




HNSWlibを理解する:高速近似最近傍探索のためのグラフベースライブラリ
HNSWlib は、高速な近似最近傍探索に使用される HNSW アルゴリズムのオープンソース C++ および Python ライブラリ実装です。
シリーズ全体を読む
- 筏か否か?クラウドネイティブデータベースにおけるデータ一貫性のベストソリューション
- Faiss(フェイスブックAI類似検索)を理解する
- 情報検索メトリクス
- ベクターデータベースにおける高度なクエリー技術
- ベクトル検索を支える人気の機械学習アルゴリズム
- ハイブリッド検索:テキストと画像を組み合わせて検索機能を強化
- ベクターデータベースの高可用性の確保
- ランキングモデル:ランキングモデルとは何か?
- Zillizでレキシカル検索とセマンティック検索を使いこなす
- バイナリ量子化とMilvusによるベクトル検索の効率化
- モデルプロバイダーオープンソースとクローズドソースの比較
- Milvusによる多言語言語の埋め込みとクエリー
- 構造化データのベクトル化とクエリの究極ガイド
- HNSWlibを理解する:高速近似最近傍探索のためのグラフベースライブラリ
- ScaNN(Scalable Nearest Neighbors)とは?
- ScaNNを始める
- 次世代検索:クロスエンコーダとスパース行列因子分解がk-NN検索を再定義する方法
- ボイジャーとは?
- 迷惑とは何か?
ベクトル検索は、ベクトル類似性検索とも呼ばれ、現代のAIにおいて最も重要なテクニックの1つである。レコメンデーションシステムを構築するにしても、Retrieval Augmented Generation (RAG)のような高度なGen AIアプリケーションを構築するにしても、その過程で必ずベクトル検索を行う必要がある。
他の要因の中でも、ベクトル検索で最も重要な点は、精度と速度である。精度は、クエリに基づいて最も関連性の高い結果を確実に得るために必要であり、速度は、これらの結果を迅速に得るために必要である。k-最近傍(k-Nearest Neighbors)アルゴリズム(kNN)は、ベクトル検索で最も一般的に実装されている方法です。その名が示すように、kNNではクエリに最も近いデータポイントが最も関連性の高い結果として選択されます。しかし、このアルゴリズムの主な問題は、特に数百万のデータポイントを扱う場合のスピードです。
この記事では、HNSWlibと呼ばれるベクトル検索ライブラリについて説明します。このライブラリはHNSWと呼ばれるアルゴリズムを実装しており、ベクトル探索をより効率的に行うことができます。HNSWlibについて詳しく説明する前に、まずベクトル探索とは何かを学びましょう。
ベクトル探索入門
ベクトル検索とは、情報検索 でよく使われる手法で、 構造化されていない大量のデータ (画像、文書、音声など) から、 与えられたクエリに最も類似した情報を探し出すものです。その名が示すように、文書とクエリの両方は、高次元ベクトル空間において特定の次元を持つベクトルとして表現される。ベクトルの次元は、文書とクエリの変換に使われる埋め込みモデルに依存する。例えば、埋め込みモデルとして"all-MiniLM-L6-v2 "を使用すると、各クエリや文書に対して384次元のベクトルが得られます。
すでにご存知かもしれませんが、埋め込みモデルによって生成されるベクトルには、それが表現する文書の意味的な意味が含まれています。そのため、下の2D可視化でわかるように、似たような文書のベクトルはベクトル空間内で互いに近接して配置されます:
2次元ベクトル空間における類似語埋め込みベクトル.png](https://assets.zilliz.com/Vector_embeddings_of_similar_words_in_a_2_D_vector_space_e9fc58083f.png)
図:2次元ベクトル空間における類似語のベクトル埋め込み。
与えられたクエリに対して最も類似した文書を見つけるには、クエリベクトルと文書コレクション内のすべてのベクトルとの間の類似度または距離を計算すればよい。そして、クエリーベクトルとの類似度スコアが最も高い(または距離が最も小さい)文書ベクトルを、最も類似した文書として選ぶ。これがベクトル検索の直感です。
k-最近傍(kNN)検索はベクトル検索における基本的な操作であるが、大規模なデータセットを総当たり的な線形スキャンとして実行すると、計算コストが高くなる可能性がある。kNN検索のパフォーマンスを最適化するために、様々なインデックス作成アルゴリズムが開発されており、HNSW(Hierarchical Navigable Small World)は最も効果的なアルゴリズムの一つである。基本的なkNN検索がどのように機能するのかを検証してから、HNSWがどのようにkNN検索をより効率的にするのか、特に大規模なアプリケーションについて検証してみよう。
k-最近傍探索(kNN)の簡単な紹介
ベクトル検索を行う際、kNNアルゴリズムは、データベース内の各文書ベクトルとクエリベクトルの類似度を計算する。メモリ上に100個の文書がある場合、kNNアルゴリズムは100個の文書ベクトルそれぞれとクエリベクトルの類似度または距離を計算する。言い換えれば、kNNアルゴリズムは網羅的検索を行うため、正確なベクトル検索結果が保証されます。
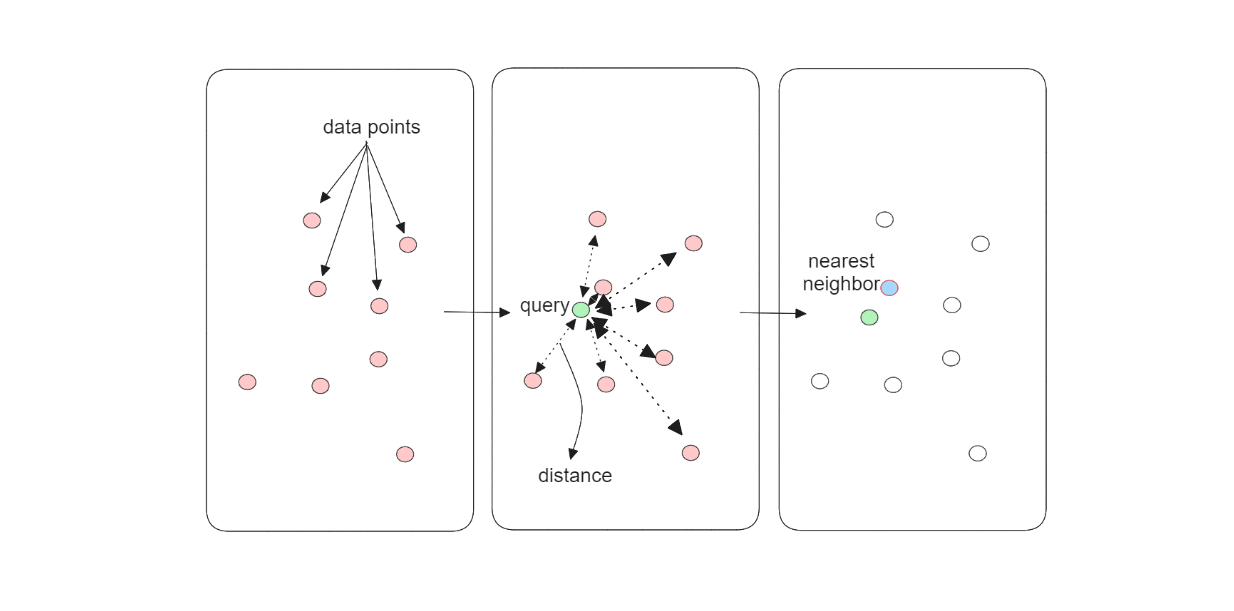 kNNアルゴリズムのワークフロー...png
kNNアルゴリズムのワークフロー...png
図:kNNアルゴリズムのワークフロー._.
しかし、kNNアルゴリズムが実行する網羅的探索には明らかな欠点がある:スピードである。このアルゴリズムによるベクトル探索操作の時間複雑性は、メモリに保存されている文書数に応じて線形に増大する。メモリ内の文書数が多ければ多いほど、ベクトル探索操作の完了にかかる時間は長くなる。この欠点は、何百万もの文書が蓄積されればされるほど明らかになる。
HNSW** (Hierarchical Navigable Small Worlds)は、この問題を解決するために考案された高度なベクトル検索手法のひとつである。次節では、このアルゴリズムがベクトル検索操作の速度と精度のバランスをどのようにとることができるかを見ていこう。
HNSW財団としての##スキップリストとNSW
HNSWはグラフベースのベクトル探索アルゴリズムであり、高速なベクトル探索を可能にする。これは2つの重要なコンセプトに依存しています:**したがって、HNSWアルゴリズムがどのように機能するかを理解する前に、この2つの概念の基礎を理解する必要があります。
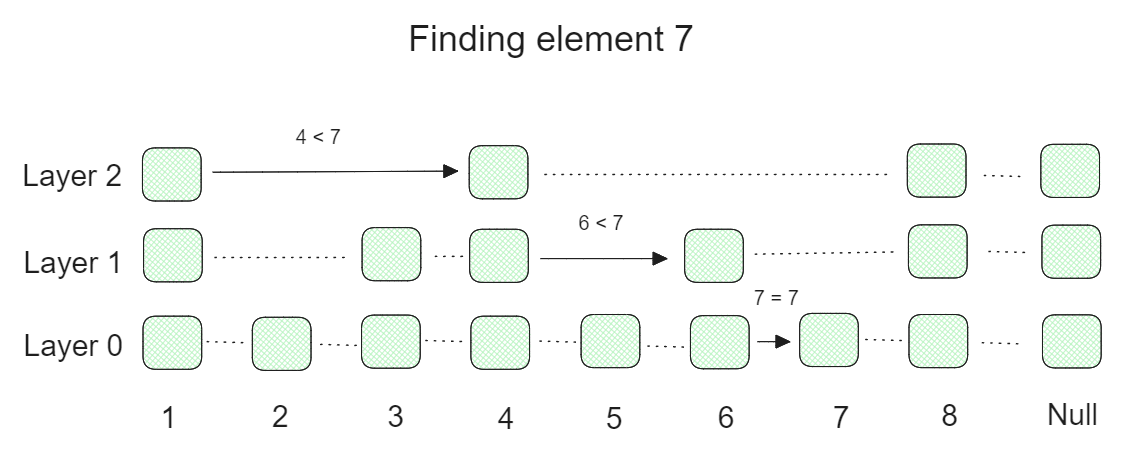
スキップリストは、リンクリストの複数のレイヤーからなる確率的データ構造で、レイヤーが高いほどリスト内の要素がスキップされる。下のビジュアライゼーションでわかるように、最下層にはリンクリストのすべての要素が含まれている。高レイヤーになるにつれて、リンクリストは徐々に要素をスキップするようになり、その結果、要素の少ないリストになる。
 リストをスキップして特定の要素を見つけるワークフロー.png
リストをスキップして特定の要素を見つけるワークフロー.png
図:特定の要素を見つけるためのスキップリストのワークフロー。
上記の可視化は、特定の要素の検索プロセスがどのように実行されるかの例を示しています。
元のリンクリストの3つのレイヤーと8つの要素を持つスキップリストから要素7を見つけようとしているとします。まず、一番上の階層から始めて、最初の要素が7以下かどうかをチェックします。もしそうなら、2番目の要素をチェックします。もし2番目の要素が7より上なら、1番目の要素を下の層の開始点として使用します。次に、下層でまったく同じことを行い、徐々に最下層まで降りていき、目的の要素を見つけます。このように多くの要素をスキップすることで、スキップリストを高速に検索することができます。
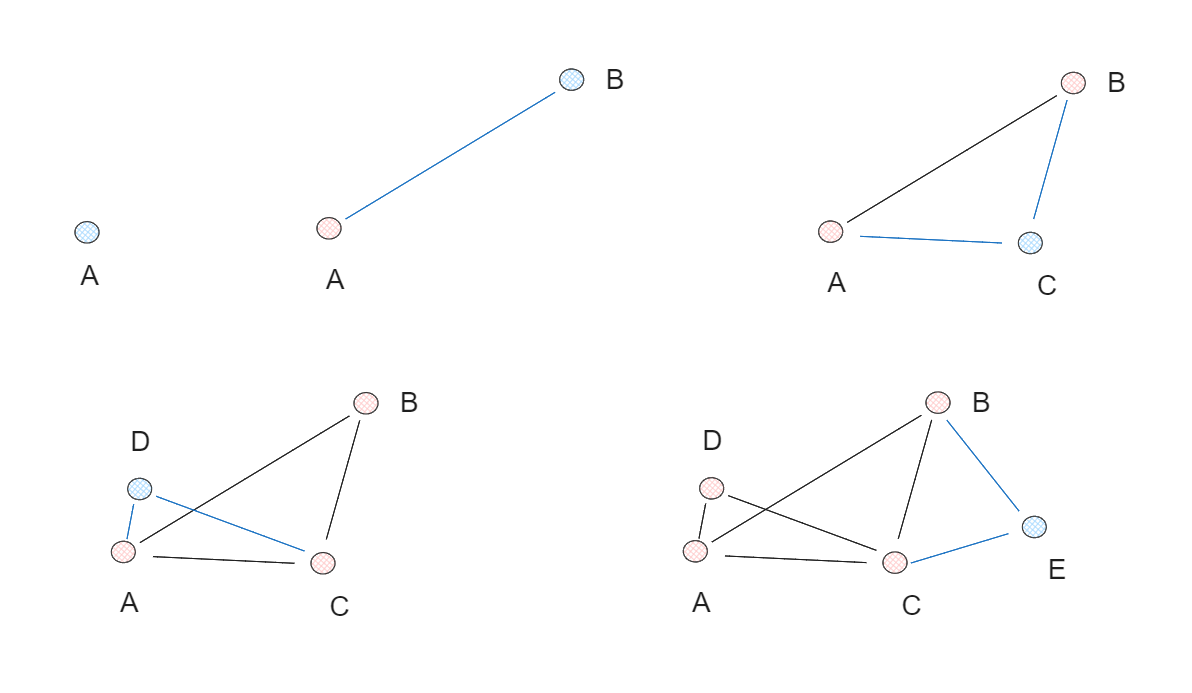
さて、スキップリストの基本概念を理解したところで、NSWグラフについて説明しよう。一言で言えば、NSWグラフはデータ点の集合をランダムにシャッフルし、それらを1つずつ挿入することで構築される。各挿入後、各データ点はあらかじめ定義された数の辺(M)を介して最近傍と接続される。各点が最近接点と接続されると、「スモールワールド」現象が発生し、任意の2点を比較的短い経路で横断できるようになる。
 NSWグラフ作成プロセス.png
NSWグラフ作成プロセス.png
図:NSWグラフ作成プロセス._.
上記の例では、5つのデータ点からNSWグラフを作成し、辺の数(M)を2とする。各反復において、1つのデータ点が個別にグラフに挿入され、各点の最近傍2点がエッジで接続される。
HNSW の概念
HNSWは前述のスキップリストとNSWグラフの概念を組み合わせたものである。HNSWは1つのグラフではなく、いくつかの層のグラフで構成され、階層を形成する。スキップリストの概念と同様に、グラフの最下層にはすべての要素が含まれ、階層が高くなるほど、より多くの要素がスキップされる。
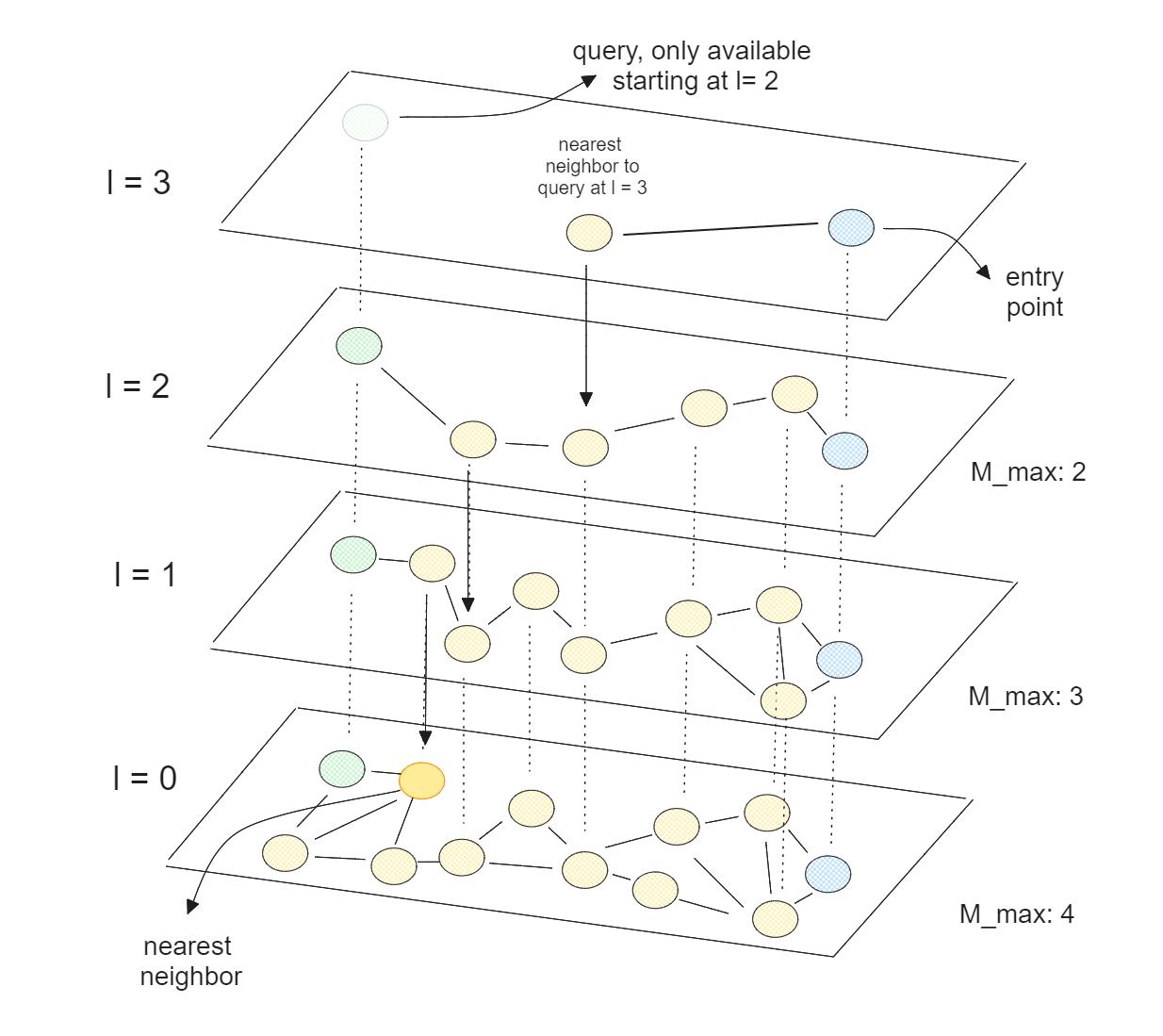
グラフ作成プロセスにおいて、HNSWは各要素に0からlまでの乱数を割り当てることから始める。ある要素のlが2で全レイヤー数が4の場合、この要素はレイヤー0からレイヤー2まで存在するが、レイヤー3には存在しない。
 HNSWアルゴリズムによるベクトル探索.png
HNSWアルゴリズムによるベクトル探索.png
図:HNSWアルゴリズムによるベクトル探索._.
ベクトル探索の過程で、HNSWアルゴリズムはまず、最上位層に存在する要素であるべきエントリーポイントを選択する。次に、エントリーポイントの最近傍が選ばれ、この最近傍がクエリーポイントに近づくかどうかをチェックする。もしそうで、最上位レイヤーにある他の要素がクエリーポイントに近くない場合、同じ検索手順を下位レイヤーで続けます。上のビジュアライゼーションでわかるように、エントリーポイントの選択された最近傍を、下のレイヤーの新しいエントリーポイントとして使用することに注意してください。
HNSW の主な特徴
HNSWアルゴリズムは多層グラフの概念に依存しており、高レイヤーになればなるほど、存在する要素は少なくなる。これにより、クエリーポイントに最も近い点を見つける前に、有望でない要素をトラバースする必要がなくなるため、ベクトル検索操作中の検索プロセスがスピードアップする。
HNSWは検索過程でいくつかの要素をスキップするため、完全一致は保証されない。これはHNSWだけでなく、FAISS やScaNNのような他の近似最近傍(ANN)アプローチにも当てはまる。従って、HNSWは厳密なマッチング結果を要求するユースケースには理想的なアルゴリズムではありません。
厳密なマッチング結果は要求されないが、それでも正確な結果を得たい場合、グラフ作成時と検索時の両方で、HNSWのハイパーパラメータを簡単に調整することができます:
M:M: 各レイヤーのグラフ作成時の要素あたりのエッジ数。一般的にM` の値を大きくすると検索精度が向上するが、その代償としてインデックス構築時間が遅くなる。defConstruction`:グラフ作成時に各層で最近傍を見つけるために考慮する近傍の数。考慮する近傍数が多いほどインデックスの品質は向上するが、インデックス構築にかかる時間は遅くなる。
defSearch
:ベクトル探索時に考慮する最近傍の数。efSearchを大きくすると再現率が高くなるが、検索処理は遅くなる。
速度対精度のトレードオフとは別に、グラフ作成過程でのメモリ消費にも注意を払う必要がある。これはHNSWがデータセット全体をRAMにロードする必要があるためで、データセットが大きすぎてメモリに収まらない場合に問題となる。
ご想像の通り、Mの値が大きいほど、各要素の近傍の情報を格納するために割り当てるメモリが多くなる。また、要素の組み合わせとその次元がグラフに追加されるにつれて、メモリは線形に増加する。したがって、グラフの作成プロセス、特に大規模なアプリケーションでは、M と efConstruction の両方を微調整することが重要である。
メモリ消費量にかかわらず、大規模データセットに対するHNSWの性能は他のANN手法と比較して非常に優れている。以下のGIST1Mデータセット(960次元の1Mベクトル)の ANN benchmarkを見ればわかるように、HNSWはMilvusのKnowhereとZilliz CloudのGlassアルゴリズムに続いて、FAISS、Annoy、pgvectorなどの他の幅広い手法の中からトップ3の結果を達成した。
GIST1MデータセットにおけるANNベンチマーク結果.png](https://assets.zilliz.com/ANN_Benchmark_results_on_the_GIST_1_M_dataset_f064223946.png)
図:GIST1MデータセットにおけるANNベンチマーク結果_。
HNSWlib の実装と Milvus との統合
HNSWlib**は、HNSWアルゴリズムのオープンソースC++およびPythonライブラリ実装です。HNSWアルゴリズムを実際のアプリケーションで使用するための実用的で最適化された方法を提供します。このライブラリは非常に効率的に設計されており、大規模データを含むユースケースに適しています。
HNSWlibは、ベクトル探索のユースケースのためのシンプルなプロトタイプを構築するのに最適です。しかし、1億、あるいは数十億のデータポイントを持つ、より複雑なシナリオでベクトル探索を実行したい場合、HNSWlibは最適なソリューションではありません。
他のベクトル検索ライブラリと同様、HNSWlib は機能が限定された軽量な ANN ライブラリです。例えば、データポイントがどんどん大きくなると、HNSWlib を使ってもうまくスケールしません。何百万ものデータポイントがある場合、HNSWlib を使うのはメモリ消費量が多すぎて RAM に収まらないため、実現不可能でしょう。大規模なアプリケーションでは、Milvusのようなベクトルデータベースを利用するのがよいでしょう。
ベクトルデータベースは、大量のデータを効率的に保存し、それに対して効果的なベクトル検索を実行できる本格的なソリューションです。例えば、Milvusは、クラウドネイティブでマルチテナンシーサービスをサポートしており、クラウド上の複数のユーザーから数百万から数十億のデータポイントを保存し、インデックスを作成し、検索することができます。HNSWlibのようなベクトル検索ライブラリは通常、ベクトルデータベースに統合され、保存されたデータに対して高速なベクトル検索を実行します。
このセクションでは、HNSWlibをスタンドアロンのベクトル検索ライブラリとして実装する方法と、Milvusベクトルデータベースに統合して使用する方法を紹介します。まず、HNSWlib のネイティブ実装の例から始めましょう。
HNSWlibのインストールはpip installで行います:
pip install hnswlib
次に、100個のダミーデータ点を作成する。次に、HNSWグラフを M を8、efConstruction を25として構築する。最後に、クエリデータ点の最近傍を計算する。
import hnswlib
np として numpy をインポートする。
インポート pickle
dim = 128
num_elements = 100
# サンプルデータの生成
data = np.float32(np.random.random((num_elements, dim)))
ids = np.arange(num_elements)
# クエリポイントの生成
query = np.float32(np.random.random((1, dim)))
# インデックスの宣言
p = hnswlib.Index(space = 'l2', dim = dim) # オプションはl2, cosine, ipのいずれかです。
# インデックスの初期化 - 要素の最大数を事前に知っておく必要がある
p.init_index(max_elements = num_elements, ef_construction = 25, M = 8)
# 要素の挿入(複数回呼び出すことができる):
p.add_items(data, ids)
p.add_items(data, ids) # efを設定することでリコールを制御:
p.set_ef(50) # efは常に>kでなければならない
# k - 最も近い要素の数 (2つのnumpy配列を返す)
ラベル、距離 = p.knn_query(query, k = 1)
以上でネイティブHNSWlibの実装は完了です。
次に、MilvusのHNSWインテグレーションをどのように利用できるかを見てみよう。Milvusを使い始める最も簡単な方法は、Milvus Lite(Milvusの軽量版で、Pythonアプリにインポート可能)を使うことで、pip installでインストールできる。
pip install -U pymilvus
pip install pymilvus[model] をインストールします。
コレクションを作成し、インデックス作成方法を定義することから始めよう。まず、コレクションスキーマを定義し、インデックスメソッドとしてHNSWを指定する。そして、インデックス構築のためにコレクションにデータを挿入し始めることができる。
from pymilvus import MilvusClient, DataType
from pymilvus import model
クライアント = MilvusClient("demo.db")
# 1.スキーマの作成
スキーマ = MilvusClient.create_schema(
auto_id=False、
enable_dynamic_field=False、
)
# 2.スキーマにフィールドを追加する
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=768)
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=200)
# 3.インデックスパラメータの準備
index_params = client.prepare_index_params()
# 4.インデックスの追加
index_params.add_index(
field_name="vector"、
index_type="HNSW"、
metric_type="L2"
)
# コレクションを作成する
if client.has_collection(collection_name="demo_collection"):
client.drop_collection(collection_name="demo_collection")
client.create_collection(
collection_name="demo_collection"、
schema=schema、
index_params=index_params
)
# 埋め込みモデルを定義する
embedding_fn = model.DefaultEmbeddingFunction()
# 検索元となるテキストデータ
docs = [
"人工知能は1956年に学問分野として設立された"、
"アラン・チューリングはAIの実質的な研究を行った最初の人物である"、
「チューリングはロンドンのマイダベールで生まれ、イングランド南部で育った、
]
# テキストデータを埋め込みデータに変換する
vectors = embedding_fn.encode_documents(docs)
データ = [
{"id": i, "vector": vectors[i], "text": docs[i]}.
for i in range(len(vectors))
]
# エンベッディングをMilvusに挿入する
res = client.insert(collection_name="demo_collection", data=data)
最後に、ベクトル検索を行いたい場合は以下のようにします:
SAMPLE_QUESTION = "アラン・チューリングの業績は?"
query_vectors = embedding_fn.encode_queries([SAMPLE_QUESTION])
res = client.search(
コレクション名="demo_collection"、
data=query_vectors、
limit=1、
output_fields=["text"]、
)
コンテキスト = res[0][0]["entity"]["text"] )
結論
ベクトル検索の実装は、現代のAIアプリケーションにおいて非常に重要である。これらのアプリケーションでは精度と速度の両方が要求されるため、洗練されたベクトル探索アルゴリズムの開発が必要となる。kNNアルゴリズムは網羅的な探索によって非常に正確な結果を提供するが、その線形時間複雑性によって大規模なデータセットには実用的ではない。
HNSWアルゴリズムは、多層グラフ構造を用いて速度と精度のバランスをとることにより、この制限に対する革新的な解決策を提供する。スキップリストとNSWグラフを組み合わせることで、HNSWは膨大なデータセットを効率的に処理できる高速な近似検索を可能にする。M、efConstruction、efSearch`のようなハイパーパラメータを微調整できる柔軟性により、HNSWは、各アプリケーションが必要とする検索速度、精度、メモリ消費量の間の特定のトレードオフに応じて、様々なユースケースに適応することができる。
HNSWlibは、HNSWアルゴリズムの実装を簡素化するオープンソースのC++およびPythonライブラリである。このライブラリは、実世界のアプリケーションでアルゴリズムを使用するための実用的で最適化された方法を提供します。このライブラリは非常に効率的に設計されており、大規模データを含むユースケースに適しています。
HNSWと他の一般的なベクトル・インデックスを比較したハンドル表をご覧ください。
 異なるインデックスの比較.png
異なるインデックスの比較.png
よくある質問
HNSWlib とは何ですか?
HNSWlib はベクトル検索のためのライブラリです。HNSW アルゴリズムを実装しており、高次元空間での効率的な類似性検索のために、 階層グラフ構造を作成します。速度と精度のバランスに優れているため、ベクトルデータベースで広く採用されており、ベクトル検索、推薦システム、画像検索などのアプリケーションで特に人気があります。
HNSWlib は Faiss のような他の ANN ライブラリと比較してどうですか?
HNSWlib は一般的に、ほとんどのユースケース、特に高い想起が要求され る場合に、他の多くの ANN ライブラリよりも優れた検索性能を提供します。また、HNSWlib は単一のアルゴリズム(HNSW)の実装に特化しています。HNSWlib は多くの場合、よりシンプルに使用できますが、Faiss インデッ クスよりも多くのメモリを消費する場合があります。
HNSWlib のメモリ要件は?
HNSWlib のメモリ使用量は、グラフ構造をメモリに格納する必要があるため、他の ANN ライブラリよりも一般的に多くなります。メモリ消費量は、要素数(N)、次元数(D)、M パラメータ(要素あたりの最大接続数)に依存する。
HNSWlib の長所と短所は?
HNSWlibは、対数複雑度O(log N)の卓越した検索速度と高い想起率を提供し、 インデックスを再構築することなく新しいデータを追加する動的更新を サポートします。ただし、グラフ構造全体をメモリに保存する必要があるため、他の ANN アルゴリズムに比べてメモリ消費量が多いこと、特に大規模なデータセットに対してインデックスの構築時間が遅いこと、要素の削除をネイティブにサポートしていないことなどが主な短所として挙げられます。
最適なパフォーマンスを得るためには、HNSWlib でどのようなパラメータを調整すればよいですか?
HNSWlib で最も重要なパラメータは M (データ点あたりの辺数) と ef_construction (構築時に考慮する最近傍の数) です。両パラメータの値を大きくすると、一般的に再現性は向上しますが、メモリ使用量と構築時間が増加します。良い点は、もう1つのハイパーパラメータ(ef_search)をクエリ時に調整することで、探索速度と精度のバランスをとることができることです。
その他のリソース
Faiss(フェイスブックAI類似検索)とは](https://zilliz.com/learn/faiss)
フェイスブックAI類似検索(FAISS)の設定】(https://zilliz.com/blog/set-up-with-facebook-ai-similarity-search-faiss)
HNSW(Hierarchical Navigable Small Worlds)を理解する】(https://zilliz.com/learn/hierarchical-navigable-small-worlds-HNSW)
検索の進化:キーワードマッチからベクトル検索、そしてGenAIへ ](https://zilliz.com/learn/evolution-of-search-from-traditional-keyword-matching-to-vector-search-and-genai)
RAGとは何か ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
ベクトル検索におけるAnnoy vs HNSWlib ](https://zilliz.com/blog/annoy-vs-hnswlib-choosing-the-right-tool-for-vector-search)
ベクトル検索における HNSWlib vs ScaNN ](https://zilliz.com/blog/hnswlib-vs-scann-choosing-the-right-tool-for-vector-search)

読み続けて

構造化データのベクトル化とクエリの究極ガイド
このガイドでは、構造化データをベクトル化する理由とタイミングについて説明し、Milvusを使用した構造化データのベクトル化とクエリを最初から最後まで説明します。

次世代検索:クロスエンコーダとスパース行列因子分解がk-NN検索を再定義する方法
AXN(Adaptive Cross-Encoder Nearest Neighbor Search)は、CEスコアの疎な行列を使用してk-NNの結果を近似し、高い精度を維持しながら計算量を削減する。

迷惑とは何か?
Annoyは、高次元ベクトル空間における高速な近似最近傍探索のために設計された、軽量でオープンソースのライブラリです。