




ベクターデータベースの高可用性の確保
高可用性の確保は、特にダウンタイムが生産性と収益の損失に直結するアプリケーションにおいて、ベクトル・データベースの運用にとって極めて重要である。
シリーズ全体を読む
- How to Evaluate RAG Applications
- Benchmarking Vector Database Performance: Techniques and Insights
- How to Spot Search Performance Bottleneck in Vector Databases
- Ensuring High Availability of Vector Databases
- Safeguard Data Integrity: Backup and Recovery in Vector Databases
- Scaling Vector Databases to Meet Enterprise Demands
- Introducing an Open Source Vector Database Benchmark Tool for Choosing the Ideal Vector Database for Your Project
データベースシステムは、停電、ネットワークの問題、人為的ミスなどの潜在的な障害にもかかわらず、中断のないアクセスを提供する高可用性が求められます。高い可用性がなければ、システムのダウンタイムやデータ損失のリスクが大きくなり、顧客離れ、評判の低下、財務上の損失につながります。
これはベクトルデータベースにも同様に当てはまります。ベクトルデータベースは、大規模な言語モデルの登場とともに脚光を浴び、Retrieval Augmented Generation(RAG)のような様々なGenAIスタックの不可欠な構成要素となっています。さらに、ベクターデータベースがプロトタイピングに使用されるものから、エンタープライズ対応のAIアプリケーションに大規模に導入されるものへと進化するにつれて、ビジネスの継続性を維持し、優れたユーザー体験を提供するために、高可用性を確保することがさらに重要になっている。
この投稿では、ベクターデータベースの高可用性の本質を探り、MilvusベクターデータベースとZilliz Cloud(マネージドMilvusサービス)がどのようにこの重要な機能を実現しているかを検証します。
高可用性とは?
データベースシステムにおける高可用性(HA)とは、継続的な運用サービスを提供し、ダウンタイムを最小限に抑え、定期的なメンテナンスや軽微な障害が発生した場合でも、システムがほぼ常時アクセス可能であることを保証することを指します。一次的な高可用性アプローチでは、単一障害点を排除し、ユーザーが中断することなく必要なデータに常にアクセスできるようにします。このアプローチは通常、冗長システム、フェイルオーバー・メカニズム、トラフィックを管理・分散するロードバランシングによって達成される。
高可用性と耐障害性の比較
高可用性(HA)とフォールトトレランスは、システムの信頼性を確保することを目的としたデータベースシステム設計において、密接に関連する概念である。しかし、そのアプローチと結果は異なります。高可用性は、障害発生後のシステム・コンポーネントの迅速な回復を通じてダウンタイムを最小化することに重点を置き、サービスの中断を最小限に抑えてほとんどの時間アクセスできるようにします。一方、フォールト・トレランスは、プライマリ・システムをミラーリングする専用インフラを使用することで、ダウンタイムとデータ損失をゼロにし、コンポーネントが故障してもシームレスに動作できるように設計されている。この要件により、フォールト・トレランスは高可用性よりもコストとリソース集約度が高くなる。
ハイ・アベイラビリティとフォールト・トレランスは、その範囲や重要性には違いがあるものの、サービスを迅速に復旧させることで障害に効率的に対処するため、交換可能である。
高可用性のゴールドスタンダード
高可用性は、100%の稼働率を約束するものではないが、可能な限りそれに近づくように設計されている。しばしば「ファイブナイン」と呼ばれるゴールドスタンダードは、システムが99.999%の時間アクセス可能であることを保証するものである。この概念には、「フォーナインズ」(99.99%)、「スリーナインズ」(99.9%)、「ツーナインズ」(99%)など、さまざまなレベルの可用性が含まれます。各レベルは、完全ではないものの、潜在的なダウンタイムを大幅に削減し、安心できるレベルのシステム信頼性を提供します。
しかし、これらの基準は具体的に何を意味するのだろうか?計算してみよう。
- 年間99.999%(ファイブナイン)**の場合、ダウンタイムはわずか5.26分に制限されます。
- 99.99%(フォーナインズ)**は、年間52.60分のダウンタイムしか許容できないことを意味します。
- 99.9%(9が3つ)**の場合、ダウンタイムは年間8.77時間に制限されます。
- 99%(9が2つ)**の場合、年間ダウンタイムは3.65日となります。
高可用性のレベルが高くなるにつれて、関連コストも高くなります。これは、潜在的なダウンタイムを最小化するために、より高度なインフラとテクノロジーが必要になるためです。高可用性レベルの選択は、ビジネスの運営方法に直接影響するため、非常に重要です。単に最高レベルの可用性を求めるのではなく、コストとビジネス要件の適切なバランスを見つけることが重要です。このバランスを理解することが、運用中断のリスクを大幅に低減できる決定を下すための鍵となります。
高可用性を実現するMilvus Vector Databaseの仕組み
Milvusは、高可用性で有名なオープンソースのベクターデータベースである。クラウドネイティブで、分散型で、Kubernetes上に簡単にデプロイできる。インメモリレプリカ機構や様々なバックアップ、リストア、同期ツールを提供し、システムの信頼性を実現します。このセクションでは、アーキテクチャ設計、機能、サポートツールの観点からMilvusの可用性について説明する。
Kubernetes への迅速なデプロイを実現するクラウドネイティブなアーキテクチャ
Milvusは、ストレージとコンピューティングを分離したクラウドネイティブな分散アーキテクチャを採用しており、Kubernetes(K8s)クラスタへの容易なデプロイが可能です。
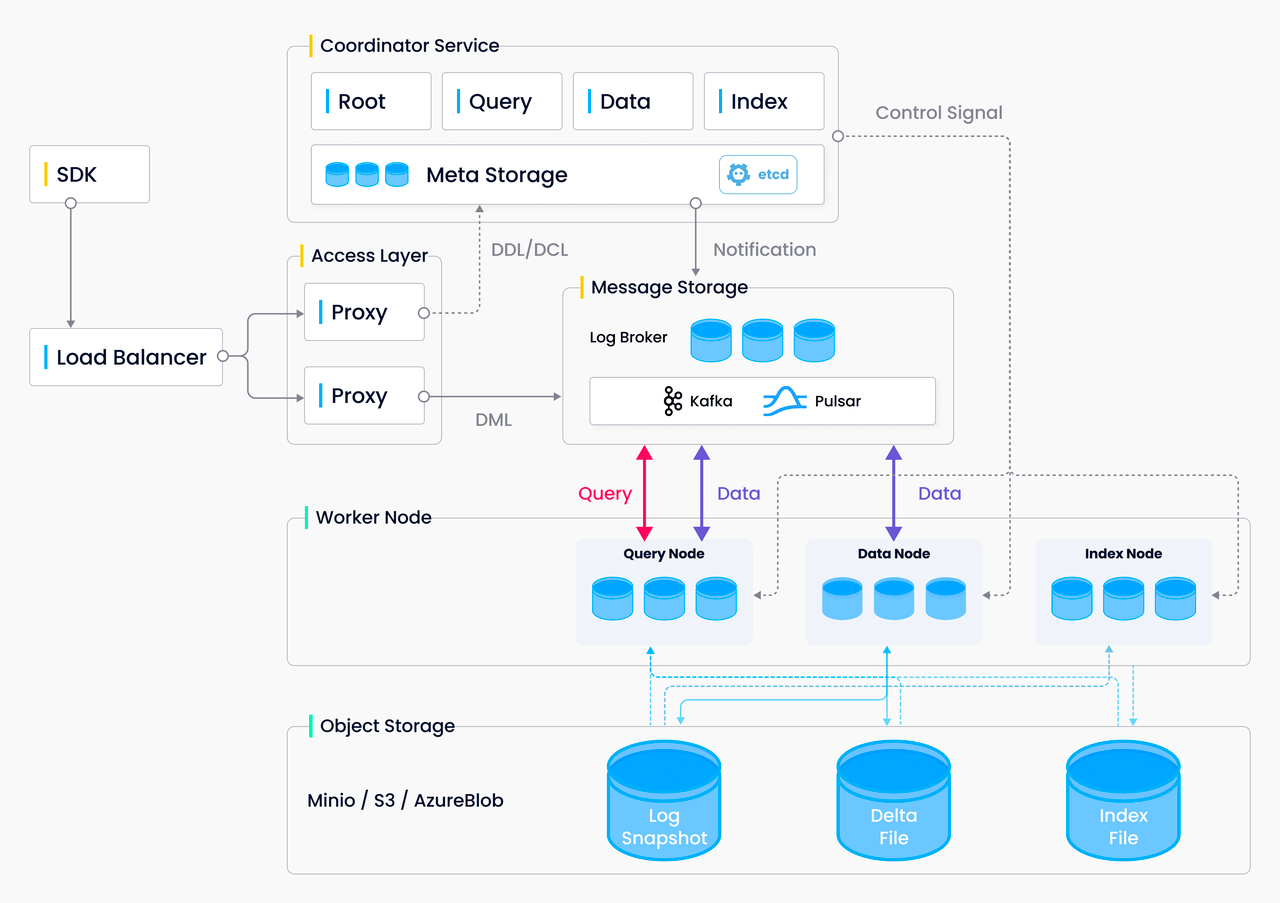 Milvusアーキテクチャ.png
Milvusアーキテクチャ.png
Kubernetes固有の高可用性機能とMilvusの分散アーキテクチャを活用することで、Milvusは容易に促進することができます:
- マルチアベイラビリティゾーンデプロイメント**:Milvusは複数のアベイラビリティゾーンにまたがるデプロイをサポートし、信頼性を高めるために様々なゾーンにレプリカを分散します。あるゾーンで問題が発生しても、他のゾーンのレプリカは稼働し続けるため、システム全体の可用性が向上します。
- ヘルスチェックとセルフヒーリング**:Kubernetesのヘルスチェック機構は定期的にサービスステータスを監視します。Milvusノードに不具合や不健全性が発見された場合、Kubernetesは自動的にノードを再起動または交換し、サービスの継続性を維持します。
- ロードバランシングとトラフィック管理**:Milvusはコンテナ間のネットワークトラフィックを効率的に分散してボトルネックを防ぎ、パフォーマンスと可用性を向上させます。
- ストレージの冗長性**:MilvusはKubernetesのPersistent Volumes (PV)とPersistent Volume Claims (PVC)を利用し、信頼性の高いストレージシステムにデータが保存されるようにし、データの耐久性と可用性を保護します。
インメモリ・レプリカ・メカニズム
Milvus は分散展開モードでインメモリレプリカ機能をサポートしています。この機能は、完全なデータセグメントを別々のクエリノードにロードし、ワーキングメモリ内で複数のセグメントレプリケーションを可能にすることで、パフォーマンスと可用性を向上させます。レプリカを持つノードに障害が発生したり、エラーが発生した場合、クエリ要求はデータを再度ロードすることなく、別のレプリカノードに迅速にリダイレクトされるため、継続的なクエリサービスが維持されます。
Miluvsインメモリ・レプリカ・メカニズム](https://assets.zilliz.com/replication_3_1_2c25513cb9.jpg)
インメモリ・レプリカの設計と実装の詳細については、このドキュメントを参照。
効率的なバックアップ、リストア、同期ツール
Milvusは、Milvus-backupやMilvus-CDCなどの専用ツールを提供し、データバックアップのリカバリを強化し、オンラインインクリメンタルデータ同期を促進します。これらのツールはサービス復旧とデータ保護の両方を強化します。
ミルバスバックアップ
Milvus-backupは、全体または特定のコレクションを問わず、オリジナルデータを効率的にバックアップおよびリストアするためのツールです。ビジネスニーズに合わせた柔軟なソリューションを提供し、以下を可能にします:
- オンラインデータの定期的なバックアップ
- 異なるMilvusクラスタ間でのデータ転送または移行。
- 偶発的または悪意のあるデータ変更の場合、原始的な履歴バージョンへの復元。
- システムアップグレードのような重要な変更やメンテナンスの前のデータバックアップ
Milvus-CDC (変更データキャプチャ)
Milvus-CDCは、上流のMilvusコレクションの変更をキャプチャして同期し、リアルタイムで下流のMilvusインスタンスにシンクするツールです。片方のインスタンスをソース、もう片方のインスタンスをターゲットとして指定することができ、コレクションのすべてまたは選択された部分についてリアルタイムかつシームレスなデータ同期を可能にします。Milvus-CDCはMilvus-backupと組み合わせることで、高可用性やディザスタリカバリのための堅牢なソリューションを実装することができます。
Zilliz Cloudにおける高可用性
Zilliz CloudはMilvus上に構築されたフルマネージドベクターデータベースです。GenAIアプリケーションのための非構造化データの可能性を最大限に引き出すことができます。
Zilliz Cloudは、リソースグループによる物理的な分離、マルチテナント機能、信頼性の高いバックアップとリストアのメカニズム、そしてSLAによる99.9%のサービスアップタイムを提供します。リソースグループとマルチテナンシーにより、マルチテナントのデータとサービスを分離し、偶発的または意図的な削除からデータを保護します。その結果、Zilliz CloudはMilvusのオフライン展開よりもさらに高度なデータ保護とサービス回復力を提供します。
詳細はZilliz Cloud システム稼働状況をご参照ください。
要約
高可用性の確保は、ベクターデータベースの運用、特にダウンタイムが生産性と収益の損失に直結するアプリケーションにおいて極めて重要である。
これまで説明してきたように、MilvusはKubernetesのデプロイに最適化された洗練されたクラウドネイティブなアーキテクチャを活用することで、耐障害性と信頼性を高めている。このセットアップは、堅牢なフェイルオーバー機能とシームレスなスケーラビリティをサポートし、インメモリ・レプリケーションや包括的なバックアップ・同期ツールなどの高度な機能を組み込んでいる。
この基盤の上に、Milvus上に構築されたフルマネージド・ベクター・データベースであるZilliz Cloudは、データ保護とサービス回復力を強化している。リソースグループによる物理的な分離、マルチテナント機能、信頼性の高いバックアップとリストアメカニズム、SLAで保証された99.9%のサービスアップタイムを提供します。これらの機能により、混乱からデータを保護し、従来の導入よりも高い信頼性を提供します。
データを守る:ベクターデータベースシステムにおけるセキュリティとプライバシー](https://zilliz.com/learn/safeguarding-data-security-and-privacy-in-vector-database-systems)のブログで、なぜ強固なセキュリティとプライバシー対策が重要なのかをご覧ください。
 Fendy Feng
Fendy FengFendy Feng is the Technical Marketing Writer at Zilliz. She has extensive experience developing and enhancing the impact of open-source projects in various global markets by producing high-quality, tailored content. Before joining Zilliz, Fendy worked as a Content Strategist at PingCAP, a fast-growing E-Series startup renowned for its open-source distributed SQL database.
 Yanliang Qiao
Yanliang QiaoYanliang Qiao is a Senior Quality Assurance Engineer at Zilliz.


