




Search Still Matters: Enhancing Information Retrieval with Generative AI and Vector Databases
Despite advances in LLMs like ChatGPT, search still matters. Combining GenAI with search and vector databases enhances search accuracy and experience.
Read the entire series
- What is Information Retrieval?
- Information Retrieval Metrics
- Search Still Matters: Enhancing Information Retrieval with Generative AI and Vector Databases
- Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
- What Are Rerankers and How Do They Enhance Information Retrieval?
- Understanding Boolean Retrieval Models in Information Retrieval
- Will A GenAI Like ChatGPT Replace Google Search?
- The Evolution of Search: From Traditional Keyword Matching to Vector Search and Generative AI
- What is a Knowledge Graph (KG)?
The history of search dates back to the very inception of the internet. Finding information online would be nearly impossible without search engines. The first internet search engine launched was Archie, which was developed in the 1990s by Alan Emtage. Following that, several other search engines were launched, including the World Wide Web Wanderer.
Nowadays, algorithms have advanced to the point where they can understand the meaning behind words, and with the help of Generative AI, you can search the depths of the internet. While it may appear that search engines have reached a plateau, especially after the rise of large language models (LLMs) like ChatGPT, search still matters. By combining GenAI technologies and information retrieval and search algorithms, users can get a better search experience and more accurate search results.
In this article, we will discuss the following:
Evolution of Search and the Impact of GenAI
Combination of Search, GenAI, and Vector Databases
Challenges and Considerations
The Future of Search
The Evolution of Search: From Exact Keyword Matching to Semantic Search
Search engines started their journey with traditional keyword searching. Keyword algorithms enable search engines to rank results based on relevance to the query. They consider factors like the frequency of keywords, placement, and overall content quality, such as Term Frequency-Inverse Document Frequency (TF-IDF) and BM25, which are still very popular.
| TF-IDF | BM25 |
| TF-IDF measures the importance of a term within a document relative to a corpus. It highlights more unique terms. | BM25 improves on TF-IDF by considering term frequency, document length, and term saturation. It offers a more nuanced document ranking based on query relevance. |
| TF-IDF considers raw term frequency | BM25 considers term frequency with diminishing returns for saturation. |
| TF-IDF does not account for document length. | BM25 adjusts for document length. It favors shorter documents with relevant terms. |
Table: Comparing TF-IDF and BM25
Traditional search struggles to understand context, synonyms, and the broader meaning behind user queries. Semantic search is a big step forward, which leverages natural language processing(NLP) to interpret a query's intent and context. The key advantages of semantic search include:
Context Awareness: Understands the meaning behind queries, not just exact keywords.
Improved Relevance: Delivers more accurate and contextually relevant search results.
Handling Synonyms: Recognizes and processes synonyms and related concepts.
Semantic search is possible due to vector embeddings and vector similarity search technologies. Vector embeddings are numerical representations of various unstructured data, such as natural languages, that capture the contextual meaning of words and sentences.
Vector embeddings are usually generated by various deep learning models (also known as embedding models), such as Cohere’s embed-english-v3.0 and OpenAI’s text-embedding-3-large.
Vector databases are purpose-built to store, index, and retrieve vast amounts of these vector embeddings efficiently. They also provide operators to retrieve relevant documents given a query.
Vector databases differ from traditional relational databases in that they are designed to handle vector data and perform similarity searches. However, they can still support traditional search capabilities alongside vector-based queries. Here’s a webinar that shows vector search capabilities on the Zilliz Cloud vector database (the fully managed Milvus).
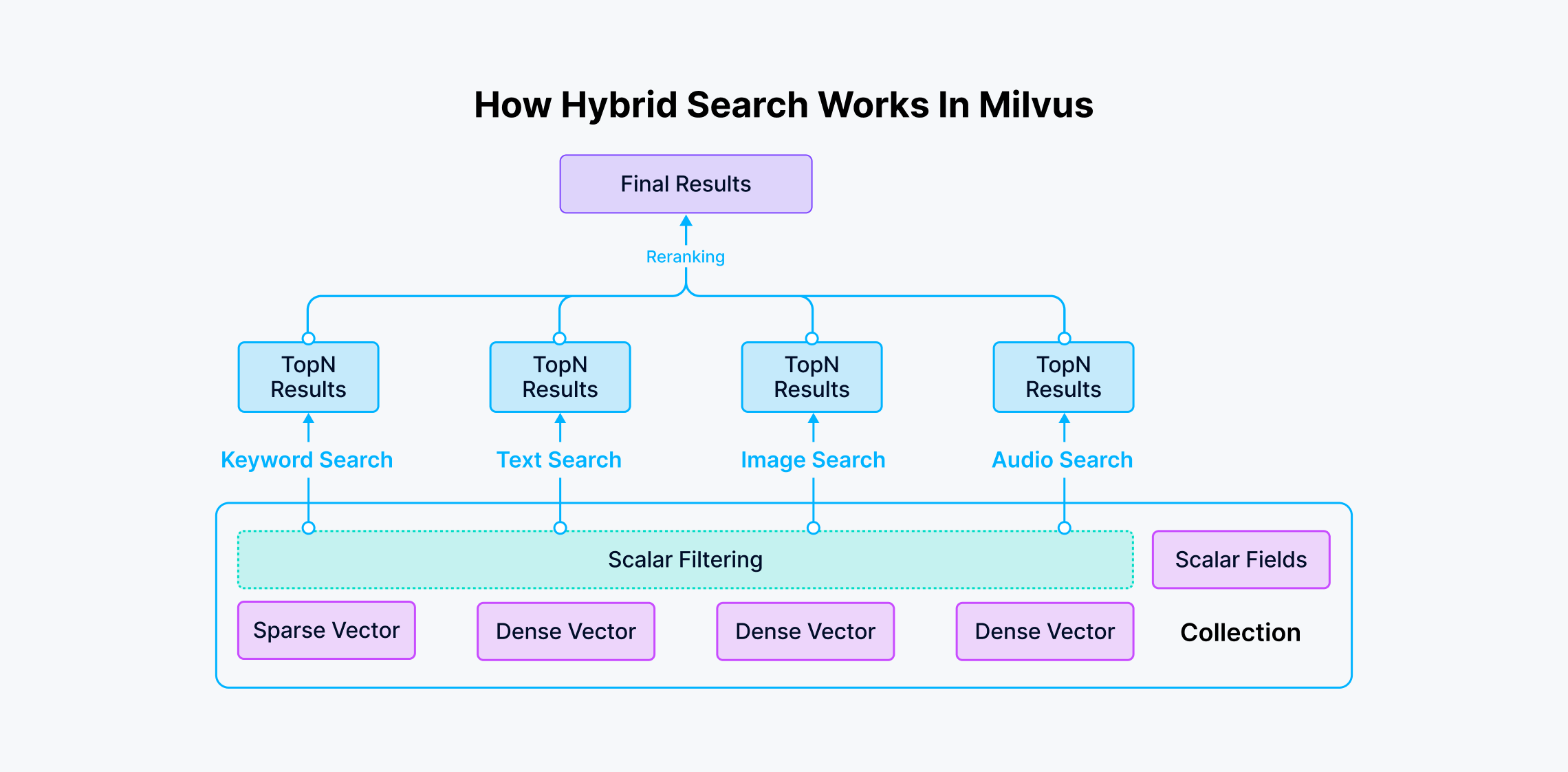 how hybrid search works
how hybrid search works
Fig 1: How Hybrid Search Works in the Milvus vector database system
Combining keyword and semantic search is possible and often leads to superior results. Vector databases like Milvus support up to 10 vector fields per dataset in a single collection, enabling hybrid searches across multiple vector columns simultaneously. Milvus advanced capabilities enable different columns to:
Represent multiple perspectives of information, such as various views of a product in e-commerce.
Utilize diverse types of vector embeddings, including dense embeddings from models like BERT and Transformers and sparse embeddings from algorithms like BM25, BGE-M3, and SPLADE.
Fuse multimodal vectors from different unstructured data types like images, videos, audio, and text, facilitating applications such as biometric identification in criminal investigations.
Integrate vector search with full-text search, providing versatile and comprehensive search functionality.
Generative AI and Its Impact on Search
Large Language Models (LLMs) are trained on a huge corpus of data. This approach allows them to understand and tackle a variety of natural language-related tasks. In the context of search, LLMs excel in:
Contextual Understanding: Grasping the intent behind queries for more accurate results.
Semantic Search: Interpreting and matching the meaning of content queries.
Natural Language Processing: Handling complex queries with nuanced language.
Synonym Recognition: Identifying and processing synonyms for broader search coverage.
Multilingual Search: Supporting queries in multiple languages for global accessibility.
Previously, Google searches returned thousands of pages requiring further investigation. Now, Generative AI, like ChatGPT, has transformed web search by offering conversational and context-aware responses, making it more engaging and helpful for simple queries. At its early stage, LLMs have several limitations:
Limitations in Authority: Generative AI cannot often provide authoritative sources and direct citations, which is crucial for academic and scientific research.
Timeliness Issues: Due to the large resource requirements for training, generative AI models may not always reflect the most up-to-date information, especially in rapidly evolving fields.
Learning and Serendipity: Using AI for search might reduce the chance of discovering new, unrelated information.
Energy Consumption: Generative AI systems consume significantly more energy than traditional search engines.
Hallucinations: LLMs can only give answers based on the information they were pre-trained on. They may provide incorrect or fabricated information if they don't have enough data to reference.
Lack of domain-specific information: LLMs are trained solely on publicly available data. Thus, they may lack domain-specific, proprietary, or private information inaccessible to the public.
These limitations can be detrimental, but combining generative AI with vector databases to build retrieval augmented generation (RAG) systems can help mitigate them.
RAG: Combining Generative AI with Traditional Search for More Accurate Search Results
Some limitations, such as outdated information, lack of citations or sources, and reduced serendipity, can be mitigated by a popular technique called Retrieval Augmented Generation (RAG), which combines generative AI with vector databases.
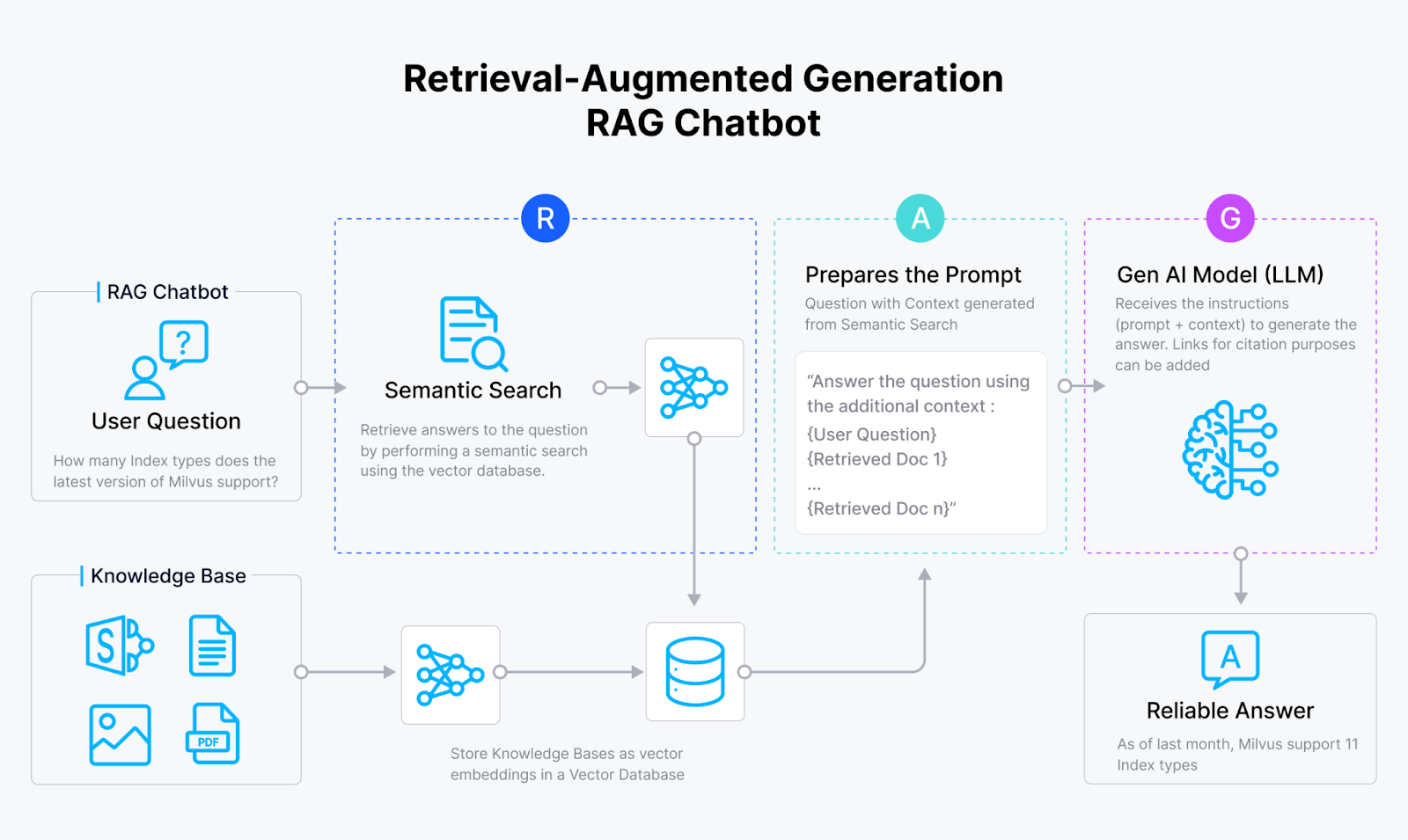 Fig 2: How RAG works
Fig 2: How RAG works
Fig 2: How RAG works
RAG begins by identifying the data sources you want to use for your generative AI application, ensuring the results are contextually relevant. The content from these data sources is then converted into vector embeddings—a numerical representation of the data in a high-dimensional space—using your chosen machine learning model. These embeddings are stored in a vector database, such as Milvus. When the application receives a query, for instance, a question from a chatbot, it converts the query into a vector embedding. This embedding performs a semantic search within the vector database, retrieving relevant documents or data. The search results, along with the original query and a prompt, are then sent to the language model (LLM) to generate contextually accurate and relevant responses.
Simply put, RAG uses search algorithms to pull relevant information from external sources and integrates it with a pre-trained LLM. This method overcomes the issues of outdated information and limited sources found in standalone LLMs.
The next section will implement a basic RAG application using Milvus and LlamaIndex.
Implementation of RAG with Milvus and LlamaIndex
We'll use some synthetic data related to technological innovations and advancements in artificial intelligence (AI). This dataset will include two files: one with a collection of summaries on technological advancements and another with a brief overview of the state of AI.
Imports and Setup
The code snippets require pymilvus and llamaindex dependencies. Install them using the following commands:
pip install pymilvus>=2.4.2
pip install llama-index-vector-stores-milvus
pip install llama-index
pip install openai
If you use Google Colab, you might need to restart the runtime after installing the dependencies. Click on the Runtime menu at the top of the screen and select "Restart session" from the dropdown menu.
Setup OpenAI
First, add your OpenAI API key to access GPT:
import openai
openai.api_key = "sk-***********"
To ensure security, store the API key in the .env file to prevent it from being exposed publicly.
Prepare Data
In this example, we will create our own dummy data that will ingested into the vector database.
Create Data Files
First, we'll create two text files.
tech_innovations.txtwith summaries of technological advancements.ai_overview.txtwith an overview of the state of AI.
You can create these files directly in your working directory or use the following commands to generate them:
mkdir -p 'data/'
# Create tech_innovations.txt
echo "1. Quantum computing promises to revolutionize the field of computing with its ability to perform complex calculations much faster than classical computers.
2. Blockchain technology enhances security and transparency by providing a decentralized and tamper-proof ledger for transactions.
3. 5G networks offer higher data speeds and lower latency, enabling advancements in IoT and smart city technologies." > data/tech_innovations.txt
# Create ai_overview.txt
echo "Artificial Intelligence (AI) is rapidly evolving, with recent advancements in natural language processing, computer vision, and robotics. Techniques like deep learning and reinforcement learning are driving innovations in various industries, from healthcare to autonomous vehicles." > data/ai_overview.txt
Generate Documents
Use the following Python code to read the documents and load them into the llama_index:
from llama_index.core import SimpleDirectoryReader
# Load documents from the created files
documents = SimpleDirectoryReader(
input_files=["./data/tech_innovations.txt", "./data/ai_overview.txt"]
).load_data()
# Print the document ID of the first document
print("Document ID:", documents[0].doc_id)
Create an Index
An index is a data structure used to quickly retrieve information from a large dataset by mapping textual or numerical data into vector representations. It facilitates efficient similarity searches and queries by enabling rapid comparison. Here’s how to create an index using the Milvus vector store:
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.milvus import MilvusVectorStore
# Initialize the vector store
vector_store = MilvusVectorStore(uri="./milvus_demo.db", dim=1536, overwrite=True)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# Create an index from the loaded documents
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
For the parameters of MilvusVectorStore:
- Setting the
urias a local file, e.g.,../milvus.db, is the most convenient method, as it automatically uses Milvus Lite to store all data in this file. - For large datasets, you can set up a more performant Milvus server on Docker or Kubernetes and use the server
uri, e.g.,http://localhost:19530. - To use Zilliz Cloud, adjust the
uriandtokento the Public Endpoint and API key in Zilliz Cloud.
Query the Data
Now that our document is stored in the index, we can query it. The index will use the data stored in itself as the knowledge base for GPT. Like this:
query_engine = index.as_query_engine()
# Example queries
res1 = query_engine.query("What are some recent technological advancements?")
Challenges and Considerations of Using LLMs and RAG
The ideas presented above are new and not without their challenges. Here are a few of them:
Balance Speed & Accuracy: Large language models such as GPT-4 and PaLM achieve higher accuracy due to their increased number of parameters. However, with more parameters comes a decrease in inference speed and an increase in cost. This creates a trade-off between generation speed and accuracy. Newer models, like Microsoft's Phi series, aim to reduce parameter size while maintaining accuracy.
Addressing Bias & Ensuring Fairness: AI-enhanced search systems must confront biases to ensure fairness. Google's image databases, for instance, have been criticized for being US and Western-centric, reinforcing stereotypes. Such latent biases in datasets result in higher inaccuracy rates for non-Caucasian groups and women. In 2018, Amazon admitted its AI recruitment tool was flawed. Over the past decade, it has learned to favor male applicants based on patterns in predominantly male resumes. Addressing these biases and ensuring fairness is necessary, with AI being the main component of this new search.
Privacy & Security Concerns: AI's demand for large datasets conflicts with privacy laws, restricting data sharing and automated decision-making and limiting AI's capacity. During COVID-19, these restrictions prevented AI developers from accessing health data. This affected their ability to improve decisions on control measures and vaccine distribution. Giving AI unrestricted access to data can raise privacy concerns, as it may use personal content from individuals during its training.
These serious concerns hinder modern search engines. Ongoing research aims to address these issues and may soon provide solutions.
The Future of Search: Trends and Predictions
The future of search is transforming information access with the following innovations:
Personalized Search: These innovations can be seen with recent Google updates. Google’s semantic search leverages vector embeddings to understand the context of queries. For instance, if a user searches for “best Italian restaurants near me,” Google uses embeddings to return results that consider user preferences, recent searches, and location.
Multimodal search: Before, the searches were bound only to text, but with embeddings, we can now search for different modalities like text, images, or audio. A user can provide text and an image to the search engine for complex queries.
Scientific and Academic Search: AI-powered tools like Semantic Scholar use natural language processing to understand and index research papers, providing more relevant search results. Google's AI-driven search algorithms can identify connections between disparate research topics, uncovering insights that traditional search methods might miss. Moreover, AI agents can divide tasks among themselves, such as finding relevant documents, retrieving key information, and presenting it to the user.
Conclusion
In the article, we discussed the previous IR systems that led to our long-known search engines like Google and Bing. We discussed the newer search systems emerging due to the rise of AI. The main key takeaways are as follows:
Continued Need for Search Systems: Despite the advancements in generative AI, traditional information retrieval (IR) systems remain essential, especially for academic use.
Authoritativeness and Timeliness: Users, particularly academics, value the authority and up-to-date nature of information, which generative AI chatbots often lack.
Challenges with Generative AI: Issues like lack of direct citations, potential misinformation, and energy consumption are significant concerns with generative AI in search.
Leverage RAG to mitigate LLM limitations for advanced search: LLM can generate more accurate answers by integrating with vector databases to access external data sources as context.
Future Potential: While generative AI may augment search processes, more research and development are needed to address current limitations.
Further Resources
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- The Evolution of Search: From Exact Keyword Matching to Semantic Search
- Generative AI and Its Impact on Search
- RAG: Combining Generative AI with Traditional Search for More Accurate Search Results
- Implementation of RAG with Milvus and LlamaIndex
- Challenges and Considerations of Using LLMs and RAG
- The Future of Search: Trends and Predictions
- Conclusion
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

What is Information Retrieval?
Information retrieval (IR) is the process of efficiently retrieving relevant information from large collections of unstructured or semi-structured data.

Will A GenAI Like ChatGPT Replace Google Search?
In this article, we will explore how GenAI and traditional search engines work, compare their strengths and weaknesses, and discuss the potential for integrating both technologies.

The Evolution of Search: From Traditional Keyword Matching to Vector Search and Generative AI
Explores the evolution of search, the limitations of keyword-matching systems, and how vector search and GenAI are setting new standards for modern search.