




Building a Multilingual RAG with Milvus, LangChain, and OpenAI LLM
During the past two years, Retrieval Augmented Generation (RAG) has quickly become one of the most popular techniques for building GenAI applications powered by large language models (LLMs). At its core, RAG enhances an LLM's output by providing contextual information on which the model wasn’t pre-trained. Multilingual RAG is an extended RAG that handles text data in multiple languages.
Yujian Tang, CEO of OSS4AI, recently spoke at an Unstructured Data Meetup hosted by Zilliz. He discussed RAG and its fundamental components and demonstrated how to construct a multilingual RAG to address diverse real-world language challenges.
In this post, we’ll recap the key insights from Yujian’s presentation and guide you through implementing a multilingual RAG. If you’d like to learn more about Yujian’s talk, we recommend you watch his presentation on YouTube.
What is RAG and How Does it Work?
One core limitation of LLM-powered applications is their reliance on the data on which they were trained. If the LLM weren’t exposed to certain information or an entire knowledge domain during pre-training, it wouldn’t understand the linguistic relationships needed to generate accurate responses. This lack of data can lead to the LLM either admitting it doesn’t know the answer or, worse, "hallucinating" and providing incorrect information.
RAG is a popular technique that addresses LLMs’ hallucinatory issues by providing them with additional contextual information. It also enables developers and enterprises to tap into their private or proprietary data without worrying about security issues.
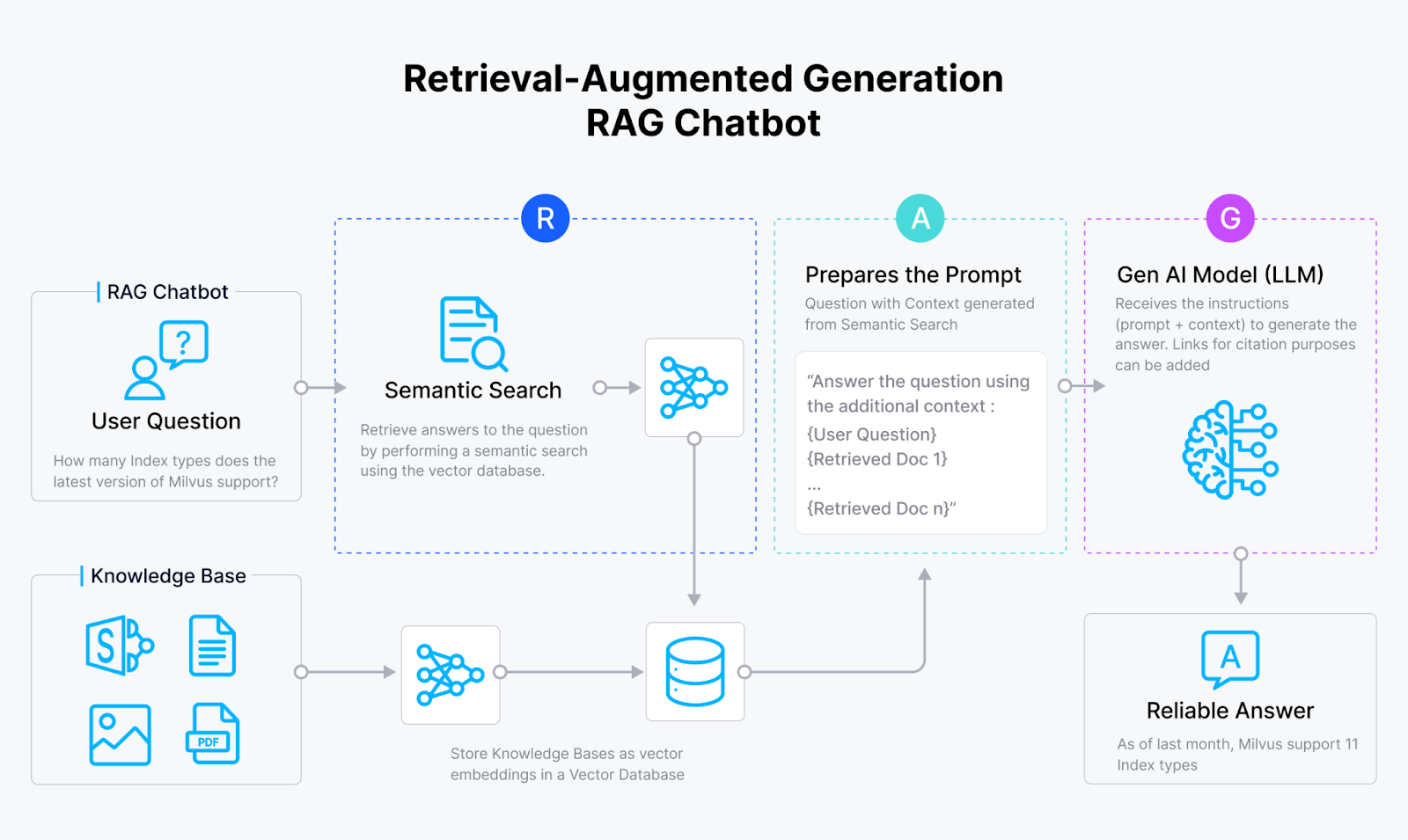 Figure 1- How RAG works
Figure 1- How RAG works
RAG starts with an embedding model that transforms text data into vector embeddings, numerical representations that capture the text's semantic meaning. The RAG system then stores these vectors in a vector database like Milvus or Zilliz Cloud, which indexes them for similarity search.
When a user submits a query, the embedding model also converts the input into a vector. Then, the RAG system compares the similarity of this query vector with the vectors in the vector database by calculating their distance in the high-dimensional vector space. If relevant data is found, the RAG system retrieves this information and adds it to the original query to form a new prompt for the LLM. The LLM uses this extra information to generate a more accurate and contextually relevant response, surpassing what it could produce based solely on its training data.
What is Multilingual RAG?
Multilingual RAG expands the capabilities of traditional RAG to support multiple languages. It integrates an embedding model trained in various languages, enabling the system to process and generate responses across different languages. Using this multilingual approach, the RAG system can handle queries in any language, retrieve relevant information regardless of its original language, and deliver accurate, contextually relevant answers in the user’s preferred language.
How to Build a Multilingual RAG Application: a Step-by-Step Guide
Now that we’ve learned RAG's core concepts and components, let’s implement a multilingual RAG application step by step.
This example application contains two parts: a web scraper and the main application.
The web scraper scrapes the required data set from the internet.
The main application creates vector embeddings, performs vector similarity search, and generates the answers.
The Web Scraper
First, we’ll scrape data from Wikipedia and use it as contextual information for this RAG example.
Define the Titles: We start by defining a list called
wiki_titles, which contains a list of cities. Each city represents a text file the web scraper will populate with content from its corresponding Wikipedia entry. For example, "Atlanta.txt" will contain text scraped from the Atlanta page on Wikipedia.Scrape the Data: We iterate over each city in
wiki_titles, make a GET request to the Wikipedia API, and extract the page content from the JSON response. The text is then saved to a corresponding text file for each city.
from pathlib import Path
import requests
wiki_titles = [
"Atlanta",
"Berlin",
"Boston",
"Cairo",
"Chicago",
"Copenhagen",
"Houston",
"Karachi",
"Lisbon",
"London",
"Moscow",
"Munich",
"Paris",
"Pékin", # French for Beijing
"San Francisco",
"Seattle",
"Shanghai",
"Tokyo",
"Toronto",
]
data_path = Path("./french_city_data")
data_path.mkdir(exist_ok=True) # Ensure directory exists
for title in wiki_titles:
response = requests.get(
"https://fr.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = page.get("extract", "") # Use .get() to avoid KeyError
if wiki_text: # Check if the extract is not empty
with open(data_path / f"{title}.txt", "w") as fp:
fp.write(wiki_text)
else:
print(f"No extract found for {title}")
Preparing Your Environment
First, set up your development environment by installing the necessary libraries: the Milvus vector database, LangChain, OpenAI, and sentence transformers.
Additionally, you’ll need to include your API key if you’re connecting to an LLM through an API, such as OpenAI. This key can be stored in a separate .env file and accessed using load_dotenv() and os .
Here is the code to install the libraries and load your API key:
!pip install -qU pymilvus langchain sentence-transformers tiktoken openai
from dotenv import load_dotenv
import os
load_dotenv() # Load environment variables from the .env file
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY") # Set the API key
Install Libraries: Use
pipto installpymilvus,langchain,sentence-transformers,tiktoken, andopenai.Load Environment Variables: Use
dotenvto load environment variables from a.envfile.Set API Key: Retrieve the OpenAI API key from the environment variables and set it.
Ensure your .env file contains your OpenAI API key in the following format:
OPENAI_API_KEY=your_api_key_here
Initializing the LLM
With your environment set up, the next step is to define the LLM you'll use within your application. In the code snippet below, we achieve this by importing the OpenAI library and defining the LLM with OpenAI’s constructor.
from langchain.llms import OpenAI
llm = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
You can opt for an open-source LLM to avoid the costs associated with OpenAI API calls. Hugging Face offers hundreds of thousands of deep-learning models with which to experiment. To use an open-source LLM from HuggingFace, you'll need to import the Transformers library.
from transformers import pipeline
llm = pipeline('text-generation', model='gpt2') # Replace 'gpt2' with your desired model
You can switch between OpenAI and an open-source model by modifying the relevant import and initialization code.
Choosing an Appropriate Embedding Model
When building a multilingual RAG system, our choice of embedding model is just as important as our choice of LLM, as the embedding model must be compatible with the language you are working with. For this example, where the language is French, the default HuggingFace embeddings are sufficient. However, you must identify and use the most suitable embedding model for other languages.
The MTEB Leaderboard on HuggingFace is a valuable resource for finding embedding models. This leaderboard lists the top-performing embedding models for various languages, such as the Chinese and Polish embeddings identified by Yujian. When selecting an embedding model, you need to specify the model's name as a parameter.
Here’s how to set up the embedding model:
from langchain_community.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings()
# Alternatively, for the Chinese embeddings, the model is # passed as a parameter, e.g.,
# HuggingFaceEmbeddings(model_name="TownsWu/PEG")
Loading and Splitting Data into Chunks
Next, load the city data files we scraped from Wikipedia and divide them into segments, or chunks. By chunking the text, we avoid comparing a query against the entire document, which enhances information retrieval efficiency. The smaller the chunk, as determined by the chunk_size parameter, the greater the accuracy, but the more retrieval operations are required. The more overlap between chunks, as defined by chunk_overlap, the less chance of lost context - at the cost of increased redundancy.
from langchain.text_splitter import CharacterTextSplitter
from langchain.schema import Document
files = os.listdir("./french_city_data")
file_texts = []
for file in files:
with open(f"./french_city_data/{file}") as f:
file_text = f.read()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=512, chunk_overlap=64,
)
texts = text_splitter.split_text(file_text)
for i, chunked_text in enumerate(texts):
file_texts.append(Document(page_content=chunked_text,
metadata={"doc_title": file.split(".")[0], "chunk_num":i}))
Loading Documents into Milvus
After chunking the city data files and storing them as a list of documents, we need to load them into a vector store—in this case, the Milvus vector database. The code below handles the initial load and updates when city data is stored in Milvus.
from langchain_community.vectorstores import Milvus
# For the first run
vector_store = Milvus.from_documents(
file_texts,
embedding=embeddings,
connection_args={"host": "localhost", "port": 19530},
collection_name="french_cities"
)
# if your data is already stored in Milvus
vector_store = Milvus(
embedding_function=embeddings,
connection_args={"host": "localhost", "port": 19530},
collection_name="french cities"
)
Create a Retriever
Next, we’ll initialize our retriever, an interface that returns documents from a particular source based on a given query. The code below uses the vector store we created in the last step as a retriever and assigns it to a variable.
retriever = vector_store.as_retriever()
Create Prompt Template Using LangChain
Prompt templates allow you to format your input to an LLM within your application precisely. They are especially useful for instances where you might want to reuse the same prompt outline but with minor adjustments - as in our multilingual RAG application where we can use the same prompt template for various languages.
Prompt templates also enable you to construct a prompt from dynamic input, e.g., user input or data retrieved from a vector store. In our application, we will dynamically include the question, which will be passed into the chain directly, and the context the retriever obtained from the vector store.
from langchain.prompts import ChatPromptTemplate
template="""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Answer in French.
Question: {question}
Context: {context}
Answer:"""
prompt = ChatPromptTemplate.from_template(template)
Chaining the Components Together to Create the RAG Application
Chaining is a process that connects components to create end-to-end AI applications, which is one of LangChain’s key capabilities.
The code below demonstrates how to construct a chain that includes the following elements: the context from the retriever, the input prompt processed by the runnablepassthrough() function, the prompt template, the LLM, and the stroutparser(), which outputs the response from the chain invocation.
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
Making Queries with the Chain
Once the chain is constructed, you can invoke it with various queries. For example:
response = chain.invoke("Tell me a historical fact about Karachi.")
This query yields the following response in French!
"Karachi a été mentionnée pour la première fois dans l'ouvrage Histoire des plantes de Théophraste au IIIe siècle av. J.-C. Elle a été occupée par les Britanniques au début du XIXe siècle et est devenue la capitale du Sind en 1839. En 1876, le futur fondateur du Pakistan, Muhammad Ali Jinnah, est né et enterré à Karachi."
To demonstrate multilingual capabilities, here's another query—this time in French:
response_2 = chain.invoke("Racontez-moi un fait historique sur Karachi.")
Despite the same underlying question, the different languages (English and French) lead to varying embeddings, resulting in a distinct output:
"Karachi est une ville qui a été fondée par les Britanniques au début du XIXe siècle et qui est devenue la capitale du Sind. Elle a été un important centre économique et a connu une croissance rapide, notamment grâce à son port. Depuis les années 1980, la ville a été le théâtre de conflits ethniques et religieux, et en 2012, elle a été le site de l'incendie industriel le plus meurtrier de l'histoire."
Congratulations! You've successfully built a multilingual RAG application. Keep in mind that embeddings are central to how the LLM interprets languages. Select the most suitable embedding to support multiple languages and integrate it into your application.
Summary
Wow! This is a pretty long post. Let’s recap some of its key points.
Retrieval augmented generation (RAG) is a framework that augments LLM output by inserting additional data into input prompts. RAG can solve the annoying LLM hallucination issues.
Multilingual RAG is an extended RAG that handles multilingual documents.
Embedding models, vector databases, and LLMs are three core components of RAG applications.
The key consideration in developing multilingual RAG applications is the choice of embedding model. HuggingFace’s MTEB Leaderboard is an excellent resource for finding the right model for your application.
Further Resources
Keep Reading

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.