




Build Better Multimodal RAG Pipelines with FiftyOne, LlamaIndex, and Milvus
Introduction
At the recent Unstructured Data Meetup hosted by Zilliz, Jacob Marks, a machine learning engineer and developer evangelist at Voxel51, discussed the intricacies of building robust multimodal RAG pipelines using FiftyOne, LlamaIndex, and Milvus.
Watch the replay of Jacob's meetup talk
This talk focused on how we can use our data to build a better multimodal RAG pipeline. It emphasized using free and open-source tools, specifically leveraging FiftyOne for data management and visualization, Milvus as a vector store, and LlamaIndex for orchestrating large language models (LLMs).
Before we look at multimodal RAG, let’s look at an overview of RAG in general.
Overview of RAG in a Text-Based Context
Jacob begins by explaining text-based Retrieval Augmented Generation (RAG) and how it works. We’ll keep this brief as we’ve already covered text-based RAG systems in detail in this four-part series RAG handbook.
RAG enhances the capabilities of large language models (LLMs) by augmenting their knowledge with relevant external data. LLMs, despite being trained on vast datasets, often have limitations like knowledge cutoffs and hallucinations. RAG mitigates these issues by retrieving and incorporating relevant documents from an external vector database like Milvus or Zilliz Cloud to provide users with more accurate and contextually relevant responses.
The architecture of a text-based RAG system is simple. Let’s take a look at the RAG process.
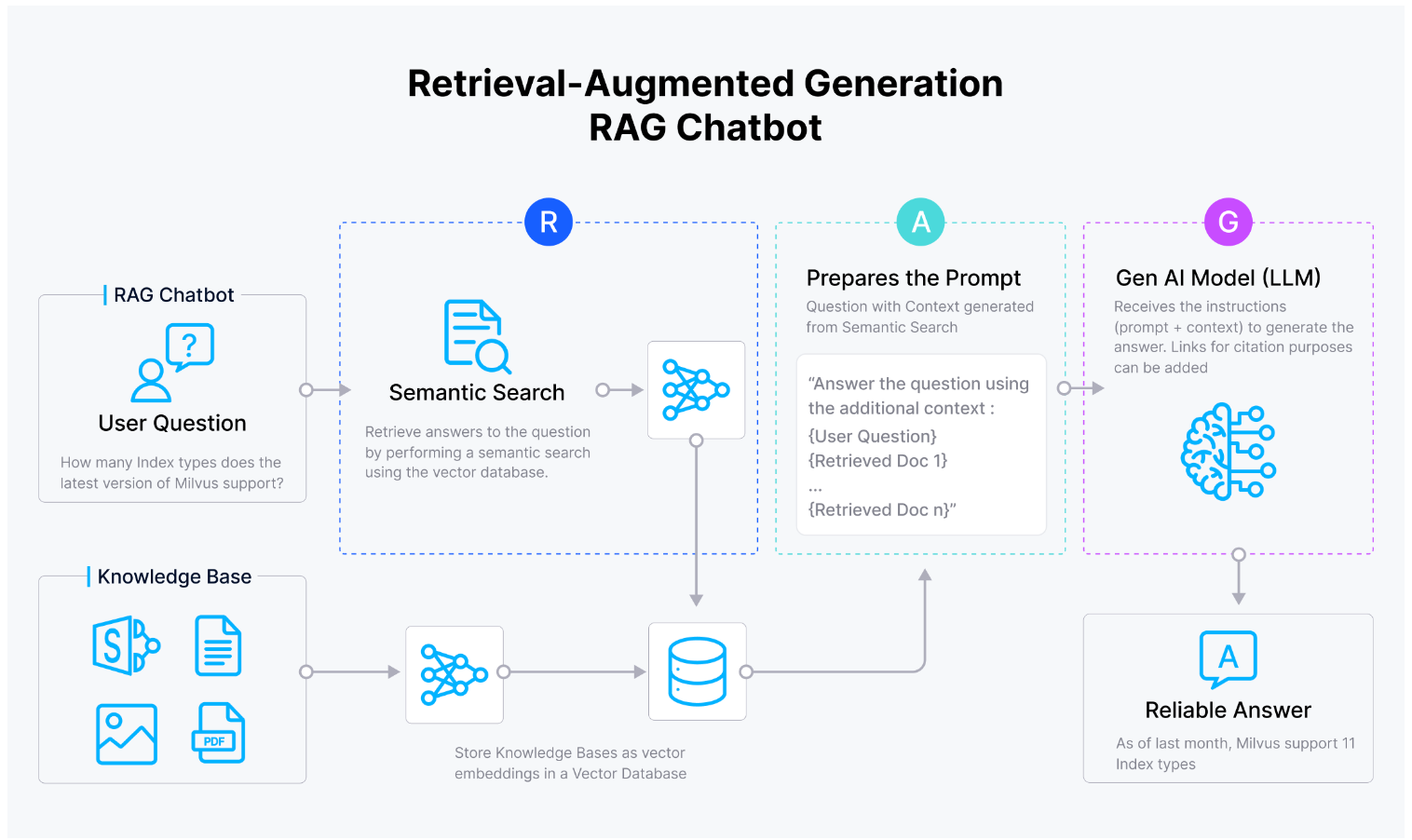 Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG)
Fig 1: RAG process of integrating LLMs with vector databases
In the above diagram, the documents are chunked into smaller text segments and then transformed into numerical representations known as vector embeddings. These embeddings are stored in a vector database like Milvus.
When a user provides a prompt, it is also converted into a vector embedding and used to query the vector database for the most relevant text passages. Combined with the original prompt, these relevant passages form a context-rich input for the LLM. Finally, the LLM processes this input to generate a more accurate and contextually relevant response.
This approach is highly effective for systems that depend solely on text. However, a text-based RAG system is insufficient for systems that need multiple data types to make informed decisions. Take an e-commerce shop, for instance. We can't rely only on text to present the most relevant product to a user; we need product images, descriptions, and more. This is where Multimodal RAG proves invaluable, leveraging modern multimodal LLMs to integrate various data modalities.
What are Multimodal LLMs and Their Applications
Multimodal LLMs such as GPT-4o and Qwen-VL are artificial intelligence systems capable of processing and understanding multiple data types, such as text, images, audio, and video. They integrate and interpret information from various modalities, enabling them to generate descriptive captions for images, answer questions about videos, and create content that combines text with visual elements. This capability allows them to better understand and generate contextually enriched responses by the diverse input data types.
They are applied in various domains, including medical services, retail, and more.
In the medical service industries, there are visual medical images, text-based clinical notes, and medical reports in the medical domain. Multimodal LLMs synthesize this multimodal information and help doctors in their work. An example is Med-PaLM LLM, which leverages both textual and visual data to enhance medical decision-making and improve patient care outcomes.
In retail, multimodal LLMs create customized advertisements and enhance product search capabilities. They process and integrate various types of data, such as text descriptions, images of products, and customer interaction data (e.g., reviews, and search queries). By analyzing this multimodal information, these LLMs can generate personalized advertisements tailored to individual preferences and browsing history.
Even with these advanced features, multimodal LLMs have the same limitations as text-based ones. They suffer from knowledge cutoffs and hallucinations. To mitigate these issues, we’ll need a multimodal RAG.
Understanding Multimodal RAG
Multimodal RAG is an advanced AI technique that combines information retrieval and generative modeling to enhance the capabilities of multimodal LLMs. To understand how multimodal RAG works, let's take a look at the following multimodal RAG retrieval pipeline.
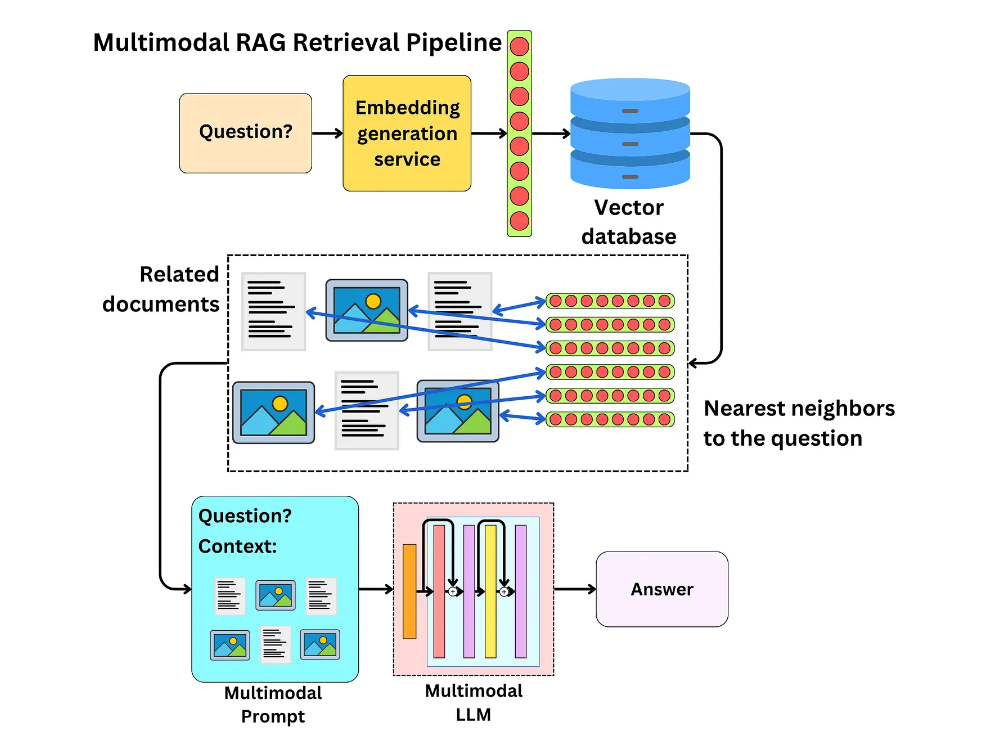 Fig 2- Multimodal RAG retrieval pipeline
Fig 2- Multimodal RAG retrieval pipeline
Fig 2: Multimodal RAG retrieval pipeline
When users ask a question, an embedding model first converts the query into an embedding. This embedding is then used to query a multimodal vector database like Milvus, which stores embeddings of related documents, including text and images. The vector database retrieves the nearest neighbors to the question, essentially the most relevant documents. The retrieved documents combine with the original question to form a multimodal prompt, incorporating both textual and visual context. A multimodal LLM then processes this enriched prompt, integrating the diverse data types to generate a more accurate and contextually relevant answer.
In the next section, let's get hands-on and see how to implement a multimodal RAG pipeline using FiftyOne, LLamaIndex, and Milvus.
Implementing a Multimodal RAG Pipeline Using FiftyOne, LLamaIndex, and Milvus
There are two ways to implement a multimodal RAG pipeline using FiftyOne, LLamaIndex, and Milvus. One is to write your own code, which gives you more control but takes more time, and the other is to use plugins that allow you to add functionality to the FiftyOne App.
This section will explore implementing the multimodal RAG Pipeline using the fiftyone-multimodal-rag-plugin powered by the Milvus vector database. If you want to code from scratch, here is a beginner’s guide on generating multimodal vector embeddings with Milvus and FiftyOne.
Setting Up Your Environment
Jacob dives into a demo with the installed multimodal plugin in the talk. Let’s slow that down, as a crucial installation step is not explicitly mentioned in either the demo or the plugin installation guide on GitHub. It is the Milvus installation step.
To use the plugin, you must already have a Milvus instance running on your computer. The Fiftyone plugin relies on Milvus to store and retrieve multimodal embeddings. The plugin assumes Milvus is running on http://localhost:19530. If you do not have Milvus installed, follow the Milvus documentation to install and run it.
After installing and running Milvus, follow these installation guidelines to install and configure the fiftyone-multimodal-rag-plugin. Once the setup is complete, launch the FiftyOne app and browse the available operations to see the functionalities provided by the plugin.
 Fig 3- FiftyOne available operations selection page
Fig 3- FiftyOne available operations selection page
Fig 3: FiftyOne available operations selection page
Let us now create the RAG pipeline.
Step 1: Create a Dataset from LLamaIndex Documents
This step involves selecting a folder containing your images and text files from your computer. You will embed this multimodal data and store the multimodal embeddings in Milvus. To load your dataset’s folder, select Create a Dataset from the LLamaIndex Documents operation. Then, name your dataset and choose its directory.
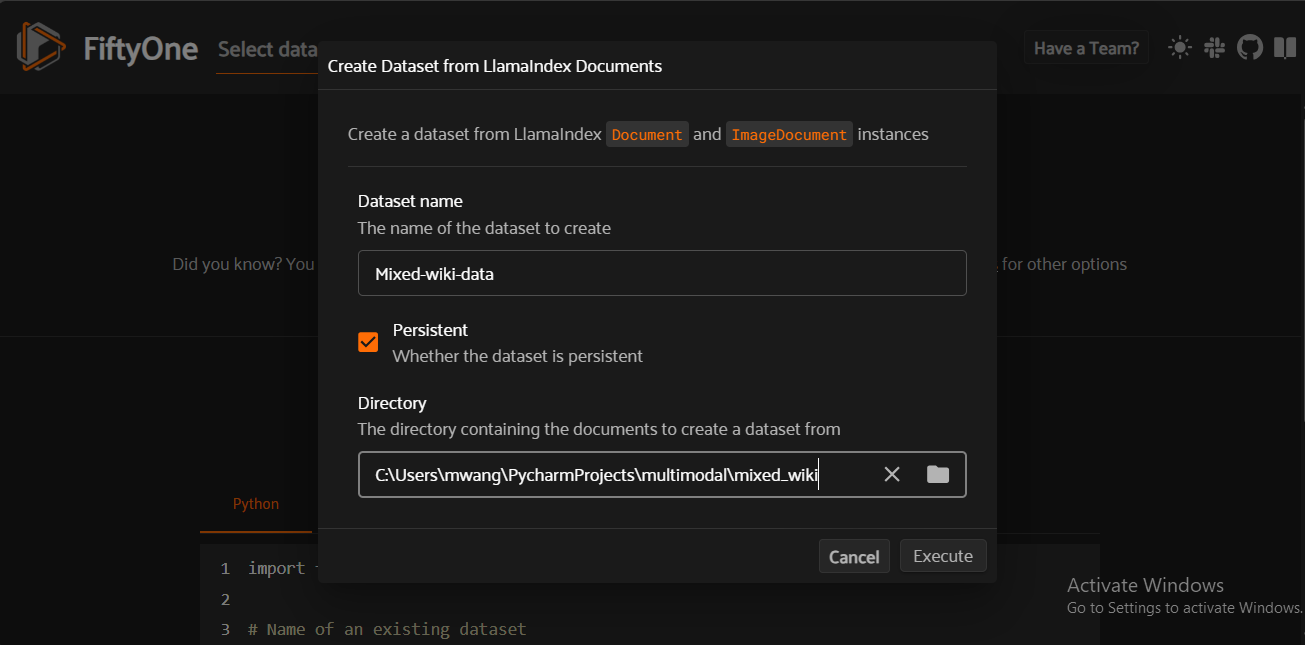 Fig 4- Creating a dataset from LLamaIndex documents
Fig 4- Creating a dataset from LLamaIndex documents
Fig 4: Creating a dataset from LLamaIndex documents
Click Execute to load and visualize your dataset.
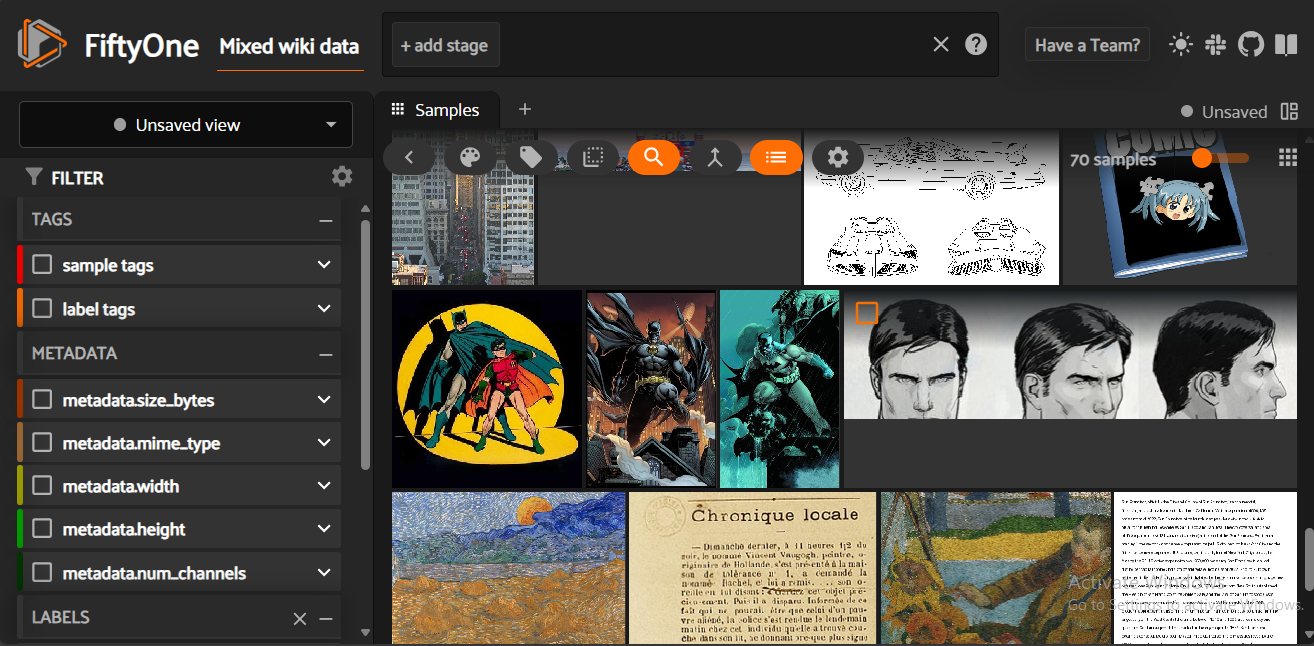 Fig 5- Visualization of a multimodal dataset in FiftyOne
Fig 5- Visualization of a multimodal dataset in FiftyOne
Fig 5: Visualization of a multimodal dataset in FiftyOne
In the visualization, you can see the dataset is composed of images and text making it multimodal. The next step is to create a multimodal RAG index of the dataset above.
Step 2: Integrating LlamaIndex with Milvus to Create a Multimodal RAG Index
To create a Multimodal RAG index using LlamaIndex and Milvus, you must integrate the two libraries to efficiently manage and retrieve multimodal data. LlamaIndex handles the ingestion and embedding of multimodal data into vector representations. These embeddings are then stored in Milvus for later retrieval during querying.
In the FiftyOne operations selection page, select the Create Multimodal RAG Index operation. Then, name your index and click execute.
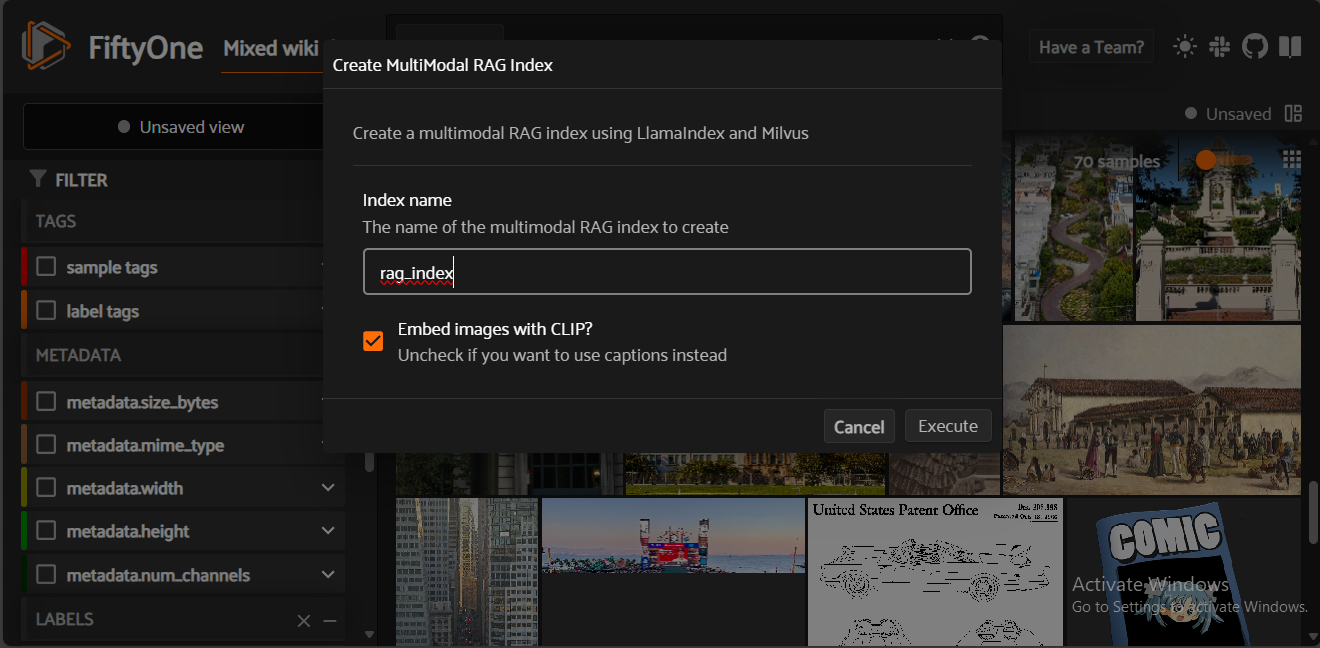 Fig 6- Creation of a Multimodal RAG index using LLamaIndex and Milvus
Fig 6- Creation of a Multimodal RAG index using LLamaIndex and Milvus
Fig 6: Creation of a Multimodal RAG index using LLamaIndex and Milvus
The execution will take some time, depending on the size of your dataset, so be patient. During this process, your dataset will be converted into vector embeddings and stored in Milvus. The larger your dataset is, the more time it takes to create the index. After the RAG index is created, you can proceed to query it.
Step 3: Querying the Multimodal RAG Index
This querying step takes the most time to execute in the RAG pipeline. As we all know, nobody likes a slow application. This is why the vector database to be queried should be fast during the retrieval process while also being accurate. This is where Milvus, the most widely adopted open-source vector database, wins.
Jacobs talks about Milvus in the talk, but since the plugin abstracts most of what is going on under the hood, we may not fully see the benefits of Milvus in multimodal RAG pipelines. But let us look at why most multimodal RAG developers, including the developer of the fiftyone-multimodal-rag-plugin, chose to use Milvus:
Billion-Scale Vector Storage and Retrieval: Milvus efficiently manages billion-scale vector data, ensuring rapid access with millisecond-level latency.
Horizontal Scalability: Milvus is highly scalable and adapts to meet your evolving needs as your business grows.
Ideal for RAG: Milvus is an indispensable infrastructure for building various GenAI applications, particularly retrieval augmented generation (RAG).
High-Speed Retrieval: With optimized search algorithms, Milvus enables rapid and accurate retrieval of relevant vectors, which is essential for real-time applications like interactive AI systems and recommendation engines.
Multimodal Data Handling: Milvus supports various data types and can perform hybrid searches. This capability allows for combining multimodal search, hybrid sparse and dense search, and hybrid dense and full-text search, offering versatile and flexible search functionality.
To query your multimodal RAG index, go to the Operations selection page and select the Query Multimodal RAG Index operation. Then, enter your query, select the index to use, the LLM to generate a response, the number of text results, and finally, the number of image results to include.
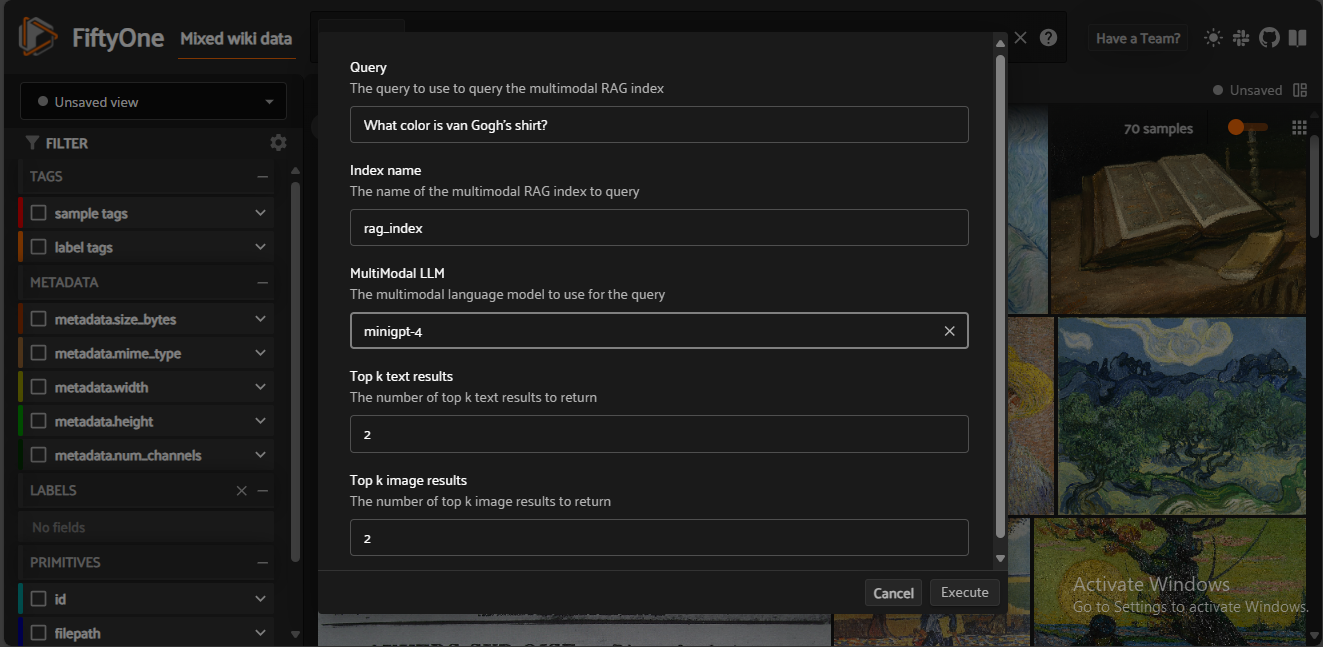 Fig 7- Querying a multimodal RAG Index powered by Milvus
Fig 7- Querying a multimodal RAG Index powered by Milvus
Fig 7: Querying a multimodal RAG Index powered by Milvus
The plugin then uses Milvus to perform a vector similarity search to retrieve the most relevant embeddings based on your query. The retrieved embeddings provide the context for generating a response using the selected large language model. Here are the results for the above query:
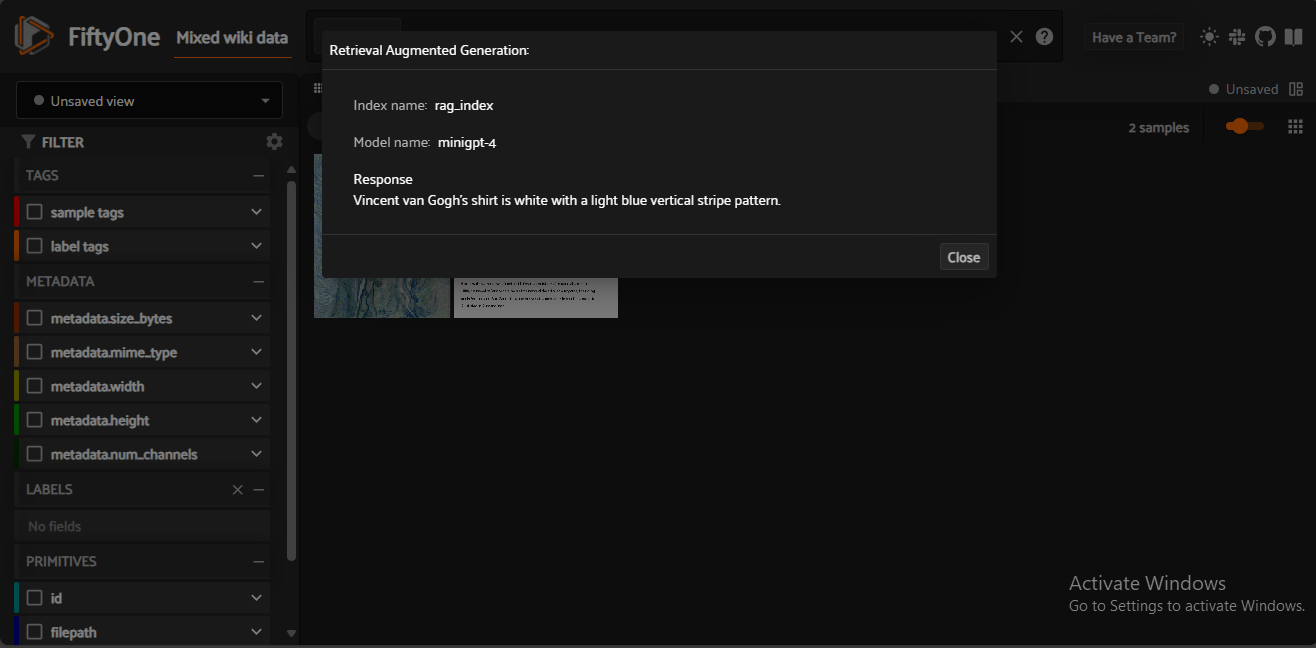 Fig 8- Results of querying a multimodal RAG Index
Fig 8- Results of querying a multimodal RAG Index
Fig 8: Results of querying a multimodal RAG Index
The results show the index and model you used while executing the query and the response generated by the large language model.
You have completed all the steps for creating a multimodal RAG pipeline using FiftyOne, LLamaIndex, and Milvus so far.
Conclusion
Jacob's presentation highlighted the potential of integrating FiftyOne, LlamaIndex, and Milvus to build powerful multimodal RAG pipelines. These tools enhance the capabilities of multimodal systems by efficiently leveraging text and visual data for improved data retrieval and context-rich responses. By following the outlined steps, you can harness the strengths of these open-source tools, with Milvus providing robust vector storage and high-speed retrieval, elevating your projects to new heights.
Further Resources
Keep Reading

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.