




Tokenization: Understanding Text by Breaking It Apart
Tokenization: Understanding Text by Breaking It Apart
TL; DR
Tokenization is the process of breaking text into smaller units called tokens, such as words, phrases, or subwords, to prepare it for machine learning models. For example, the sentence "Tokenization in Milvus is powerful" might be split into tokens like ["Tokenization," "in," "Milvus," "is," "powerful"]. These tokens are transformed into numerical embeddings that capture their meaning for tasks like semantic search. In Milvus vector database, tokenization is integrated with built-in analyzers that process text efficiently for indexing and retrieval. This feature simplifies workflows, allowing developers to handle raw text directly and power advanced search applications with high precision and scalability.
Introduction
At the heart of many artificial intelligence (AI) and natural language processing (NLP) systems lies a process that transforms raw text into “structured data” – tokenization. But what exactly is tokenization, and why is it so important for machines to break down text into smaller chunks?
Tokenization is the process of breaking down text into smaller units, allowing machines to analyze and understand language more effectively. This essential step enables computers to handle and process human language for various NLP tasks, such as sentiment analysis, language translation, and text generation.
 tokenization
tokenization
What is Tokenization?
Tokenization divides texts, such as words or characters, into smaller units called tokens. It is a foundational step in NLP, enabling machines to process and understand human language more effectively.
Why Do We Need Tokenization?
Tokenization is like learning a new language: you start by breaking down sentences into smaller units to understand their meaning and structure. In the same way, computers divide a block of text into smaller, manageable units to process it. Tokenization teaches the computer to identify these fundamental components, like words or subwords, enabling it to understand and analyze the text.
Technically, tokenization converts unstructured text into a structured format that a computer can process. For instance, when you input a sentence into an NLP model, the tokenizer splits it into tokens, which are then assigned numerical values. These values allow computers to perform mathematical operations, identify relationships, and extract meaning from the data. Without tokenization, the text would remain an incomprehensible string of characters to the machine, making further analysis impossible.
Key Concepts in Tokenization
Here, we will explore the key concepts you need to understand about tokenization.
Token
A token is a basic unit of text considered meaningful for analysis. Tokens can be characters, words, or subwords serving as the primary input for subsequent text-processing tasks.
Tokenizer
Tokenizers are the fundamental tools that enable computers to dissect and interpret human language by breaking text into tokens. It applies specific rules, such as splitting by spaces or using subword-level techniques, to define the granularity of text representation.
Analyzer
An analyzer goes beyond simple tokenization to deeply process and understand text. After tokenization, filters are applied to the tokens to refine them further by applying additional processing, such as lowercasing, stemming, lemmatization, or removing stopwords.
Vocabulary
Vocabulary is the set of unique tokens (words, subwords, or characters) that a model can process. It is built from the tokens produced during tokenization. The vocabulary serves as the model's reference for understanding text. Its design and size affect the model's ability to handle language, especially rare or unseen words.
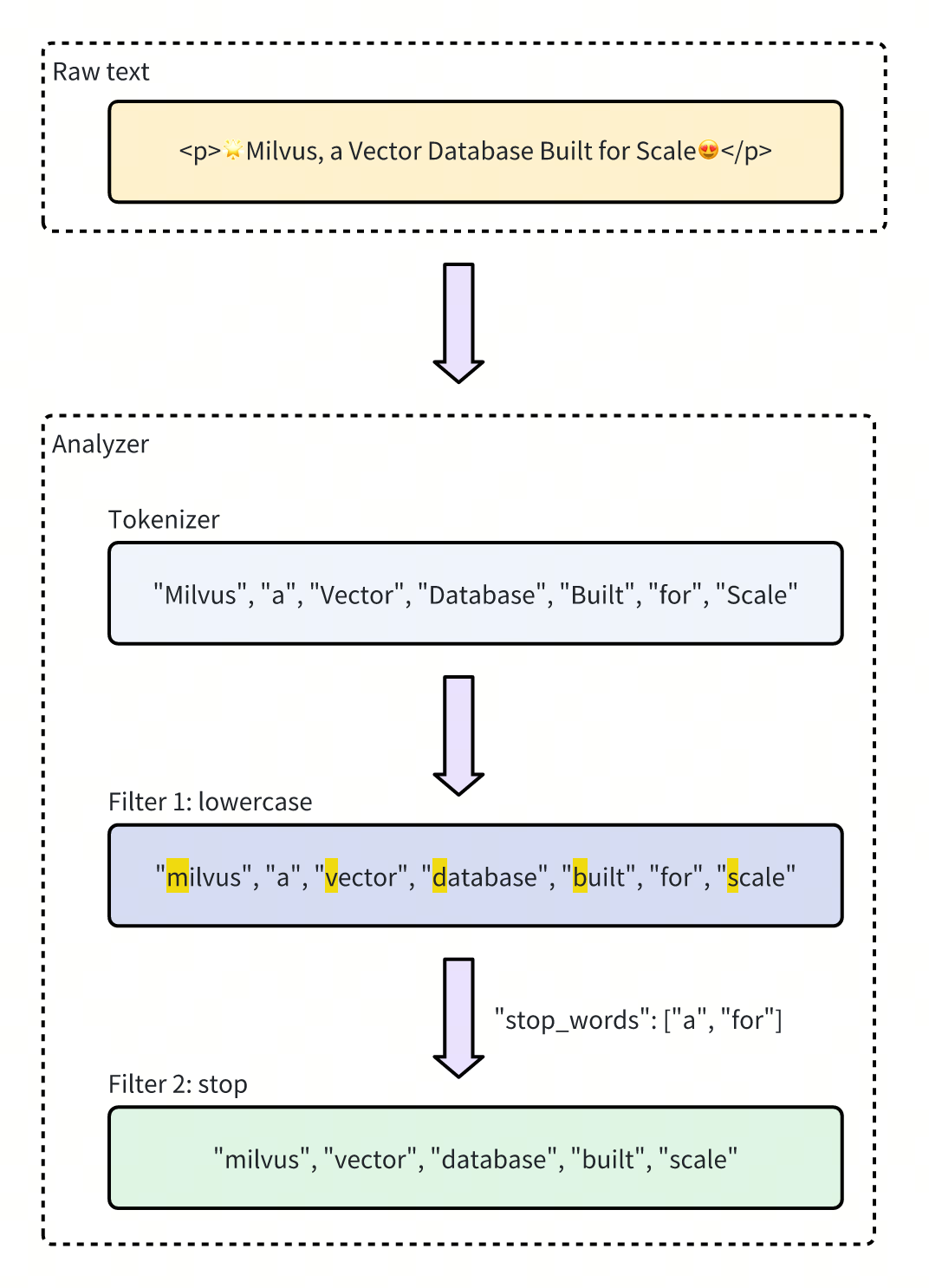 Figure- Tokenizer and Analyzer in Milvus
Figure- Tokenizer and Analyzer in Milvus
Figure: Tokenizer and Analyzer in Milvus
This diagram illustrates the text processing flow, where the raw text is tokenized. Then, an analyzer applies filters to convert the tokens to lowercase and remove stop words, resulting in a refined list of meaningful tokens.
Types of Tokenization
Tokenization methods vary based on the granularity of the text breakdown and the specific requirements of the task at hand. Here are the common types of tokenization:
1. Character Tokenization: It breaks the text down into individual characters. This can be useful for languages with complex morphology and tasks like spelling correction or handling noisy text.
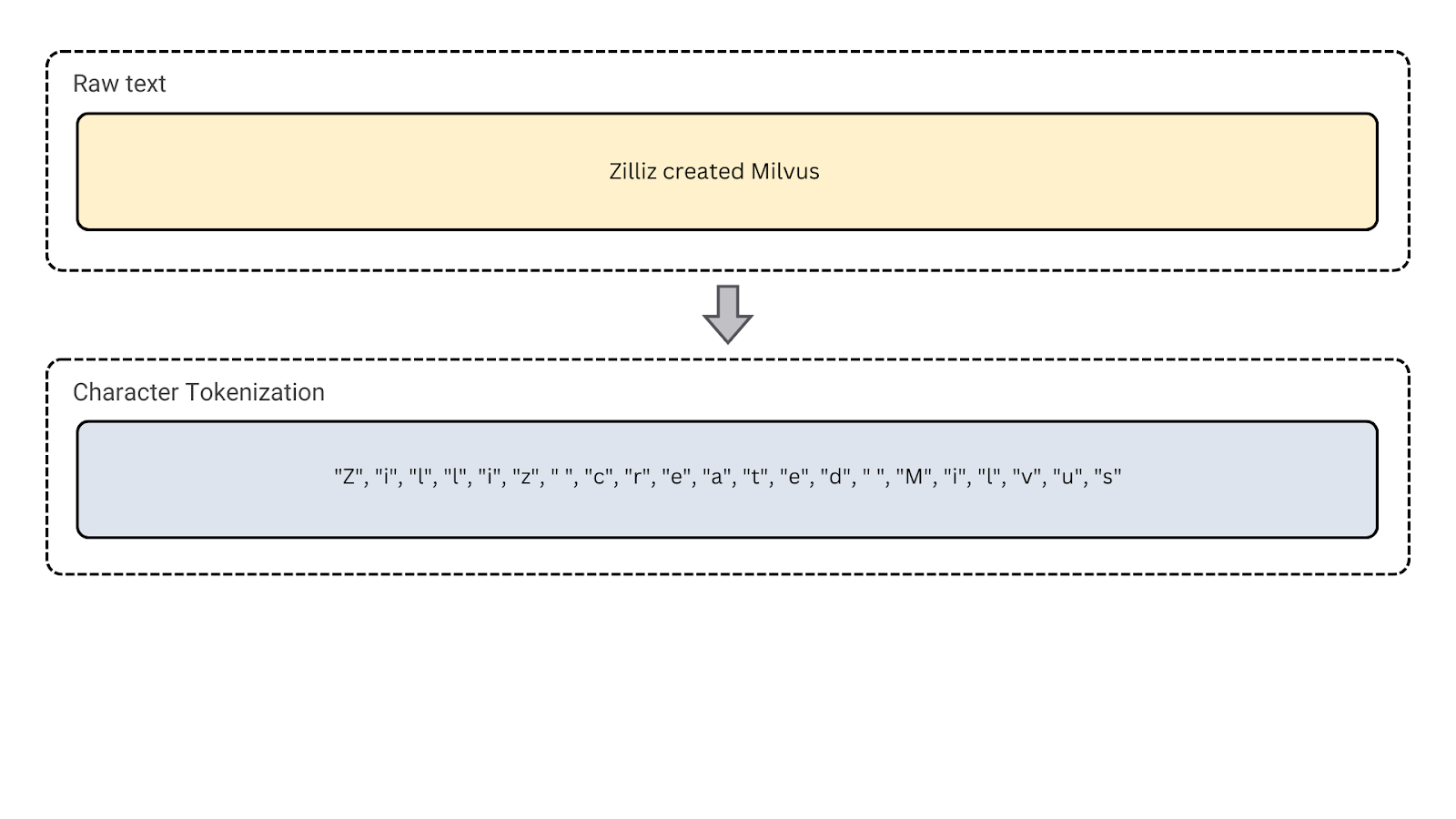 Figure- Character tokenization
Figure- Character tokenization
Figure: Character tokenization
2. Word Tokenization: This is the most common type of tokenization, splitting the text into individual words. It is useful for language modeling, part-of-speech tagging, and named entity recognition, which rely on word-level analysis.
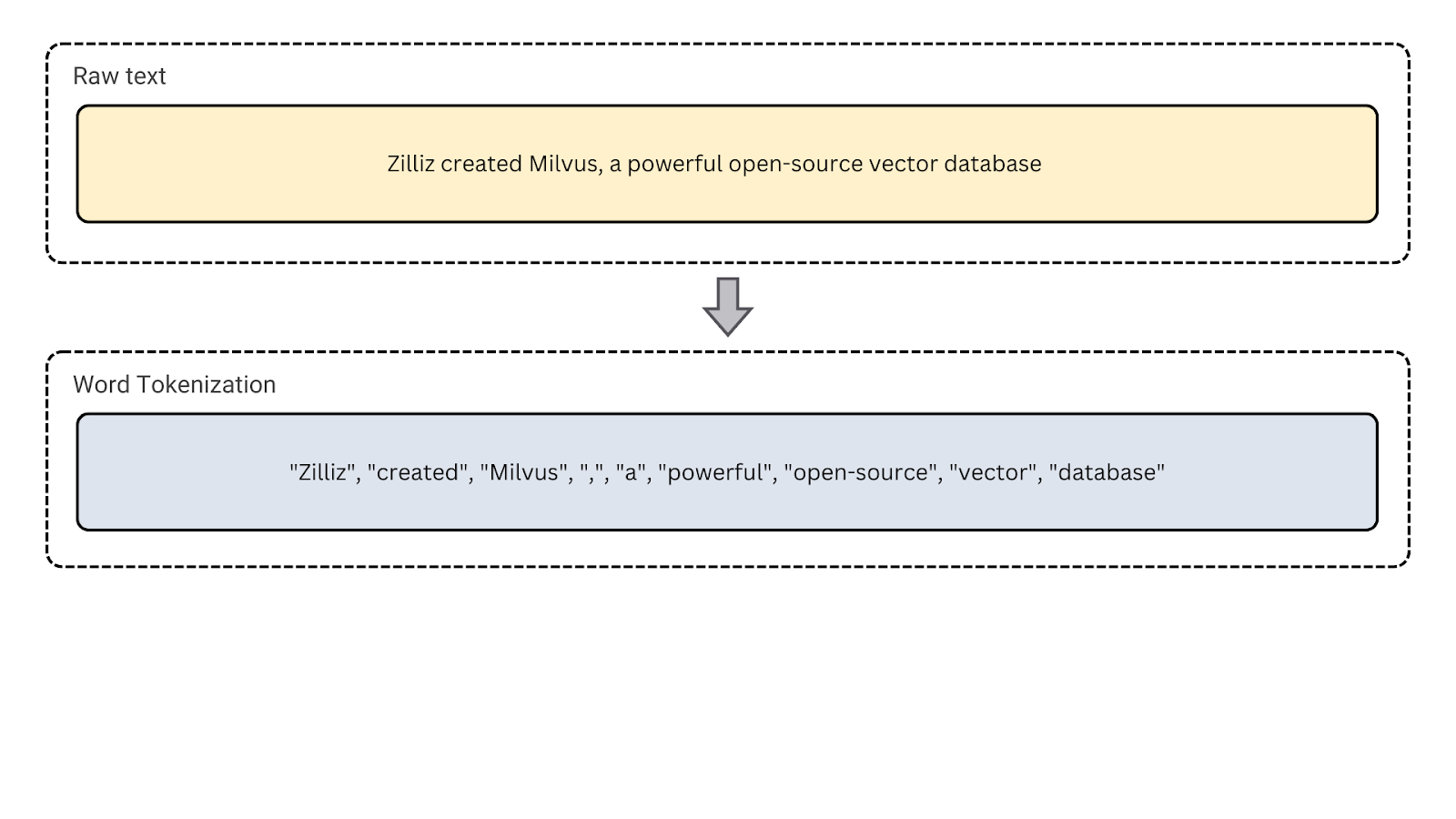 Figure- Word tokenization
Figure- Word tokenization
Figure: Word tokenization.
3. Sentence Tokenization: This type segments text into sentences. It separates paragraphs or long blocks of text into distinct sentences. Use this type for tasks like sentiment analysis and text summarization, where analyzing sentence-level structure is required.
 Figure- Sentence tokenization
Figure- Sentence tokenization
Figure: Sentence tokenization.
4. Subword Tokenization: This method breaks words into smaller, meaningful units (e.g., prefixes, suffixes, or stems). It helps reduce vocabulary size and is especially useful for tasks like text generation.
 Figure- Subword tokenization
Figure- Subword tokenization
Figure: Subword tokenization
Subword tokenization has split the sentence into subword tokens. Rare words like “Zilliz” and “Milvus” are broken into smaller units. Also, “open-source” is split into [“open”, “-”, “source”], treating the hyphen as a separate token.
Code Example
Here is a Python example using Hugging Face’s BERT tokenizer. It demonstrates how the sentence is tokenized using subword tokenization with the WordPiece algorithm:
from transformers import AutoTokenizer
# Load a pre-trained tokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# Tokenize a sentence
sentence = "Zilliz created Milvus, a powerful open-source vector database"
tokens = tokenizer.tokenize(sentence)
print(tokens)
Output
['z', '##ill', '##iz', 'created', 'mil', '##vus', ',', 'a', 'powerful', 'open', '-', 'source', 'vector', 'database']
Comparison Between Tokenization and Word Embedding
Tokenization and word embedding are both fundamental techniques in natural language processing (NLP), but they serve different purposes. Tokenization breaks the text into smaller units, while embeddings convert these units into numerical form.
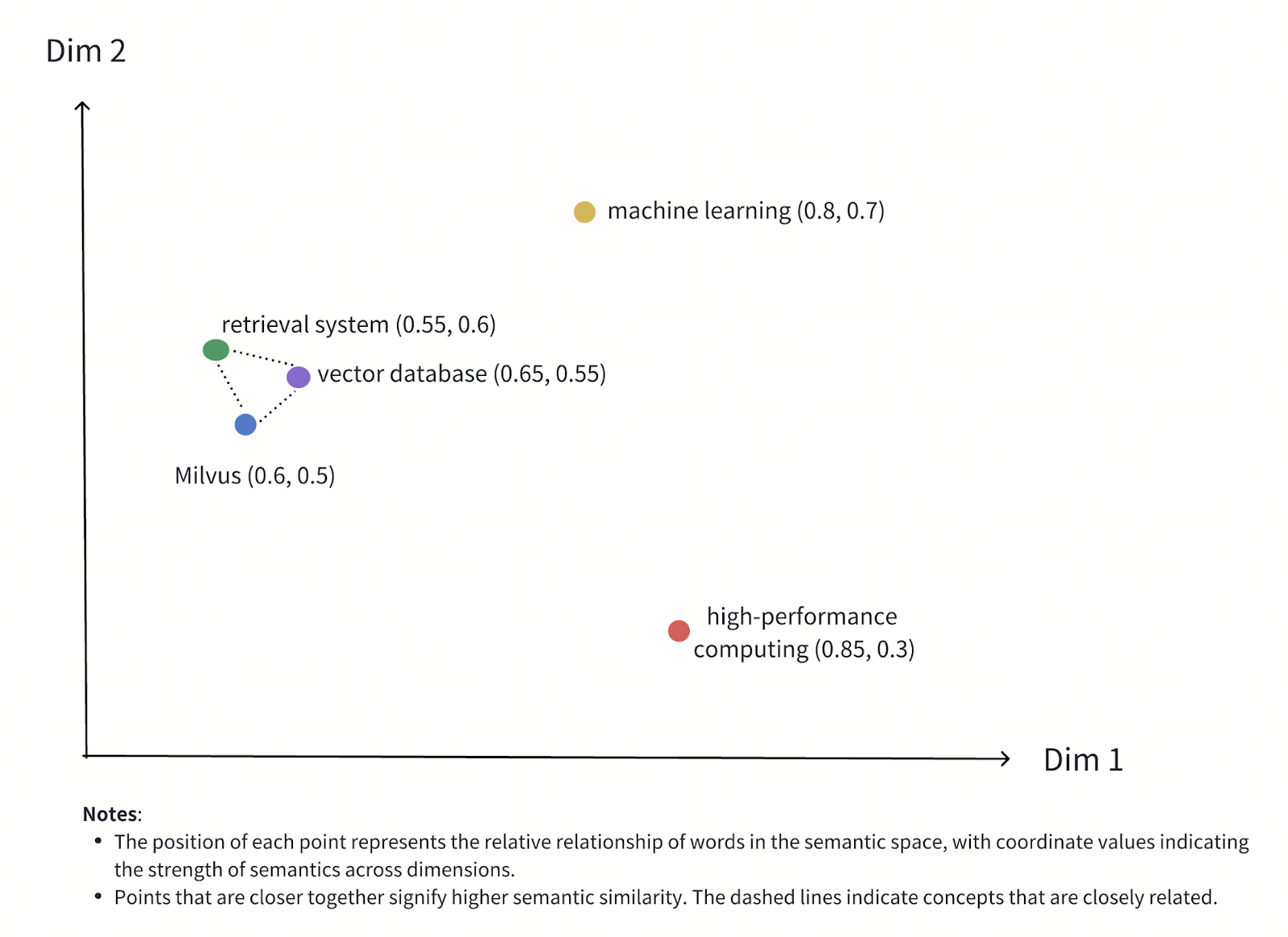 Figure- Semantic Relationship Between Words in Vector Space
Figure- Semantic Relationship Between Words in Vector Space
Figure: Semantic Relationship Between Words in Vector Space
Here’s a comparison of Tokenization and Word Embedding:
| Aspect | Tokenization | Word Embedding |
|---|---|---|
| Definition | The process of splitting text into smaller units (tokens) | A method to represent tokens as dense vectors in high dimensional vector space |
| Purpose | Break text into units that can be processed | Capture semantic meaning and relationship between words in vector representation |
| Examples | Sentence: “Tokenization is crucial”Tokens: [“Tokenization”, “is”, “crucial”] | Word: “Milvus”Embedding: [0.23, 0.56, -0.12, ...] |
| Advantages | Converts unstructured text into a structured format that a computer can process | Capture word semantics, relationships, and context |
| Limitations | Does not capture the semantics of the tokens | Requires large computational power to generate embeddings |
Benefits and Challenges of Tokenization
Tokenization is crucial in text processing. It offers various advantages for language modeling and analysis but also has its own challenges. Let’s examine both aspects.
Benefits
Effective Text Processing: Tokenization is fundamental in preparing text data for NLP tasks. It makes the text more suitable for machine learning models.
Granularity Control: Tokenization provides control over the level of granularity, allowing the model to work with words, subwords, or even characters based on the task at hand. Different tasks have varying requirements, and specific granularity can enhance performance.
Language Independence: Tokenization techniques can adapt to different languages and scripts to suit different languages.
Facilitates Language Modeling: Tokenization is crucial for language modeling. It defines the basic units (tokens) the model processes, enabling better understanding and generation of text.
Challenges
Ambiguity: Tokenization faces challenges due to language ambiguity. For example, the word "bank" could refer to a financial institution or the side of a river, depending on context. Similarly, phrases like "high school" may be tokenized as two separate words or a single unit, affecting interpretation.
Token Loss: Some tokenization methods may lose information by breaking words into smaller tokens, making it harder for models to understand the full context or meaning of the original text
Punctuation Handling: Segmenting tokens that include punctuation, such as apostrophes or dashes, can sometimes be tricky for NLP algorithms.
Languages Without Clear Boundaries: Tokenization can be particularly difficult in languages without clear word boundaries, such as Chinese or Japanese, where spaces do not always separate words. These languages require more sophisticated tokenization methods to split text accurately.
Use Cases of Tokenization
Tokenization is widely used across various NLP tasks, helping systems process and analyze textual data. Below are some of the primary use cases for tokenization:
Search Engines: Tokenization allows search engines to index and retrieve relevant content quickly by breaking down query terms and documents into tokens, ensuring accurate results for user queries.
Machine Translation: Tokenization is critical in machine translation, helping break down source and target languages into tokens that a model can map and translate effectively between languages.
Speech Recognition: Tokenization helps convert spoken language into text by segmenting audio input into tokens for processing, allowing systems to understand spoken words in a structured way.
Sentiment Analysis: Tokenization is essential for sentiment analysis, where it breaks down text into tokens for further processing to determine whether the sentiment expressed is positive, negative, or neutral.
Chatbots and Virtual Assistants: Tokenization enables chatbots and virtual assistants to understand and process user queries by splitting text into manageable units. This allows them to respond intelligently based on the input.
Tools for Tokenization
Several tools are commonly used for tokenization in NLP:
NLTK: It is a powerful Python library for natural language processing, providing tools for tokenization, stemming, lemmatization, POS tagging, and more.
SpaCy: A fast NLP library with a powerful tokenizer for words and sentences and customizable tokenization, making it a go-to tool for industrial applications.
Hugging Face Tokenizer: It tokenizes transformer-based models like BERT and GPT with subword handling.
Gensim: Popular for topic modeling, it includes text preprocessing and tokenization functions.
Tokenization in the Milvus Vector Database
A vector database is designed to store, index, and search unstructured data—such as text, images, and videos—using high-dimensional vector embeddings. These embeddings allow for fast semantic information retrieval and similarity-based searches, making vector databases essential for applications like recommendation systems, search engines, and AI workflows.
Tokenization is the first step in this process. It breaks down raw text into smaller units, such as words, phrases, or subwords, which are then converted into numerical representations (vector embeddings) by machine learning models. Milvus, an open-source vector database developed by Zilliz, stores these embeddings in a high-dimensional space where they can be efficiently queried for similarity.
Built-In Tokenization in Milvus
Milvus simplifies tokenization with its built-in analyzers, which are tailored to different languages and use cases. These analyzers integrate tokenizers and filters to process text data for efficient indexing and retrieval:
Standard Analyzer: The default analyzer for general-purpose text processing. It performs grammar-based tokenization, converts tokens to lowercase, and supports case-insensitive searches.
English Analyzer: Designed specifically for English text. It includes stemming (reducing words to their root forms) and removing common stop words, focusing on meaningful terms.
Chinese Analyzer: Optimized for processing Chinese text, with tokenization designed to handle unique language structures.
These built-in analyzers allow developers to input raw text directly into Milvus without the need for external preprocessing, streamlining workflows and reducing complexity.
How Milvus Handles Tokenization
Starting with Milvus 2.5, the database includes built-in full-text search capabilities, enabling it to process raw text inputs internally. When you insert text data, Milvus uses the specified analyzer to tokenize the text into individual, searchable terms. These terms are then converted into sparse vector representations using algorithms like BM25 and stored for efficient retrieval.
This hybrid approach enables Milvus to handle both dense vectors (semantic embeddings) and sparse vectors (keyword-based representations). As a result, Milvus supports advanced hybrid search scenarios that combine semantic understanding with keyword precision, all while managing tokenization and vectorization seamlessly within the database.
Benefits of Built-In Tokenization in Milvus
Simplified Workflow: Milvus's built-in analyzers eliminate the need for external tokenization tools, making it easier to ingest raw text data directly.
Enhanced Search Capabilities: By combining full-text search with vector similarity search, Milvus delivers highly accurate and relevant results for diverse applications.
Scalability: The internal handling of tokenization and vectorization ensures that Milvus can efficiently process large-scale text data across a variety of use cases.
With these features, Milvus enables developers to build intelligent search and analysis applications more easily, focusing on innovation rather than the intricacies of text preprocessing. Whether you're working on natural language search, AI-driven recommendations, or hybrid retrieval systems, Milvus provides a robust and developer-friendly platform to power your applications.
FAQs about Tokenization
01. Why is tokenization important in NLP?
Tokenization converts unstructured text into manageable units, allowing computers to process language. It helps NLP models assign numerical representations to tokens, enabling mathematical operations and extracting meaningful patterns.
02. What's the difference between word and character tokenization?
Word tokenization splits text into individual words, treating each word as a separate token. On the other hand, character tokenization breaks text down into individual characters.
03. What is lemmatization and tokenization?
Tokenization splits text into smaller units, such as words or sentences, making processing easier for computers. Lemmatization reduces words to their base form, such as converting "running" to "run," ensuring consistency in language understanding.
04. How does tokenization affect model performance?
Tokenization affects how text is broken down and understood by a model. Proper tokenization can enhance model performance by capturing accurate relationships between words, while poor tokenization may lead to misinterpretations or loss of meaning.
05. What role does tokenization play in sentiment analysis or text classification?
In sentiment analysis and text classification, tokenization breaks text into smaller units, like words or phrases, which can be analyzed for patterns or sentiment. This process allows algorithms to process individual tokens and classify or assign sentiment to the text accurately.
Related Resources
- TL; DR
- Introduction
- What is Tokenization?
- Why Do We Need Tokenization?
- Key Concepts in Tokenization
- Types of Tokenization
- Comparison Between Tokenization and Word Embedding
- Benefits and Challenges of Tokenization
- Use Cases of Tokenization
- Tools for Tokenization
- Tokenization in the Milvus Vector Database
- FAQs about Tokenization
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free