




The Evolution of Search: From Traditional Keyword Matching to Vector Search and Generative AI
Explores the evolution of search, the limitations of keyword-matching systems, and how vector search and GenAI are setting new standards for modern search.
Read the entire series
- What is Information Retrieval?
- Information Retrieval Metrics
- Search Still Matters: Enhancing Information Retrieval with Generative AI and Vector Databases
- Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
- What Are Rerankers and How Do They Enhance Information Retrieval?
- Understanding Boolean Retrieval Models in Information Retrieval
- Will A GenAI Like ChatGPT Replace Google Search?
- The Evolution of Search: From Traditional Keyword Matching to Vector Search and Generative AI
- What is a Knowledge Graph (KG)?
In today's digital age, with a wealth of information available at our fingertips, search engines have become indispensable tools. From helping us find the latest news to locating specific research papers, these engines guide us through vast amounts of data to find exactly what we need. However, the way search engines retrieve and present information has evolved significantly, from the early days of simple keyword matching to the rise of advanced algorithms and technologies like vector search and Generative AI (GenAI), which we see today.
This blog will explore the evolution of search, the limitations of traditional systems, and how modern technologies like vector search and AI are setting new standards for accuracy and relevance.
An Overview of Traditional Search Engines
Search engines are software systems that extract information relevant to user queries from the vast world of the Internet. Based on a search query entered within a web browser, they index millions of web pages, documents, and resources and deliver results comprising a list of hyperlinks along with images and textual summaries.
The earliest innovations of search engines started around 1990 with simple indexing tools. Archie, created in 1990 at McGill University, was based on File Transfer Protocol (FTP) to index and help users locate files. Later, in 1993, it was followed by a similar indexing tool called Veronica, which indexed Gopher files. Gopher files belonged to the Gopher protocol, which provided access to information using an online hierarchical directory-based system.
The advent of web-based search engines started with the invention of WebCrawler in 1994, the first tool to index the full text of web pages. Later, it was followed by Lycos, AltaVista, and Yahoo. These early search engines laid the groundwork for modern giants such as Google and Bing. Officially launched in 1998, Google quickly became popular because of its PageRank algorithm. Using keyword matching, it ranked search results based on the relevance and quantity of hyperlinks pointing to web pages, generating accurate results. Later, in 2009, Microsoft released Bing, which gained attention due to its image-based search feature and integration with other Microsoft products.
Basic Functionalities of Search Engines
Search engines function through these three primary processes - crawling, indexing, and retrieving.
Crawling: The first step is to explore the internet as much as possible with the help of bots known as crawlers or spiders. These bots discover content on the web by continuously following links from one page to another.
Indexing: The second step is to analyze the discovered content. The content is first stored in a vast database and indexed using keywords, metadata, and other relevant information.
Retrieving: The final step is to retrieve the analyzed content. When a user enters a query, the search engine presents the retrieved content from the database in the order of relevance.
The algorithms used in search engines play a crucial role in determining the search results. They assess the user query and output relevant results using numerous factors such as keyword density, click-through rates, site authority, etc. For example, Google’s PageRank algorithm ranks a web page based on the quality and number of links pointing to it. Algorithms also personalize results based on user location, search history, and other preferences.
Limitations of Traditional Search Systems
While traditional search systems are powerful in many ways, they present several limitations.
Difficulty in understanding context and semantic meaning. Traditional search systems often fail to fully grasp the user’s intent in the query. They struggled to understand the deeper meaning behind the words as their approaches were based on keyword matching, leading to less accurate results.
Challenges with handling natural language queries. Queries entered by users are composed of natural language, similar to a casual conversation, but search engines are more capable of understanding only the keywords rather than the whole complex sentence or question.
Issues with synonymy and polysemy
Synonymy - Using different words with similar meanings can lead to missed results if the system only searches for exact matches.
Polysemy - A word with multiple meanings can lead to irrelevant results if the system cannot discern the correct context.
These limitations highlight the need for more advanced search technologies to understand and process natural language better, paving the way for the development of modern search engines.
The Emergence of Vector Similarity Search
As the volume and complexity of information continue to grow, the need for more sophisticated search methods has become apparent. Vector Search or Vector Similarity Search is the latest search technique used in modern search engines that can understand the semantic meaning of data. This approach allows for more accurate and context-aware retrieval of information.
The main idea behind vector search is to represent unstructured data such as text, images, audio, and videos in numerical representations called vector embeddings in a high-dimensional space and then find similarities between those vectors. The closer these vectors are located, the more similar they are. This representation allows users to leverage machine learning algorithms for effective processing. Unlike traditional search systems that rely on a keyword-matching approach, vector search can understand the context and semantics of user queries and generate more relevant results.
How Vector Search Works
Encoding: The first step is to encode the data into embeddings using existing pre-trained word embedding models such as Word2Vec and GloVe or advanced transformer models such as BERT or RoBERTa. These models can even be fine-tuned to your dataset.
Indexing: The next step is to store the embeddings in a vector database like Milvus or Zilliz Cloud (fully managed Milvus), which is purpose-built to store, index, and query these embeddings. Indexing algorithms then organize these vectors efficiently to quickly retrieve and compare them during the search process. Think of it as how books are stored in a library section-wise, so it's easy for us to pick one.
Querying: Finally, when a search query is entered, it is also encoded into a vector using an embedding model. The vector search system (usually the vector database) then compares this query vector with the indexed vectors to find the most similar ones.
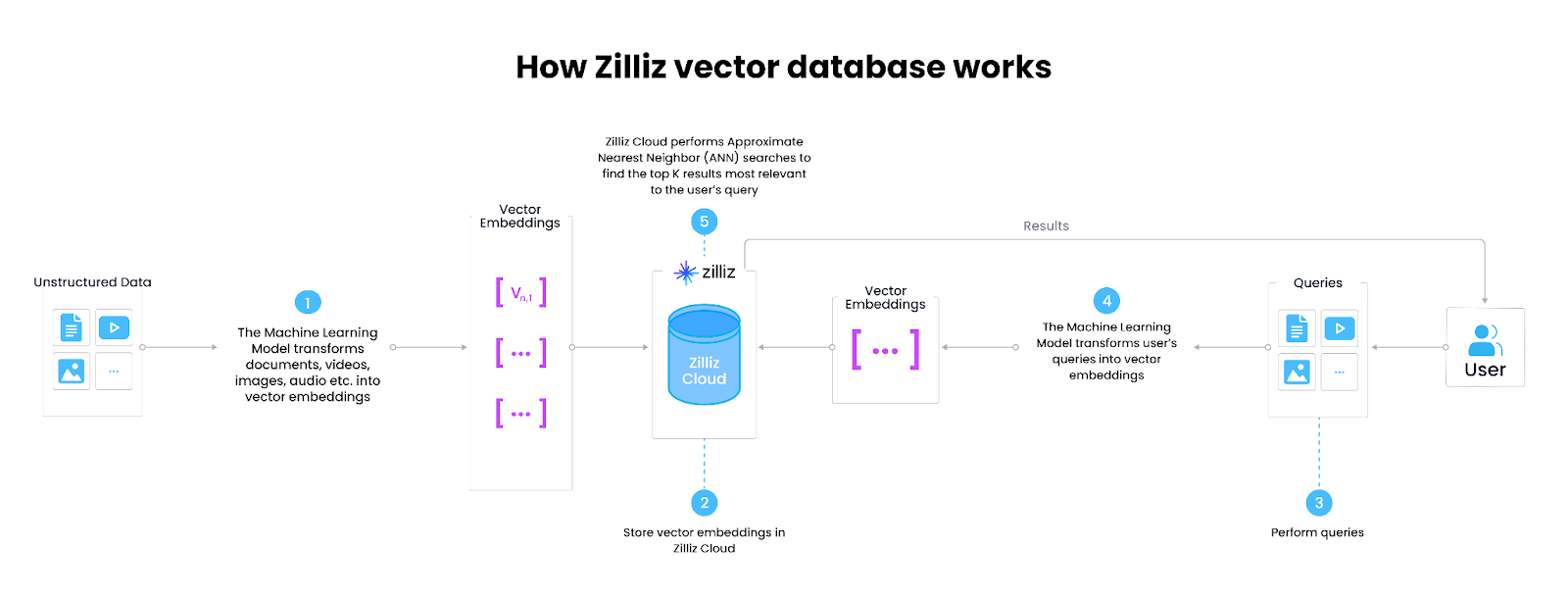 Figure 1- How vector databases work
Figure 1- How vector databases work
Figure 1: How vector databases work
In vector search, the relevance of results is determined by measuring the similarity between the query and document vectors. Some of the popular similarity metrics used are:
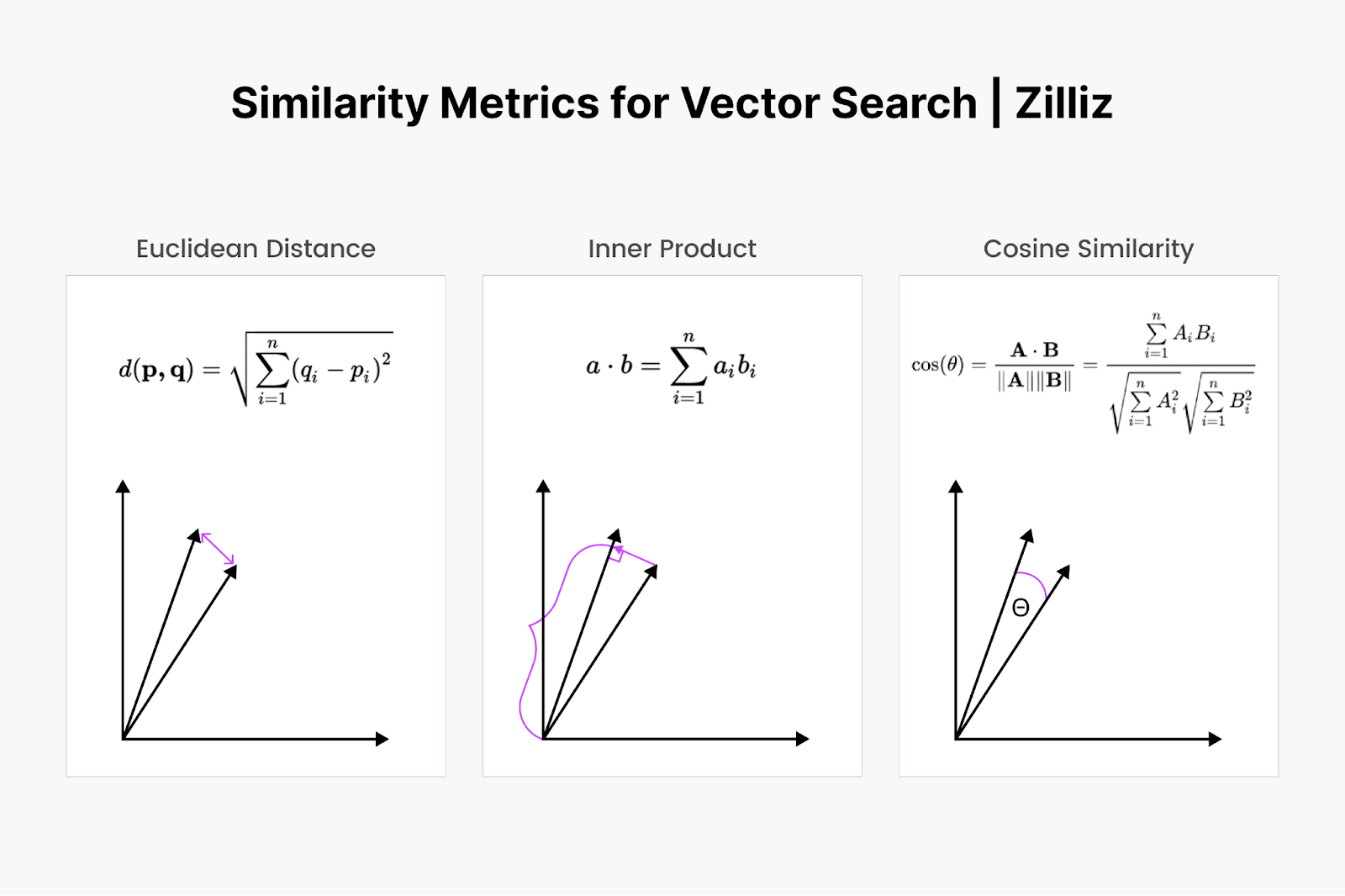 Figure 2- Similarity Metrics for Vector Search
Figure 2- Similarity Metrics for Vector Search
Figure 2: Similarity Metrics for Vector Search
Euclidean Distance (L2) - It finds the straight-line distance between two vectors by calculating the square root of the sum of squared differences between the coordinates. It is more sensitive to the magnitude of the vectors. Hence, it is useful in certain applications where the magnitude is important.
Cosine Similarity - It measures the cosine of the angle between two vectors. This metric is commonly used because it focuses on the orientation (how closely the vectors align) rather than the magnitude of the vectors, making it ideal for comparing text embeddings.
Inner Product: The inner product is the projection of one vector onto the other. The inner product's value is the vector's length drawn out. The bigger the angle between the two vectors, the smaller the inner product. It also scales with the length of the smaller vector. So, we use the inner product when we care about orientation and distance. For example, you would have to run a straight distance through the walls to your refrigerator.
Key Benefits of Vector Search
Semantic and Contextual Understanding - Vector search enables understanding complex relationships and similarities between entities, providing more meaningful retrieval. Hence, it improves the handling of natural language queries.
Scalability - Vector search's fast computational speed makes it highly scalable. It can easily extract queries from massive datasets.
Personalization - Vector search allows for personalization of services. Based on user preferences and item attributes, retailers or streaming services can easily present similar items and engage their user base for a better experience.
Applications of Vector Search
Semantic Search - Vector search improves the accuracy and relevance of search engine results by understanding the semantic meaning of queries. This allows users to find content that matches their intent, even if the exact keywords aren't present.
Recommendation Systems - Vector search powers recommendation engines by finding items similar to those a user has interacted with. It helps suggest products, movies, music, or content that align with a user's preferences, enhancing personalization and user satisfaction.
Image, Video, and Multimodal Search - Vector search retrieves images or videos that are visually similar to a query. It compares visual features encoded as vectors, allowing for efficient search and retrieval of multimedia content based on appearance or content similarity.
Retrieval Augmented Generation (RAG): With the rise of large language models (LLMs) like ChatGPT, vector search is used to mitigate hallucinations in LLMs by providing them with additional contextual information. We will cover this technique in detail in the following sections.
For more use cases of vector search, refer to our use case page or read this blog covering top use cases of vector search in 2024.
Implementing Vector Search with Milvus
Milvus is an open-source vector database for AI applications of all sizes. It can handle billion-scale vectors with a millisecond-level latency. Milvus offers various deployment options that can scale alongside your project, from running a demo chatbot in a Jupyter Notebook to building enterprise-level AI search.
In this section, we’ll use Milvus as an example to showcase how to implement a vector search efficiently,
- Install Milvus
We will use Milvus Lite, a Python library in Pymilvus that can be embedded into the client application.
Before proceeding, make sure that Python 3.8+ is available in the local environment. Let’s install pymilvus, which contains both the Python client library and Milvus Lite.
pip install -U pymilvus
- Set Up Vector Database
To create a local Milvus vector database, simply instantiate a MilvusClient by specifying a file name to store all data, such as "milvus_demo.db".
from pymilvus import MilvusClient
client = MilvusClient("milvus_demo.db")
- Create a Collection
Milvus requires creating a collection to store vectors and their associated metadata. When creating a collection, you can define the schema and various index params to configure vector specs such as dimensionality, index types, and distant metrics. For now, we will use the default settings.
if client.has_collection(collection_name="demo_collection"):
client.drop_collection(collection_name="demo_collection")
client.create_collection(
collection_name="demo_collection",
dimension=768, # vector dimensions will be 768
)
Prepare Data
- Installing Model Library
We need to generate vectors for text with an embedding model. PyMilvus is the Python SDK for Milvus, which seamlessly integrates various popular embedding models. You can easily use these functions from pymilvus[model] library.
Let’s install the model library containing essential ML tools such as PyTorch.
pip install "pymilvus[model]"
- Generate Vector Embeddings
Milvus expects data organized as a list of dictionaries, each representing a data record. So, let’s first organize the data and then use the default model to generate the embeddings.
from pymilvus import model
# This will download a small embedding model "paraphrase-albert-small-v2" (~50MB)
embedding_fn = model.DefaultEmbeddingFunction()
# Text strings to search from
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England.",
]
vectors = embedding_fn.encode_documents(docs)
# The output vector has 768 dimensions, matching the collection that we just created.
print("Dim:", embedding_fn.dim, vectors[0].shape) # Dim: 768 (768,)
# Each entity has id, vector representation, raw text, and a subject label that we use
# to demo metadata filtering later.
data = [
{"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"}
for i in range(len(vectors))
]
print("Data has", len(data), "entities, each with fields: ", data[0].keys())
print("Vector dim:", len(data[0]["vector"]))
Output:
Dim: 768 (768,)
Data has 3 entities, each with fields: dict_keys(['id', 'vector', 'text', 'subject'])
Vector dim: 768
- Insert Data
Let’s insert the data into the collection.
res = client.insert(collection_name="demo_collection", data=data)
print(res)
Output:
{'insert_count': 3, 'ids': [0, 1, 2], 'cost': 0}
- Semantic Search
Now, let’s perform a semantic search by representing the search query text as a vector and conducting a similarity search on Milvus.
Milvus accepts one or multiple vector search requests at a time. The query_vectors variable contains a list of vectors, each an array of float numbers.
query_vectors = embedding_fn.encode_queries(["Who is Alan Turing?"])
res = client.search(
collection_name="demo_collection", # target collection
data=query_vectors, # query vectors
limit=2, # number of returned entities
output_fields=["text", "subject"], # specifies fields to be returned
)
print(res)
Output:
data: ["[{'id': 2, 'distance': 0.5859944820404053, 'entity': {'text': 'Born in Maida Vale, London, Turing was raised in southern England.', 'subject': 'history'}}, {'id': 1, 'distance': 0.5118255615234375, 'entity': {'text': 'Alan Turing was the first person to conduct substantial research in AI.', 'subject': 'history'}}]"] , extra_info: {'cost': 0}
The output is a list of results, each mapping to a vector search query. Each query contains a list of results, where each result contains the entity primary key, the distance to the query vector, and the entity details with specified output_fields.
- Vector Search with Metadata Filtering
Milvus provides the metadata filtering feature. You can also conduct a vector search while specifying certain criteria for metadata values. For example, let’s filter the search with the ‘subject’ field in the following example.
# Insert more docs in another subject.
docs = [
"Machine learning has been used for drug design.",
"Computational synthesis with AI algorithms predicts molecular properties.",
"DDR1 is involved in cancers and fibrosis.",
]
vectors = embedding_fn.encode_documents(docs)
data = [
{"id": 3 + i, "vector": vectors[i], "text": docs[i], "subject": "biology"}
for i in range(len(vectors))
]
client.insert(collection_name="demo_collection", data=data)
# This will exclude any text in "history" subject despite close to the query vector.
res = client.search(
collection_name="demo_collection",
data=embedding_fn.encode_queries(["tell me AI related information"]),
filter="subject == 'biology'",
limit=2,
output_fields=["text", "subject"],
)
print(res)
Output:
data: ["[{'id': 4, 'distance': 0.27030569314956665, 'entity': {'text': 'Computational synthesis with AI algorithms predicts molecular properties.', 'subject': 'biology'}}, {'id': 3, 'distance': 0.16425910592079163, 'entity': {'text': 'Machine learning has been used for drug design.', 'subject': 'biology'}}]"] , extra_info: {'cost': 0}
In addition to vector search, you can also perform other types of searches. Head over to the official documentation for implementing vector search with Milvus to learn more details.
The Role of Generative AI and Retrieval-Augmented Generation (RAG) in Modern Search
As search technology evolves, Generative AI and Retrieval Augmented Generation (RAG) have emerged as transformative tools that significantly enhance search's magic.
Generative AI, exemplified by large language models like ChatGPT, has redefined search engines by enhancing their ability to understand, process, and generate answers in natural language. Unlike traditional AI methods, Generative AI can create coherent, human-like text responses based on what they learned from their pre-trained knowledge, allowing search engines to deliver more intuitive and contextually accurate results. This advancement makes interactions with search engines more seamless, enabling users to receive answers that closely match their queries and intent.
RAG is an improved retrieval technique that merges the strengths of vector search-based retrieval methods with generative models for mitigating the notorious LLM hallucinations. In RAG, a retrieval system first identifies the most relevant documents or pieces of information using vector search to a user query from a vector database like Milvus, which is then used by a generative model like ChatGPT to create a comprehensive and contextually accurate response. This approach is particularly effective in applications like chatbots, customer support, and content creation, where understanding context and providing detailed answers is crucial.
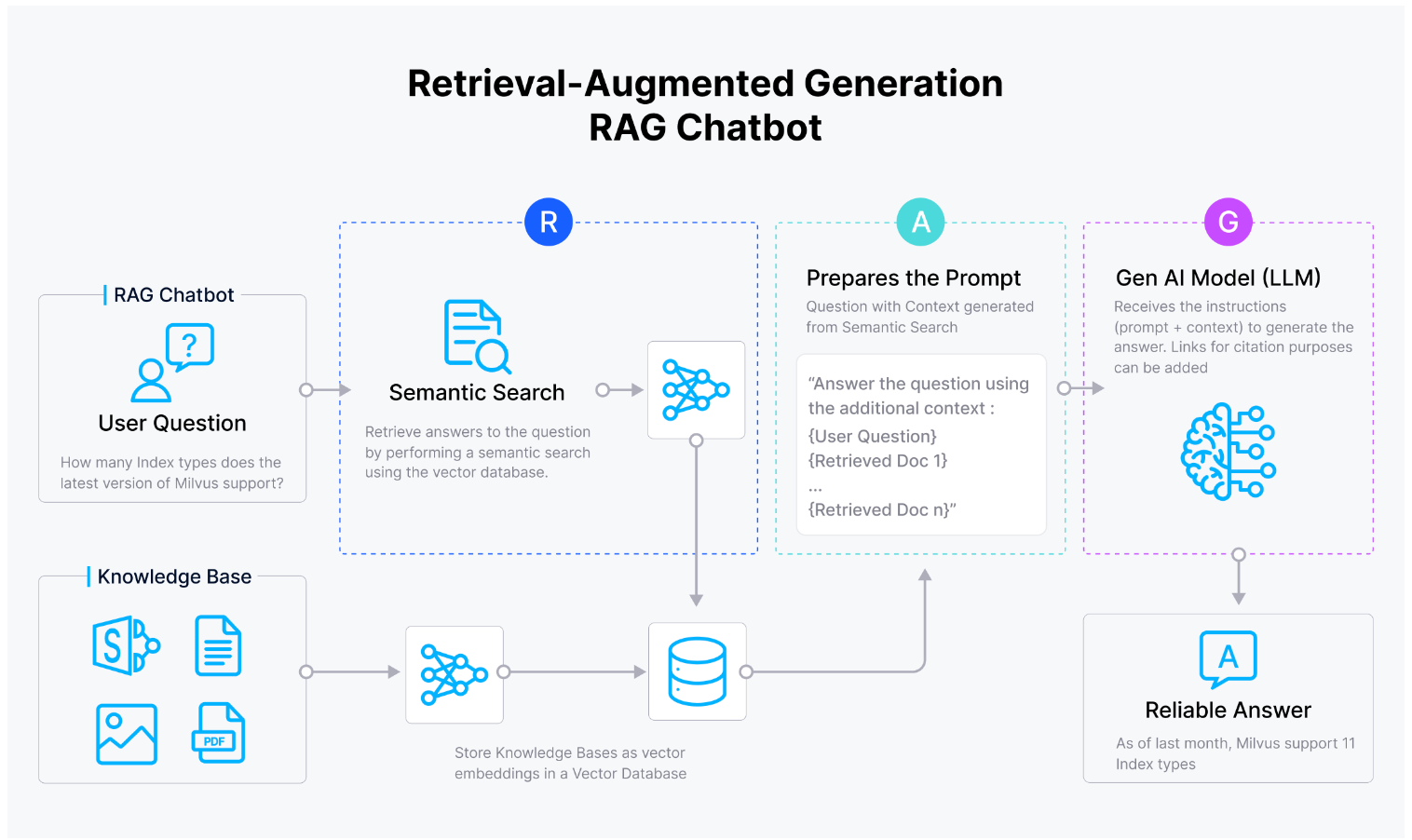 Figure- Vector database facilitating RAG chatbot
Figure- Vector database facilitating RAG chatbot
Figure 3: How RAG works
The Future of Search: A Combination of AI, Vector Search and Keyword Search
The future of search will be shaped by a strategic integration of keyword search, vector search, and generative AI, each addressing specific needs. AI will enhance search by analyzing patterns in user behavior, enabling a deeper understanding of complex queries. Vector search will excel at retrieving semantically similar content, making it ideal for multimedia and context-based searches. Keyword search will remain essential for tasks requiring exact matches and precise results. Together, these technologies will offer a comprehensive search experience that is accurate and adaptable to the diverse ways we seek information.
Conclusion
The evolution of search technology from simple keyword-based systems to vector search and to GenAI-powered modern search reflects the growing complexity and demands of the digital age. As we continue to generate and consume massive amounts of information, these technologies will play a crucial role in ensuring we can access the most relevant and accurate data quickly and efficiently. Understanding and leveraging these modern search techniques will be key to staying ahead in the ever-evolving information retrieval landscape.
For those interested in harnessing the power of vector search, GenAI, and RAG, the following resources can help you gain a deeper understanding.
 Yesha Shastri
Yesha ShastriYesha Shastri, Freelance Technical Writer in AI/ML
- An Overview of Traditional Search Engines
- The Emergence of Vector Similarity Search
- The Role of Generative AI and Retrieval-Augmented Generation (RAG) in Modern Search
- The Future of Search: A Combination of AI, Vector Search and Keyword Search
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Search Still Matters: Enhancing Information Retrieval with Generative AI and Vector Databases
Despite advances in LLMs like ChatGPT, search still matters. Combining GenAI with search and vector databases enhances search accuracy and experience.

Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
Milvus enables hybrid sparse and dense vector search and multi-vector search capabilities, simplifying the vectorization and search process.
Understanding Boolean Retrieval Models in Information Retrieval
Boolean retrieval models are an information retrieval method for retrieving relevant documents using a set of Boolean logic operators, eg. AND, OR, and NOT.