach:
- Compute similarity scores between each query token and every patch token in the image.
- Aggregate these scores to generate a relevance score for each document.
- Sort the documents by the score in descending order, using the score as a relevance measure.
This method enables ColPali to match user queries effectively with relevant documents, focusing on the image patches that best align with the query text. Doing so highlights the most relevant portions of the document, combining textual and visual content for precise retrieval.
Model Training Process
ColPali is built on the PaliGemma-3B model, a Vision Language Model developed by Google. In its implementation, ColPali keeps the model’s weights frozen during training to retain the VLM's pre-trained knowledge while focusing on optimizing for document retrieval tasks.
The key to adapting this general-purpose VLM for document retrieval lies in a small but crucial component: a retrieval-specific adapter. This adapter is layered on top of the PaliGemma-3B model and is trained to learn representations tailored for retrieval tasks.
The training process for this adapter utilizes a triplet learning approach:
- A text query
- An image of a page relevant to the query
- An image of a page irrelevant to the query
This method enables the model to learn fine-grained distinctions between relevant and irrelevant content, enhancing its retrieval accuracy.
ColPali Advantages
- Elimination of complex preprocessing: ColPali replaces the traditional pipeline of text extraction, OCR, layout detection, and chunking with a single VLM that takes a screenshot of the page as input.
- Capturing both visual and textual information: By working directly with page images, ColPali can incorporate both textual content and visual layout in its understanding of documents.
- Efficient retrieval from visually rich documents: The late interaction mechanism allows for fine-grained matching between queries and document content, enabling efficient retrieval of relevant information from complex, visually rich documents.
- Preservation of context: By operating on whole page images, ColPali maintains the full context of the document, which can be lost in traditional text-chunking approaches.
ColPali Challenges
As with any large-scale retrieval system, ColPali faces significant challenges in terms of computational complexity and storage requirements.
Computational Complexity: The compute requirements for ColPali grow quadratically with the number of query tokens and patch vectors. This means that as the complexity of queries or the resolution of document images increases, the computational demand grows rapidly.
Storage Requirements: The storage cost of ColBERT-like approaches is 10x to 100x of dense vector embedding, as it requires a vector for each token. The storage needs of the system scale linearly with three factors:
Number of documents
Number of patches per document
Dimensionality of the vector representations.
This scaling can lead to substantial storage requirements for large document collections.
Optimization Strategy - Precision Reduction
To address these scaling challenges, we suggest using the precision reduction strategy.
- Precision reduction: Moving from higher-precision representations (e.g., 32-bit floats) to lower-precision formats (e.g., 8-bit integers) can dramatically reduce storage requirements with often minimal impact on retrieval quality.
Summary
ColPali has significant potential to transform how we retrieve visually rich content with textual context in RAG systems. By leveraging Vision Language Models, it enables document retrieval based not only on text but also on visual elements.
However, despite its impressive results, ColPali faces challenges due to its high storage demands and computational complexity, which may hinder widespread adoption. Future optimizations could address these limitations, making it more practical. As RAG methods continue to develop, retrieval methods like ColPali, which integrate visual and textual understanding, are likely to play an increasingly important role in information retrieval across diverse document types.
We'd love to hear what you think!
If you like this blog post, we’d really appreciate it if you could give us a star on GitHub! You’re also welcome to join our Milvus community on Discord to share your experiences. If you're interested in learning more, check out our Bootcamp repository on GitHub or our notebooks. We'd also love to hear if you are planning on trying out ColPali in the future!
Further Reading
- ColPali Paper: [2407.01449] ColPali: Efficient Document Retrieval with Vision Language Models
- ColPali GitHub: https://github.com/illuin-tech/colpali
- ColBERT: A Token-Level Embedding and Ranking Model
- ColPali: Document Retrieval with Vision Language Models
- What is RAG?
- What are Vector Databases and How Do They Work?

Keep Reading

Zilliz Cloud Now Available in AWS Europe (Ireland)
Zilliz Cloud launches in AWS eu-west-1 (Ireland) — bringing low-latency vector search, EU data residency, and full GDPR-ready infrastructure to European AI teams. Now live across 30 regions on five cloud providers.

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.