




How to Make Online Shopping More Intelligent with Image Similarity Search?
Learn how to build an intelligent image similarity search system for online shopping using a vector database.
Read the entire series
- Image-based Trademark Similarity Search System: A Smarter Solution to IP Protection
- HM-ANN Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory
- How to Make Your Wardrobe Sustainable with Vector Similarity Search
- Proximity Graph-based Approximate Nearest Neighbor Search
- How to Make Online Shopping More Intelligent with Image Similarity Search?
- An Intelligent Similarity Search System for Graphical Designers
- How to Best Fit Filtering into Vector Similarity Search?
- Building an Intelligent Video Deduplication System Powered by Vector Similarity Search
- Powering Semantic Similarity Search in Computer Vision with State of the Art Embeddings
- Supercharged Semantic Similarity Search in Production
- Accelerating Similarity Search on Really Big Data with Vector Indexing (Part II)
- Understanding Neural Network Embeddings
- Making Machine Learning More Accessible for Application Developers
- Building Interactive AI Chatbots with Vector Databases
- The 2024 Playbook: Top Use Cases for Vector Search
- Leveraging Vector Databases for Enhanced Competitive Intelligence
- Revolutionizing IoT Analytics and Device Data with Vector Databases
- Everything You Need to Know About Recommendation Systems and Using Them with Vector Database Technology
- Building Scalable AI with Vector Databases: A 2024 Strategy
- Enhancing App Functionality: Optimizing Search with Vector Databases
- Applying Vector Databases in Finance for Risk and Fraud Analysis
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
- Safeguarding Data: Security and Privacy in Vector Database Systems
- Integrating Vector Databases with Existing IT Infrastructure
- Transforming Healthcare: The Role of Vector Databases in Patient Care
- Creating Personalized User Experiences through Vector Databases
- The Role of Vector Databases in Predictive Analytics
- Unlocking Content Discovery Potential with Vector Databases
- Leveraging Vector Databases for Next-Level E-Commerce Personalization
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
This article is transcreated by Angela Ni.
Due to the coronavirus pandemic, people increasingly sought to socially distance themselves and avoid contact with strangers. As a result, no-contact delivery became an incredibly desirable option for many consumers. Amazon, the leading online retailer, reported that its net sales increased from 110.8 billion in the third quarter of 2021, a 15% year-over-year (YoY) growth. The rising popularity of e-commerce has also led to people buying a greater variety of goods online, including niche items that can be hard to describe using a traditional keyword search.
To help users overcome the limitations of keyword-based queries, companies can build image search engines that allow users to use images instead of words for search. Not only does this allow users to find items that are difficult to describe, but it also helps them shop for things they encounter in real life. This functionality helps build a unique user experience and offers general convenience that customers appreciate.
This article explores how to use AI models and a vector database to build an image search engine for online shopping platforms.
How does image search work?
An image search system searches in the database inventory for product images that are similar to user uploads. The following chart shows the two stages of the system process, the data import stage (the right column) and the query stage (the left column):
- Detect targets from uploaded photos. This article uses the YOLO model.
- Extract feature vectors from the detected targets. This article uses ResNet.
- Conduct vector similarity search in a vector database. This article used Milvus, the open-source vector database.
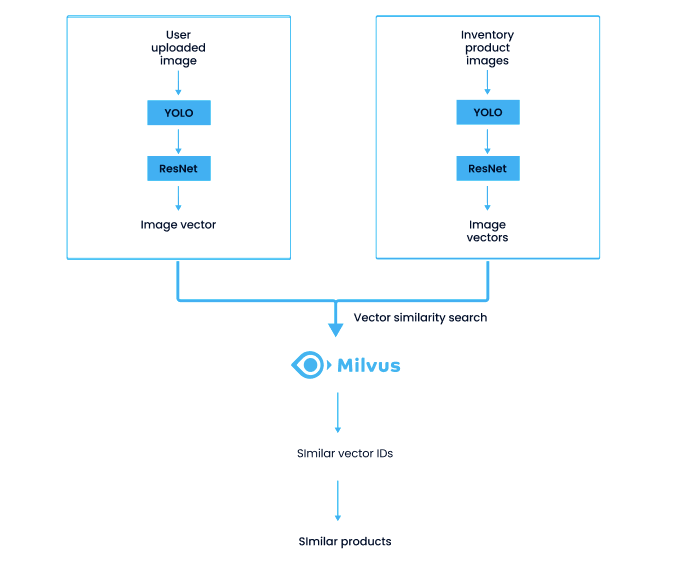 System process of an image similarity search system for e-commerce.
System process of an image similarity search system for e-commerce.
Target detection using the YOLO model
This article uses YOLO (You only look once) to detect objects in user uploaded images. YOLO is a one-stage model, using only one convolutional neural network (CNN) to predict categories and positions of different targets. It is small, compact, and well-suited for mobile use.
YOLO uses convolutional layers to extract features and fully-connected layers to obtain predicted values. Drawing inspiration from the GooLeNet model, YOLO’s CNN includes 24 convolutional layers and two fully-connected layers.
As the following illustration shows, a 448 × 448 input image is converted by a number of convolutional layers and pooling layers to a 7 × 7 × 1024-dimensional tensor (depicted in the third to last cube below), and then converted by two fully-connected layers to a 7 × 7 × 30-dimensional tensor output.
The predicted output of YOLO P is a two-dimensional tensor, whose shape is [batch,7 ×7 ×30]. Using slicing, P[:,0:7×7×20] is the category probability, P[:,7×7×20:7×7×(20+2)] is the confidence, and P[:,7×7×(20+2)]:] is the predicted result of the bounding box.
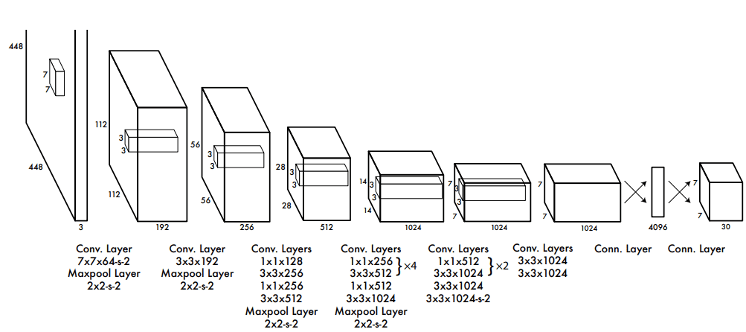 The YOLO network architecture.
The YOLO network architecture.
Image feature vector extraction with ResNet
After the images go through YOLO, they need to be converted into vectors for the system to process. This article adopts the residual neural network (ResNet) model to extract feature vectors from an extensive product image library and user uploaded photos. ResNet is limited because as the depth of a learning network increases, the accuracy of the network decreases. The image below depicts ResNet running the VGG19 model (a variant of the VGG model) modified to include a residual unit through the short circuit mechanism. VGG was proposed in 2014 and includes just 14 layers, while ResNet came out a year later and can have up to 152.
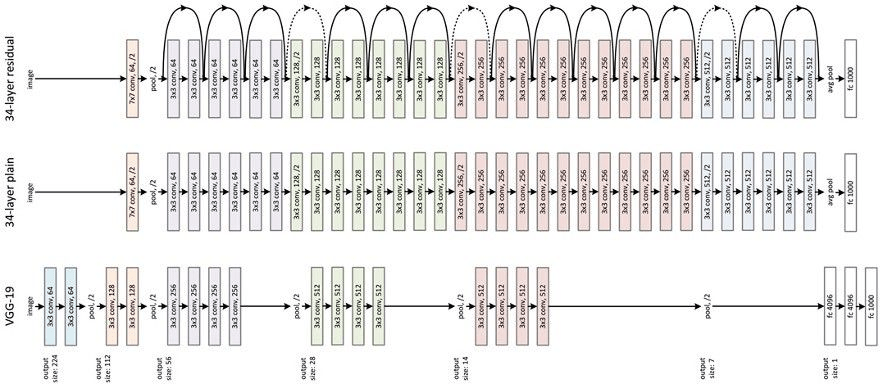 The ResNet structure.
The ResNet structure.
The ResNet structure is easy to modify and scale. By changing the number of channels in the block and the number of stacked blocks, the width and depth of the network can be easily adjusted to obtain networks with different expressive capabilities. This effectively solves the network degeneration effect, where accuracy declines as the depth of learning increases. With sufficient training data, a model with improving expressive performance can be obtained while gradually deepening the network. Through model training, features are extracted for each picture and converted to 256-dimensional floating point vectors.
Vector similarity search powered by Milvus
When images are converted into vectors using ResNet, a vector database is needed to manage and process the vectors. To quickly retrieve the most similar product images from this massive dataset, Milvus is used to conduct vector similarity search. Milvus is an open-source vector database that offers a fast and streamlined approach to managing vector data and building machine learning applications. Milvus offers integration with popular index libraries (e.g., Faiss, Annoy), and supports multiple index types and distance metrics.
In addition, online shopping platforms usually have a library of massive, billion-scale, or even trillion-scale image data. Processing such large volumes of data has a high demand for the vector database. Therefore, a distributed system with high scalability can fit the situation better. Milvus also adopts cloud-native architecture and provides a distributed version. You can easily scale your Milvus cluster in order to process large volumes of vector data.
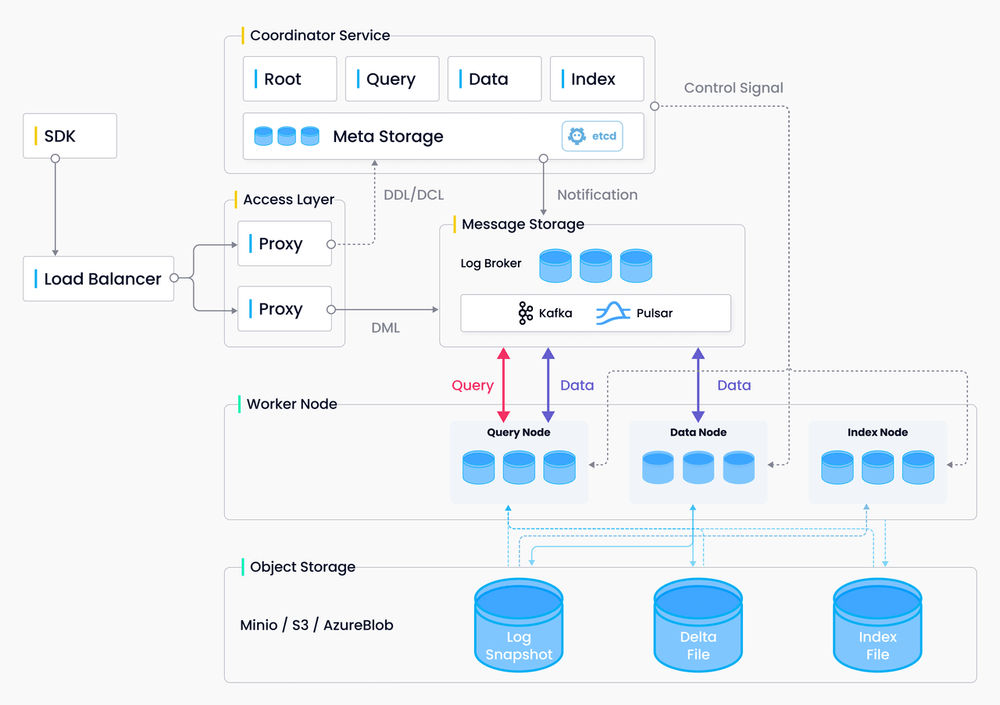 The Milvus architecture.
The Milvus architecture.
Looking for more resources?
- Application of vector similarity search in more industries:

Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Making Machine Learning More Accessible for Application Developers
Learn how Towhee, an open-source embedding pipeline, supercharges the app development that requires embeddings and other ML tasks.

Transforming Healthcare: The Role of Vector Databases in Patient Care

Leveraging Vector Databases for Next-Level E-Commerce Personalization
Explore the concepts of vector embeddings and vector databases and their role in improving the user experience in e-commerce.