




Harnessing Embedding Models for AI-Powered Search
As AI continues to evolve, the way we search and retrieve information has transformed, particularly when dealing with vast amounts of unstructured data. Traditional keyword-based search methods struggle to handle the complexity of modern datasets—especially when it comes to understanding meaning and context. This is where embedding models and vector embeddings come into play, enabling systems to grasp the relationships between words, images, and other data types.
At a recent Unstructured Data Meetup, Aamir Shakir, the Co-Founder of Mixedbread, shared insights on how to build and train embedding models to create high-performance AI systems, particularly Retrieval Augmented Generation (RAG) at scale. In this blog, we’ll recap the key points from his talk and explore the role of embedding models in powering advanced search systems. We’ll also cover techniques for training, scaling, and efficiently storing embeddings, including the use of compression methods and vector databases like Milvus and Zilliz Cloud (the managed Milvus).
 Aamir Shakir speaking at the August SF Unstructured Data Meetup
Aamir Shakir speaking at the August SF Unstructured Data Meetup
If you want to learn more about this topic, we recommend watching Aamir’s talk on YouTube.
What are Embedding Models and Why Do They Matter for Unstructured Data?
In a data-driven world, organizations are overwhelmed with vast amounts of unstructured data—logs, internal documents, audio, videos, and more. Extracting meaningful insights from such diverse data can be a significant challenge. This is where embedding models and vector embeddings come into play.
Embedding models are a type of machine learning model designed to transform unstructured data into numerical representations and project them in a high-dimensional space. These representations are called vector embeddings. They capture the relationships and meanings within the data, enabling computers to understand, process, and analyze it more effectively. The closer these vectors are located in the vector space, the more semantically similar they are.
Embedding models are fundamental tools in a wide range of tasks, from natural language processing (NLP) to computer vision and beyond.
Semantic Understanding
Embedding models encode the meaning of words, sentences, or documents into vectors, capturing their semantic relationships. By representing data in this way, these models allow machines to understand context and meaning, enabling more sophisticated tasks like question-answering, translation, and summarization.
Multilingual and Multimodal Capabilities
Advanced embedding models can handle multiple languages and data types (modalities) like text, images, and audio. This capability enables the comparison and retrieval of information across different languages or data formats. For example, a single model could retrieve similar content across text and images or translate and align text in multiple languages, all within the same vector space.
Transferability
Pre-trained embedding models can often be adapted (through techniques like fine-tuning) for different downstream tasks. Instead of training a model from scratch, you can leverage a pre-trained model and modify it for specific tasks, saving time and computational resources. This transferability makes embedding models highly efficient for building AI applications, whether for classification, recommendation systems, or other use cases.
Issues with Classical Search Approaches
Before the rise of embeddings, traditional search methods such as term frequency-inverse document frequency (TF-IDF) or keyword-based matching were used for information retrieval. However, these approaches work well for simple use cases but fail to capture the semantic relationships between words. They also have significant limitations when addressing today’s more complex information needs. There are several limitations:
Difficulty with Ambiguity
One of the primary challenges with traditional methods is their difficulty in handling ambiguity.
Words with multiple meanings (polysemy) and different words with the same meaning (synonymy) challenge traditional methods and lead to inaccurate results. Consider the word “bank.” A search for “bank” might return results about financial institutions when, in reality, the user was searching for information on riverbanks.
Embeddings solve this issue by considering the context in which a word appears. The word “bank” in finance will have a different vector representation from “bank” in the context of nature. This helps search systems to return results that are not just relevant but also contextually accurate.
Fixed Representations
Another limitation of traditional methods is their use of fixed representations for words or documents. These representations do not change to different contexts over time, which can limit their use in dynamic information retrieval.
Limited Scalability
Traditional methods struggle to maintain performance and efficiency as the data grows larger and more complex, mainly when dealing with web-scale information retrieval tasks. On the other hand, semantic search systems dealing with vector embeddings are designed to scale. Once the data is converted into vectors and stored in a vector database like Milvus, even billion-scale vector data can be handled effectively and used for fast and accurate retrieval. This makes embeddings important for systems like recommendation systems and RAG.
These limitations show the need for embeddings in building modern search systems that can understand and retrieve relevant content using meaning rather than keywords.
Embedding Models and Their Generalization Issues
Embedding models have become a cornerstone in AI applications, from RAG to recommendation systems and beyond. While these models are highly effective in encoding data and facilitating tasks like search and classification, they aren't without limitations—particularly when it comes to generalization.
Handling out-of-vocabulary (OOV) terms: Many embedding models have a fixed vocabulary, which causes problems when running across new words that were not part of the training data.
Long-tail Performance: While embedding models usually do well with common words and concepts, they could find difficulty with highly specific terms.
Domain Specificity: Embedding models trained on data from one domain may perform poorly when applied to a different domain. This limitation is because the embeddings contain the statistical patterns of the training data, which may not be effective for new types of data. Embedding models, therefore, usually require fine-tuning on domain-specific data to reach the best performance.
Bias in Embeddings: Embedding models are also sensitive to bias. They are trained on large, sometimes uncurated datasets. Hence, they can mistakenly absorb societal biases present in the data.
Contextual Variations: Static embedding models assign the same vector to a word regardless of context. This can be a problem for words that can have more than one meaning.
How to Build and Train a State-of-the-Art Embedding Model
Building a high-quality embedding model, especially for complex systems like RAG requires a thoughtful approach to ensure scalability, accuracy, and efficiency. Embedding models are typically built using neural networks, and the quality of the embeddings they generate depends heavily on the training process. To achieve state-of-the-art (SOTA) performance, several key steps must be followed:
Pretraining on Large, Diverse Datasets
A critical first step in building a robust embedding model is pretraining on large, diverse datasets. This pretraining exposes the model to a wide range of language patterns, structures, and contexts, allowing it to learn generalizable features that can be applied to various downstream tasks. The idea is to give the model a broad understanding of data, enabling it to perform well not just on familiar inputs but on new, unseen data as well.
There are different types of embeddings, including:
Word embeddings are low-dimensional, dense vectors that project words in a continuous vector space. They are useful in capturing semantic and syntactic relationships.
Conceptual embeddings are vector representations of concepts in a semantic space that capture their relationships and attributes, which frequently come from large-scale knowledge graphs.
Contextual embeddings are dynamic word representations generated by models such as BERT and GPT. They consider the surrounding context of each word in a phrase to produce contextually sensitive embeddings.
The following illustration will help you understand the training process of embedding models:
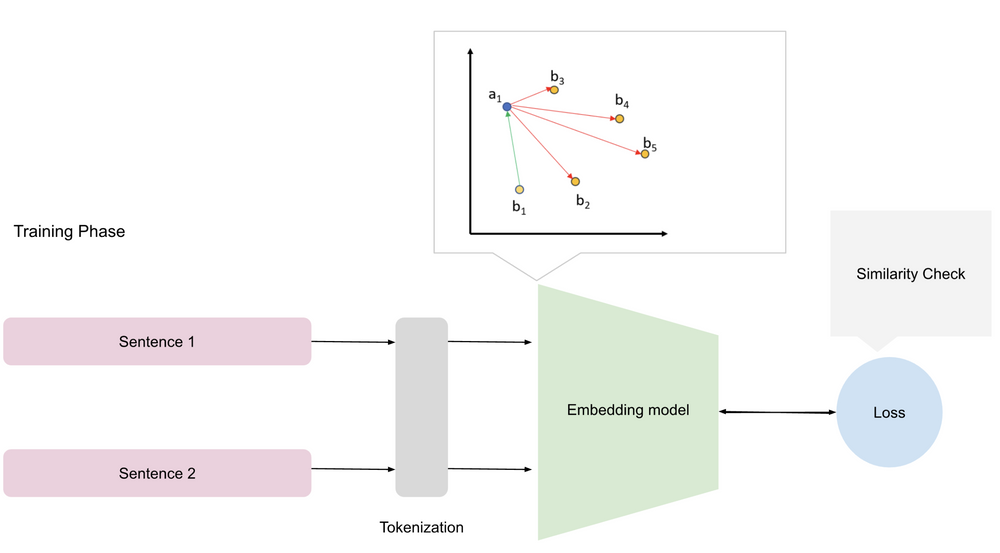 Training phase of the embedding model
Training phase of the embedding model
Tokenization breaks down input data into smaller units (tokens), such as words or subwords, creating a vocabulary for the model. The vocabulary is a set of unique tokens the model will use to understand and represent the data during training.
Embedding initialization initializes a matrix in which an embedding vector represents each token in the dataset. This matrix summarizes the relationships and meanings between tokens, with vectors typically ranging from 50 to 1,000 dimensions.
Training adjusts the model's parameters to minimize the distance between semantically similar words and maximize the distance between dissimilar words.
Fine-Tuning for Task-Specific Optimization
After the pretraining, fine-tuning is important to optimize the model for specific tasks. For instance, if the RAG system is being used in a legal context, we fine-tune the embedding model on legal documents. By doing this, embeddings maintain domain-specific vocabulary, which improves RAG system performance. During this stage, we also fine-tune the model to handle structured and unstructured data suitable for multimodal and multilingual search tasks.
Storing Vectors Embeddings at Scale
As embedding models become more advanced, the vectors they produce can become increasingly complex. While model complexity doesn’t always mean higher-dimensional vectors, larger models often generate embeddings with more detailed representations, sometimes leading to thousands of dimensions. This presents challenges in terms of both storage and retrieval, especially when dealing with large datasets or real-time applications.
To address these challenges, efficient storage and retrieval methods are crucial. Techniques like vector databases, approximate nearest neighbor (ANN) search, and optimized indexing structures are commonly used to ensure that embeddings can be quickly retrieved without sacrificing performance. In addition, compression techniques are also essential for reducing the size of these high-dimensional vectors without losing their semantic meaning.
Vector Databases
Vector databases such as Milvus and Zilliz Cloud (the managed version of Milvus), are specifically designed for efficiently managing and retrieving unstructured data in the form of vector embeddings. Milvus is an open-source vector database optimized for storing and searching vectors at mega scale. It uses approximate nearest neighbor (ANN) searches to quickly retrieve relevant embeddings, even when working with databases that contain billions of vectors. Zilliz Cloud offers the more advanced capabilities in a managed service, reducing the operational overhead of managing vector databases at scale.
Compression Techniques
While embeddings can be stored directly in vector databases, storing them at scale can be expensive. This is where compression techniques come in handy. The main idea behind compression is to reduce memory requirements and improve query speed. One type is binary quantization, and the other is scalar quantization.
Binary quantization reduces each feature of a given embedding into a binary digit, while scalar quantization reduces the overall size of dimensions to a smaller data type, like a 2-byte float or 1-byte integer.
For example, if an image is represented by three distinct features, where each feature holds a value in the range of a FLOAT-32 storage unit, performing binary quantization on this vector would result in each of the three features being independently represented by a single binary digit. Thus, the vector containing three FLOAT-32 values would be transformed into a vector of three binary digits, such as [1, 0, 1].
Understanding of binary quantization
Binary Quantization is highly effective for conducting vector searches on large datasets due to its efficient and less complex computations. In the case of Milvus and binary vectors, Milvus uses the Hamming Distance as a similarity metric. This metric can rapidly calculate the distance between two stored binary vectors. Here's an example of how the Hamming Distance method works.
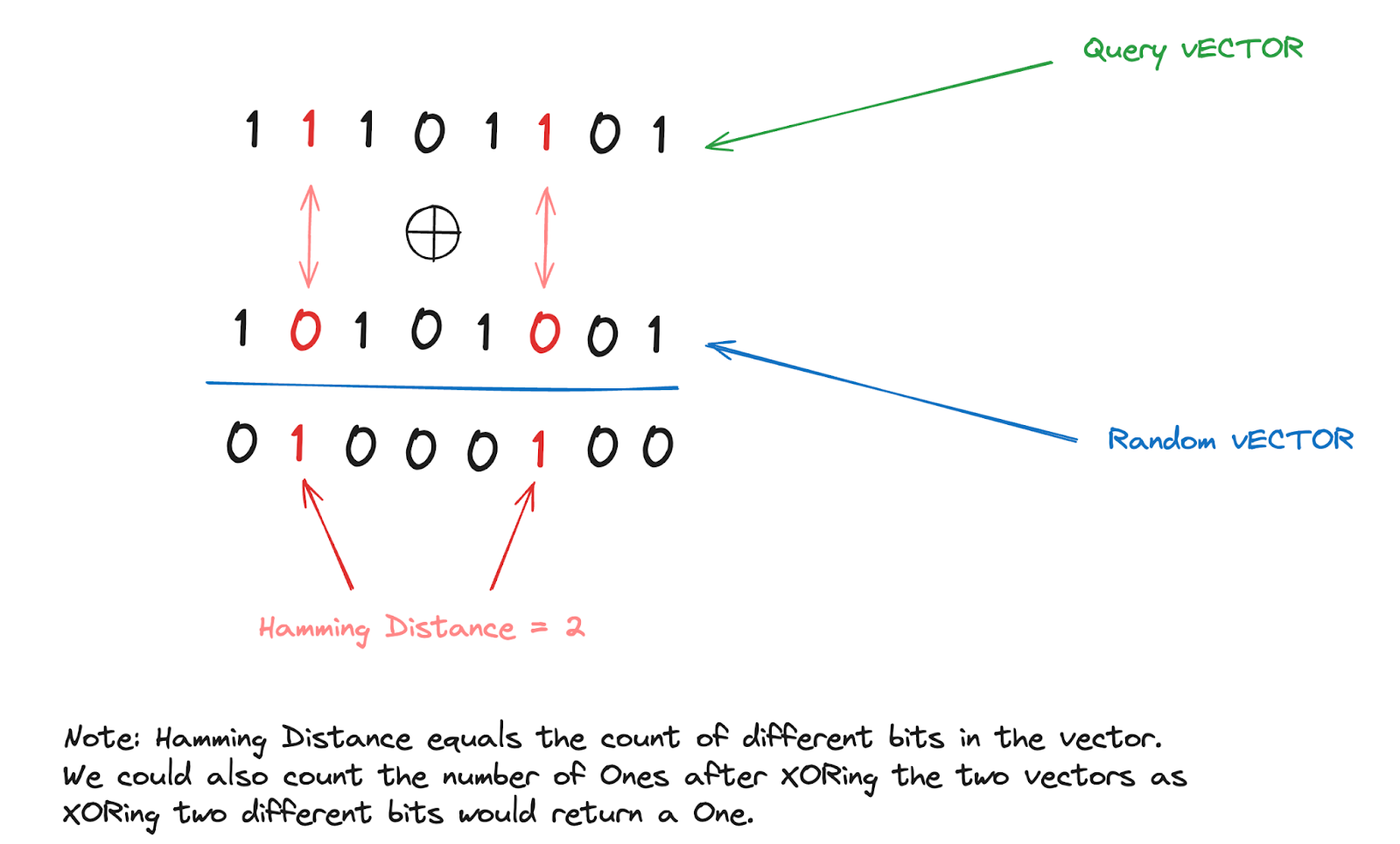 How the hamming distance method works
How the hamming distance method works
Now, we will use the scalar quantization technique to convert float32 embeddings into int8 format. This approach maps the continuous range of float32 values to a discrete set of 256 distinct int8 values, ranging from -127 to 127.
To perform scalar quantization:
Calculate the range: Determine the minimum and maximum values for each embedding dimension.
Determine the quantization step: Calculate the step size needed to distribute the float32 values evenly across the int8 range.
Quantize: Round each float32 value to the nearest int8 value using the calculated step size.
Values from -1.0 to 1.0 into discrete int8 values
With scalar quantization to int8, we reduce the original float32 embeddings' precision so that each value is represented with an 8-bit integer (4x smaller), thereby decreasing the amount of memory required to store them, while attempting to preserve as much information as possible.
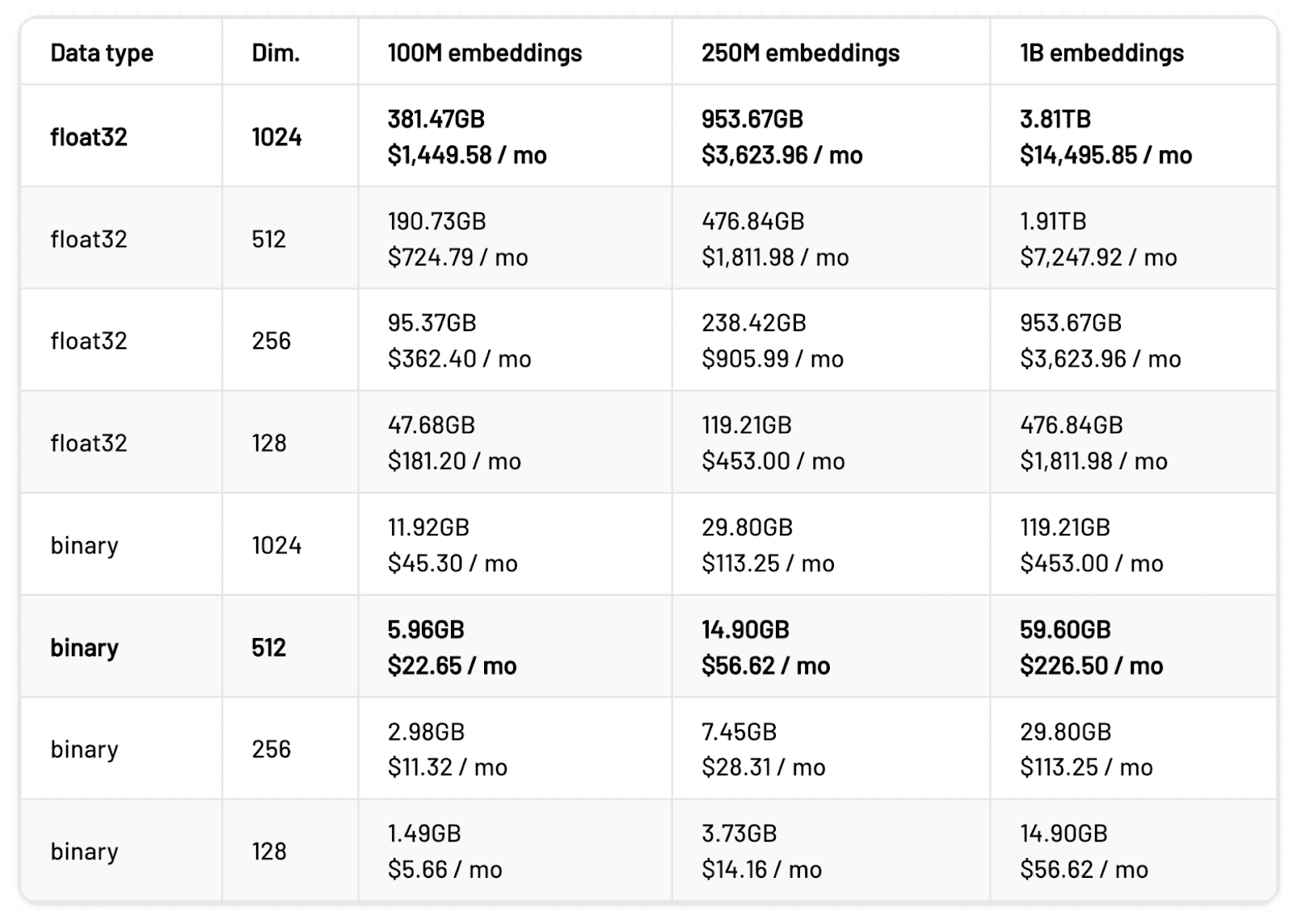 The economics of compression
The economics of compression
Summary
Embedding models—which provide a flexible, scalable, semantically rich approach to information retrieval—are helping define the direction of similarity search. From improving clustering and bi-text mining to allowing multimodal and multilingual search, embeddings provide many opportunities that traditional methods cannot reach.
Building state-of-the-art embedding models for high-quality RAG systems needs careful attention to pretraining, fine-tuning, and scalability. Zilliz Cloud and Milvus help manage embeddings at scale and create more intelligent and responsive neural search systems.
Further Resources

Keep Reading

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.