




情報検索メトリクス
情報検索メトリクスを理解し、これらのメトリクスを適用してシステムを評価する方法を学びます。
シリーズ全体を読む
- 筏か否か?クラウドネイティブデータベースにおけるデータ一貫性のベストソリューション
- Faiss(フェイスブックAI類似検索)を理解する
- 情報検索メトリクス
- ベクターデータベースにおける高度なクエリー技術
- ベクトル検索を支える人気の機械学習アルゴリズム
- ハイブリッド検索:テキストと画像を組み合わせて検索機能を強化
- ベクターデータベースの高可用性の確保
- ランキングモデル:ランキングモデルとは何か?
- Zillizでレキシカル検索とセマンティック検索を使いこなす
- バイナリ量子化とMilvusによるベクトル検索の効率化
- モデルプロバイダーオープンソースとクローズドソースの比較
- Milvusによる多言語言語の埋め込みとクエリー
- 構造化データのベクトル化とクエリの究極ガイド
- HNSWlibを理解する:高速近似最近傍探索のためのグラフベースライブラリ
- ScaNN(Scalable Nearest Neighbors)とは?
- ScaNNを始める
- 次世代検索:クロスエンコーダとスパース行列因子分解がk-NN検索を再定義する方法
- ボイジャーとは?
- 迷惑とは何か?
情報検索(IR)システムは、関連する入力クエリを使用して、広範で高密度なデータセットを横断するように設計されている。これらのシステムは、統計的アルゴリズムを使用して入力クエリと参照文書を照合し、ランキング・メトリクスを使用して最も関連性の高い情報を検索する。IRは、Googleのような一般的な検索エンジンで使用されている。また、会社関連の文書を検索するために、地域の組織にも導入されている。
導入前に、情報検索メトリクスを用いてIRシステムを適切に評価する必要がある。これらのメトリクスは、入力クエリと検索結果の検索関連性に基づいてIRシステムを判断します。このブログでは、主な情報検索メトリクスと、それらがIRシステムに対してどのように実装されているかについて説明します。
主な情報検索メトリクス
基本的な情報検索メトリクスには、以下のようなものがあります:
- 精度@k:Precision@k:検索された結果における真正性を評価する。検索クエリに関連する検索結果がいくつ返されたかを分析する。メトリクスに付加された「@k」は、評価中に分析された上位k個の結果を表します。例えば、Precision@5は、最初の5つの出力に対する精度を意味します。
- Recall@k**:Recallは、データベースに存在するすべての関連項目に対して返された関連項目の数を分析することで、IRシステムを評価します。kがデータセット全体と等しい場合、リコールは1になるため、top-kの値が大きく影響する。top-kの優先順位は、アプリケーションの要件に従って設定する必要がある。
- F1-Score@k:F1は精度と想起の調和平均である。F1-Score@k:F1はprecisionとrecallの調和平均であり、2つの指標のバランスをとり、上記の両方の評価が関連する場合に使用される。
これらのメトリクスは順序を意識せず、返された結果の順序を気にしません。
しかし、順位付けされたメトリクスは、検索された結果の順序に影響されます。よく使われるランキング・メトリクスには、次のようなものがあります:
- MAP(平均平均精度)**:MAPには2つの部分があります。まず、1つのクエリに対して、1からNまでの複数のkの値の平均精度を計算します。2つ目の部分は、全ての可能なクエリに対する平均精度を計算します。
- NDCG (Normalized Discounted Cumulative Gain)**:NDCGはデータベース内の各要素に関連する2つのランクを考慮する。最初のランクはユーザーが割り当てたもので、ユーザーのクエリに関連する要素に応じて高い値を持つ。IRシステムは2番目のランクを提供する。NDCGはグランドトゥルースとシステムが生成したランクを比較して評価する。
リコールとプレシジョンの理解
情報検索の文脈におけるRecallとPrecisionは、返された結果の関連性を直接的に分析する。両者は似たような働きをするが、スコープは異なる。精度は、結果セットで返された項目のみに基づいて検索システムを判断します。その計算式は

真陽性は、(kで定義された)サブセット内のすべての関連する結果であり、偽陽性は無関係である。10枚の画像からなるデータセットがあったとして、上位5件(k=5)を評価したいとする。このうち3つはクエリに関連しているが、2つは関連していない。このシステムの精度は
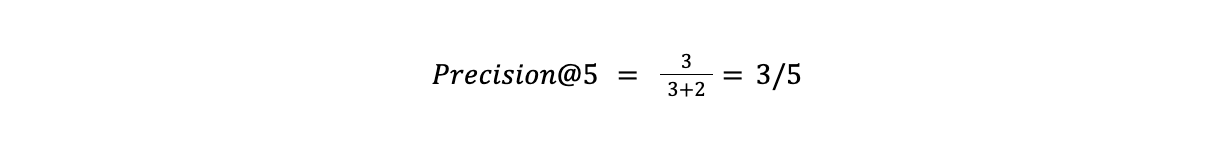
Recallは、データベースに存在するすべての関連する結果に基づいて、返された結果の関連性を評価します。その計算式は

式中の偽陰性は、最終的な結果セットに含まれなかったすべての関連項目を表している。先ほどの例の続きで、データセットの残りの部分に4つの関連する結果があった場合、そのリコールは次のようになります。
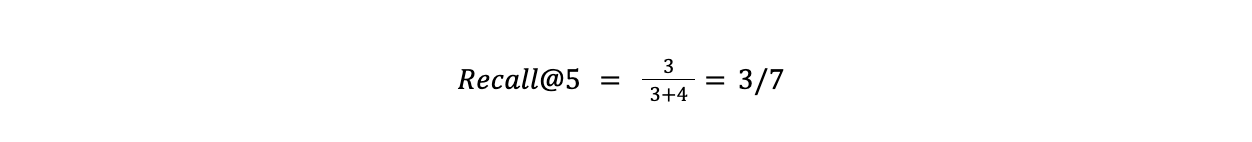
開発者はしばしば精度とリコールのトレードオフに直面する。精度は検索された真のラベルに基づいてシステムを示すのに対して、リコールは残された真のラベルを判断するため、両方のメトリクスは対照的です。効果的なIRシステムは、両方の妥当な値を表示する必要があります。
高度なメトリクス:NDCGとMAP
NDCGやMAPのような高度なメトリクスは、順序を意識します。つまり、メトリクス値は検索されたアイテムの順序によって影響を受けます。
MAP (平均平均精度)
MAPはその中核で精度メトリックを使用する。しかし、kの単一の値を使用する代わりに、MAPは異なるkの値に対して計算された複数の精度値の平均を取ります。
kを5とした場合、精度は1,2,3,4,5に対して計算され、平均して平均精度(AP)が得られます。しかし、ロバストな情報検索システムは、様々なユーザー入力に対して機能すべきである。MAPは複数のクエリに対してAPを計算し、すべての値の平均を取る。最終的なMAP値は、異なる入力に対するシステムの性能をよりよく表している。
NDCG (正規化割引累積利得)
NDCG は、データベースの各要素に関連付けられたグランド・トゥルース・ランクを使用する。ランクの範囲はユーザーが定義できる。例えば、「赤いスポイラーを付けた白いスポーツカー」というユーザークエリは、異なるレベルでそれに関連する複数の画像を持つことになる。説明文と一致する画像にはランク5が与えられ、まったく無関係な画像にはランク1が与えられるでしょう。部分的に説明文と一致する画像には、その中間のランク(2,3,4)が与えられます。
NDCGはまず、検索されたすべての画像のランクの合計を取る。この総和は、結果セットに関連画像が多く含まれていれば高くなるが、結果の順序に関係なく一定である。この結果に対して、対数ベースのペナルティを導入する。ペナルティ・ファクターは、各画像のランクを、その値と結果における配置に応じてペナルティを与える。最終セットで上位にランク付けされた、より低い値は、より多くのペナルティを受けます。こうすることで、無関係な画像を最初に出力した場合、システムはより低いスコアを受け取ることになる。
このメトリックの最後の問題は、スコアに上限がないことである。この問題は、最終スコアを正規化し、0から1の間に制限することで対策される。正規化は、まず理想的なシナリオ、つまりシステムがすべての関連画像を上位にランク付けした場合のスコアを計算することで行われる。次に、実際のスコアを理想で割って、最終的な正規化値を得る。
システムを評価するためのメトリクスの適用
IR メトリクスは、開発者レベルのテストと検索フレームワーク全体の改善のために、アプリケーションのデプロイ前に使用されます。 テスターは通常、事前に定義されたクエリとラベル付けされたドキュメントを使用して、IRシステムを自動的に評価するフレームワークを持っています。このフレームワークは、パフォーマンスの低いクエリをハイライトします。
情報検索の最も顕著な用途は、GoogleやBingのような検索エンジンである。これらのエンジンは、数十億のデータセットから関連文書を検索するために、統計的アルゴリズムとベクトル・データベースを使用する。評価指標は、入力クエリに応じて検索の関連性を改善し、ユーザーの満足度を向上させるのに役立つ。
結論
情報検索メトリクスは、ユーザーのクエリに対して文書を検索する統計アルゴリズムを評価します。これらの評価指標は、提供されたクエリに対する検索された文書の関連性をチェックする。評価指標には、順序を意識しないものと、順序を意識するものの2つのカテゴリーがある。
順序を意識しない評価指標には、Precision、Recal、F1-Scoreなどがあります。これらの評価指標は、検索された文書の順序を気にせず、最終的なサブセットの全体的な関連性だけに注目する。
順序を考慮するメトリクスにはMAPとNDCGがある。これらのランキング・メトリクスはやや高度で、複数の検索窓とクエリに対する評価を集約する。順序を考慮したメトリクスは検索順序も考慮し、関連性のない文書を関連性のある文書より上位にランク付けするシステムにはペナルティを与える。
この記事で説明したことは、氷山の一角に過ぎない。大企業では、より複雑な検索と評価のフレームワークを採用し、ロバストな検索メカニズムを構築している。ベクトル類似検索](https://zilliz.com/learn/vector-similarity-search)やベクトル・データベースなどの検索メカニズムをさらに探求し、現代の情報検索評価をより深く理解することをお勧めする。
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS


