




ベクターデータベースにおける高度なクエリー技術
ベクトルデータベースは、ANN、マルチベクトル、範囲検索などの高度なクエリ技術によってAIアプリケーションを強化し、データ検索の速度と精度を向上させる。
シリーズ全体を読む
- 筏か否か?クラウドネイティブデータベースにおけるデータ一貫性のベストソリューション
- Faiss(フェイスブックAI類似検索)を理解する
- 情報検索メトリクス
- ベクターデータベースにおける高度なクエリー技術
- ベクトル検索を支える人気の機械学習アルゴリズム
- ハイブリッド検索:テキストと画像を組み合わせて検索機能を強化
- ベクターデータベースの高可用性の確保
- ランキングモデル:ランキングモデルとは何か?
- Zillizでレキシカル検索とセマンティック検索を使いこなす
- バイナリ量子化とMilvusによるベクトル検索の効率化
- モデルプロバイダーオープンソースとクローズドソースの比較
- Milvusによる多言語言語の埋め込みとクエリー
- 構造化データのベクトル化とクエリの究極ガイド
- HNSWlibを理解する:高速近似最近傍探索のためのグラフベースライブラリ
- ScaNN(Scalable Nearest Neighbors)とは?
- ScaNNを始める
- 次世代検索:クロスエンコーダとスパース行列因子分解がk-NN検索を再定義する方法
- ボイジャーとは?
- 迷惑とは何か?
#はじめに
ベクターデータベースは、高次元のベクターデータを管理し、クエリを実行できるため、最新のAIや機械学習のワークフローにおいて極めて重要な役割を果たしている。この能力により、パーソナライズされたレコメンデーションや画像認識から自然言語処理に至るまで、様々なAIアプリケーションに不可欠な高速かつ正確な類似検索が可能になる。ベクトルデータベースは、このような操作を大規模に容易にすることで、AIアプリケーションのパフォーマンスと有効性を大幅に向上させ、スピードと正確性が不可欠な時代において、高次元データの処理に不可欠なものとなっています。
高度なクエリ技術は、データ検索のパフォーマンスを向上させることで、AIにおけるベクトルデータベースの有用性を大幅に高めます。マルチベクタークエリ、最近傍検索、スカラーデータフィルタリングなどの技術により、的を絞った効率的な検索が可能になり、AIアプリケーションの精度と有効性に直接影響を与えます。
ベクターデータベースの基礎
ベクトル・データベースはデータを高次元ベクトルで格納する。非構造化データを数学的に表現したもので、基礎モデルによって学習されたあらゆるもののベクトル空間内で、そのオブジェクトの「意味的意味」を捉える。そして開発者は、これらの埋め込みを類似検索、クラスタリング、その他のデータ検索タスクに使用する。ベクトルとは、いくつかの次元に沿った浮動小数点の位置を表す数値の配列である:
埋め込み:[array([-3.09392996e-02, -1.80662833e-02, 1.34775648e-02, 2.77156215e-02、
-4.86349640e-03, -3.12581174e-02, -3.55921760e-02, 5.76934684e-03、
2.80773244e-03, 1.35783911e-01, 3.59678417e-02, 6.17732145e-02、
...
-4.61330153e-02, -4.85207550e-02, 3.13997865e-02, 7.82178566e-02、
-4.75336798e-02, 5.21207601e-02, 9.04406682e-02, -5.36676683e-02]、
dtype=float32)]。
Dim: 384 (384,)
この例では、384次元の数値配列の一部を示しています。
これらのベクトル埋め込みにはオブジェクトの意味的な意味が含まれているため、一緒にクラスタ化されたベクトルは類似しており、互いに関連している可能性が高い。このため、ベクトル検索(意味的類似性検索とも呼ばれる)を中心に様々なユースケースが生まれ、あらゆるデータベースが採用したがる最もホットな機能の1つとなっている。サポートベクター埋め込みは一見簡単そうに見えますが、ストア、インデックス、クエリと見た目以上に複雑です。
高度なベクトル検索技術の概要
高度なクエリテクニックは、複雑なデータ検索ニーズに対応する可能性を解き放ちます。これらのテクニックは、ベクトル検索結果の質を高めるだけでなく、複雑なクエリによるデータ検索のパフォーマンスを向上させます。これらのテクニックのいくつかと、実際のアプリケーションをご紹介します。
近似最近傍(ANN)検索
ベクトル空間のすべてのベクトルをk個の完全一致が現れるまで比較することは、特に高次元のベクトルを持つ大規模なデータセットでは時間がかかる。その代わりに、より良いパフォーマンスを得るために近似探索を行います。そのためには、あらかじめインデックスを構築しておく必要がある。ベクトル探索アルゴリズムには一般に4つのタイプがある:
ハッシュベースのインデックス作成(例:Locality-sensitive hashing)
ツリーベースのインデックス(ANNOYなど)
クラスタインデックス(例:積量子化)
グラフベースの索引付け (例: HNSW、CAGRA)
様々なアルゴリズムが様々なタイプのベクトルデータに対してより効果的に働きますが、これらはすべて、精度/想起を少し犠牲にする代わりに、ベクトル検索プロセスのスピードアップに役立ちます。
ラージ・ランゲージ・モデル(LLM)はしばしば、ユーザーのクエリの背後にある根本的な意図を把握する能力を向上させる必要があり、無関係な結果をもたらす。しかし、ある企業が社内のドキュメントをベクトルに統合し、ベクトル・データベースに保存しているとしよう。このセットアップにより、従業員はANNクエリを使ってドキュメントを検索できる。ベクトル・データベースは、社員のクエリー埋め込みに最も近いデータ埋め込みを検索し、それをプロンプトとしてLLMに渡す。LLMは会社のデータに基づいて人間のようなテキスト回答を生成し、関連性を確保する。このプロセスはRAG(Retrieval Augmented Generation:検索拡張生成)と呼ばれ、社内検索の関連性を大幅に向上させ、会社の文書の意味理解を取り入れることでAIの幻覚を軽減する。
マルチベクター・クエリー
マルチベクタークエリーは、複数のベクターを同時に使用して検索できるようにすることで、ベクターデータベースのクエリー機能を拡張します。ほとんどの場合、マルチベクタクエリは、個々のシングルベクタクエリに対して検索するよりも待ち時間がはるかに短いため、シングルベクタクエリを実行するよりも効率的です。それ以外にも、マルチベクター・クエリーはより良いクエリー結果を提供することができる。
例えば、電子商取引サイトでは、マルチベクター・クエリによって、商品推薦システムを劇的に改善することができる。ユーザーの嗜好の異なる側面(例えば、ブランド嗜好、価格帯、製品カテゴリー、過去の購買履歴)を表す複数のベクトルを使用することで、これらのクエリは、ユーザーの複雑な嗜好により近い製品を検索することができ、ショッピング体験を向上させ、コンバージョン率を高める可能性がある。
レンジクエリ
範囲クエリは、クエリベクトルから指定された距離または類似度のしきい値内のすべてのアイテムを取得することができます。このテクニックは、単一の最も類似したアイテムを特定するのではなく、最小の類似性要件を満たすアイテムのセットを見つけることに重点を置くアプリケーションにとって重要である。
創薬は、数十原子の小さな分子から数万原子の大きな生物学的製剤に至るまで、膨大な課題を抱えている。開発者は、機械学習を活用して各分子をベクトル化し、特定の病気や症状をターゲットにするなど、意図された目的に合わせた機能的表現を作成することができる。
この枠組みの中では、範囲検索機能が適切である。従来のtop-k検索とは異なり、範囲検索は、ターゲットから指定された距離内にあるすべてのベクトル(分子)を特定することによってその範囲を広げ、固定数ではなく、関連する候補の包括的なリストを提示する。この機能は創薬に不可欠であり、不正検出やサイバーセキュリティのような多様な領域で応用可能である。
クエリの最適化
ベクトル・データベースにおける高度なクエリの最適化は、AIや機械学習アプリケーションにおいて高いパフォーマンスと精度を達成するために極めて重要である。この最適化により、システムが大量の高次元データを効率的に処理できるようになり、リアルタイムで適切なデータ検索が可能になります。以下に、これらのクエリを最適化するためのベストプラクティスをいくつか紹介する。
インデックス戦略
インデックスは、特にANNにおいて、クエリを高速化する上で重要な役割を果たします。全てのケースに対応できるインデックスタイプはありません。インデックス(例えば、ツリーベース、ハッシュベース、グラフベース)は、異なるクエリやデータ特性に対して最適化されます。例えば、KD-treesのようなツリーベースのインデックスは低次元のデータに適しており、グラフベースのインデックスは高次元のデータに適しています。
クエリ最適化戦略
分割
インデックス効率を向上させるために、データを戦略的に分割します。クラスタリングのような技術は、類似したベクトルをグループ化し、クエリの検索空間を縮小し、レスポンスタイムを改善します。
近似検索の使用
多くのアプリケーションでは、厳密な最近傍探索は不要であり、近似結果は精度にわずかな影響を与えるだけで、クエリ時間を大幅に短縮することができる。HNSW (Hierarchical Navigable Small World)やAnnoyのようなANNアルゴリズムはこの目的のために設計されています。
スピードと精度のバランス
インデックスの選択とインデックスのパラメータの調整
ベクターデータベースは、ユーザーが自分のニーズに最も適したインデックスを選べるように、どんなにシンプルで人気のあるインデックスであっても、1つ以上のインデックスをサポートする必要があります。インデックスを選択したら、次にインデックスパラメーターを調整し、次に検索パラメーターを調整します。
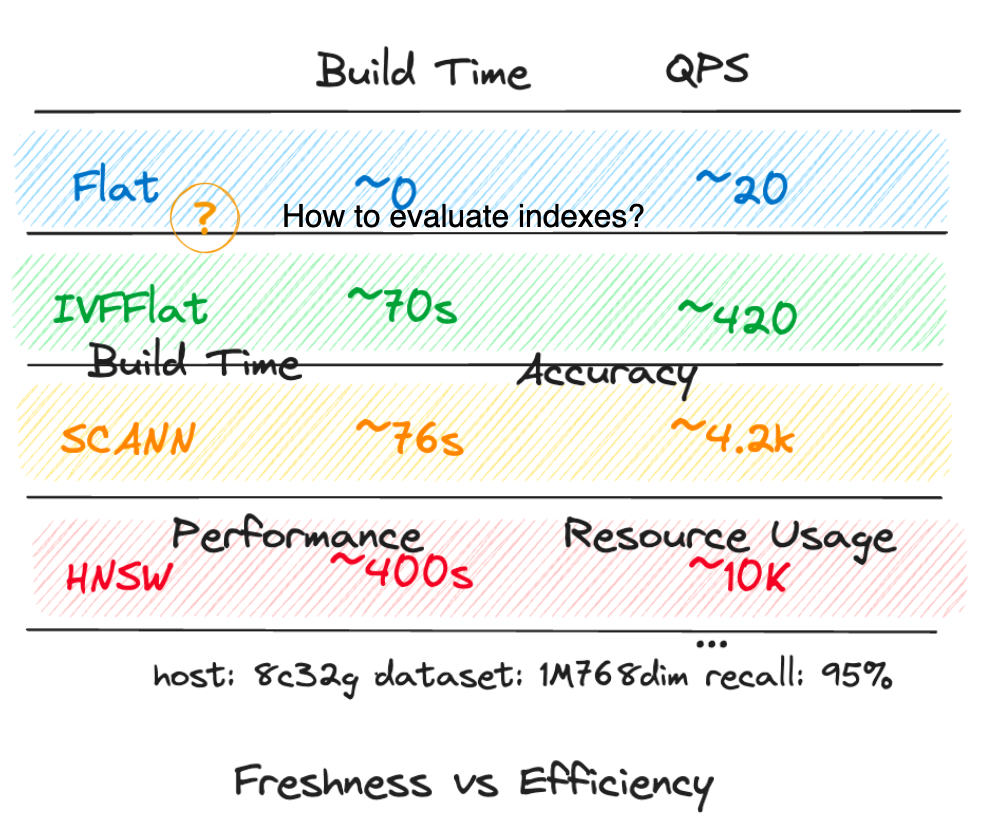
ほとんどのベクトルデータベースシステムとANNライブラリは、検索速度と精度のトレードオフを制御するパラメータを提供しています(例えば、検索の深さや森の木の数)。これらのパラメータを試してみることで、アプリケーションのニーズに最適なバランスを見つけることができます。
早期停止基準
検索アルゴリズムに早期停止を実装して、「十分な」結果が見つかった時点で検索プロセスを停止し、網羅的検索の計算オーバーヘッドを削減します。
サービス品質(QoS)レベル
クエリーやユーザーリクエストの種類によって異なる QoS レベルを定義します。たとえば、バックグラウンド・タスクでは、より遅く、より正確な検索が許容されるかもしれませんが、ユーザー向けのクエリでは、スピードが優先されるかもしれません。
高度なクエリの使用
高度なクエリを実行できるかどうかは、使用するベクターデータベースに依存します。詳しくは公式ドキュメントを参照してください。この例ではZilliz上のMilvusベクターデータベースを使用します。
res = client.search(
collection_name=COLLECTION_NAME、
data=[data["rows"][0]["title_vector"]],
filter='publication not in ["Towards Data Science", "Personal Growth"]'、
output_fields=["title", "publication"]、
limit=5
)
print(res)
上記のクエリーは、ANNを使用したフィルターでクエリー検索を実行します。この例では、"Towards Data Science "と "Personal Growth "以外の出版物を除外しています。
課題と解決策
ベクターデータベースに高度なクエリーを実装するには、独特の課題があります。ここでは、よくある課題と実践的な解決策を紹介します。
スケーラビリティ
データセットが大きくなるにつれて、クエリのパフォーマンスを維持することがビッグデータ最適化の課題になります。幸い、ベクターデータベースをスケーラブルにするための様々なテクニックがある。その1つが、負荷を分散し並列処理を活用するデータベースパーティションの使用です。ベクターデータベースは分散する必要があるため、Google CloudやAWS、あるいはZilliz Cloudのような確立されたクラウドコンピューティングプラットフォームを使用してデータベースを管理するのがよいでしょう。
次元削減
高次元のデータは、類似検索のパフォーマンスが低下する「次元の呪い」につながる可能性があります。PCA(主成分分析)やオートエンコーダのような次元削減テクニックを使えば、重要な情報を失うことなくデータセットの次元を削減し、インデックス作成をより効果的にすることができる。
動的データ
クエリのパフォーマンスを低下させることなく、ベクトルデータベースを新しいデータで更新し続けること。この問題を解決するには、完全な再構築を必要とせずに定期的に新しいベクトルをインデックスに追加するインクリメンタルインデックス戦略を実装します。
クエリの将来動向
ベクターデータベースにおけるクエリの将来は、主に大規模な言語モデルの統合を通じたAIの進歩に影響されるだろう。新たなテクノロジーによって強化されたこれらの進歩は、膨大なデータセットに対するより高速で効率的な検索とリアルタイムの分析を約束します。LLMとベクトルデータベースの相乗効果により、より直感的で強力なデータ探索ツールが生まれ、データとの関わり方やデータからの価値の引き出し方に革命をもたらすでしょう。
結論
高度なクエリ技術は、ベクトルデータベースの可能性を最大限に引き出すための基本である。これらのクエリ機能を活用することで、企業はデータをより深く掘り下げ、以前は手の届かなかった洞察を発見することができる。これらのテクニックは、正確で効率的、かつコンテキストを考慮したデータ検索を可能にします。これらの技術は、膨大な量の高次元データを迅速かつ正確に処理・分析する能力が成果を大きく左右する、最新のAIや機械学習ワークフローの微妙な要求に応えます。
この急速に進化する状況において、高度なクエリ技術に関する知識とスキルの向上を追求することは、継続的な努力であるべきだ。継続的な学習と実験を奨励することは、単に技術の進歩に遅れを取らないということではなく、複雑な問題に対する斬新な解決策を先導することなのである。好奇心と革新の文化を育むことで、個人も組織も、データ主導のプロジェクトにおいて、高度なクエリをツールとして、また変革の触媒として活用することができる。 テキスト



