




What is the BEIR benchmark for Information retrieval system
What is the BEIR benchmark for Information retrieval system
Analyzing the BEIR Benchmark for Information Retrieval
Introduction to Information Retrieval and BEIR
IR systems are designed to find documents in response to user queries. As these systems have evolved so have the need for comprehensive evaluation methods to understand the existing systems.
BEIR (Benchmarking IR) is a tool to evaluate how well search systems perform across many tasks and types of information. Researchers developed BEIR to address the limitations of existing evaluation methods. BEIR is a more realistic evaluation of search technology especially out of domain.
Unlike traditional benchmarks that focus on specific tasks or domains, BEIR is a heterogeneous evaluation framework that tests many IR system models across many scenarios. It has 18 datasets for various tasks such as fact checking, question answering and biomedical information retrieval. This diversity allows BEIR to evaluate the versatility and robustness of IR systems in a way that is more like real world applications.
One of BEIR's key innovations is its focus on zero-shot evaluation, testing how well models perform on tasks they weren't specifically trained for. This has shown important insights about the strengths and weaknesses of different IR models, especially the challenges faced by dense retrieval models in out of domain searches.
In the following we will jump into BEIR’s features, its importance in information retrieval and the impact it has on search technology. We will compare BEIR to different approaches from traditional lexical and search engines to modern neural models and discuss what it means for developers building robust and adaptable search systems.
What is BEIR?
Even though it sounds like "beer" and the logo is two beer steins, unfortunately it isn’t the kind of beer I am used to and instead, a totally different kind of "Bier!" BEIR stands for Benchmarking IR (Information Retrieval) and is a tool to evaluate how well Information Retrieval Systems (search systems) perform across many tasks and types of information. Researchers developed BEIR to address the limitations of existing evaluation methods. BEIR is a more realistic evaluation of search technology.
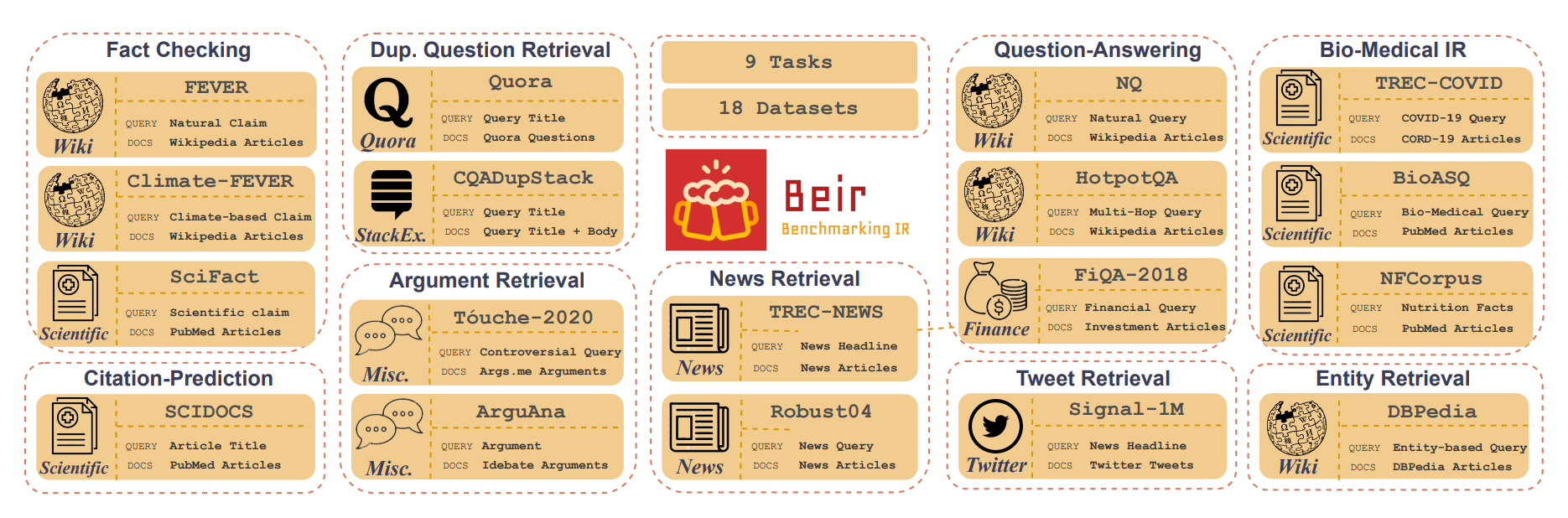 Overview of the diverse collection of datasets of Bier
Overview of the diverse collection of datasets of Bier
BEIR Features
Benchmarking Information Retrieval is a standard benchmark for evaluating the performance of information retrieval models and provides a diverse collection of datasets that focus on various retrieval tasks. It addresses the need for more realistic assessment of search technology across diverse tasks and domains. Here are some key features of BEIR:
BEIR is a benchmark designed for evaluating the versatility and robustness of information retrieval models. It features 18 diverse datasets from domains like bioinformatics, finance, and news, allowing models to be tested on a wide range of diverse text retrieval tasks, such as fact-checking, question answering, document retrieval, and recommendation systems.
The benchmark covers nine distinct retrieval tasks, such as similarity** retrieval**, argument retrieval, and fact-checking, which tests models across various real-world scenarios. Its cross-domain testing capability allows models to be evaluated on tasks outside their training domain, making it a valuable tool for assessing their generalization capabilities.
BEIR uses standardized evaluation metrics like NDCG and Recall, simplifying comparisons across models and datasets. It also includes integration with popular models like BERT, T5, and GPT, streamlining the benchmarking process. The open-source nature of BEIR fosters community collaboration and adaptation, which for a benchmarking tool is important to help it maintain transparency.
Additionally, BEIR emphasizes zero-shot evaluation, which measures how well retrieval systems perform on tasks they weren’t explicitly trained for, providing insight into their adaptability. Its datasets also include varied text types, from short tweets to lengthy scientific articles, mimicking the range of content found across the web.
BEIR allows researchers and developers to identify strengths and weaknesses in IR algorithms, compare approaches fairly, and develop more robust baseline versatile search technologies. Its comprehensive evaluation drives advancements in IR technology, potentially improving search experiences across various applications.
Limitations
Passage retrieval focus
The benchmark is focused on passage retrieval because of the length limitations of transformer based models. Most documents in BEIR fit within the 512 token limit of transformer models. There are some exceptions like documents stored in the robust04 dataset which has news articles of around 700 words. But BEIR doesn’t have very long documents like PDFs with hundreds of pages. This is a “blind spot” where future benchmarks can be developed.
Creating harder versions of the benchmark
As dense retrieval models have improved, they have performed much better on BEIR. Recent results show that lexical search (like BM25) is only better on 2 out of 14 datasets compared to earlier results where it was better on most datasets. This raises the question if BEIR is still a challenging benchmark. There’s a discussion in the community about the need for a “BEIR 2” that has more challenging retrieval datasets to push the limits of the models.
Dense retrieval models in out-of-domain search
BEIR showed that dense embedding models which performed very well on in-domain tasks (up to 18 points boost) struggle a lot in out-of-domain scenarios. For example some dense models performed well only on the Wikipedia dataset they were trained on but were worse than lexical search on all other 17 datasets in BEIR. This led to a lot of research on why dense models struggle with unknown domains. Researchers found issues like high train-test overlap in some datasets and unseen words. These insights have driven improvements in model training techniques including better way to handle out-of-domain words and more robust benchmarks with clear separation between training and test sets.
These results from BEIR have driven IR advancements, innovations in model, training and evaluation.
Why BEIR:
BEIR fills the gap in how search is evaluated. By providing a standard, varied and challenging set of tests, researchers and developers can see the strengths and weaknesses of current search algorithms, compare approaches fairly and comprehensively and build more versatile and better search technology. Also BEIR helps them to see how search systems will perform in real world, diverse applications.
For users of web search engines and technology, the results of BEIR will lead to more accurate, versatile and efficient search experiences across all applications and platforms. This means better search results in everyday applications, from web search to database queries.
BEIR is an open-source project, so researchers all over the world can contribute and benefit from it. This openness will accelerate the improvement of search technology as researchers build upon and refine BEIR. As BEIR is improved, the entire IR field will benefit and ultimately end-users will have better search experiences across all applications.
Beir Background
BEIR (Benchmarking IR) is the first broad, zero-shot information retrieval benchmark. Unlike previous benchmarks, it evaluates modern information retrieval, across multiple domains and task types in zero-shot setting. Previous works like MultiReQA and KILT were limited in scope, single task, small corpus or specific domain.
The benchmark comes at a time when IR methods are evolving. Traditionally lexical approaches like TF-IDF and BM25 were the dominant text retrieval methods. Recently there is a growing interest in using neural networks like Splade to improve or replace these methods. Early neural techniques were to enhance lexical information retrieval techniques, like docT5query for document expansion and DeepCT for term weighting.
Dense retrieval models were then developed to capture semantic matches and fill the lexical gap. These models map queries and documents into a shared dense vector space. Hybrid lexical-dense models followed to combine the strengths of both.
Another line of research explored unsupervised domain adaptation for training dense retrievers. Also models like ColBERT introduced token-level contextualized embeddings for retrieval.
Re-ranking using neural networks especially those using BERT’s cross-attention mechanism showed big performance boost but with high computational cost.
BEIR tries to see how these existing retrieval systems and methods generalize across different domains and tasks, especially in zero-shot setting, to fill the gap in understanding the adaptability of modern IR systems.
Beir Software and Framework
BEIR is a user-friendly Python framework that can be installed with pip. It’s designed to make model evaluation in IR tasks easy. The software comes with comprehensive wrappers to replicate experiments and evaluate models from well known repositories like Sentence-Transformers, Transformers, Anserini, DPR, Elasticsearch, ColBERT and Universal Sentence Encoder. This wide range of compatibility makes BEIR useful for both academic research and industry applications.
The framework provides many IR-based metrics: Precision, Recall, Mean Average Precision (MAP), Mean Reciprocal Rank (MRR), Normalized Discounted Cumulative Gain (nDCG) for any top-k. This allows to evaluate retrieval models comprehensively.
BEIR is flexible, users can evaluate existing models on new datasets and new models on the datasets in the benchmark. To address the problem of datasets in different formats, BEIR introduces a standard format for corpus, queries and relevance judgments (qrels). This standardization makes the evaluation process across many datasets easier for researchers and developers to test their models on different data retrieval tasks.
Evaluation metric used in BEIR
BEIR uses Normalized Discounted Cumulative Gain (nDCG@10) as its main evaluation metric. This was chosen to have comparable results across different models and datasets in the benchmark.
The choice of nDCG@10 was based on:
Real world applications can be either precision or recall focused, so a balanced metric was needed.
Some metrics like Precision and Recall don’t consider the ranking of results which is important in retrieval tasks.
Other rank-aware metrics like Mean Reciprocal Rank (MRR) and Mean Average Precision (MAP) are limited to binary relevance judgments which isn’t suitable for all tasks.
nDCG@10 can handle both binary and graded relevance judgments so it’s versatile across different types of retrieval tasks.
The BEIR team says nDCG@10 is a good metric to broadly evaluate the different retrieval tasks. They use the Python interface of the official TREC evaluation tool to compute this metric for all datasets in the benchmark.
By using a single metric across all tasks, BEIR allows to compare different retrieval models and across different datasets, regardless of whether they use binary or graded relevance judgments.
Key Findings with comparing neural search methods
When you look at the Beir paper (or watch the nice and short video from one of the authors, Nils Reimers), they share some findings of a comparison of different neural search methods vs BM25 (lexical search).
BEIR evaluates many state-of-the-art retrieval architectures, focusing on transformer-based neural approaches. The benchmark uses publicly available pre-trained checkpoints and groups models into five categories: lexical, sparse, dense, late-interaction and re-ranking. Due to transformer network limitations, only the first 512 word pieces of text documents, are used in the experiments.
Key findings from BEIR's evaluation include:
The researchers did a comprehensive benchmarking of dense models for information retrieval (IR). Traditionally, embedding approaches were used for in-domain IR where a model is trained with domain specific data and then applied to search within that same domain. But the researchers explored a more interesting challenge: out-of-domain IR where a pre-trained model is applied to new domains without retraining it for the specific data. To evaluate this, they collected many datasets across different retrieval tasks. For example, in tweet retrieval, the task was to match news articles with relevant tweets. In ArguAna and Touche-2020 datasets, the task was argument retrieval, specifically finding counter-arguments. The Fever dataset was used to find Wikipedia articles supporting specific claims.
They compared many dense retrieval models to a baseline lexical search model (BM25). The dense retrieval model from Facebook worked well on Wikipedia where it was trained but poorly on 17 other datasets compared to BM25. Even the best dense embedding model, TAS-B, only outperformed BM25 on 8 out of 18 datasets. So dense models have big challenges in out-of-domain tasks. So dense embedding models have big difficulties when applied to unknown domains. More research is needed to improve their generalization ability.
Some models like SPLADE worked better in unknown domains. But across many settings, the most robust retrieval method was BM25 with cross-encoder and T5 query model which showed stable results across many domains. As dense models evolve, recent benchmarks show that lexical search still outperforms dense models in 2 out of 14 datasets. Some models might be overfitting to the current Beir Benchmark datasets. Maybe it’s time to create Beir Benchmark 2 with more challenging and diverse datasets.
Dense models work by projecting queries and documents into a vector space and retrieve documents by finding the nearest vector match. This works well in in-domain but struggles with unseen words and out-of-domain. The researchers also found that many in-domain datasets have training-test overlap where test queries are seen during training and hence artificially high performance. Dense models struggle when exposed to domains or words not seen during training. This led to more research on improving dense models generalization beyond their training domains.
Next the researchers suggest to have better benchmarks that separate training and test sets well and have longer documents or more complex retrieval tasks. Future research will focus on models that can perform well across many domains especially in out-of-domain retrieval.
Conclusion
BEIR (Benchmarking IR) is a tool for information retrieval. As the first broad, zero-shot information retrieval benchmark, it fills the gap of evaluating search technologies across many domains and tasks. BEIR with 18 datasets and 9 tasks provides unprecedented understanding of many information retrieval methods and models especially in out-of-domain.
The benchmark showed the challenges of dense and sparse retrieval models in generalizing to unknown domains which led to more research and innovation. By showing the strengths of traditional methods like BM25 in some cases and hybrid approaches BEIR encouraged a more balanced view of sparse retrieval models and system capabilities.
Moreover BEIR is open source and has standardized metrics which encouraged collaboration in the research community and accelerated the progress. As models improve, the discussion of creating more challenging version of the benchmark proves that BEIR is still relevant and information retrieval is a dynamic field.
Next the insights from BEIR will drive more robust, flexible and efficient search technologies. These will improve search experience across many applications from specialized academic databases to everyday web search. As the field moves forward BEIR is a proof that comprehensive real-world evaluation is important to push the limits of information retrieval systems.
References
Reimers, N. (2022). Evaluating Information Retrieval with BEIR. Cohere. [YouTube video]. https://www.youtube.com/watch?v=w6_5-hAsjBQ
Thakur, N., Reimers, N., Rücklé, A., Srivastava, A., & Gurevych, I. (2021). BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. arXiv preprint arXiv:2104.08663.
- Introduction to Information Retrieval and BEIR
- What is BEIR?
- BEIR Features
- Limitations
- Why BEIR:
- Beir Background
- Beir Software and Framework
- Evaluation metric used in BEIR
- Key Findings with comparing neural search methods
- Conclusion
- References
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free