




What is a Context Window in AI?

What is a Context Window in AI?
In AI, a context window defines how much text the model can process at one time, measured in tokens. Understanding the context window is crucial as it impacts an AI model’s ability to generate accurate and coherent responses. This guide will explore what a context window is, its importance in AI models, and the challenges of managing larger context windows.
Understanding Tokens
Before we discuss the context window, let's first learn the concept of tokens.
Tokens are the smallest units of data AI models use to process and learn from text. They are essentially the pieces of a sentence—like individual words or punctuation marks—that a computer uses to understand and process language. When a computer reads a sentence, it breaks it into smaller parts (tokens) to make sense of it. For example, in the sentence "It's sunny!", tokens would be "It's", "sunny", and "!". This process, called tokenization, helps the computer analyze text for tasks like translating languages, detecting spam, or answering questions.
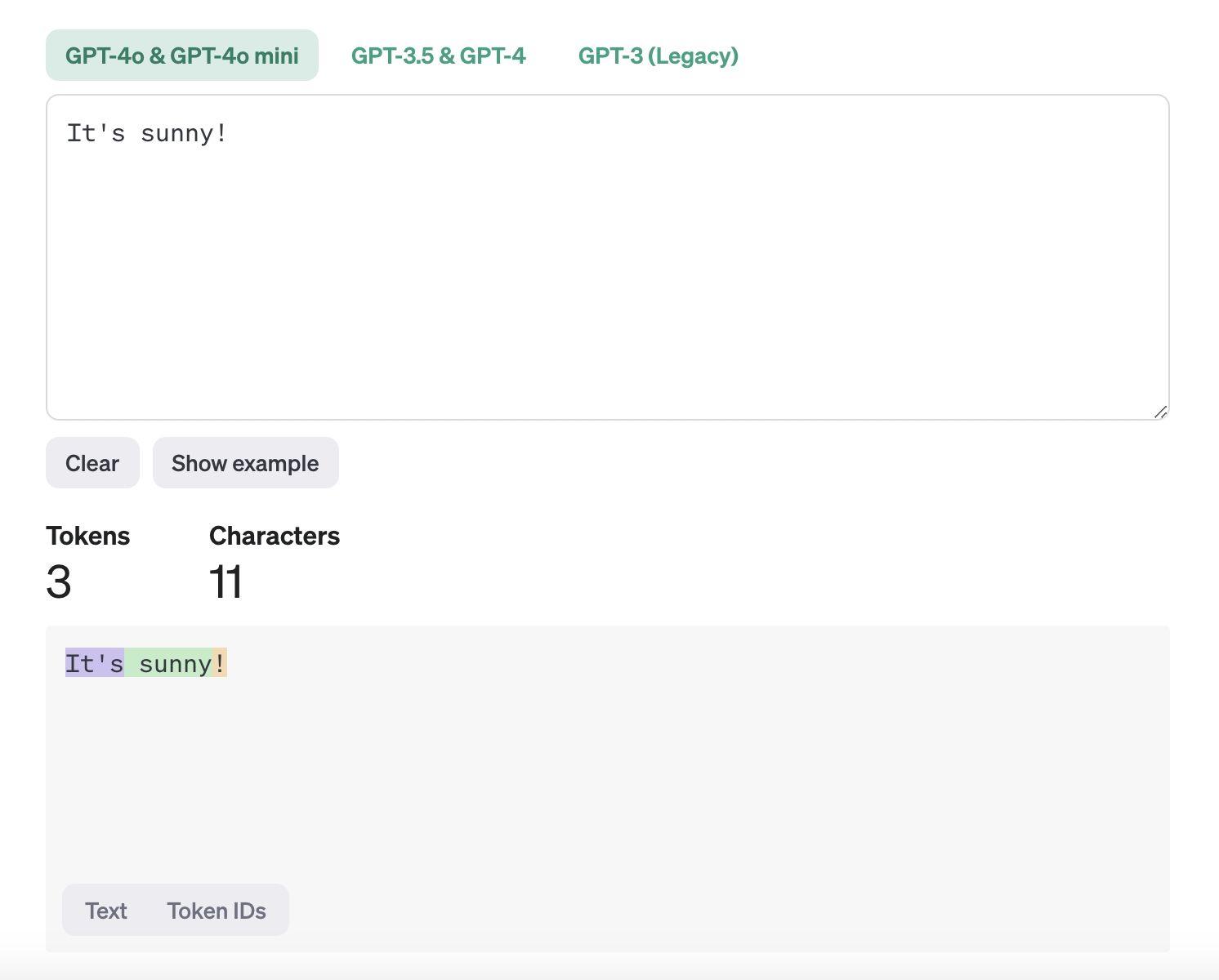 What are tokens.jpeg
What are tokens.jpeg
What is a Context Window in AI?
The context window is a fundamental concept in AI, particularly in large language models (LLMs). It refers to the maximum amount of text, measured in tokens, an AI model can remember and use during a conversation when generating a response.
Think of a context window like the model's short-term memory span. For example, if a model like ChatGPT has a context window of 4,096 tokens, it can "remember" the information from the last 4,096 tokens (words or punctuation marks) it processed. This is similar to how a person can only keep track of a certain amount of information while reading or listening. When this token limit is reached, the earliest information begins to "fade" as new information comes in, affecting the model's ability to refer back to earlier parts of the conversation. This concept is crucial in determining how well a model can maintain context over long discussions or documents.
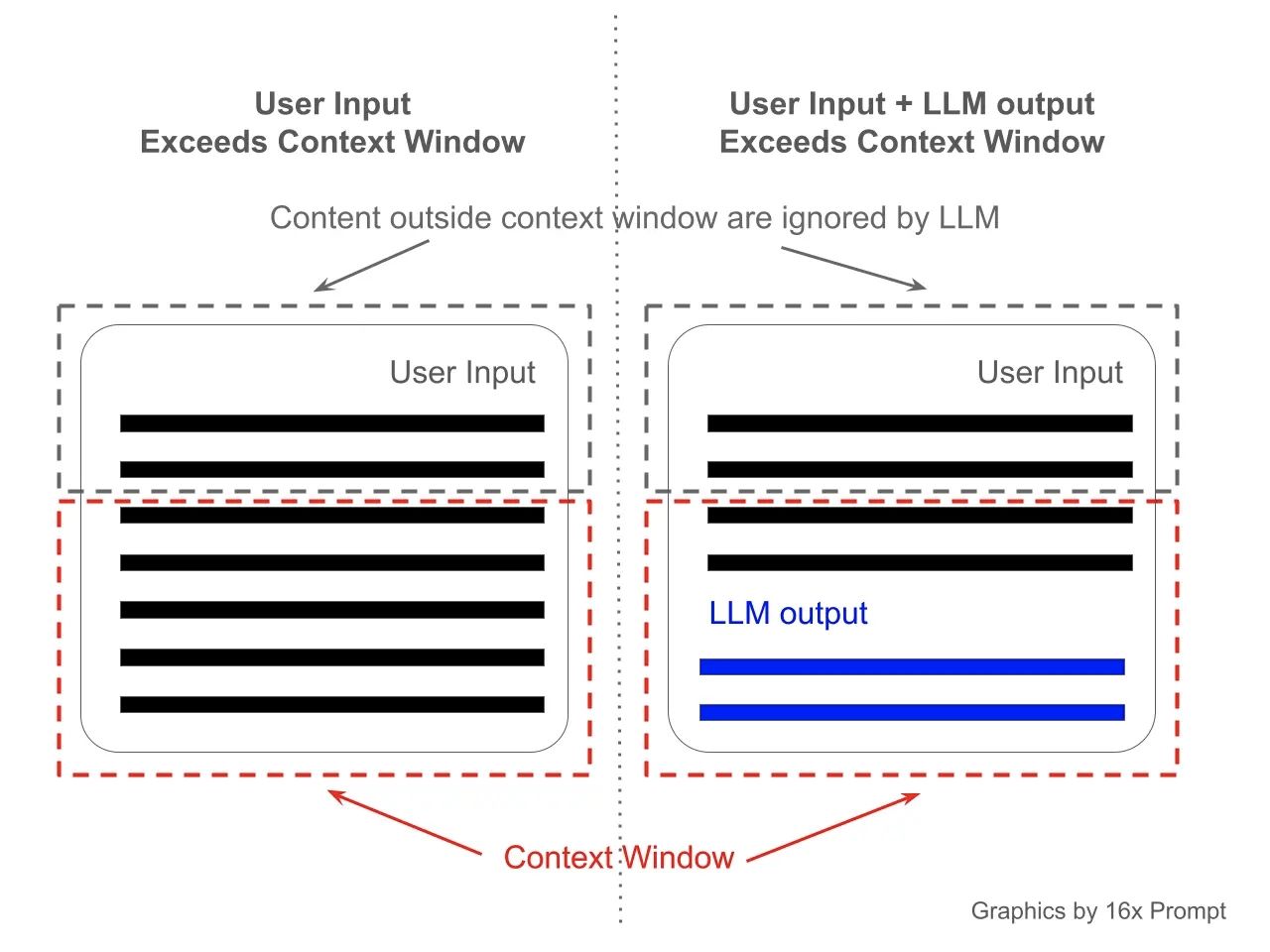 Context Window Visualized, credit 16x Prompt.jpeg
Context Window Visualized, credit 16x Prompt.jpeg
The context window not only applies to the input or the ongoing conversation history but also the responses generated by the model. For example, if a response itself contains 500 tokens, this count is deducted from the total tokens available for processing the conversation history. Consequently, if nearing the token limit, the earliest 500 tokens of the conversation may not be considered in ongoing processing.
Token Limits Within the Context Window
The size of the context window, or token limit, is the total number of tokens that the model can consider at one time. If the conversation exceeds this limit, only the most recent tokens are retained and older tokens are dropped. For instance, OpenAI's advanced model GPT-4o offers a much larger context window up to 128,000 tokens, allowing for broader and deeper engagement with the text.
 GPT-4o's context window and output token limit.jpeg
GPT-4o's context window and output token limit.jpeg
Output and Input Token Limits
Besides the context window, AI models have specific token limits for outputs and inputs:
- Output Token Limit: This is the maximum number of tokens the model can generate in a single response. For example, OpenAI's GPT-4o-mini has an output token limit of 16,348 tokens. If the generated response reaches this limit, the model will cease token generation, potentially truncating the response.
 GPT-4o-mini's output token limit .jpeg
GPT-4o-mini's output token limit .jpeg
- Input Token Limit: This determines how many tokens from the input can be processed in one go. Exceeding this limit means the model must segment the input into smaller pieces, which might impact the response’s coherence and accuracy.
Balancing Token Limits
The volume of the token limit significantly influences a model’s performance, dictating its capability to parse and interpret complex information effectively. Balancing the number of tokens with the model's processing power is essential, as more comprehensive processing capabilities allow for handling complex ideas more effectively, albeit with necessary trade-offs in tokenization and processing strategies.
Importance of Larger Context Windows in AI Models
 A visual representation of the importance of larger context windows in AI..jpeg
A visual representation of the importance of larger context windows in AI..jpeg
Larger context windows significantly enhance an AI’s ability to comprehend and analyze extensive documents, making them indispensable in fields like legal and medical research. For instance, in legal research, AI can efficiently extract relevant information from large datasets, providing valuable insights quickly. Similarly, in medical research, large context windows facilitate the summarization of complex scientific papers, aiding researchers in deriving insights promptly.
The increased capacity to process over one million tokens allows AI models to handle diverse tasks effectively, from data processing to code generation. Claude 3.5 Sonnet, for example, features a context window size of 200,000 tokens, enabling it to manage complex instructions and nuanced tasks with remarkable precision. This capability underscores the critical role of larger context windows in enhancing AI performance.
However, larger context windows in AI models themselves come with trade-offs. They can lead to higher operational costs and require robust data strategies to ensure the effective utilization of relevant training data. Additionally, managing a larger context window can result in information overload, decreasing the model’s effectiveness at identifying key points. Therefore, a balanced approach is essential to harness the full potential of larger context windows while mitigating associated challenges.
In the following section, we'll explore the challenges with expanding context windows.
Challenges with Expanding Context Windows in AI Models
Expanding context windows in AI models introduces various trade-offs that need careful consideration. Allowing for longer inputs and outputs can enhance the richness of the generated responses but also increases the complexity in processing. The balance between longer context windows and efficient processing is crucial to mitigate potential drawbacks in AI performance.
Computational Resources
As context window sizes grow, the requirement for processing power increases substantially, leading to slower inference times. The complexity in scaling when increasing context windows arises from parameters increasing quadratically, which poses significant challenges. When the length of text sequences doubles, the memory and computational needs quadruple, highlighting the heightened demands of larger context windows.
To address these challenges, techniques such as ring attention have been implemented to enhance the efficiency of models dealing with extended context windows. However, the ‘Zone of Proximal Development’ theory suggests that overloading language models with information beyond their current capabilities can diminish their effectiveness. Thus, careful consideration is needed to manage computational resources effectively.
Cost Implications
Longer context windows can lead to significant computational and financial costs, which organizations need to manage effectively. Expanding the context window from 4K to 8K tokens can lead to an exponential rise in operational expenses. Therefore, organizations must weigh the benefits of improved AI model performance against the increased costs of longer context windows.
Effective cost management strategies are crucial for organizations considering the expansion of context windows in AI models. Implementing these strategies helps organizations balance enhanced AI capabilities with associated financial implications, ensuring sustainable and efficient AI operations.
Data Management
Managing larger volumes of training data presents significant challenges for AI models, particularly in optimizing performance without overwhelming the system. Research indicates that providing a focused set of relevant documents yields better performance for language models than inundating them with an excessive volume of unfiltered information. This approach ensures that the AI can process and respond effectively, maintaining relevance in its outputs.
Filtering and managing the context of training data is essential for enabling accurate responses and efficient model performance. Strategically selecting and organizing relevant data enables AI models to deliver contextually appropriate and meaningful outputs, even with larger context windows.
RAG: Enhancing AI Models with an External Knowledge Base for Extended Memory
Larger context windows are crucial in AI models for improved understanding and handling of complex tasks. They allow models to maintain and leverage more extensive information, enhancing continuity and relevance in responses. This proves especially beneficial for handling intricate tasks. However, maintaining a large context window can increase computational demands, costs, and complexity in data management.
To equip AI models with long-term memory capabilities while addressing these challenges, researchers have explored innovative approaches like Retrieval-Augmented Generation (RAG). This technique enhances the output of AI models by connecting them to an external knowledge base housed in a vector database. By doing so, it provides models with a broader contextual backdrop without the overhead associated with large internal context windows. This external knowledge base acts as an extended memory, aiding models in accessing a vast pool of information dynamically, which is crucial for processing complex queries and improving the depth and accuracy of responses.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) combines the generative power of language models with the dynamic retrieval of external documents. This approach expands the potential of LLMs by accessing and integrating a broader range of information, thereby enhancing the relevance and accuracy of the generated responses.
A standard RAG system usually integrates an embedding model, a vector database like Milvus or its managed version Zilliz Cloud, and an LLM (or a multimodal model), where the embedding modeltransform the text into vector embeddings, the vector database stores and retrieves contextual information for user queries, and the LLM generates answers based on the retrieved context.
 Figure- RAG workflow.png
Figure- RAG workflow.png
Leveraging RAG allows AI models to dynamically retrieve relevant documents or data points during the generation process, ensuring outputs are contextually rich and aligned with user intent. This technique is particularly useful in scenarios requiring detailed and precise information, such as legal research or scientific analysis.
Comparing Context Window Sizes Across Popular Models
 A comparison chart of context window sizes across popular AI models
A comparison chart of context window sizes across popular AI models
Different LLMs come with varying context window sizes, catered to different requirements and tasks. GPT-4o, for instance, features a context window size of 128,000 tokens, significantly enhancing its ability to process extensive inputs and generate contextually relevant responses. Meanwhile, Gemini 1.5 Pro can utilize a context window of more than 2 million tokens, offering substantial advantages in handling large datasets.
Claude 3.5 Sonnet and Llama 3.2 also showcase varying context window sizes, each with its strengths and limitations. Claude 3.5 Sonnet has a context window size of 200,000 tokens, enabling it to manage extensive information in a single interaction. In contrast, Llama 3.2 supports a context window of 128,000 tokens.
| Model | Context window | Max output tokens |
|---|---|---|
| GPT-4o | 128,000 tokens | 16,384 tokens |
| GPT-4-turbo | 128,000 tokens | 4,096 tokens |
| GPT-4 | 8,192 tokens | 8,192 tokens |
| Gemini 1.5 Pro | 2,097,152 tokens | 8,192 tokens |
| Claude 3.5 Sonnet | 200,000 tokens | 8192 tokens |
| Llama 3.2 | 128,000 tokens | 2048 tokens |
Summary
In conclusion, mastering the context window is essential for advancing AI capabilities. Larger context windows enhance AI’s ability to process and analyze extensive documents, making them invaluable in fields like legal and medical research. However, expanding context windows comes with challenges, including increased computational demands, higher costs, and complex data management requirements.
By implementing techniques such as Retrieval-Augmented Generation (RAG) and vector databases, AI models can optimize the utilization of long context windows with an external knowledge base powered by vector databases, ensuring contextually relevant and accurate responses. As we look to the future, balancing context window size with efficiency and exploring innovative strategies will be crucial for developing advanced AI applications that can handle complex tasks effectively. The journey of mastering context windows is ongoing, and the possibilities are boundless.
Frequently Asked Questions
What is a context window in AI?
A context window in AI is the range of text surrounding a target token that the model uses to generate responses, determining the amount of information it can process at one time. Understanding this concept is crucial for optimizing AI interactions.
Why are larger context windows important?
Larger context windows are crucial as they significantly improve an AI model's comprehension and ability to analyze extensive documents, resulting in more coherent and contextually relevant responses. This advancement ultimately enhances overall interaction quality.
How do token limits impact AI models?
Token limits critically affect AI models by determining the maximum input size they can handle. Exceeding these limits results in incomplete or inaccurate outputs, necessitating the segmentation of text into smaller parts.
What are the challenges of expanding context windows?
Expanding context windows poses significant challenges, including elevated computational demands and increased operational costs. Additionally, it complicates data management, necessitating careful consideration before implementation.
How can AI models be enhanced with long context windows?
AI models can be enhanced with long context windows by utilizing techniques such as Retrieval-Augmented Generation (RAG) and integrating vector databases, which help ensure contextually relevant and accurate responses. This approach significantly improves the model's performance in handling extensive information.
Further Resources
- Understanding Tokens
- What is a Context Window in AI?
- Importance of Larger Context Windows in AI Models
- Challenges with Expanding Context Windows in AI Models
- RAG: Enhancing AI Models with an External Knowledge Base for Extended Memory
- Comparing Context Window Sizes Across Popular Models
- Summary
- Frequently Asked Questions
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free