




次世代検索:クロスエンコーダとスパース行列因子分解がk-NN検索を再定義する方法
AXN(Adaptive Cross-Encoder Nearest Neighbor Search)は、CEスコアの疎な行列を使用してk-NNの結果を近似し、高い精度を維持しながら計算量を削減する。
シリーズ全体を読む
- 筏か否か?クラウドネイティブデータベースにおけるデータ一貫性のベストソリューション
- Faiss(フェイスブックAI類似検索)を理解する
- 情報検索メトリクス
- ベクターデータベースにおける高度なクエリー技術
- ベクトル検索を支える人気の機械学習アルゴリズム
- ハイブリッド検索:テキストと画像を組み合わせて検索機能を強化
- ベクターデータベースの高可用性の確保
- ランキングモデル:ランキングモデルとは何か?
- Zillizでレキシカル検索とセマンティック検索を使いこなす
- バイナリ量子化とMilvusによるベクトル検索の効率化
- モデルプロバイダーオープンソースとクローズドソースの比較
- Milvusによる多言語言語の埋め込みとクエリー
- 構造化データのベクトル化とクエリの究極ガイド
- HNSWlibを理解する:高速近似最近傍探索のためのグラフベースライブラリ
- ScaNN(Scalable Nearest Neighbors)とは?
- ScaNNを始める
- 次世代検索:クロスエンコーダとスパース行列因子分解がk-NN検索を再定義する方法
- ボイジャーとは?
- 迷惑とは何か?
効率的なk-最近傍(k-NN)検索は、類似アイテムの検索や関連情報の検索などのタスクの基本である。これらの検索では、与えられたクエリに対して最も関連性の高い近傍を決定することが目標となる。クロスエンコーダ(CE)は、クエリとアイテムのペアを同時に考慮するため、関連性の評価において非常に正確である。しかし、計算コストが高いため、数千から数百万の比較が必要な大規模なk-NN検索には不向きである。
このスケーラビリティの問題を解決するために、デュアルエンコーダ(DE)がよく使われる。DEはクエリとアイテムの数値表現(またはvector embeddings)を別々に事前計算し、検索を高速化する。しかし、この効率性は精度を犠牲にするものであり、特に新しいドメインや馴染みのないドメインでは、DEは追加的なfine-tuningを行わないと性能が低下する傾向がある。もう一つのアプローチはCUR行列分解で、これは関連性行列(クエリとアイテムの関係)を近似することで精度と効率のバランスをとるものである。DEに比べて性能は向上するものの、複数のCE計算に大きく依存するため、コストがかかり、大規模なアプリケーションでは実用的ではありません。
現在の手法には限界があるため、k-最近傍探索(k-NN)において信頼度推定値を近似するための、より効率的で正確な手法を開発する必要がある。目的は以下のような手法を開発することである:
CURに基づく手法よりも、項目のインデックス付けに必要なCEコールが大幅に少ない。
DEベースのretrieve-and-rerank手法よりも高い精度を、特に新しいドメインにおいて、DEの微調整を追加することなく達成する。
AXN (Adaptive Cross-Encoder Nearest Neighbor Search)**は、このニーズを満たす新しいソリューションを導入している。AXNは、CEスコアの疎行列を使用してk-NNの結果を効率的に近似し、高い精度を維持しながら計算量を大幅に削減します。これらの手法の詳細に興味がある方は、研究論文をご覧ください。
キーコンセプトの理解基礎固め
このブログで取り上げている革新的な方法論を掘り下げる前に、基本的な構成要素を把握することが重要である。
K-最近傍(k-NN)検索:** K-最近傍 近傍(k-NN)検索は、機械学習における基本的な検索手法である。これは、距離や関連性などの事前に定義された類似度メトリックに基づいて、与えられたクエリに最も近いk個のアイテムを識別する。この手法は、推薦システム、検索エンジン、自然言語処理 (NLP)タスクなど、関連するマッチを見つけることが重要なアプリケーションの基礎となっている。
クロスエンコーダ(CE):** クロスエンコーダ(CE)は、一対のデータポイント(例えば、クエリとアイテム)を入力とし、スカラー類似度スコアを直接出力する類似度関数である。質問応答(QA)やエンティティ・リンキングなどのタスクにおいて、CEは最先端の結果を達成している。しかし、CEは計算コストが高く、特に変換器のようなディープニューラルモデルを用いてパラメータを設定する場合には、計算コストが高くなる。
クロスエンコーダによる効率的なk-NN探索のための方法論
次に、クロスエンコーダーモデルを使用した効率的なk-最近傍(k-NN)検索の主な方法論について説明します。核となる考え方は、学習された埋め込み空間におけるドット積を用いて、クロスエンコーダのスコアリング関数を効率的に近似することである。
方法論は大きく2つの段階に分類できる:
オフラインインデックス作成段階: 疎行列因子分解
オンラインk-NN探索段階(AXN):適応的クロスエンコーダ最近傍探索
スパース行列因数分解によるオフライン索引付け
CE ベースの検索で項目をインデックス化する標準的なアプローチには、CUR 分解を使用するものがあるが、これは多くの CE 呼び出しを必要とし、大規模なデータセットでは実用的でない。スパース行列因数分解に基づくアプローチは、クエリとアイテムのペアの慎重に選択されたサブセットに対するクロスエンコーダのスコアを含むスパース行列(Gと表記)を構築し、アイテム表現を学習するためにこの行列を因数分解することで、この制限に対処する。行列の疎な性質は、可能性のある全てのクエリ-項目ペアに対してクロスエンコーダスコアを計算することが計算上不可能であるという事実から生じる。
行列因数分解には主に2つの方法がある。
帰納的行列分解 (MFTRNS)
帰納的行列分解 (MFIND)
帰納的行列因子分解 (MFTRNS)
Transductive Matrix Factorizationは、クエリとアイテムの埋め込みを学習可能なパラメータとして扱い、Gにおいて観測されたクロスエンコーダのスコアと学習された埋め込みとのドット積の差を最小化することにより、これらの埋め込みを直接学習する。
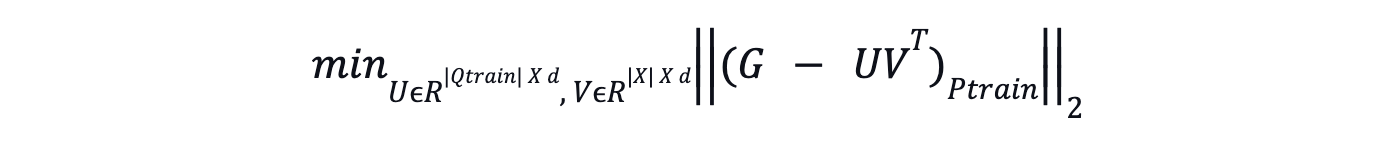 式 -Transductive Matrix Factorization .png
式 -Transductive Matrix Factorization .png
ここで
Gは、訓練クエリ(Qtrain)とアイテムのサブセット(I)との間のクロスエンコーダのスコアを含む疎行列である。
PtrainはGの観測されたエントリの集合への射影を表す。
UとVはそれぞれクエリとアイテムの埋め込みに対応する行列である。
MFTRNSは小規模なデータセットでは有効であるが、大規模なアイテムセットでは学習可能なパラメータが多くなるため、計算コストが高くなり、メモリを消費する。
帰納的行列因子分解 (MFIND)
MFINDは,スケーラビリティを向上させるために,生のクエリと項目の特徴を埋め込み空間にマッピングする浅いMLPを学習します.これらのMLPは、ベースとなるデュアルエンコーダモデル(関連するタスクで学習されるが、ターゲットドメインでは微調整されていない)からクエリと項目の埋め込みを入力し、クロスエンコーダのスコアによく近似する埋め込みを生成することで学習される。このアプローチは未知のクエリやアイテムに対してより良い汎化を与え、蒸留によって完全なDEモデルを学習するよりも計算効率が良い。
スパース行列の構築戦略
クロスエンコーダを用いたk-NN探索法におけるスパース行列の構成には、主に2つの戦略がある:
クエリごとの固定項目
訓練クエリの集合(Qtrain )が訓練されると、この戦略はスパース行列Gを構築するために、各クエリに対して固定数の項目(kd)を選択する。 項目の選択は、一様にランダムに行うこともできるし、デュアルエンコーダーモデル(DESRC)のようなベースライン検索法を用いることもできる。 この戦略は、クエリがアイテムよりも多様なシナリオで最も効果的である。
アイテムごとの固定クエリー
このストラテジーはアイテムセット(I)の各アイテムに対して固定数のトレーニングクエリを選択する。 この選択プロセスもランダムにするか、ベースライン検索メソッドに基づく。このアプローチは、アイテムがクエリよりも多様な場合に理想的である。
AXNによるオンラインk-NN検索
AXN (Adaptive Cross-Encoder Nearest Neighbor Search)は、与えられたテストクエリに対して、クロスエンコーダのスコアからのフィードバックを用いて適応的に埋め込みを改良することで、k-NN検索を行います。この方法は、クエリの埋め込みを適応的に改良し、検索に近似CEスコアを用いることで、与えられたクエリのk-最近傍を効率的に見つける。アイテムの埋め込みはこのプロセスを通して固定されたままである。
AXNは複数のラウンドに渡って動作し、テストクエリに対するクロスエンコーダスコアの近似を段階的に改善する。まず、ランダムにアイテムを検索するか、デュアルエンコーダやTF-IDFのようなベースライン検索手法を使用する。そして、クロスエンコーダがこれらの項目をスコアリングし、連立一次方程式を解くことにより、最初のクエリ埋め込みが計算される。その後のラウンドでは、AXNは、現在のクエリ埋め込みと固定アイテム埋め込みを用いて計算された近似クロスエンコーダ・スコアに基づいて、追加アイテムを検索する。これらの新しく選択された項目に対する正確なクロスエンコーダのスコアが計算され、次のラウンドのクエリ埋め込みを更新するために使用される。
このプロセスは一定のラウンド数、もしくは計算予算がなくなるまで続けられる。予算は各ラウンドに均等に分配される。最後に、検索された項目は正確なクロスエンコーダのスコアに基づいてランク付けされ、上位k項目が与えられたテストクエリに対する近似k-NNとして返される。
AXN - テスト時間k-NN検索推論
以下に、AXNを用いた適応k-NN探索の実行手順を示す。
図- AXNアルゴリズム.png](https://assets.zilliz.com/Figure_AXN_Algorithm_cd8c575036.png)
図-AXNアルゴリズムAXNアルゴリズム|出典
テストクエリの正則化
正則化は、絞り込み過程におけるオーバーフィッティングを防ぐために行われます。これは、DEモデルのようなパラメトリックモデルからの埋め込みと、適応的な絞り込み処理から得られるクエリ埋め込みを、重み付き平均を用いて結合することで行われる。この正則化により、未見の項目を一般化し、検索品質を向上させることができる。最終的なテストクエリ埋め込みは以下のようになる:
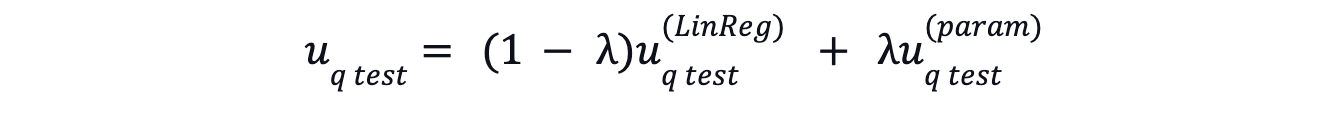 equation -regularization.png
equation -regularization.png
AXN と疎行列因子分解の結果の分析
ZESHEL(ゼロショットエンティティリンク用)とBEIR(ゼロショット情報検索用)の2つの一般的なベンチマークデータセットを用いて、異なる検索モデルを用いたretrieve-and-rerankや、最近提案されたCUR分解ベースの手法であるADACURなどの様々なベースラインアプローチに対する、提案する疎行列因子分解とAXN手法の有効性を評価する。
AXNとRNRの比較
適応型k-NN検索手法であるAXNは、従来のretrieve-and-rerank (RNR)アプローチよりも優れた性能を発揮する。例えば、YuGiOhデータセット(ZESHELデータセットのテストドメイン)において、インデックス作成と初期検索の両方にDESRCを使用したAXNは、DESRCを使用したRNRと比較して、Top-1-Recallで5.2%の改善、Top-100-Recallで54%の顕著な改善を達成している。特筆すべきは、この性能向上は最小限の計算オーバーヘッドでもたらされることである。
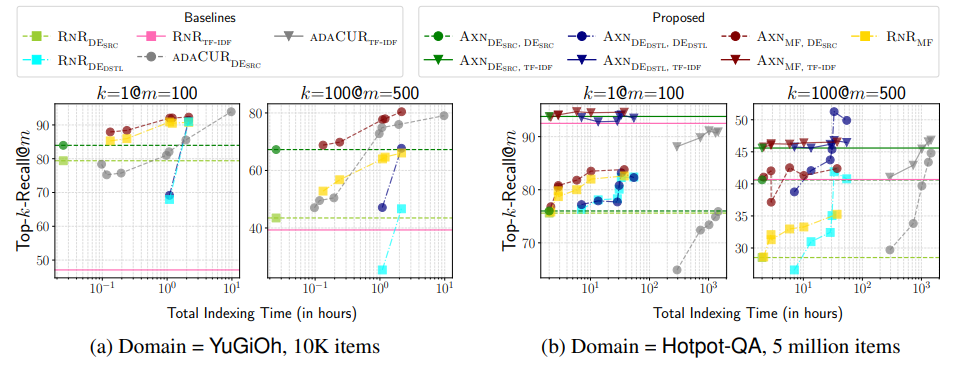 図- Top-1-RecallとTop-100-Recallと様々なアプローチのインデックス作成時間との比較.png
図- Top-1-RecallとTop-100-Recallと様々なアプローチのインデックス作成時間との比較.png
図:Top-1-RecallとTop-100-Recallのインデックス作成時間に対する様々なアプローチ | ソース
x軸は、埋め込みと学習モデルの計算などのステップを含む、総インデクシング時間を表す。y軸はTop-1-Recall@100とTop-100-Recall@500を示しており、それぞれ検索された上位100項目と500項目の中で見つかった(クロスエンコーダーによる)トップk近傍の割合を意味する。
行列因数分解とDEDSTLの比較
行列因数分解ベースのアプローチ、特に帰納的変種(MFIND)は、効率と精度のバランスをとる驚くべき能力を示す。これらの手法は、インデックス付けに必要な計算資源を大幅に削減しながら、デュアルエンコーダーモデルを訓練するための蒸留ベースの手法の性能に常に匹敵するか上回る。この効率性は、因数分解に疎行列を用い、MFINDで浅いMLPを訓練することで、完全なデュアルエンコーダーモデルを訓練するのに比べてパラメータが少なくなることに起因する。
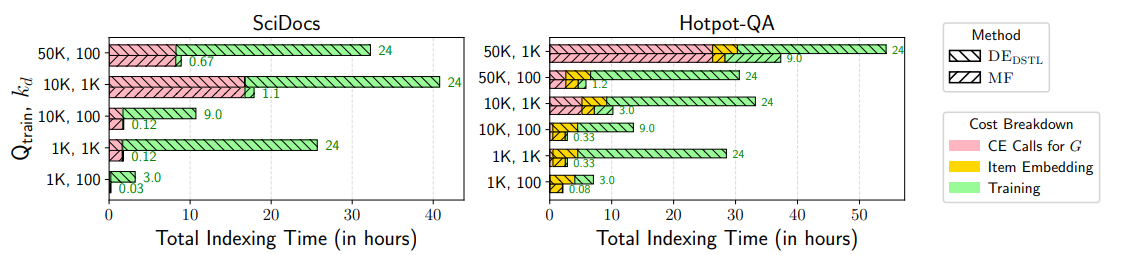 図- MFとDEDSTLのインデックス作成待ち時間.png
図- MFとDEDSTLのインデックス作成待ち時間.png
図:MFとDEDSTLのインデックス待ち時間| ソース
ADACURに対する大幅なインデックス高速化
提案手法は、特にAXNと組み合わせた場合、最近のCUR分解に基づく手法であるADACURと比較して、インデクシング速度において大きな優位性を示す。例えば、大規模なHotpot-QAデータセット(BEIRのデータセット)において、ADACURは500万項目のインデックス作成に1000GPU時間以上を必要とする。一方、MFINDは、初期検索にDESRCを用いたAXNと組み合わせることで、同等の検索精度を達成しながら、3時間未満で索引付け処理を完了する。これはスパース行列分解アプローチの計算効率の高さを示している。
下流タスク性能分析
k-NN探索精度の向上に関する評価では、異なるデータセット間で、下流タスクのパフォーマン スに与える影響が異なることが示された。Hotpot-QAデータセットではk-NNリコールの向上がダウンストリームタスクの性能向上と直接相関しているが、SciDocs、YuGiOh、Star Trekなどの他のデータセットでは傾向が異なる。これらのデータセットでは、クロスエンコーダを用いた厳密な総当たり探索は、RNRDESRC.と比較して、下流タスクの性能が最適化されない。
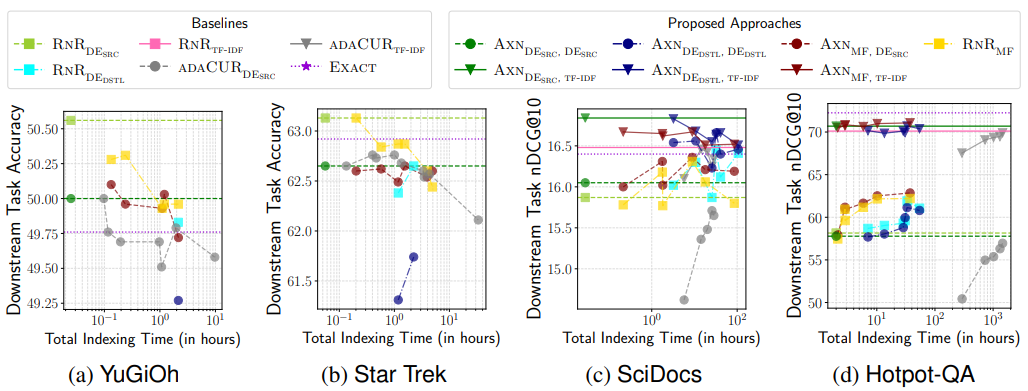 図-下流タスク性能とインデックス作成時間.png
図-下流タスク性能とインデックス作成時間.png
図:下流タスクのパフォーマンスとインデックス作成時間|出典
影響と意味
この方法論は、様々な機械学習アプリケーションにいくつかの重要な影響と示唆を与える。
1.効率と精度のギャップを埋める
クロスエンコーダは、その優れた精度にもかかわらず、計算負荷の高さから、大規模なアプリケーションに適したものが必要とされることが多い。スパース行列分解やAXN適応検索アルゴリズムなどの手法は、このような制限に対処する。これらの手法を組み合わせることで、スケーラビリティを大幅に向上させながら、精度の低下を最小限に抑えてクロスエンコーダの性能を近似することができる。その結果、検索エンジン、推薦プラットフォーム、質問応答ツールなどのシステムは、法外な計算コストをかけることなく、高品質の検索を実現できるようになった。
2.ゼロショット検索性能の向上
提案するAXN手法の適応的な性質は、学習中に未見のアイテムを扱った場合でも、検索想起を向上させることを可能にする。これは、モデルが新しいドメインやアイテムセットに汎化することが求められる、ゼロショット検索シナリオにおいて特に有用である。完全な蒸留に基づく学習の計算コストを回避しつつ、既存のDEモデルを初期化に活用できることは、実用的な設定におけるこれらの手法の適用性をさらに高める。
3.タスク全体への幅広い適用性
提案手法は特定のタスクやドメインに限定されない。情報検索、質問応答、エンティティリンク、推薦システムなど、CEモデルによるk-NN検索が有益なあらゆるアプリケーションに適用できる。手法の汎用性は、その効率的な利点と相まって、幅広い機械学習の実務家や研究者にとって価値あるツールとして位置づけられる。
4.クロスエンコーダのスケーラブルな展開
フレームワークはクロスエンコーダのスケーラビリティを解き放ち、膨大なデータセットを扱う実世界のシステムへの統合を可能にする。オフライン・インデクシングや反復精緻化のような技術により、これらのシステムは数百万から数十億のクエリー-アイテム・ペアを効率的に管理することができます。このスケーラビリティは、迅速かつ正確な検索がユーザーの満足度や収益に直結するeコマースなどの業界にとって、特に大きな変革をもたらしている。このアプローチにより、アプリケーションは膨大な商品カタログに対しても正確な結果を提供することができます。
5.大規模データセットに対する計算効率
スパース行列因数分解は、類似度スコア計算のためにクエリとアイテムのペアを戦略的に選択することで、計算オーバヘッドを削減する。このシステムはコンパクトな埋め込みを再利用可能なように最適化し、その後の検索が非常に効率的になるようにする。この計算効率は、モバイル機器やIoTシステムのようなリソースに制約のある環境では非常に貴重である。音声による検索やパーソナライズされたレコメンデーションなどのアプリケーションは、パフォーマンスを犠牲にすることなく、高度な検索手法を採用できるようになった。
結論と今後の方向性
提案する方法論(疎行列分解、オフラインインデックス作成、AXN適応型k-NN検索アルゴリズム)は、クロスエンコーダーベースのk-NN検索のスケーラビリティと効率性を再定義するものである。このフレームワークは、高精度を維持しながら計算上の課題に対処することで、大規模な実世界システムでの実用的な展開を可能にします。この技術革新は、電子商取引、ヘルスケア、情報検索のような業界において、大規模で関連性の高い結果を提供する変革の可能性を秘めています。
将来の研究機会
1.マルチモーダル検索機能の強化:* 将来の研究としては、テキスト、画像、音声などのマルチモーダルデータをサポートする検索方法を拡張することができる。例を挙げると、テキストと画像を組み合わせることで、電子商取引におけるビジュアル検索を改善できるかもしれないし、音声とテキストを統合することで、より効果的な音声による検索が可能になるかもしれない。これらのイノベーションは、商品説明、レビュー、画像を一緒に使うことで、ハイブリッドな推薦システムをサポートすることもできる。このようなアプリケーションを実用化するためには、これらのデータタイプに対するクロスモーダル埋め込みや統一モデルの開発が鍵となるだろう。
2.グラフベースインデキシングの統合:大規模検索における効率性で知られるグラフベースインデキシング手法にスパース行列分解を組み合わせることで、検索のスケーラビリティと性能を向上させることができる。
3.正則化手法の高度化:よりロバストな正則化手法を開発することで、ノイズや複雑なデータセットにおけるフレームワークの汎化能力を高め、多様な環境における信頼性を向上させることができる。
4.**特にソーシャルメディアやニュースアグリゲータのような変化の早いプラットフォームでは、データセットが動的に進化するのに合わせてフレームワークを調整できるようにする戦略を探ることが重要である。
5.**フレームワークの機能は、バイオインフォマティクス、法律研究、医療検索など、高次元のゲノムデータや臨床データを扱うことが重要な分野に合わせることができる。
6.スパースマトリックス構築の最適化:* スパースマトリックス構築時に、機械学習を活用し、インパクトの大きいクエリとアイテムのペアを特定することで、効率と精度を向上させることができる。
関連リソース
機械学習におけるK-最近傍(KNN)アルゴリズムとは](https://zilliz.com/blog/k-nearest-neighbor-algorithm-for-machine-learning)
ベクトル埋め込みとは](https://zilliz.com/glossary/vector-embeddings)
ベクトルデータベースとは](https://zilliz.com/learn/what-is-vector-database)
ベクターデータベース技術による推薦システムとその利用について知っておくべきすべて](https://zilliz.com/learn/Introduction-to-Recommendation-systems)
情報検索とは](https://zilliz.com/learn/what-is-information-retrieval)
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS


