




ScaNNを始める
GoogleのScaNNはANNSのためのライブラリです。このガイドでは、ScaNNを実装し、Milvusと統合する方法を説明します。
シリーズ全体を読む
- Raft or not? The Best Solution to Data Consistency in Cloud-native Databases
- Understanding Faiss (Facebook AI Similarity Search)
- Information Retrieval Metrics
- Advanced Querying Techniques in Vector Databases
- Popular Machine-learning Algorithms Behind Vector Searches
- Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
- Ranking Models: What Are They and When to Use Them?
- Navigating the Nuances of Lexical and Semantic Search with Zilliz
- Enhancing Efficiency in Vector Searches with Binary Quantization and Milvus
- Model Providers: Open Source vs. Closed-Source
- Embedding and Querying Multilingual Languages with Milvus
- An Ultimate Guide to Vectorizing and Querying Structured Data
- Understanding HNSWlib: A Graph-based Library for Fast Approximate Nearest Neighbor Search
- What is ScaNN (Scalable Nearest Neighbors)?
- Getting Started with ScaNN
- Next-Gen Retrieval: How Cross-Encoders and Sparse Matrix Factorization Redefine k-NN Search
- What is Voyager?
- What is Annoy?
最近傍探索(NNS)は、推薦エンジン、画像検索、文書検索などのアプリケーションに力を発揮する、大規模データセット中の類似アイテムを特定するための基本的なテクニックである。例えば、電子商取引では、NNSアルゴリズムは、カテゴリ、価格、レビューなどの属性に基づいて、顧客が見ているものに似た商品を提案することができる。しかし、データセットのサイズと複雑さが増すにつれ、速度と精度の両方を達成することはますます難しくなっています。
このような課題に対処するため、近似最近傍探索(ANNS)は、わずかな精度をスピードとスケーラビリティの大幅な改善と引き換えにすることで、解決策を提供している。GoogleのScaNN (Scalable Nearest Neighbors)はANNSのためのライブラリで、大規模で高次元のデータセットを効率的に扱うように設計されている。クラスタリングや圧縮といった高度な技術を採用することで、ScaNNは精度を維持しながら高性能な検索を実現している。
前回の投稿](https://zilliz.com/learn/what-is-scann-scalable-nearest-neighbors-google)では、ベクトル探索とScaNNの基本を紹介しました。この投稿では、ScaNNの実装方法を説明し、実稼働規模のベクトル検索用に構築されたオープンソースのベクトルデータベースであるMilvusと統合する方法を示します。ScaNNとMilvusを組み合わせることで、次世代アプリケーションを構築するための堅牢でスケーラブルなソリューションを提供します。
ScaNN を始める
ScaNN を使用するには、まず pip でインストールします:
pip install scann
このコマンドはScaNNとその依存関係をインストールします。インストールが終わったら、次は最近傍探索を行うデータセットを準備します。
データセットの準備
このブログでは、GloVe datasetを使用します。GloVe datasetは、事前に学習された単語埋め込みを提供します。単語埋め込みは、単語を高次元空間のベクトルとして表し、似たような単語は近くにある。例えば、kingとqueenは埋め込みが似ているので、このデータセットは類似検索のテストに最適です。
GloVeデータセットを次のようにロードする:
# 必要なライブラリをインポートする
np として numpy をインポート
インポート h5py
インポート os
インポート リクエスト
インポート tempfile
import scann # pip install scann でインストールする。
# データセットのダウンロードと準備
with tempfile.TemporaryDirectory() as temp_dir:
# URLからデータセットを取得し、ローカルに保存する
response = requests.get("http://ann-benchmarks.com/glove-100-angular.hdf5")
file_path = os.path.join(temp_dir, "glove_data.hdf5")
with open(file_path, 'wb') as file:
file.write(response.content)
# h5pyでデータをメモリにロードする
glove_data = h5py.File(file_path, "r")
# データをベクトルとクエリに分割する
vectors = glove_data['train'] # ベクトルとクエリにデータを分割する
queries = glove_data['test'] # ベクトルとクエリに分割
print("Vectors shape:", vectors.shape)
print("Queries shape:", queries.shape)
このコードは GloVe データセットをダウンロードし、一時的に保存し、メモリにロードする。データセットは train (vectors として格納されるメインデータ) と test (queries として格納されるサンプルクエリ) に分割される。
ベクトルの正規化
類似度計算](https://zilliz.com/blog/similarity-metrics-for-vector-search) が意味のあるものになるように、ベクトルを正規化 します。
# 効率的な ScaNN インデックスのためにベクトルを正規化する。
normalized_vectors = vectors / np.linalg.norm(vectors, axis=1)[:, np.newaxis].
各ベクトルをその大きさで割って np.linalg.norm で計算し、各ベクトルを単位長さにします。これは、長いベクトルが類似度の計算を支配するのを防ぎ、より正確な結果を導くので、ドット積の類似度に便利です。
ScaNN インデックスの設定
次のステップは ScaNN インデックスの設定です。インデックス は検索操作をスピードアップするためにデータを整理するデータ構造です。インデックスを設定することで、検索速度と精度のバランスをコントロールすることができます。
# ScaNN インデクサーの設定と構築
# ハイブリッドスコアリングと並べ替えによる効率的な検索のための ScaNN のセットアップ
index = scann.scann_ops_pybind.builder(normalized_vectors, 10, "dot_product").tree(
num_leaves=2000, num_leaves_to_search=100, training_sample_size=250000).score_ah(
2, anisotropic_quantization_threshold=0.2).reorder(100).build()
上記のコードでは、インデックスを作成するデータセットとして normalized_vectors を指定し、クエリごとに取得する最近傍の数として 10 を指定している。そして、ベクトル間の角度を測定する類似度指標として dot_product を設定する。num_leaves=2000はデータを2000のクラスタに分割し、検索空間を縮小し、関連するクラスタにフォーカスすることで検索を高速化する。さらに、num_leaves_to_search=100を設定することで、検索を100クラスタに制限し、速度と精度のバランスをとる。training_sample_size=250000はインデックスを学習するサンプル数を指定し、データセット全体を使用することなくインデックス作成を高速化する。
score_ah(2, anisotropic_quantization_threshold=0.2)パラメータは非対称ハッシュを有効にする。非対称ハッシュは量子化しきい値を用いてデータを圧縮する手法であり、メモリ使用量を減らし、検索速度を向上させる。最後に、reorder(100)`は上位100件を絞り込み、高い精度を保証する。
検索の実行
インデックスを設定したら、類似検索を実行してクエリの最近傍を探します。検索は、インデックスの構成に基づいて最も近い一致を検索します。
# デフォルトの近傍値を10に設定して初期検索を実行します。
neighbors, distances = index.search_batched(queries)
# サンプルクエリの検索結果を表示
sample_query_index = 0 # 別のクエリの結果を表示するには、このインデックスを変更します。
print(f "クエリ{sample_query_index}に対するサンプル結果:")
print("最近傍インデックス:", neighbors[sample_query_index])
print("最近傍までの距離:", 距離[sample_query_index])
上記のコードでは、クエリをバッチ検索しています。変数 neighbors には各クエリに最も近いベクトルのインデックスが格納され、distances にはこれらの近傍ベクトルの類似度スコアが格納されます。距離の値が小さいほど類似度が高いことを示す。
期待される出力は以下の通りである:
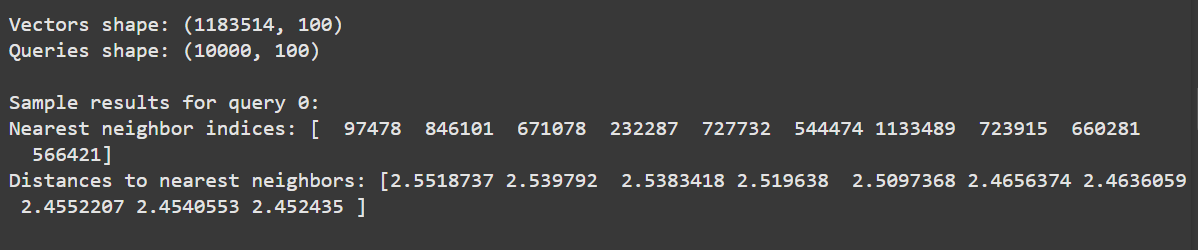
図:ScaNN_ におけるサンプルクエリの最近傍インデックスと距離
出力は最初のクエリの最近傍インデックスとその距離を表示します。距離は類似度スコアであり、値が小さいほど類似度が高いことを示します。
それではScaNNをMilvusと統合し、より人間に優しくシンプルなデータセットを使ってみましょう。
ScaNN と Milvus の統合
Milvus は大規模なベクトルコレクション(最大数兆)の保存と検索に最適化されたベクトルデータベースです。Milvus は ScaNN をそのアーキテクチャにネイティブに統合し、高速な検索結果を実現します。ScaNNとMilvusを組み合わせることで、Milvusのデータ管理とスケーラビリティの利点を得ることができ、膨大なデータセットを効率的に扱うことが可能になります。
このセクションでは、ScaNNとMilvusの実装方法について説明します。
ステップ1: Milvusのインストールと依存関係
まだMilvusをインストールしていない場合は、このガイドに従ってインストールと実行を行ってください。
次に、MilvusのPythonクライアントであるPymilvusをインストールする。このクライアントにより、Pythonを使用してMilvusと対話し、ベクトルデータコレクションを管理することができます。また、PyMilvusは様々なembedding and reranking modelsとシームレスに統合されており、Milvusを使った最新のAIアプリケーション、特に検索拡張世代(RAG)の構築が容易になります。
pip install "pymilvus[モデル]"
ステップ2: Milvusクライアントの初期化とコレクションの作成
Milvusクライアントを初期化し、コレクションのスキーマを定義します。Milvusでは、コレクションはベクターデータを保存・整理する場所です。
from pymilvus import MilvusClient, DataType
from pymilvus import model
# サーバ全体のURIでMilvusクライアントを初期化する。
client = MilvusClient(uri="http://localhost:19530") # あなたのMilvusサーバのURIに置き換えてください。
# 768次元のコレクションスキーマを定義する
schema = client.create_schema(
auto_id=False、
enable_dynamic_field=False、
)
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=768) # 768に設定する。
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=200) # 768に設定する。
上記のコードはクライアントを初期化し、ローカルで動作しているMilvusサーバーへの接続を作成します。次に、コレクションのスキーマを定義し、各エントリに id (整数識別子)、vector フィールド (100次元の浮動小数点ベクトル)、text フィールド (関連するテキストデータを格納する) を指定します。
ステップ 3: Milvus における ScaNN インデックスの設定
このコレクションのインデックスタイプとしてScaNNを設定し、検索をより高速かつ効率的にするためにデータを整理する。
# nlist による ScaNN インデックスパラメータ
index_params = client.prepare_index_params()
index_params.add_index(
field_name="vector"、
index_type="SCANN", # インデックスタイプとしてScaNNを使用
metric_type="L2"、
nlist=128
)
# ScaNNインデックスを使用してMilvusにコレクションを作成する
コレクション名 = "scann_collection"
if client.has_collection(collection_name=collection_name):
client.drop_collection(collection_name=collection_name)
client.create_collection(
collection_name=collection_name、
schema=schema、
index_params=index_params
)
index_type="SCANN"を設定すると、Milvus は効率的な検索のために ScaNN を使用する。metric_type="L2"はMilvusがユークリッド距離を使って類似度を測定することを意味し、nlist=128はデータを128のクラスタに分割する。
ステップ4: Milvusへのデータ挿入
サンプル文書のvector embeddingsを生成し、Milvusに挿入する。このステップでは、各ベクトルを id とテキストデータと共にMilvusに格納する。
# 埋め込み関数の定義とサンプルデータの準備
embedding_fn = model.DefaultEmbeddingFunction()
docs = [
"人工知能は1956年に学問分野として設立された"、
"アラン・チューリングは、AIの実質的な研究を行った最初の人物である"、
「チューリングはロンドンのマイダ・ベイルで生まれ、イングランド南部で育った、
]
vectors = embedding_fn.encode_documents(docs)
# サンプルデータをMilvusに挿入する
data = [{"id": i, "vector": vectors[i], "text": docs[i]} for i in range(len(vectors))].
client.insert(collection_name=collection_name, data=data)
上記のコードでは、サンプル文書をベクターとしてエンコードし、Milvusに挿入している。各文書は一意な id と100次元ベクトル、そして参照用の原文とともに格納される。
ステップ5: Milvusでのベクトル検索の実行
次に、ScaNNをインデックスとしてMilvusでベクトル検索を実行する。サンプルクエリに最も近いベクトルを検索します。
# nprobeでScaNNインデックスを使ってMilvusでベクトル検索を実行する。
SAMPLE_QUESTION = "アラン・チューリングの功績は?"
query_vectors = embedding_fn.encode_queries([SAMPLE_QUESTION])
# ScaNNのnprobeを含む検索パラメータを設定する
search_params = {"nprobe":10} # 精度/速度のトレードオフに基づいてnprobeを調整する
search_res = client.search(
collection_name=collection_name、
data=query_vectors、
limit=1、
output_fields=["text"]、
search_params=search_params
)
# 結果を取得して表示する
context = search_res[0][0]["entity"]["text"] # 結果の取得と表示
print("検索結果:", context)
上記のコードでは、クエリをエンコードし、そのエンベッディングを使ってMilvusにマッチする可能性のあるクエリを検索している。nprobe=10を設定することで、Milvusに10クラスタ以内の検索を指示し、精度とパフォーマンスのバランスをとっている。limit=1パラメータを指定すると、検索結果が最も近いものに制限される。この検索を実行すると、クエリに最も近いドキュメントが検索され、最も関連性の高い結果を見ることができる。
これが期待される出力です:

図:MilvusのScaNNインデックスを使用したサンプルクエリの最も近いマッチング文書
出力はサンプルクエリに対する最も近い一致を示し、最も類似した文書のテキストを表示します。ご覧の通り、最も関連性の高い結果が質問に正しく答えています。これはMilvusとScaNNが正しい結果を取得できたことを意味します。
結論
ScaNN (Scalable Nearest Neighbors) は近似最近傍探索を実装するためのライブラリであり、大規模で高次元のデータセットに対して速度と精度のバランスを取る。クラスタリングや圧縮などの高度な技術により、推薦システム、画像検索、自然言語処理などの最新のアプリケーションに理想的なソリューションとなっている。
オープンソースのベクトルデータベースであるMilvusは、ScaNNをネイティブにサポートし、そのアーキテクチャに統合しているため、開発者は何十億ものベクトルデータを効率的に扱うことができるスケーラブルで量産可能なシステムを構築することができる。これらのツールを組み合わせることで、ベクトル検索における現実世界の課題に取り組むために必要な柔軟性とパフォーマンスを提供することができる。
ScaNNに加え、MilvusはHNSW、DiskANN、IVFなど、他の多くのタイプのANNアルゴリズムもサポートし最適化することで、最適なパフォーマンスを提供します。詳細については、Milvus documentation を参照してください。
その他のリソース
ScaNN GitHub リポジトリ](https://github.com/google-research/google-research/tree/master/scann)
ScaNN (Scalable Nearest Neighbors)とは](https://zilliz.com/learn/what-is-scann-scalable-nearest-neighbors-google)
ScaNN: 効率的なベクトル類似度検索の発表](https://research.google/blog/announcing-scann-efficient-vector-similarity-search/)
ANNベンチマークを理解する](https://zilliz.com/glossary/ann-benchmarks)
ベクトルデータベースとは何か、どのように機能するのか](https://zilliz.com/learn/what-is-vector-database)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
HNSWlib: A Graph-based Library for Fast ANN Search](https://zilliz.com/learn/learn-hnswlib-graph-based-library-for-fast-anns)

読み続けて

筏か否か?クラウドネイティブデータベースにおけるデータ一貫性のベストソリューション
PaxosやRaftのようなコンセンサスに基づくアルゴリズムが、なぜ銀の弾丸ではないのかを説明し、コンセンサスに基づくレプリケーションの解決策を提案する。

バイナリ量子化とMilvusによるベクトル検索の効率化
バイナリ量子化は、Milvusにおけるベクトルデータの管理および検索に対する革新的なアプローチであり、パフォーマンスと効率の両方において大幅な向上をもたらします。ベクトル表現をバイナリコードに単純化することで、ビット演算の速度を活用し、検索操作を大幅に高速化し、計算オーバーヘッドを削減します。

ScaNN(Scalable Nearest Neighbors)とは?
ScaNNはGoogleによって開発されたオープンソースのライブラリで、大規模なデータセットにおける高速な近似最近傍検索を行う。