




Building an Intelligent Video Deduplication System Powered by Vector Similarity Search
Learn how to use the Milvus vector database to build an automated solution for identifying and filtering out duplicate video content from archive storage.
Read the entire series
- Image-based Trademark Similarity Search System: A Smarter Solution to IP Protection
- HM-ANN Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory
- How to Make Your Wardrobe Sustainable with Vector Similarity Search
- Proximity Graph-based Approximate Nearest Neighbor Search
- How to Make Online Shopping More Intelligent with Image Similarity Search?
- An Intelligent Similarity Search System for Graphical Designers
- How to Best Fit Filtering into Vector Similarity Search?
- Building an Intelligent Video Deduplication System Powered by Vector Similarity Search
- Powering Semantic Similarity Search in Computer Vision with State of the Art Embeddings
- Supercharged Semantic Similarity Search in Production
- Accelerating Similarity Search on Really Big Data with Vector Indexing (Part II)
- Understanding Neural Network Embeddings
- Making Machine Learning More Accessible for Application Developers
- Building Interactive AI Chatbots with Vector Databases
- The 2024 Playbook: Top Use Cases for Vector Search
- Leveraging Vector Databases for Enhanced Competitive Intelligence
- Revolutionizing IoT Analytics and Device Data with Vector Databases
- Everything You Need to Know About Recommendation Systems and Using Them with Vector Database Technology
- Building Scalable AI with Vector Databases: A 2024 Strategy
- Enhancing App Functionality: Optimizing Search with Vector Databases
- Applying Vector Databases in Finance for Risk and Fraud Analysis
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
- Safeguarding Data: Security and Privacy in Vector Database Systems
- Integrating Vector Databases with Existing IT Infrastructure
- Transforming Healthcare: The Role of Vector Databases in Patient Care
- Creating Personalized User Experiences through Vector Databases
- The Role of Vector Databases in Predictive Analytics
- Unlocking Content Discovery Potential with Vector Databases
- Leveraging Vector Databases for Next-Level E-Commerce Personalization
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
This article is transcreated by Angela Ni.
Deduplication refers to eliminating redundant data in the database. This is not a new idea in the industry. However, it seems a necessary solution to managing today's explosive data growth, especially the growth of unstructured data like videos.
Online video streaming platforms such as Youtube store massive volumes of archive videos. It is very likely that there are many duplicate video resources in the archive. But the data redundancy brings two problems:
- Duplicate videos take up much of the storage. According to statistics, an uncompressed 4K one-minute long clip could require over 40 GB of storage.
- Duplicate videos are not conducive to an excellent user experience. Online video platforms usually adopt AI algorithms calculating user interests, and recommend a variety of videos to users. However, if the archival resources are duplicated, it is highly possible that users will be shown a list of redundant content in recommendation.
Therefore, to manage data more efficiently and optimize user experience, a video deduplication system is necessary for online video platforms.
This tutorial aims to explain how to build an intelligent video deduplication system using a vector database designed for vector management and vector similarity search.
System implementation
Generally, when conducting video similarity search, the system extracts several key frames of a video clip and converts these key frames into multiple feature vectors, using deep learning models. Then here comes the problem. How do we calculate the similarity between multiple feature vectors? One common practice is to combine all the feature vectors and generate one single vector for the next stage - vector similarity search. However, for those small and medium enterprises whose resources are limited, there is another alternative. Another solution is to treat a video clip as an aggregation of multiple images. The video deduplication system extracts a certain number of key frames (images) from a video clip to create an image set. In this way, a video clip is represented by an image set. The video deduplication system defines the similarity between two videos as the similarity of two image sets, and uses Milvus, an open-source vector database, to calculate the similarity. Since in this tutorial, we intend to build an MVP deduplication system, we will use the second way instead of combining the feature vectors.
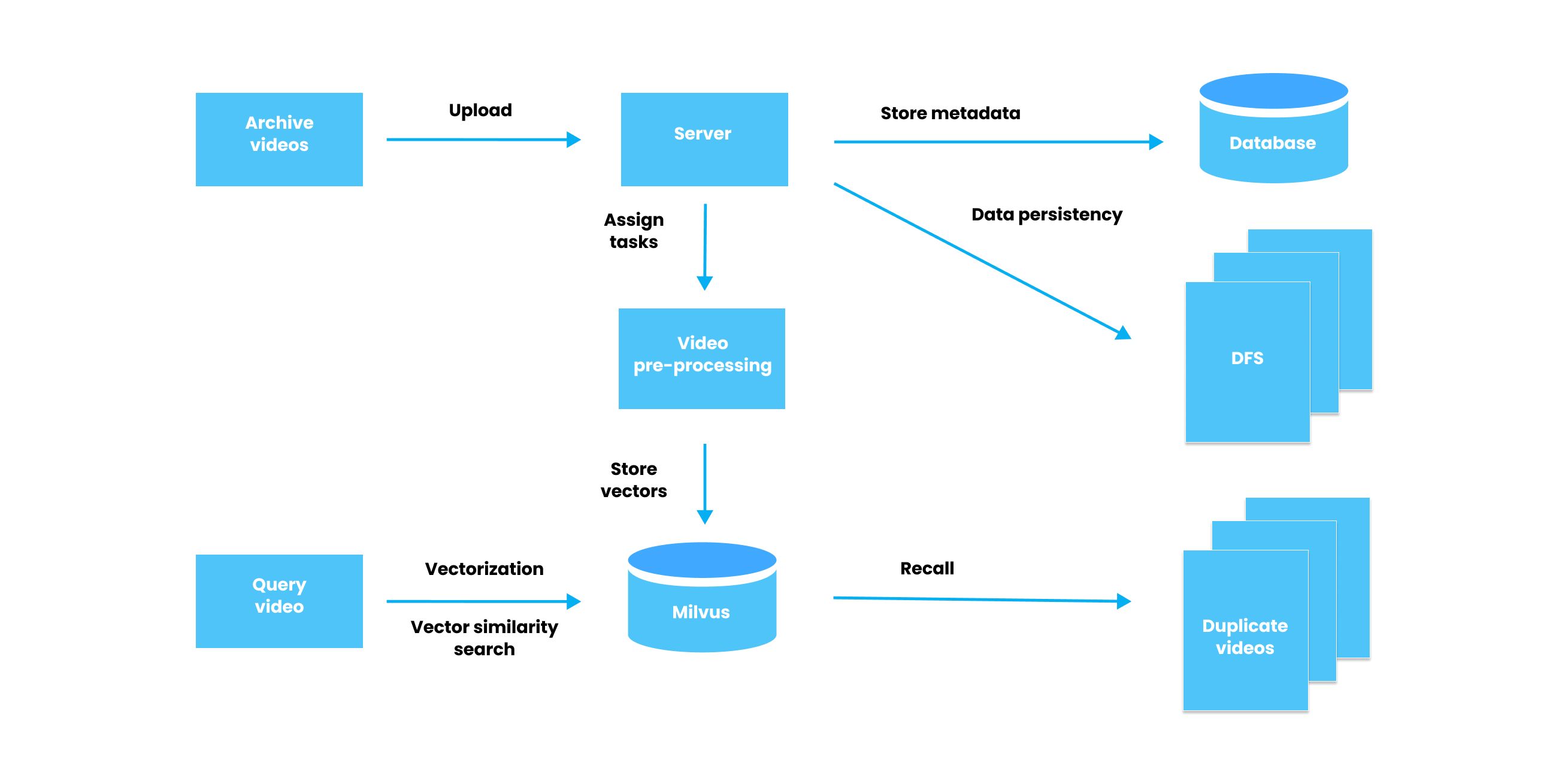 The workflow of a video deduplication system.
The workflow of a video deduplication system.
- Archive videos are uploaded to the server by engineers of an online video platform. Meanwhile, the corresponding metadata of these archive videos are stored in a relational database. In addition, a distributed file system (DFS) is also adopted for data persistency.
- When the archive videos are uploaded, the video processing task is triggered in the system. As a result, the system preprocesses the uploaded archive videos, extracts key frames, converts the key frame images into feature vectors, and stores the vectors in a vector database. Note that each video is represented by the set of feature vectors converted from its key frames.
- Whenever a new video is uploaded, the system turns the newly uploaded video into a new set of feature vectors. Then the system conducts vector similarity search in the same vector database, calculates the similarity between the newly uploaded video and the archive videos stored in the database, and returns TopK similar videos.
The following section describes the key steps of building an intelligent video deduplication system in detail.
Key steps
1. Convert a video into an image set
ffprobe is a tool specifically designed for analyzing multi-media assets. It extracts information from streaming videos or audios and prints the information in a human- and machine-readable fashion. ffprobe can also be used to detect the format of the container used by a multimedia stream as well as the format and type of each multi-media asset. Use the following command to obtain information about the duration of a video.
ffprobe -show_format -print_format json -v quiet input.mp4
FFmpeg is an open-source tool for audio and video analysis that supports recording and converting audio and video clips into multiple formats. We use FFmpeg to extract a certain amount of frames in the video at a certain interval. For instance, if a video clip lasts for 100 seconds and we extract the frames every 10 seconds, the extraction ratio is 0.1. Run the following command to extract the video frames.
ffmpeg -i input.mp4 -r 0.1 ./images/frames_%02d.jpg
2. Convert images into feature vectors
Pre-processing of the images includes cropping, enlarging, and reducing images, as well as adjusting image gray scale, and more. After pre-processing the images, use the pre-trained deep learning model VGG or ResNet to convert the images into 1000-dimensional feature vectors.
# Use the nativeImageLoader to convert to numerical matrix
File f=new File(absolutePath, "drawn_image.jpg");
NativeImageLoader loader = new NativeImageLoader(height, width, channels);
# put image into
INDArrayINDArray image = loader.asMatrix(f);
# values need to be scaled
DataNormalization scalar = new ImagePreProcessingScaler(0, 1);
# then call that scalar on the image dataset
scalar.transform(image);
# pass through neural net and store it in output array
output = model.output(image);
3. Calculate video similarity
As mentioned above, video similarity is equivalent to the similarity of two image sets. However, we cannot calculate the similarity of two sets of vectors directly. Only the similarity of two single vectors is calculable. Therefore, we need to define the rules for calculating the similarity between two image sets:
- A = The similarity between an image and another image = The inner product (IP) of image feature vectors.
- B = The similarity between an image and an image set = The maximum value of A.
- The similarity between an image set and another image set = The average value of A and B.
To further clarify the rules, suppose we have two vector sets and would love to know their similarity.
- Set 1 (containing Vec_1, Vec_2, ..., and Vec_10)
- Set 2 (Vec_11, Vec_12, ..., Vec_20)
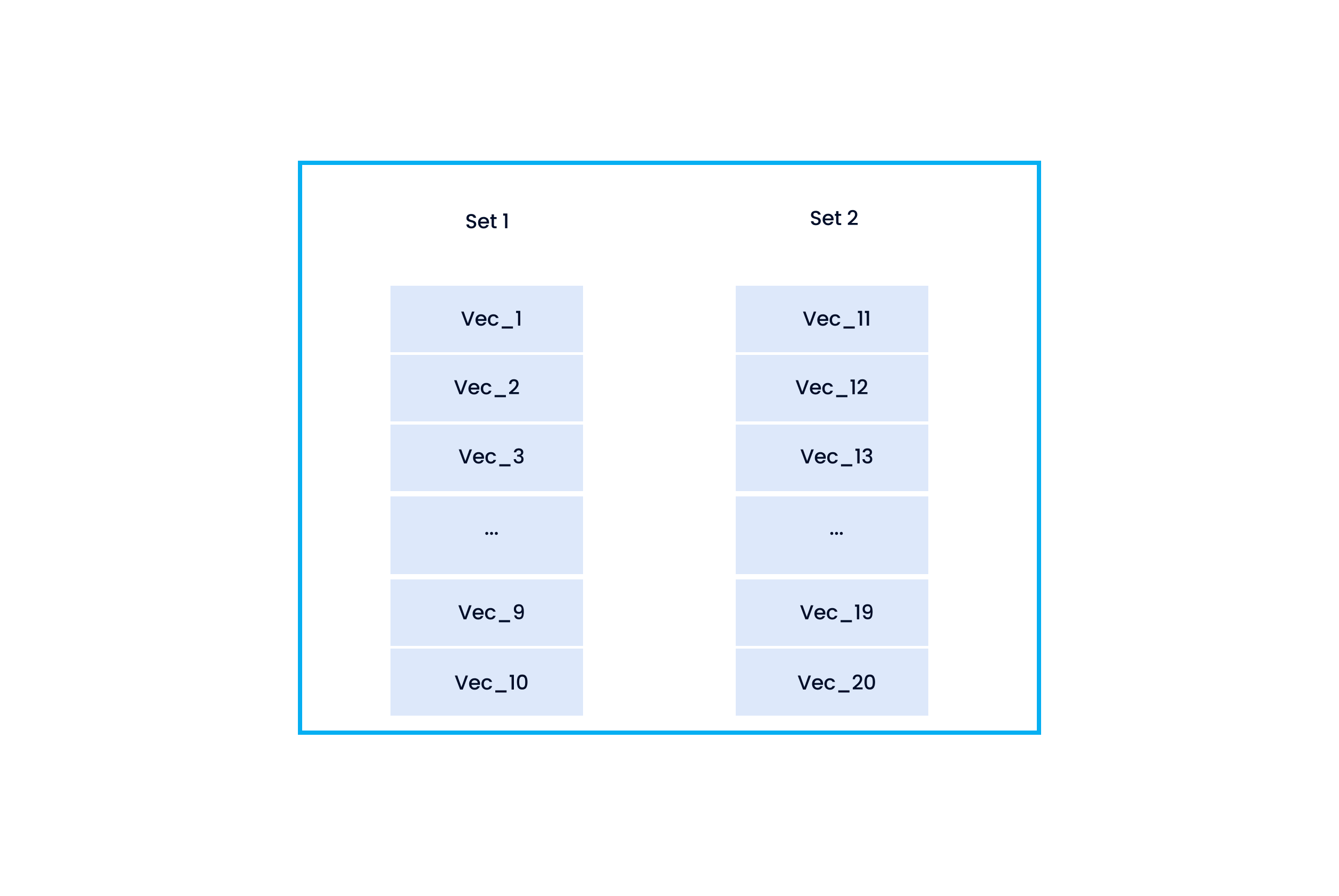 Two image sets, each containing 10 vectors.
Two image sets, each containing 10 vectors.
First, we compare Vec_1 with Vec_11, Vec_12, ..., and Vec_20 respectively and calculate the inner product value. Then, we will obtain IP_1, IP_2, ..., and IP_10. The maximum value among them is the similarity between Vec_1 and Set 1, and we rename the maximum value as Max_1. For example, IP_3 is the largest among IP_1 to IP_10. This is to say, the similarity between Vec_1 and Set 1 equals IP_3 (the similairty between Vec_1 and Vec_13). We rename IP_3 as Max_1. Subsequently, we repeat the same process by comparing the rest of the vectors in Set 1 to each vector in Set 2. After this, we will obtain Max_1, Max_2, ..., and Max_10. The similarity of Set 1 and Set 2 equals the average mean of Max_1, Max_2, ..., and Max_10.
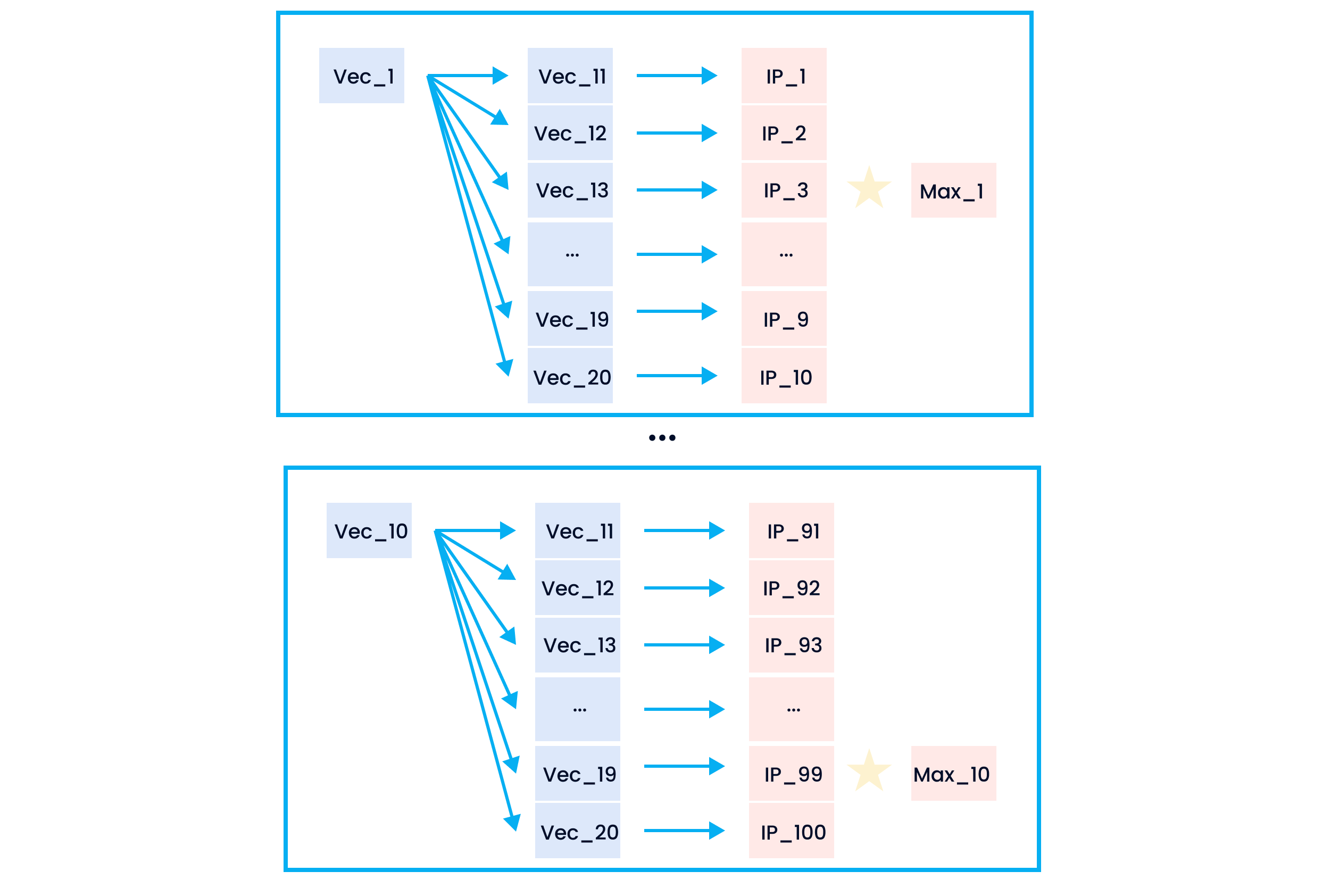 The calculation of similarity between vectors and vector sets.
The calculation of similarity between vectors and vector sets.
4. Vector similarity search powered by Milvus
As a database specifically designed to handle queries over input vectors, Milvus is capable of indexing vectors on a trillion scale. Unlike existing relational databases which mainly deal with structured data following a pre-defined pattern, Milvus is designed from the bottom-up to handle embedding vectors converted from unstructured data.
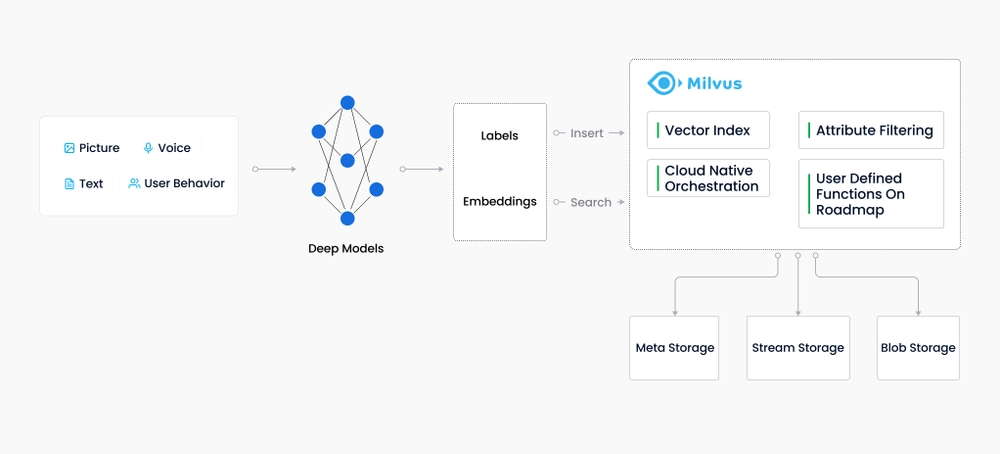 How Milvus fits into the data workflow.
How Milvus fits into the data workflow.
As the Internet grew and evolved, unstructured data became more and more common, including emails, papers, IoT sensor data, Facebook photos, protein structures, and much more. In order for computers to understand and process unstructured data, these are converted into vectors using embedding techniques. Milvus stores and indexes these vectors. Milvus is able to analyze the correlation between two vectors by calculating their similarity distance. If the two embedding vectors are very similar, it means that the original data sources are similar as well.
In this tutorial, follow the steps below to conduct vector similarity search in Milvus:
- Store the image feature vectors in Milvus, the vector database. And Milvus will automatically generate corresponding IDs for the feature vectors.
- Conduct vector similarity search in batches in Milvus and obtain the preliminary TopK results.
- Calculate the similarity between videos according to the pre-defined formulae in step 3 to return TopK results.
System optimization
This tutorial serves as a basic instruction on building a minimum viable product (MVP). However, more work can be done to further optimize the system:
- Optimize the frame extraction strategy. Try to extract frames that are more representative of the video.
- Minimize the influence of video duration on video similarity.
- Add more weight to videos of longer duration to obtain more accurate results when calculating the weighted average mean of video similarity.
Looking for more resources?
- Application of vector similarity search in more industries:
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Safeguarding Data: Security and Privacy in Vector Database Systems
With vector data providing so much power, it is paramount to prioritize robust data security and privacy measures.

The Role of Vector Databases in Predictive Analytics
Explore how vector databases enhance Predictive Models and their applications.

Enhancing Customer Experience with Vector Databases: A Strategic Approach
Understand how vector databases process data to enhance customer experience and drive business growth.