




バイナリ量子化とMilvusによるベクトル検索の効率化
バイナリ量子化は、Milvusにおけるベクトルデータの管理および検索に対する革新的なアプローチであり、パフォーマンスと効率の両方において大幅な向上をもたらします。ベクトル表現をバイナリコードに単純化することで、ビット演算の速度を活用し、検索操作を大幅に高速化し、計算オーバーヘッドを削減します。
シリーズ全体を読む
- Raft or not? The Best Solution to Data Consistency in Cloud-native Databases
- Understanding Faiss (Facebook AI Similarity Search)
- Information Retrieval Metrics
- Advanced Querying Techniques in Vector Databases
- Popular Machine-learning Algorithms Behind Vector Searches
- Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
- Ranking Models: What Are They and When to Use Them?
- Navigating the Nuances of Lexical and Semantic Search with Zilliz
- Enhancing Efficiency in Vector Searches with Binary Quantization and Milvus
- Model Providers: Open Source vs. Closed-Source
- Embedding and Querying Multilingual Languages with Milvus
- An Ultimate Guide to Vectorizing and Querying Structured Data
- Understanding HNSWlib: A Graph-based Library for Fast Approximate Nearest Neighbor Search
- What is ScaNN (Scalable Nearest Neighbors)?
- Getting Started with ScaNN
- Next-Gen Retrieval: How Cross-Encoders and Sparse Matrix Factorization Redefine k-NN Search
- What is Voyager?
- What is Annoy?
#はじめに
今日のデータ駆動型の世界では、特に高次元のベクトルデータに関しては、膨大なデータセットを扱い、検索する際の効率が重視される。このような状況を救うために登場した手法がバイナリ量子化である。これは、すべての要素を0か1の2進数にすることで、ベクトルの保存と操作を簡素化するものだ。データの複雑さとサイズを小さくすることで、処理速度が向上し、ストレージ効率も改善される。
Milvusはスケーラブルなベクトル・データベースであり、特に大規模なベクトル・データセット内の効率的な類似性検索を促進するように設計されている。現在、Milvusはバイナリ量子化をサポートしていませんが、効率的なバイナリインデックスにより、量子化前のバイナリベクトルを非常に効果的に保存・利用することができます。このインデックス機能は、大規模なベクトルデータセット内の類似検索の性能を大幅に向上させる。バイナリインデックスを使用することで、Milvusは検索時に浮動小数点ベクトルに必要な演算よりも計算量の少ない高速なビット演算を活用することができます。その結果、Milvusはより迅速かつ効率的に検索を実行することができ、迅速な応答時間が重要な大規模データセットを扱う環境において特に有益です。
出典:Dalle](https://assets.zilliz.com/Dalle_image_bffb964137.png)
ベクターデータベースと埋め込み
バイナリ量子化を復習する前に、ベクトル埋め込みについて簡単に説明しましょう。例えば、下の図は3つの異なるデータタイプを持っています:画像、テキスト、音声です。これらのモデルは、各データポイントを保存しやすい形式、この場合はベクトル/埋め込みに変換します。これは、1つのデータポイントを複数の特徴に分割し、各特徴に所定の値を与えることで行います。ベクトル・データベースの主な目的は、機械学習モデルによって生成されたベクトル埋め込みを扱うことである。
画像は著者による](https://assets.zilliz.com/Image_By_Author_f1594292ed.png)
ご想像の通り、ベクトルデータベースには、様々なタイプのデータや分析タスクに合わせた、多種多様なベクトル埋め込みを格納することができます。
バイナリ埋め込み
この記事の主な焦点の1つであるバイナリ埋め込みは、データをバイナリベクトルとして表現します。このタイプの埋め込みは、ストレージと計算速度の両方で高い効率を必要とするタスクに特に有用です。バイナリ埋め込みは、データ形式が単純なため類似度の計算が高速に行える情報検索システムでよく用いられます。
密な埋め込み
高密度エンベッディングは、各次元が連続値を含むベクトルでデータを表現します。これらのエンベッディングは、コンパクトな形で非常に多くの情報をキャプチャし、自然言語処理や画像認識などのタスクに非常に効果的です。密な埋め込みは、一般的にベクトルがほとんどの次元でゼロでない値を持ち、それによって各要素に豊富な情報が含まれていることから、そう呼ばれている。
スパース埋め込み
スパース埋め込みは、密な埋め込みとは対照的に、ゼロ値を多く含むベクトルが特徴です。これらの埋め込みは、本質的に次元が大きいが、ほとんどが空であったり、無関係であったりするデータを表現するのに効率的です。スパース埋め込みは、ある種の自然言語データやレコメンデーションシステムにおけるユーザとアイテムのインタラクションデータなど、少数の属性のみが重要な環境で有用です。このスパース性は、特にシステムがゼロ値をスキップできる場合、より効率的なストレージと処理につながります。
バイナリ量子化とは?
初期エンベッディングが提供された後、バイナリ量子化が便利になります。バイナリ量子化とは、簡単に言えば、与えられたベクトル(埋め込み)の各特徴を2進数に変換することです。
例えば、ある画像が3つの異なる特徴で表現され、各特徴がFLOAT-32の記憶単位の範囲の値を保持している場合、このベクトルに対して2進量子化を実行すると、3つの特徴のそれぞれが独立して1つの2進数で表現されることになります。従って、2進量子化の後、元々3つのFLOAT-32値を含んでいたベクトルは、[1, 0, 1]のような3つの2進数のベクトルに変換されます。
画像は著者による](https://assets.zilliz.com/Image_By_Author_2_c08e15e02e.png)
バイナリ量子化について理解したところで、このアプローチの長所と短所を探ってみましょう。このような処理の明確な欠点は、精度が失われることですが、ベクトル・データベースや検索システムに関しては、バイナリ・コードの方が、データのインデックス付けや検索が高速になります。
例えば、ハミング距離計算を使用すると、バイナリ・ベクトル間の類似性を迅速かつ効率的に利用することができます。このような計算は、浮動小数点数空間で距離を測定するよりもはるかに速く、計算量も少ないため、モデルの精度が多少低下するという欠点を軽減することができます。
高次元空間における厳密最近傍探索の課題は、「次元の呪い」に苦しむことです。データの次元が大きくなると、空間の体積は指数関数的に増大し、意味のある方法で距離を区別することがますます難しくなります。このため、計算量とメモリ要件が大幅に増加する可能性がある。
バイナリ量子化の利点
1.#### 高速化** 2.
バイナリ量子化は、膨大なデータセットに対してベクトル検索を行う際に高いパフォーマンスを発揮します。それはなぜか?簡単に言えば、計算が小さく複雑ではないからです。Milvusと2値ベクトルの場合、Milvusはハミング距離として知られる類似性メトリックを利用します。このメトリックは、2つの保存されたバイナリベクトル間の距離をごくわずかな時間で計算するために使用することができます。以下はハミング距離法の動作例である。
著者による画像](https://assets.zilliz.com/Image_By_Author_3_9b24ee44f0.png)
2.#### ストレージの削減とデータの効率化**. ストレージの削減とデータの効率化](https://assets.zilliz.com/Storage_Reduction_and_Data_Efficiency_96092694e7.png)
バイナリに変換することで、このベクトルのストレージ要件は96ビットからわずか3ビットに削減される。これは大幅な減少であり、事実上ストレージサイズを31倍以上削減できる。このような削減は、大規模なデータセットに適用すると大幅にスケールアップし、ストレージスペースと関連コストの大幅な節約につながるとともに、データ形式がシンプルになるため処理速度も向上する。この効率性は、ベクトル・データベースや大規模な分析業務など、膨大な量のデータを扱う環境において特に有益である。
バイナリ埋め込みをMilvusで実装する
1) 準備
この最初のステップは基本的なもので、標準的なデータエンジニアリングのプラクティスに沿ったものです。最初に、分析を歪める可能性のある破損したデータポイントや異常値データポイントを除去することで、データをクリーンにします。
次に、特徴選択を行い、最も関連性の高い特徴を特定する。これは次元を減らし、2値量子化の効率を高めるのに役立ちます。
次に、正規化を行います。これは、データを一様な範囲、典型的には[0,1]または平均ゼロ、単位分散を持つようにスケーリングすることです。これは、スケールによって単一の特徴が支配的にならないようにするために重要です。
量子化処理はこれらの予備ステップなしでも機能しますが、正しく実行されるとより簡単で効率的になります。
2)ベクトル変換
まず、ベクトルの各次元について閾値(x)を決めます。このしきい値以上のベクトル内の値は1に設定され、しきい値未満の値は0に設定される。
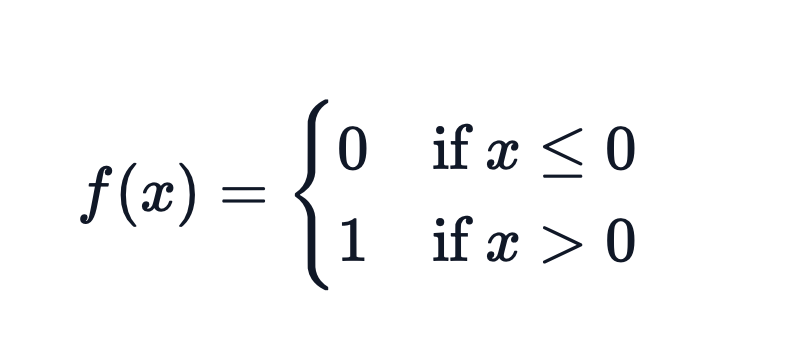
バイナリ量子化を手動で行うには、しきい値を0.5とした以下のコードを使うことができる:
| import numpy as np# Example datadata = np.array([0.85, 0.23, 0.76])# Setting a thresholdthreshold = 0.5# Binary quantizationbinary_data = np.where(data >= threshold, 1, 0)print(binary_data) | . |
ベクトルの各次元に対して適切な閾値を選択するために、一般的な方法では、データセット全体の各特徴の中央値(中間値)または平均値(平均値)を使用します。
選択された閾値がデータの構造の完全性を維持し、情報の損失を最小限に抑えることを保証することが重要である。
3) Milvusによるインデックス作成
ベクトルがバイナリになったら、Milvusを使ってインデックスを作成し、効率的な検索を行うことができます。
Milvusの検索機能を利用する前に、類似検索指標とともにインデックスタイプを宣言する必要があります。インデックスタイプが何を表すかご存じない方のために説明すると、インデックスはクエリのパフォーマンスを最適化するための特殊なデータ構造です。
バイナリインデックス型
インデックスタイプを選択することから始めましょう。バイナリベクトルの場合、MilvusはBIN_FLATやBIN_IVF_FLATなどのインデックスタイプをサポートしています。
BIN_FLATはバイナリデータのブルートフォース検索に適しており、BIN_IVF_FLATはファイルインデックスを反転させたもので、より大きなデータセットの検索効率を向上させることができます。
BIN_IVF_FLATを利用する場合、クラスタ数(nlist)のような他のメトリクスを指定する必要があります。
4)クエリ
最後に、Milvusにおけるバイナリベクタのクエリでは、類似性またはマッチングに基づく検索を設定し実行します。以下のコードでは、BIN_FLATインデックスを選択し、ハミング距離を類似度の指標として、インデックスの種類と指標を指定します。指定されたステップの詳細については、以下のMilvus documentationを確認してください。
ステップ1: Milvusインスタンスへの接続
このステップに進む前に、自分のMilvusインスタンスが作成されていることを確認してください。一旦それがセットアップされたら、MilvusClient()メソッドにあなたのサーバのURIを入力して接続を確立してください。
| -------------------------------------------------------------------------------------------------------------------- | | from pymilvus import MilvusClient# 1.Milvusクライアントをセットアップする client = MilvusClient( uri="http://localhost:19530") |.
ステップ2:ベクターDBスキーマ、検索インデックス、メトリックの設定
**スキーマを作成し、新しいフィールドを追加する。
| スキーマを作成し、新しいフィールドをスキーマに追加します。 |
**インデックスのパラメータを準備する。
| index_params = client.prepare_index_params() | インデックスパラメータを準備する。 |
**インデックスを追加する。
このセクションでは、ベクトルデータベース内でのバイナリ量子化の設定について概説します。ここでは、インデックスタイプを設定し、それに応じてメトリックタイプを設定します。この設定により、スキーマはデータをバイナリ形式で保存し、ハミング距離法を利用してベクトル間の距離を計算することができるようになります。
| index_params.add_index(field_name="my_id",metric_type="HAMMING",index_type="BIN_FLAT",params={"nlist":1024}) |
最後に、設定されたインデックス・パラメーターを使用して、最終的なコレクションを作成します。以下のスキーマパラメーターの詳細については、milvus documentationを参照してください。
| client.create_collection( collection_name="cities", schema=schema, index_params=index_params) |
ステップ3:ベクターデータベースへのデータ挿入
ドキュメントの例に従って、ランダムに生成されたベクトルを新しく作成したDBに挿入します。
| city = ["paris", "New York", "Cairo", "Tokyo"]data = [ {"id": i, "vector":[ random.uniform(-0, 1) for _ in range(5) ], "city": f"{random.choice(city)}_{str(random.randint(1, 5))}".} for i in range(5) ]res = client.insert( collection_name="cities", data=data) | . |
ステップ4:バイナリ単一ベクトル検索の実行
次に、検索を実行する。最初に、特定のベクトルをクエリとして送信します。バイナリベクトルを使用するので、Milvusデータベースは提供されたベクトルをバイナリ形式に変換します。その後、あらかじめ格納されている各ベクトルについてハミング距離を計算し、最も一致するベクトルが見つかるまでこの処理を続けます。
| # 単一ベクトル searchres = client.search( collection_name="cities", # 実際のコレクション名に置き換える # クエリベクトルに置き換える binary_vectors = [] data=binary_vectors.append(bytes(np.packbits([0,1,1,0,0,1], axis=-1).tolist())) limit=1, # 最大検索結果数 search_params={"metric_type":"HAMMING", "params":{}}# 検索パラメータ)# 出力をフォーマットされたJSON文字列に変換result = json.dumps(res, indent=4)print(result) | . |
出力
| [ { "id":2, "distance":1, "entity":{} } ]] |
上記の結果は、私のベクトルデータベースで最も類似したインデックスと、私の元のベクトルクエリに対するベクトルのハミング距離を返します。
ベンチマーク分析と推奨使用法
バイナリ量子化はデータ計算を簡略化することで検索速度を向上させますが、バイナリコードでは元データのニュアンスを完全に捉えられない可能性があるため、精度を損なう可能性があります。これは、システムがすべての関連ベクトルを検索する能力が低下し、再現率に影響を与える「再現率の低下」につながることがよくあります。
最適なスピードと精度のバランスを見つけることは困難ですが、ユーザーは許容できるスピードと精度の明確なベンチマークを定義し、構成がニーズに合っているかどうかを判断する必要があります。このバランスの重要性は、ベクトルデータベースの特定の用途に依存します。シナリオによっては、わずかな精度の低下も許容できないものもあれば、わずかなデータのずれが結果に大きな影響を与えないものもあります。
結論
バイナリ量子化は、Milvus におけるベクトルデータの管理および検索において、パフォーマンスと効率性の両面で大幅な向上をもたらす革新的なアプローチです。ベクトル表現をバイナリコードに単純化することで、この方法はビット演算の速度を活用し、検索操作を大幅に高速化し、計算オーバーヘッドを削減します。
これらの改善は、大規模なデータセットを扱い、リアルタイム応答機能を必要とするアプリケーションにとって極めて重要です。従って、膨大なデータを扱うアプリケーションや、迅速なデータ検索を必要とするアプリケーションでは、Milvusのバイナリ量子化機能の利用をご検討ください。
今後の方向性
バイナリ量子化がMilvusのようなベクトルデータベースの中で発展し続けるにつれて、ベクトル検索タスクをさらに洗練させ、向上させる数々の進歩や革新が期待できます。そのような機能強化のひとつに、二値量子化のための適切な閾値を設定するプロセスの改良があります。さらに、リアルタイムのデータ解析とフィードバックループに基づいて、これらの閾値を自動的に調整・最適化できる、より洗練された機械学習アルゴリズムの実装が期待される。これにより、2値表現の精度が向上するだけでなく、探索操作の全体的な効率も向上する。

読み続けて

ベクターデータベースにおける高度なクエリー技術
ベクトルデータベースは、ANN、マルチベクトル、範囲検索などの高度なクエリ技術によってAIアプリケーションを強化し、データ検索の速度と精度を向上させる。

モデルプロバイダーオープンソースとクローズドソースの比較
この記事では、さまざまなプロバイダー、その長所と短所、それぞれの意味合いについて検証します。最後には、オープンソースとクローズドソースのプロバイダーのどちらを選ぶべきか、十分な情報を得た上で選択するための知識と理解が得られるでしょう。

Milvusによる多言語言語の埋め込みとクエリー
このガイドでは、MilvusとBGE-M3多言語埋め込みモデルを使用して、多言語言語をベクトル空間に埋め込むための課題、戦略、アプローチを探ります。