




Understanding Boolean Retrieval Models in Information Retrieval
Boolean retrieval models are an information retrieval method for retrieving relevant documents using a set of Boolean logic operators, eg. AND, OR, and NOT.
Read the entire series
- What is Information Retrieval?
- Information Retrieval Metrics
- Search Still Matters: Enhancing Information Retrieval with Generative AI and Vector Databases
- Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
- What Are Rerankers and How Do They Enhance Information Retrieval?
- Understanding Boolean Retrieval Models in Information Retrieval
- Will A GenAI Like ChatGPT Replace Google Search?
- The Evolution of Search: From Traditional Keyword Matching to Vector Search and Generative AI
- What is a Knowledge Graph (KG)?
Information retrieval is a fundamental concept that plays a crucial role in the modern landscape of recommendation systems and Generative AI (GenAI). At a high level, it enables us to efficiently retrieve relevant data from vast collections of information.
In this article, we'll discuss a specific information retrieval method known as Boolean Retrieval Models. However, before we explore this method in more detail, let's first explore the concept of information retrieval in general.
The Importance of Information Retrieval
Whether you realize it or not, the concept of information retrieval is used in many sectors and aspects of our lives. Consider a situation where you're surfing the internet: when looking for a specific topic, you typically type that topic in Google. In a split second, Google presents you with several relevant web pages.
As the name suggests, information retrieval is retrieving relevant content related to our query or question from a vast collection of data. You can see its application in many use cases in today's world, such as:
Search engines: Google is the prime example. When you type a query, Google quickly scans through millions of available web pages online and presents you with the most relevant results.
E-commerce: Platforms like Amazon and Shopify utilize information retrieval technologies to help their customers find products they would like to purchase. If you type in "t-shirt for men," for example, you'll be presented with various men’s t-shirts in a split second.
Companies' Internal Chatbots: Internal chatbots are becoming increasingly popular for customer assistance. These chatbots process requests and return relevant content or articles that might help troubleshoot customers’ problems.
Social Media: The combination of information retrieval and recommendation systems creates more personalized feeds on social media platforms. For example, if you frequently watch technology-related content on YouTube, most of your feed will consist of videos.
How Information Retrieval Systems Work
Common information retrieval systems consist of the following components:
Document: Refers to any retrievable content for the user. This process includes videos on streaming services like YouTube or Netflix, web pages on search engines like Google or Bing, and data, images, and texts in information management systems such as company internal databases.
Query: This represents the user's request, which can be expressed as a string of words or a complex set of criteria. A query represents specific information a user seeks, ranging from a simple keyword to a complex one requiring Boolean operators (e.g., "Find me a t-shirt AND for men").
Indexing: As information retrieval needs to be fast and efficient in fetching relevant content, indexing plays a crucial role. It refers to creating a mapping between a document and its location in a database for faster retrieval.
Retrieval: The process of returning relevant documents to the user. Several retrieval methods can be applied, including boolean retrieval and vector space models.
The information retrieval process begins with collecting documents for storage. In reality, this often involves hundreds of thousands or even millions of documents. Next, each document in the collection is indexed and stored in information management systems, typically databases.
Structured data are usually indexed and stored in traditional relational databases, while unstructured data, such as images or text, require storage in vector databases. Depending on your use case, you can implement different indexing methods. For example, vector databases like Milvus support different indexing methods, including Inverted File Index (IVF), Hierarchical Navigable Small World (HNSW), or Product Quantization to perform Approximate Nearest Neighbor (ANN) search. You can find more info about these indexing methods in this article.
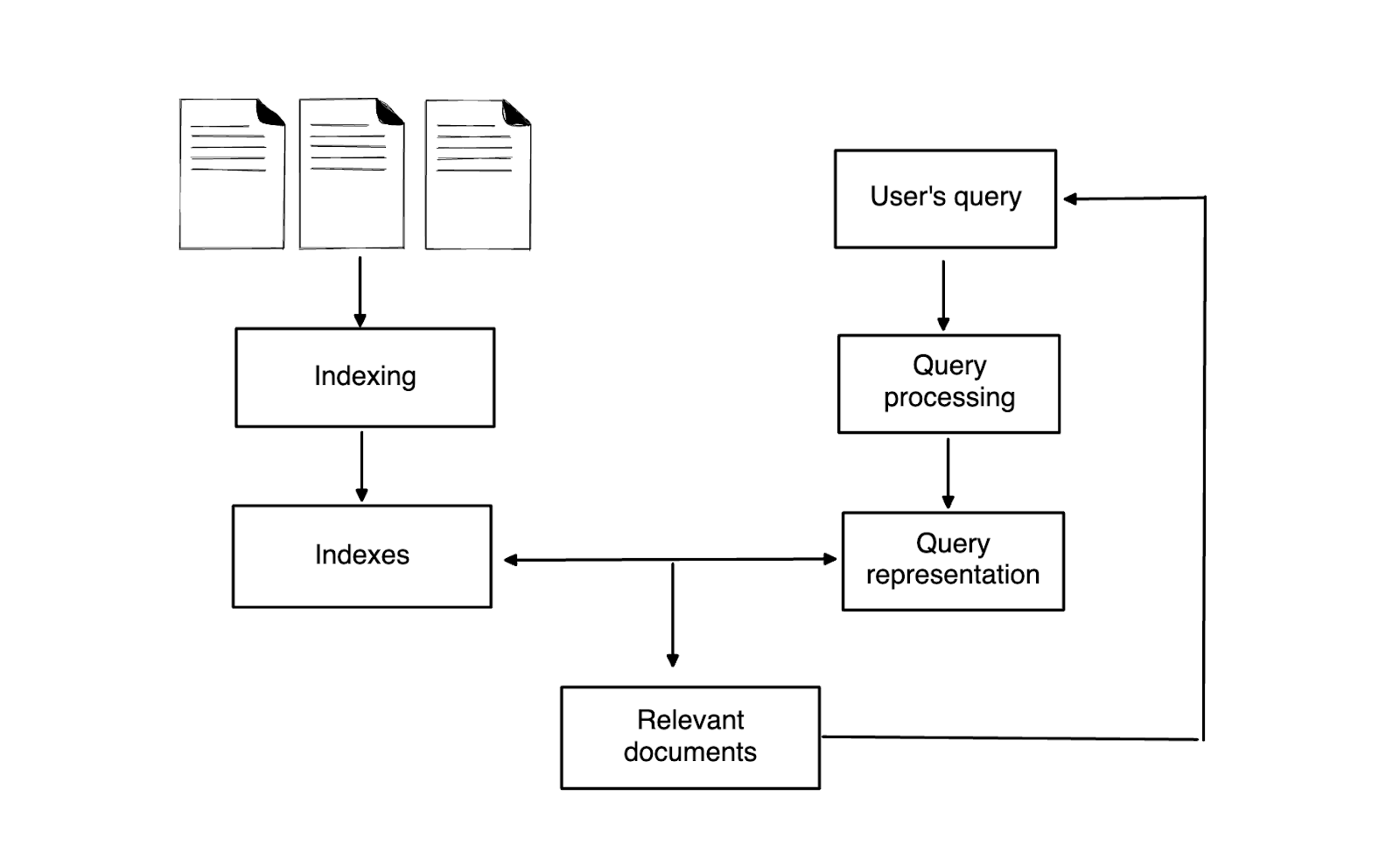 Figure 1- High-level workflow of the information retrieval system
Figure 1- High-level workflow of the information retrieval system
The information retrieval process can begin once all documents are indexed and stored. Users input their queries, and based on the chosen retrieval algorithm, the most relevant documents in the database are fetched. Common retrieval algorithms include boolean retrievals or vector-based retrievals, such as cosine distance or cosine similarity.
The Concept of Boolean Retrieval Model
Now that we understand the basic concept of information retrieval, let's discuss a specific type known as the Boolean retrieval model. As the name suggests, the boolean retrieval model retrieves relevant documents using a set of Boolean logic operators, such as AND, OR, and NOT.
AND: Retrieves all documents that contain all terms in our query. If our query is "A AND B," then documents containing both A and B will be retrieved.
OR: Retrieves all documents that contain any of the terms in our query. If our query is "A OR B," then documents containing either A or B, or both, will be retrieved.
NOT: Excludes all documents that contain a specific term in our query. If our query is "A AND NOT B," documents containing A but not B will be retrieved.
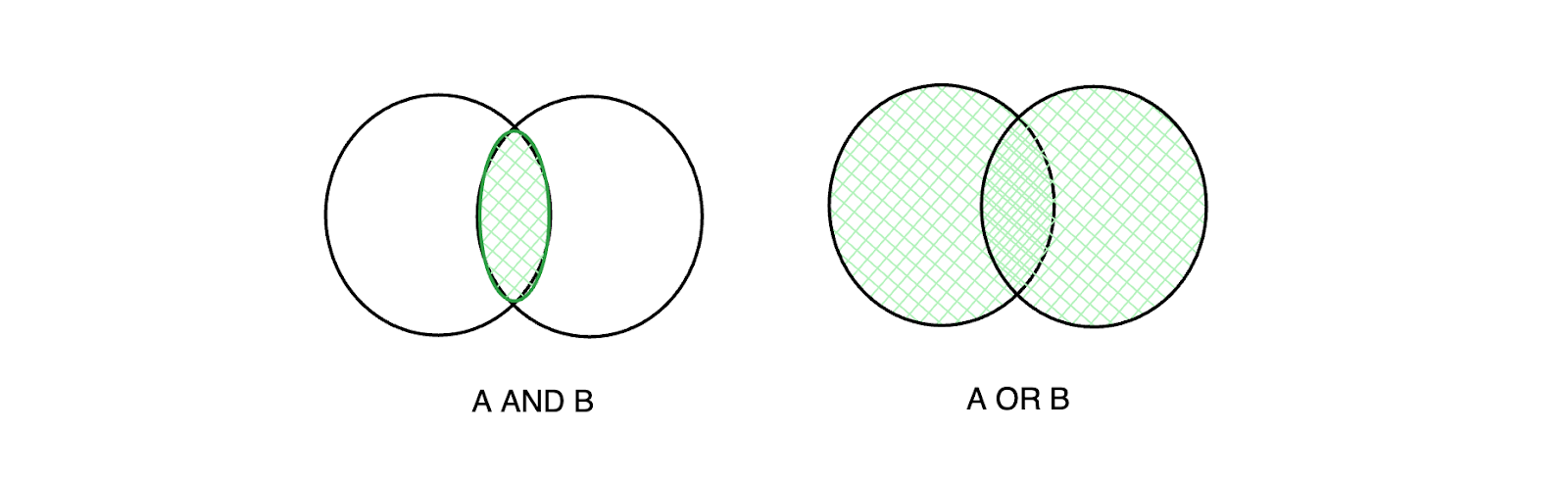 Figure 2- Venn diagram of AND and OR operations
Figure 2- Venn diagram of AND and OR operations
In its most basic form, the Boolean retrieval model uses a concept called the Term-Document Incidence Matrix. This concept relies on the bag-of-words method, where we construct a 2D matrix: columns represent documents, and rows represent the vocabulary or unique terms available in all documents.
Each cell in the matrix is expressed as a Boolean value with only two possible values: 0 or 1. It represents whether or not a term is present in a document. If a term is present, the value is 1; if not, the value is 0.
Let's say we have three documents, and only three distinct terms exist in them. Document 1 contains terms 1 and 3 but not term 2; document 2 contains only term 1, and document 3 contains terms 1 and 2.
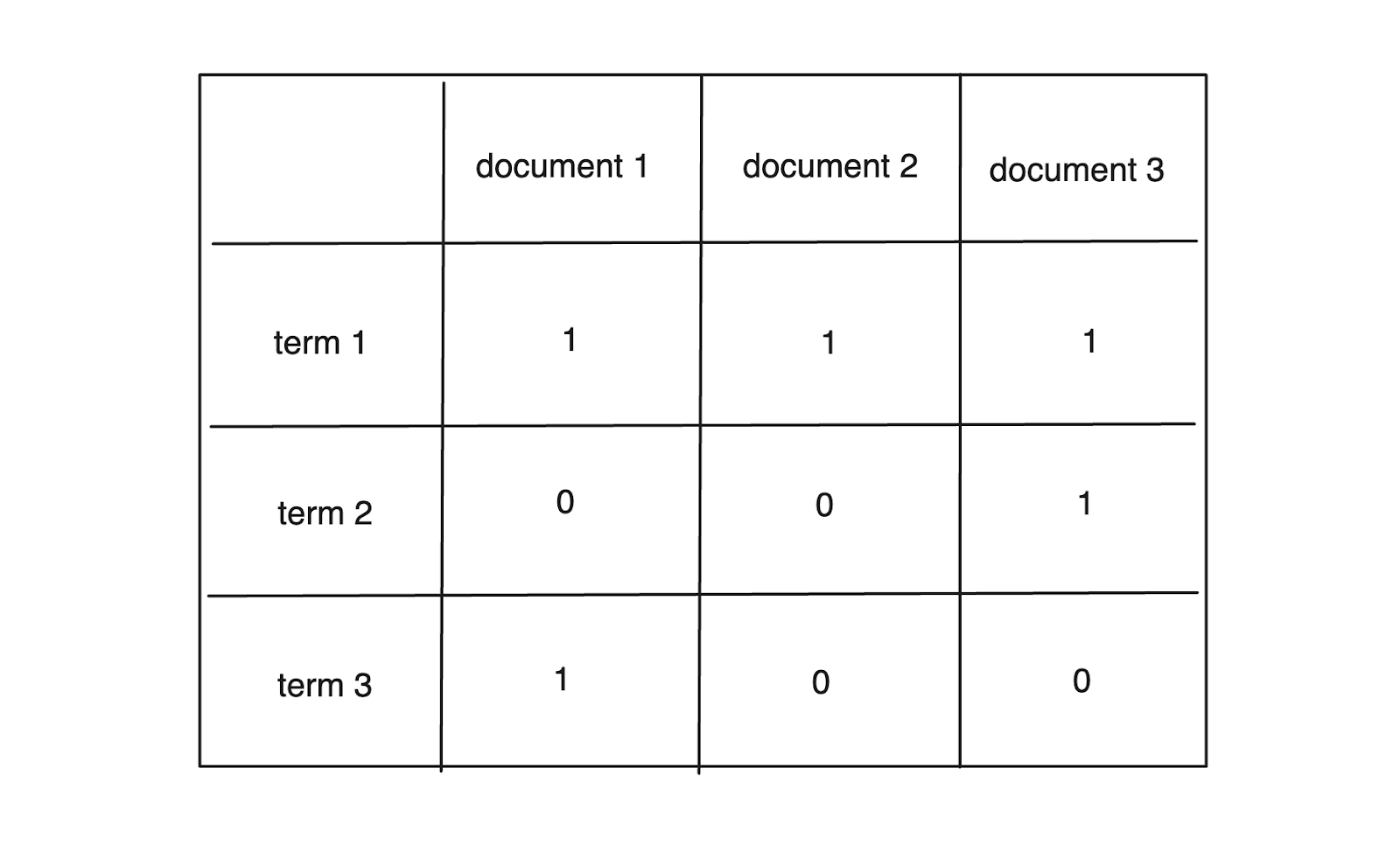 Figure 3- Example of term-document matrix
Figure 3- Example of term-document matrix
Once we have set up the term-document matrix as shown above, we can provide our query and perform a Boolean retrieval method. Consider the following query: "Find me documents with term 1 and term 2". To process this query, the Boolean retrieval method will perform the following operations:
Take the row associated with term 1. In the above visualization, this value would be [1, 1, 1].
Take the row associated with term 2. In the above visualization, this value would be [0, 0, 1].
Perform a bitwise AND operation: [1, 1, 1] AND [0, 0, 1] = [0, 0, 1].
Based on the result of the bitwise operation above, document 3 will be returned to us.
Inverted Index in Boolean Retrieval Model
The problem with implementing a term-document matrix, as shown above, is that, in reality, the row associated with each term is extremely sparse.
Imagine we have 10,000 documents and 100,000 unique terms in total. If we implemented a term-document matrix as above, we'd end up with a 100,000 x 10,000 matrix. In almost all cases, each row in that matrix would be extremely sparse, i.e., it would contain many 0 values, as there could only be so many documents that contain any given term. The space complexity required to perform Boolean operations increases quadratically for every increment of document and term.
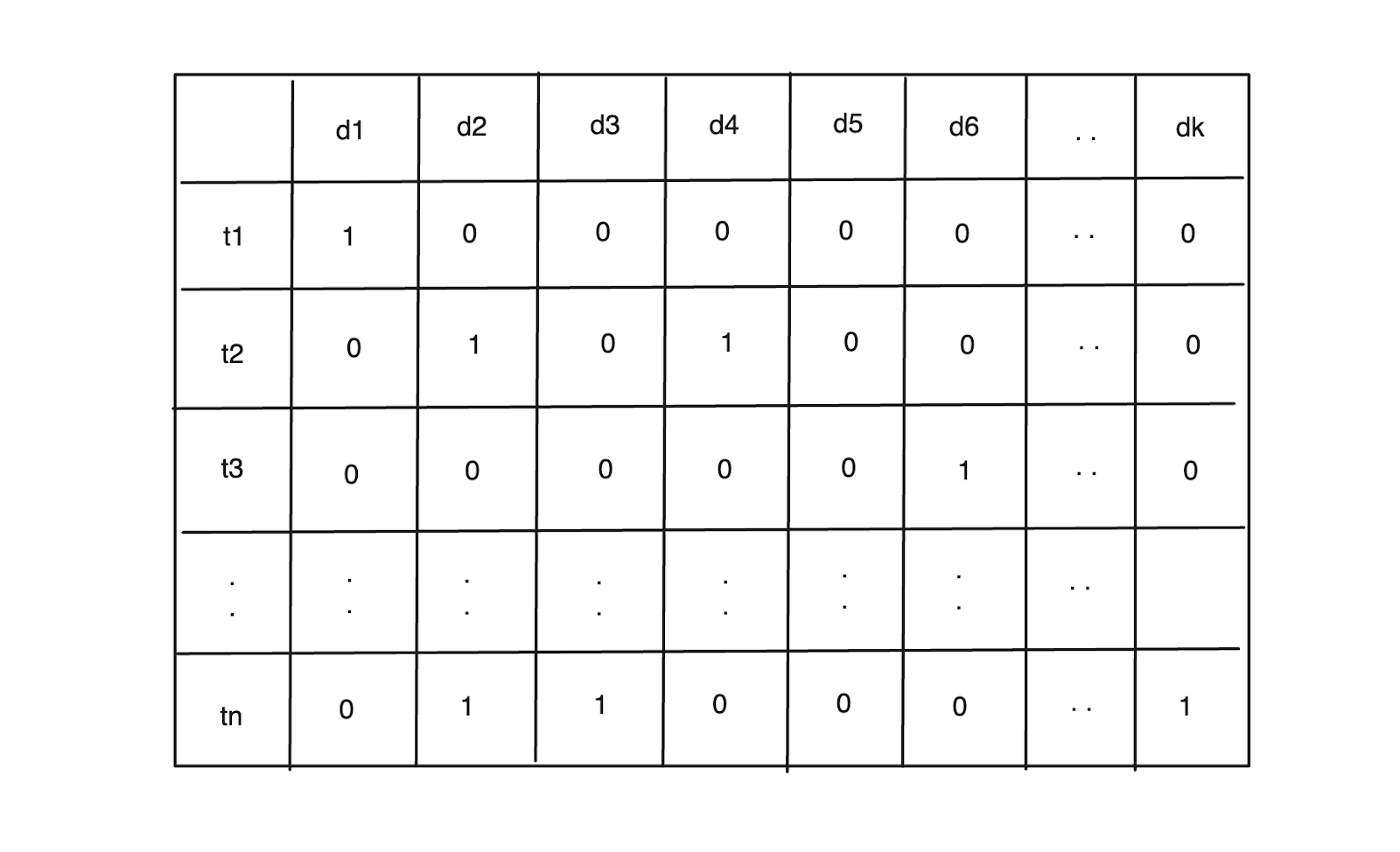 Figure 4- Sparse representation of term-document matrix
Figure 4- Sparse representation of term-document matrix
To tackle this problem, a method called inverted index is normally implemented to improve the efficiency and speed in a Boolean retrieval model. In a nutshell, instead of creating the whole term-document matrix, we store only the IDs of the documents that contain the term x. In other words, for each term, we store a so-called posting list where each element corresponds to a document's ID in which that term is present, as you can see in the visualization below:
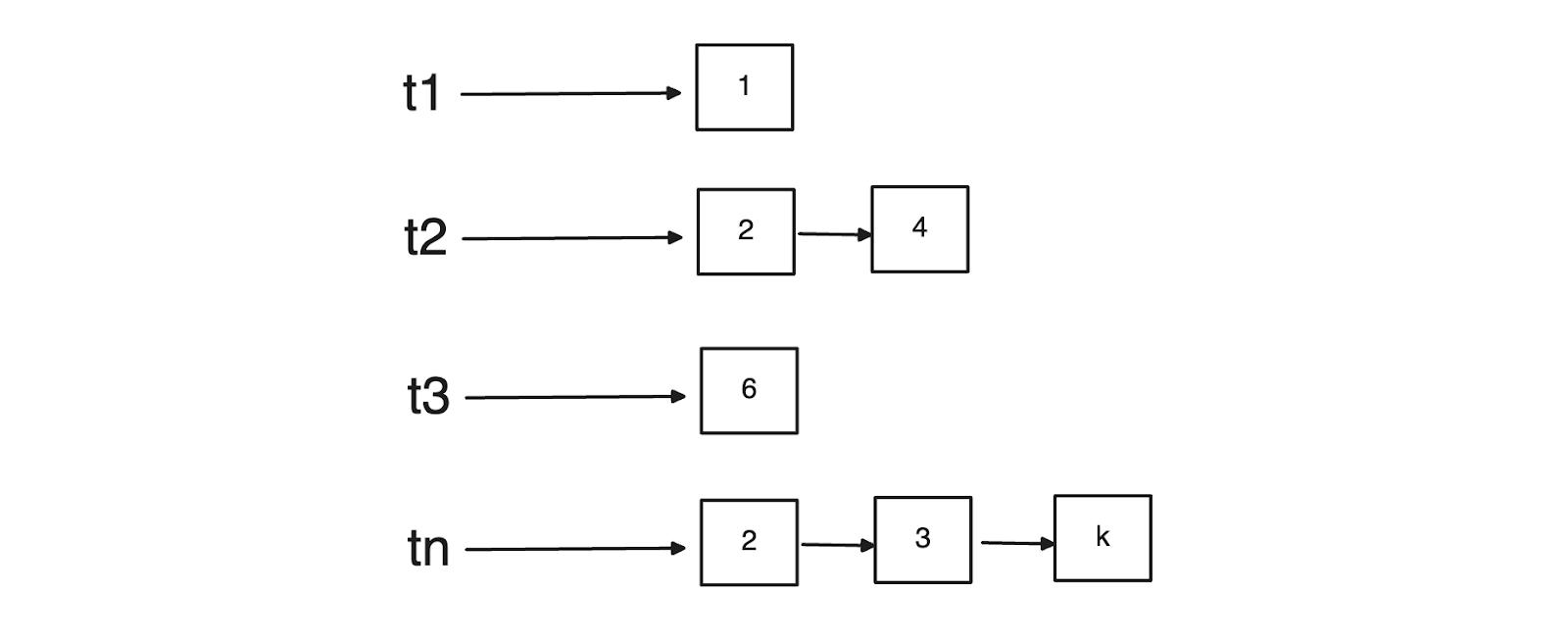 Figure 5- Posting list examples
Figure 5- Posting list examples
The first step in creating this posting list is preprocessing our input documents. Let's say our documents consist of texts. We begin by preprocessing and cleaning those texts, which includes methods like tokenization, normalization, lemmatization, and stopword removal. Once we've done that, we can start building the inverted index.
Let's build an inverted index with an example to make things easier to understand. Suppose we have two documents that contain the following words:
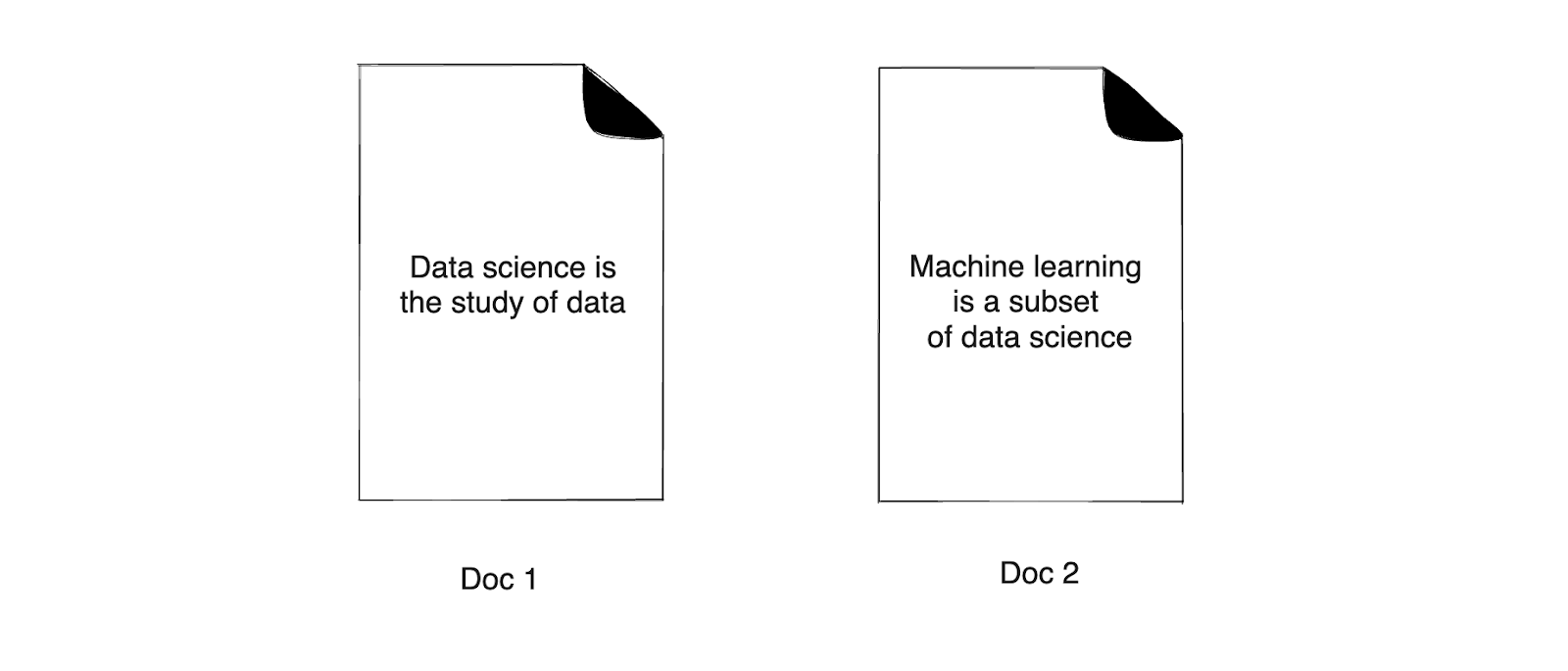 Figure 6- Example documents
Figure 6- Example documents
After cleaning the texts in the above two documents, we'll end up with the following:
Document 1: data science study data
Document 2: machine learning subset data science
The inverted index method will then create a list of term-document IDs as follows:
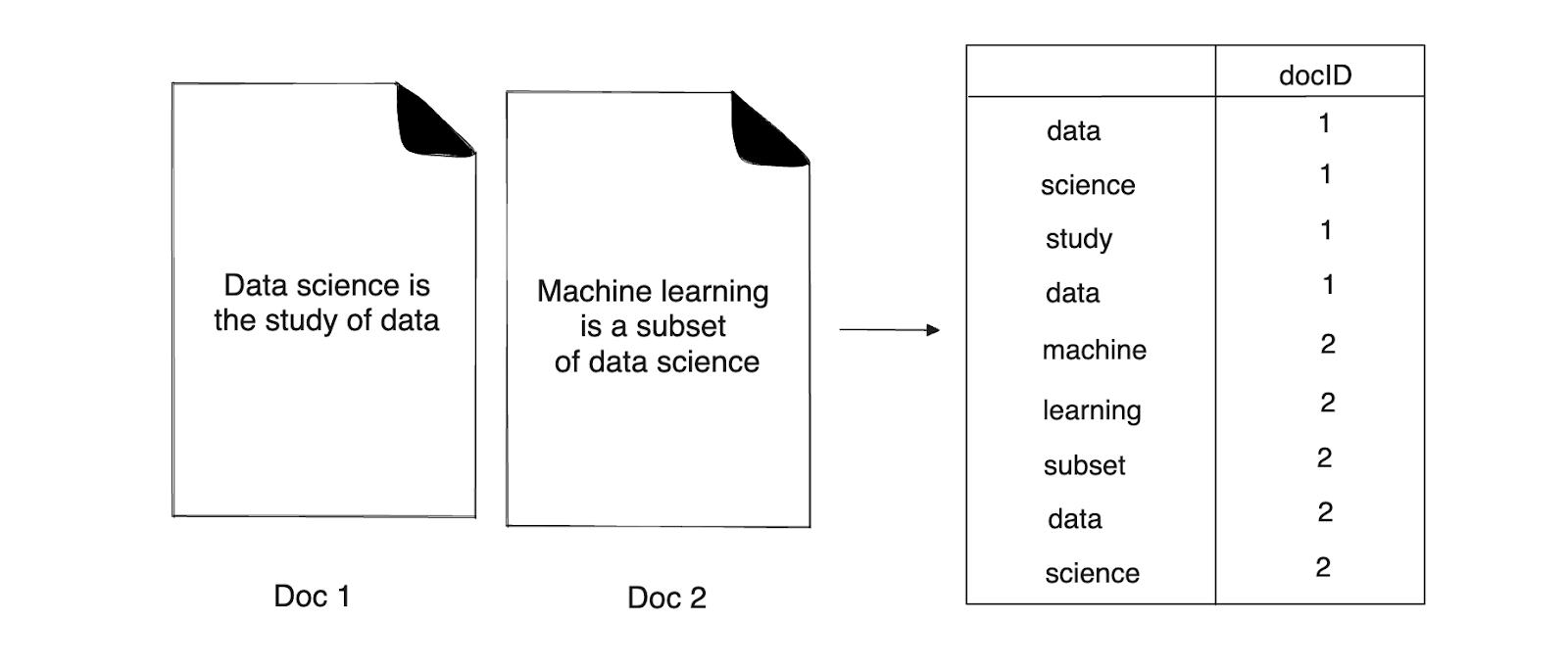 Figure 7- Documents to term-docID list
Figure 7- Documents to term-docID list
Next, we sort the terms alphabetically. If the same term appears in multiple documents, we sort them based on the document ID. Then, we create a posting list for each term that contains the document IDs in which the corresponding term is present.
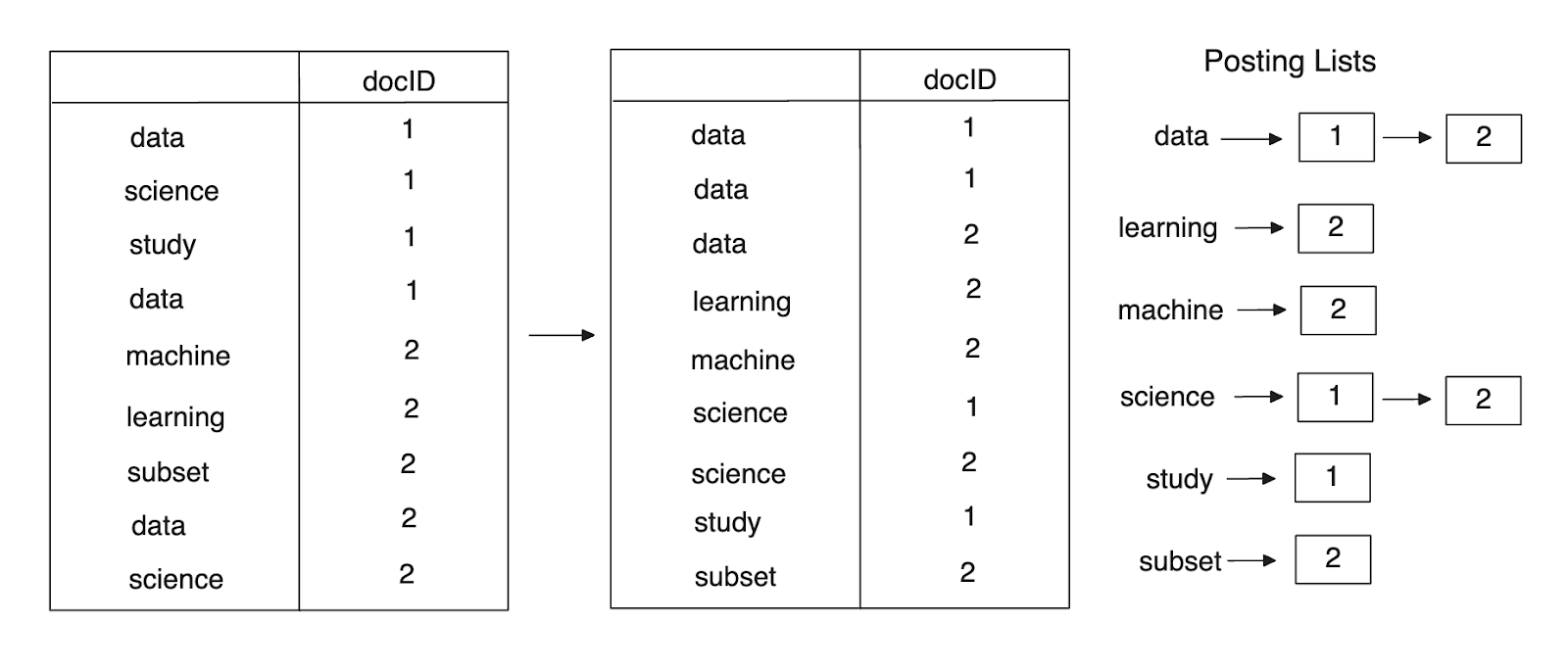 Figure 8- Posting lists creation from sorted terms-docID list
Figure 8- Posting lists creation from sorted terms-docID list
Now, we're ready to perform query processing. When retrieving based on a query, the first step is to parse the query to understand its structure and the operators that need to be checked (AND, OR, NOT). Then, operators are executed in order of precedence. Generally, NOT is processed first, followed by AND and OR to optimize the speed and efficiency of information retrieval.
Let's say we have a query, "data AND learning." The query will be parsed first, identifying the AND operator. Then, it will retrieve the linked lists of terms "data" and "learning" from the inverted index. Since the operator is AND, it will find the intersection of both posting lists, which in our case is document 2. Therefore, document 2 will be returned to the user.
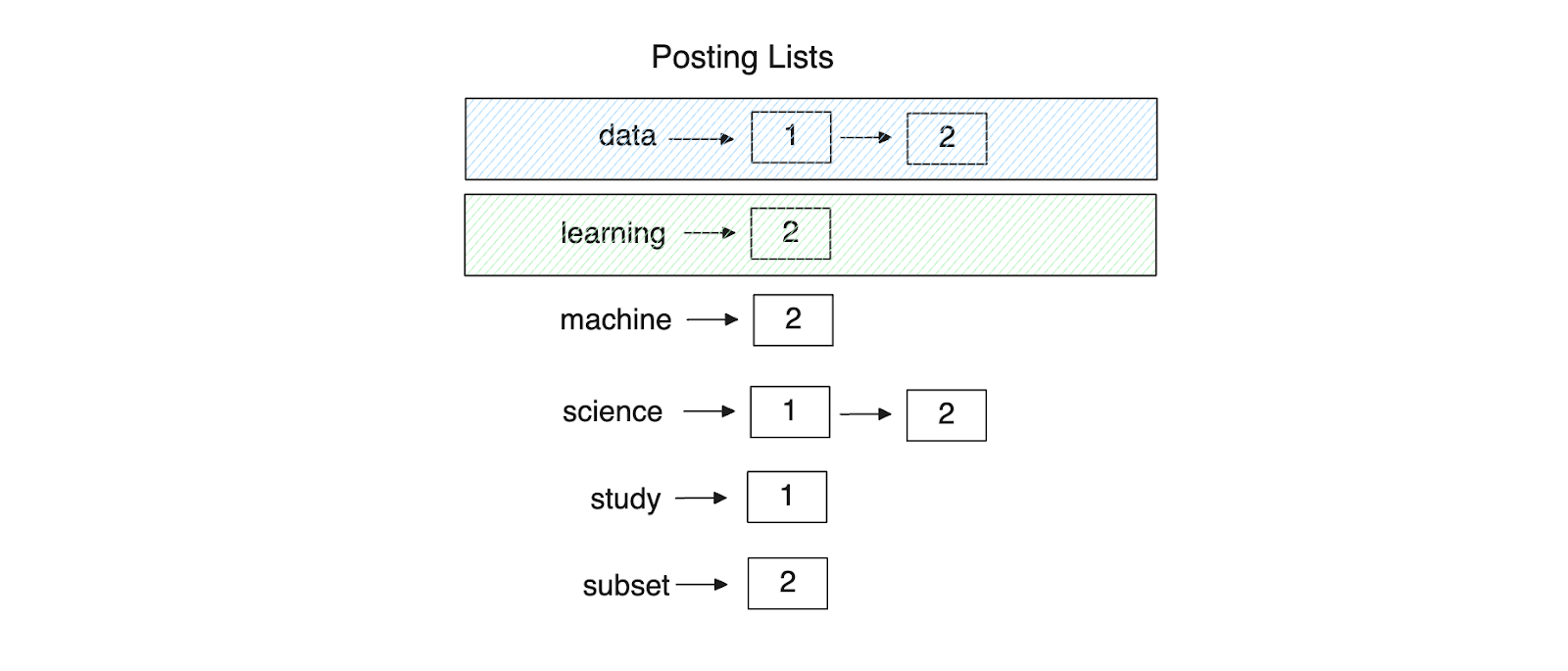 Figure 9- Retrieved posting lists for a given query
Figure 9- Retrieved posting lists for a given query
Advantages and Limitations of the Boolean Retrieval Model
Just like any other method, the Boolean retrieval model has its advantages and limitations. Therefore, whether or not this method would be useful depends entirely on your use case. Below are some advantages that this method can offer:
Simplicity and efficiency: This method is based on a simple Boolean concept that is easy to understand and implement.
User control over retrieval results: You can fine-tune your search results by adjusting the Boolean operators and terms. In other words, you have total control over the retrieval results.
Efficiency in processing straightforward queries: Boolean queries can be processed quickly, especially with the implementation of the inverted index described above. The system only needs to check whether documents match the specified Boolean conditions.
However, the Boolean retrieval model also has its limitations, such as:
No inherent ranking of results based on relevance: Boolean retrieval simply determines whether a document matches the query criteria or not. It doesn't provide a way to order the results based on how well they match the query or their potential relevance to the user's needs.
The need for users to understand Boolean logic and operators: Not all users are familiar with Boolean logic, which can create a barrier to effectively using these systems. This limitation often requires user training or the implementation of user-friendly interfaces that abstract the complexity of Boolean queries.
The binary nature of Boolean retrieval (document is either relevant or not) can lead to a lack of nuanced results. The core concept of this model is based on exact term matches, which means that we might get retrieval results that are not semantically similar to our query.
Applications of Boolean Retrieval Model in Modern Retrieval Systems
Although the core concept of the Boolean retrieval model is quite simple, it's still widely implemented in today's applications. During the information retrieval process, it's often combined with more advanced methods like the vector space model.
The vector space model is another information retrieval method where documents and queries are represented as vector embeddings. To convert each document into a vector embedding, we can use a wide variety of embedding models such as those from OpenAI, HuggingFace, Voyage AI, Sentence Transformers, and others.
These embeddings carry the semantic meaning of the documents they represent, and therefore, this method can retrieve results that are semantically similar to our query. This is the capability that a Boolean retrieval model lacks.
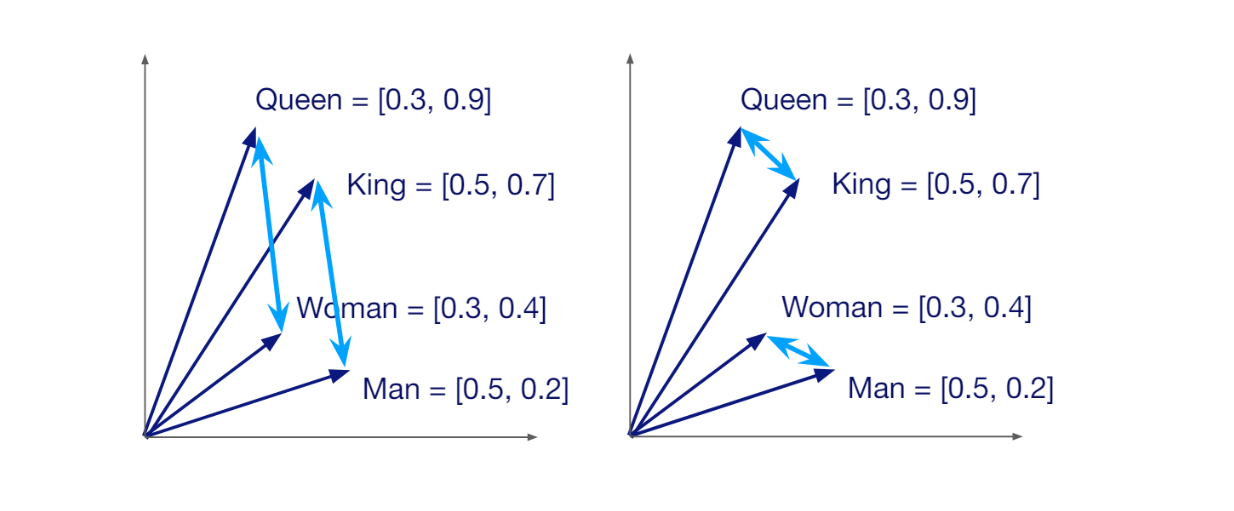 Figure 10- Vector embeddings in 2D vector space
Figure 10- Vector embeddings in 2D vector space
When we combine a Boolean retrieval model with a vector space model, we typically refer to this approach as a hybrid retrieval system. In this section, we'll implement a hybrid retrieval system with the help of Milvus, an open-source vector database that enables us to store and retrieve relevant documents in a split second.
Let's start by installing Milvus. The easiest way to install Milvus is through Milvus Lite, which can be done by executing the following pip command:
!pip install pymilvus
!pip install pymilvus [model]
Suppose we have product data and the corresponding color, as you can see below:
product_color = ['blue','green','blue', 'white']
product_title = ['Toilet Seat Bumpers', 'Headset Apple', 'Headset JBL ', 'Headset Sony']
Now, we need to transform each product title into vector embedding using an embedding model. To do so, we’ll use a sentence Transformers model that has been integrated into Milvus.
from pymilvus import model
sentence_transformer_ef = model.dense.SentenceTransformerEmbeddingFunction(
model_name='all-MiniLM-L6-v2', # Specify the model name
device='cpu' # Specify the device to use, e.g., 'cpu' or 'cuda:0'
)
product_title_vector = sentence_transformer_ef.encode_documents(product_title)
Next, let’s store all the data, i.e. product ID, product title, product title vector, and color, into our vector database. We can finish this process in only a few lines of code with Milvus Lite:
from pymilvus import MilvusClient
client = MilvusClient("./milvus_demo.db")
client.create_collection(
collection_name="product_color_collection",
dimension=384 # The vectors we will use in this demo has 384 dimensions
)
data = [ {"id": i, "vector": product_title_vector[i], "color": product_color[i], "title": product_title[i]} for i in range(len(product_title_vector)) ]
res = client.insert(
collection_name="product_color_collection",
data=data
)
And now we’re ready to perform an information retrieval process.
Let’s say that we have the following query: “Find me a product that I can use to listen to music.”, then we can retrieve relevant products with a vector space model, as you can see below:
query = "Find me a product that I can use to listen to music"
query_vector = sentence_transformer_ef.encode_queries([query])
res = client.search(
collection_name="product_color_collection",
data=query_vector,
limit=5,
output_fields=["title", "color"],
)
print(res)
"""
Output:
data: ["[{'id': 1, 'distance': 0.3618576228618622, 'entity': {'color': 'green', 'title': 'Headset Apple'}}, {'id': 3, 'distance': 0.3233926296234131, 'entity': {'color': 'white', 'title': 'Headset Sony'}}, {'id': 2, 'distance': 0.2899249494075775, 'entity': {'color': 'blue', 'title': 'Headset JBL '}}]"]
"""
The information retrieval with the vector space model above will give us a list of headsets with different brands. However, we can narrow the result and make it more specific with a Boolean retrieval model.
With a Boolean retrieval model, we can also ask the system to give us a product with a specific set of colors. In the following query, we would also like the system to return a relevant product with either white or green color.
res = client.search(
collection_name="product_color_collection",
data=query_vector,
filter='(color == "green") or (color == "white")',
limit=5,
output_fields=["title", "color"],
)
print(res)
"""
Output:
data: ["[{'id': 1, 'distance': 0.3618576228618622, 'entity': {'color': 'green', 'title': 'Headset Apple'}}, {'id': 3, 'distance': 0.3233926296234131, 'entity': {'color': 'white', 'title': 'Headset Sony'}}]"]
"""
And now it excludes the headsets in blue, leaving us with the ones in green and white!
As you can see, the Boolean retrieval method still plays an important role in modern information retrieval systems, as it allows us to gain full control over the output. We can further refine the retrieval results with the Boolean retrieval model if we want the output to have specific metadata, like color, size, or material.
Conclusion
The Boolean retrieval model is an information retrieval method that uses a set of Boolean logic operators, such as AND, OR, and NOT, in its operation. The AND operation retrieves all documents that contain all terms in our query. The OR operation retrieves all documents that contain any of the terms in our query, while the NOT operation excludes all documents that contain a specific term in our query.
The Boolean retrieval model utilizes an inverted index approach to speed up and improve the retrieval process. This approach stores all documents that contain a specific term as a posting list, so we don't need to create a term-document matrix that would scale poorly as the number of terms and documents grows. Nowadays, the Boolean retrieval model is commonly used with other more advanced information retrieval systems, such as the vector space model.
Further resources

- The Importance of Information Retrieval
- How Information Retrieval Systems Work
- The Concept of Boolean Retrieval Model
- Inverted Index in Boolean Retrieval Model
- Advantages and Limitations of the Boolean Retrieval Model
- Applications of Boolean Retrieval Model in Modern Retrieval Systems
- Conclusion
- Further resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

What is Information Retrieval?
Information retrieval (IR) is the process of efficiently retrieving relevant information from large collections of unstructured or semi-structured data.

Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
Milvus enables hybrid sparse and dense vector search and multi-vector search capabilities, simplifying the vectorization and search process.

What is a Knowledge Graph (KG)?
A knowledge graph is a data structure representing information as a network of entities and their relationships.