




Image-based Trademark Similarity Search System: A Smarter Solution to IP Protection
Learn how to use a vector database to build your own trademark image similarity search system that could save you from intellectual property lawsuits.
Read the entire series
- Image-based Trademark Similarity Search System: A Smarter Solution to IP Protection
- HM-ANN Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory
- How to Make Your Wardrobe Sustainable with Vector Similarity Search
- Proximity Graph-based Approximate Nearest Neighbor Search
- How to Make Online Shopping More Intelligent with Image Similarity Search?
- An Intelligent Similarity Search System for Graphical Designers
- How to Best Fit Filtering into Vector Similarity Search?
- Building an Intelligent Video Deduplication System Powered by Vector Similarity Search
- Powering Semantic Similarity Search in Computer Vision with State of the Art Embeddings
- Supercharged Semantic Similarity Search in Production
- Accelerating Similarity Search on Really Big Data with Vector Indexing (Part II)
- Understanding Neural Network Embeddings
- Making Machine Learning More Accessible for Application Developers
- Building Interactive AI Chatbots with Vector Databases
- The 2024 Playbook: Top Use Cases for Vector Search
- Leveraging Vector Databases for Enhanced Competitive Intelligence
- Revolutionizing IoT Analytics and Device Data with Vector Databases
- Everything You Need to Know About Recommendation Systems and Using Them with Vector Database Technology
- Building Scalable AI with Vector Databases: A 2024 Strategy
- Enhancing App Functionality: Optimizing Search with Vector Databases
- Applying Vector Databases in Finance for Risk and Fraud Analysis
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
- Safeguarding Data: Security and Privacy in Vector Database Systems
- Integrating Vector Databases with Existing IT Infrastructure
- Transforming Healthcare: The Role of Vector Databases in Patient Care
- Creating Personalized User Experiences through Vector Databases
- The Role of Vector Databases in Predictive Analytics
- Unlocking Content Discovery Potential with Vector Databases
- Leveraging Vector Databases for Next-Level E-Commerce Personalization
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
This article is transcreated by Angela Ni.
In recent years, the issue of IP protection has come under the limelight as people's awareness of IP infringement is ever-increasing. Most notably, the multi-national technology giant Apple Inc. has been actively filing lawsuits against various companies for IP infringement, including trademark, patent, and design infringement. Apart from those most notorious cases, Apple Inc. also disputed a trademark application by Woolworths Limited, an Australian supermarket chain, on the grounds of trademark infringement in 2009. Apple. Inc argued that the logo of the Australian brand, a stylized "w", resembles their own logo of an apple. Therefore, Apple Inc. took objection to the range of products, including electronic devices, that Woolworths applied to sell with the logo. The story ends with Woolworths amending its logo and Apple withdrawing its opposition.
With the ever-increasing awareness of brand culture, companies are keeping a closer eye on any threats that will harm their intellectual properties (IP) rights. IP infringement includes:
- Copyright infringement
- Patent infringement
- Trademark infringement
- Design infringement
- Cybersquatting
The aforementioned dispute between Apple and Woolworths is mainly over trademark infringement, precisely the similarity between the trademark images of the two entities. To refrain from becoming another Woolworths, an exhaustive trademark similarity search is a crucial step for applicants both prior to the filing as well as during the review of trademark applications. The most common resort is through a search on the United States Patent and Trademark Office (USPTO) database that contains all of the active and inactive trademark registrations and applications. Despite the not so charming UI, this search process is also deeply flawed by its text-based nature as it relies on words and Trademark Design codes (which are hand annotated labels of design features) to search for images.
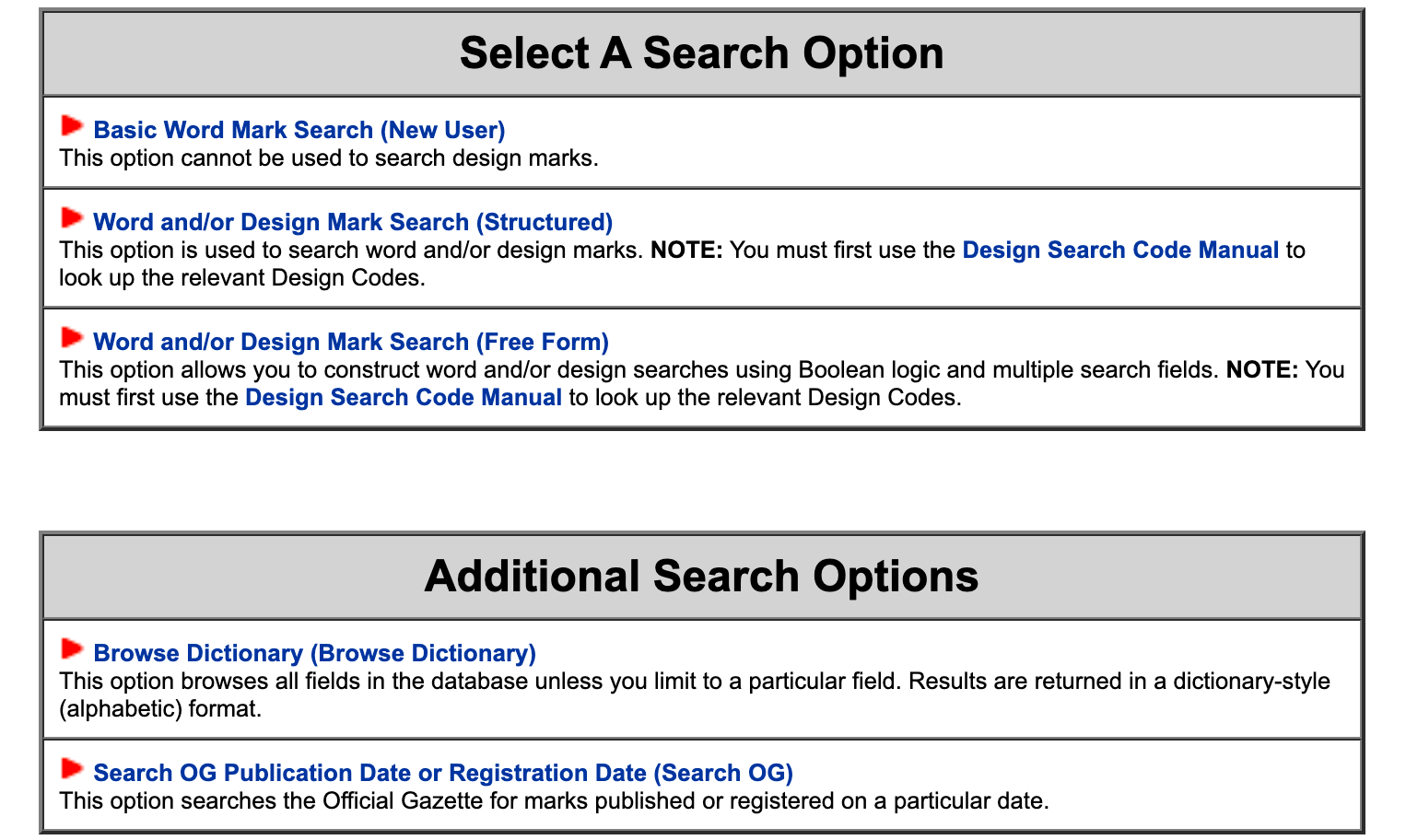 The text-based trademark search options offered by the Trademark Electronic Search System (TESS).
The text-based trademark search options offered by the Trademark Electronic Search System (TESS).
This article intends to explain how to build a vector similarity search system for trademarks using Milvus, an open-source vector database.
A vector similarity search system for trademarks
To build a vector similarity search system for trademarks, you need to go through the following steps:
- Prepare a massive dataset of logos. Likely, the system can use a dataset like USPTO Dataset.
- Train an image feature extraction model using the dataset and data-driven models or AI algorithms.
- Convert logos into vectors using the trained model or algorithm in step 2.
- Store the vectors and conduct vector similarity searches in Milvus, the open-source vector database.
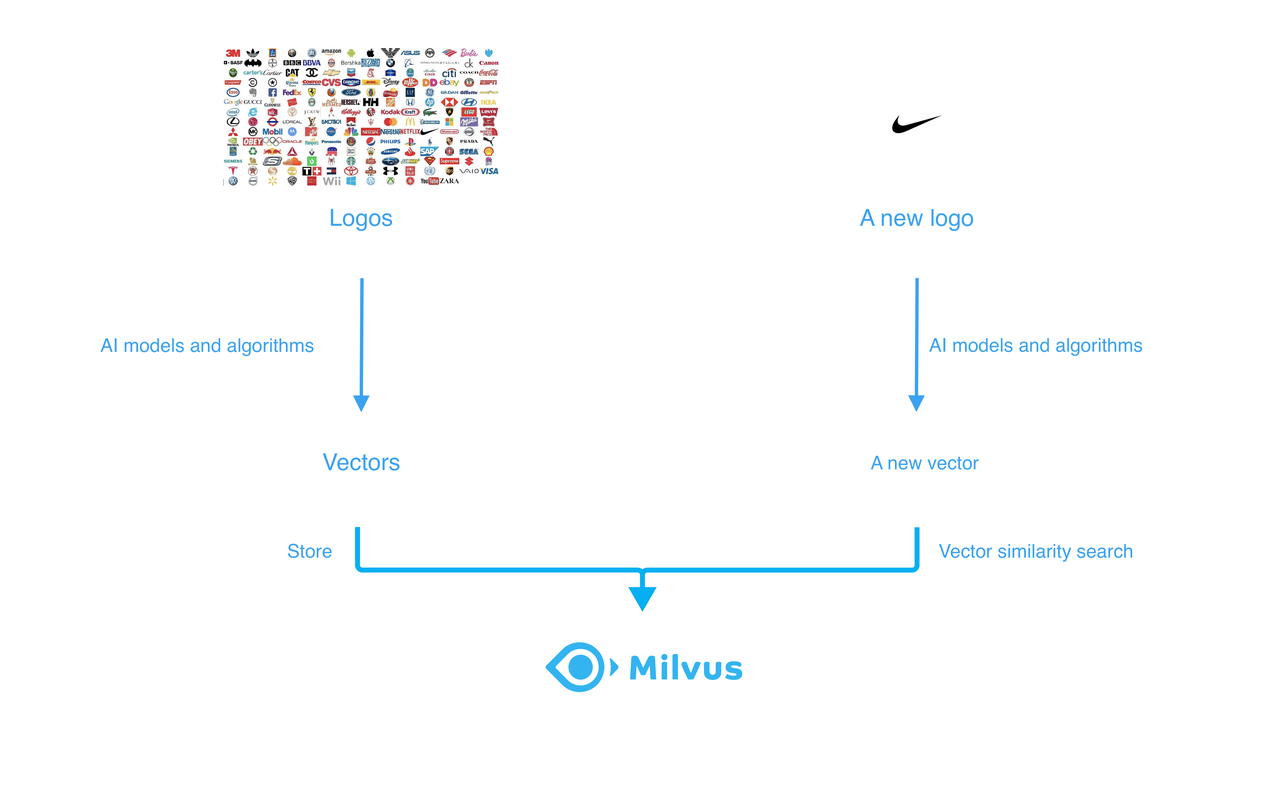 The workflow of trademark similarity search system.
The workflow of trademark similarity search system.
To accelerate the process of feature extraction, you can deploy the trained AI model on multiple servers. However, you do not have to worry about data inconsistency if you use distributed service to process data because you can use Flask to ensure synchronized data processing.
When the system is built, your user only needs to upload an image of a logo, and then the system converts this new image into a new vector using the same AI model you trained. The system searches for similar vectors to the new vector in the Milvus database and returns the corresponding vector IDs. Ultimately, your user will be able to see all the results of similar logos to the one he or she has uploaded. The following screenshot is a demonstration of a vector similarity search system for trademarks. As you can see, the user uploaded the logo, the swoosh, of the sportswear brand Nike. The system returns all images that are similar to this logo.
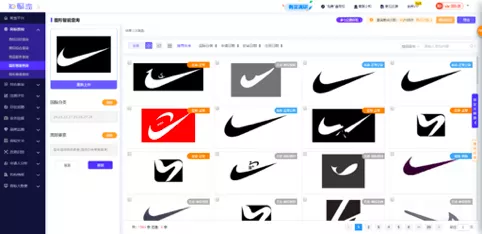 A demo of the trademark similarity search system.
A demo of the trademark similarity search system.
In the following sections, let's take a closer look at the two major steps in building a vector similarity search system for trademarks: using AI models for image feature extraction, and using Milvus for vector similarity search. In our case, we used VGG16, a convolutional neural network (CNN), to extract image features and convert them into embedding vectors.
Using VGG16 for image feature extraction
VGG16 is a CNN designed for large-scale image recognition. The model is quick and accurate in image recognition and can be applied to images of all sizes. The following are two illustrations of the VGG16 architecture.
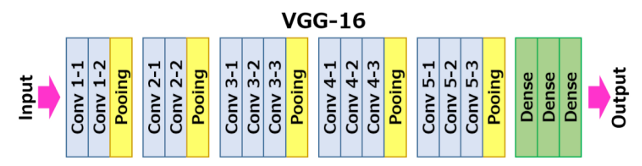 vgg16 layers.
vgg16 layers.
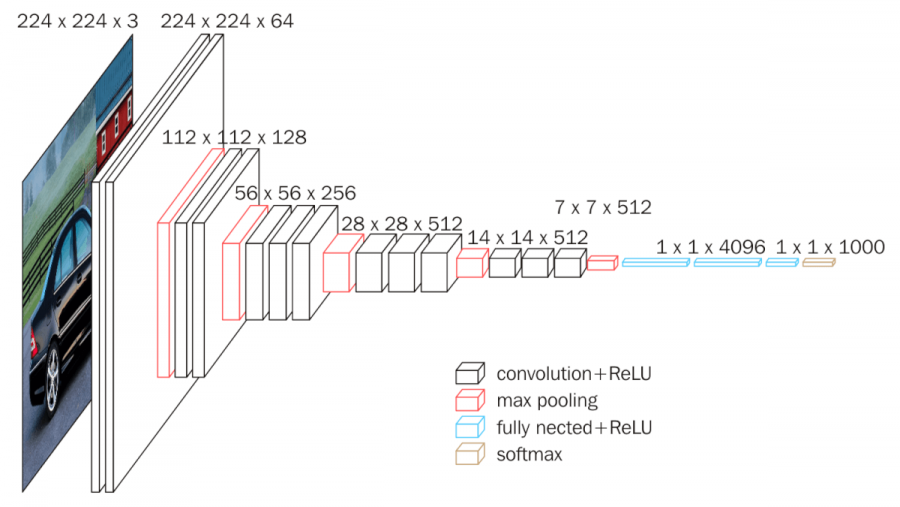 vgg16 architecture.
vgg16 architecture.
The VGG16 model, as its name suggests, is a CNN with 16 layers. All VGG models, including VGG16 and VGG19, contain 5 VGG blocks, with one or more convolutional layers in each VGG block. And at the end of each block, a max pooling layer is connected to reduce the size of the input image. The number of kernels is equivalent within each convolutional layer but doubles in each VGG block. Therefore, the number of kernels in the model grows from 64 in the first block, to 512 in the fourth and fifth blocks. All the convolutional kernels are 33-sized while the pooling kernels are all 22-sized. This is conducive to preserving more information about the input image.
Therefore, VGG16 is a suitable model for image recognition of massive datasets in this case. You can use Python, Tensorflow, and Keras to train an image feature extraction model on the basis of VGG16.
Using Milvus for vector similarity search
After using the VGG16 model to extract image features and convert logo images into embedding vectors, you need to search for similar vectors from a massive dataset.
Milvus is a cloud-native database featuring high scalability and elasticity. Also, as a database, it can ensure data consistency. For a trademark similarity search system like this, new data like the latest trademark registrations are uploaded to the system in real time. And these newly uploaded data need to be available for search immediately. Therefore, this article adopts Milvus, the open-source vector database, to conduct vector similarity search.
When inserting the logo vectors, you can create collections in Milvus for different types of logo vectors according to the International (Nice) Classification of Goods and Services, a system of classifying goods and services for registering trademarks. For example, you can insert a group of vectors of clothing brand logos into a collection named "clothing" in Milvus and insert another group of vectors of technological brand logos into a different collection named "technology". By doing so, you can greatly increase the efficiency and speed of your vector similarity search.
Milvus not only supports multiple indexes for vector similarity search, but also provides rich APIs and tools to facilitate DevOps. The following diagram is an illustration of the Milvus architecture. You can learn more about Milvus by reading its introduction.
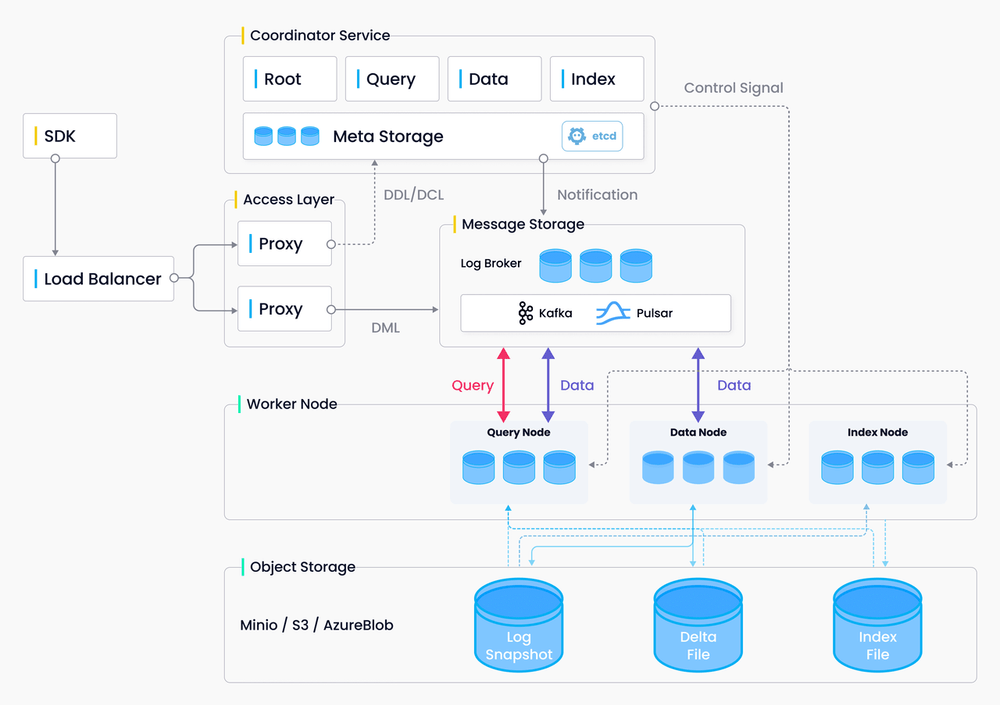 The Milvus architecture.
The Milvus architecture.
Looking for more resources?
- Application of vector similarity search in more industries:

Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

How to Make Online Shopping More Intelligent with Image Similarity Search?
Learn how to build an intelligent image similarity search system for online shopping using a vector database.

Applying Vector Databases in Finance for Risk and Fraud Analysis
How to use the Milvus Vector Database in Finance

The Role of Vector Databases in Predictive Analytics
Explore how vector databases enhance Predictive Models and their applications.