




Supercharged Semantic Similarity Search in Production
Read the entire series
- Image-based Trademark Similarity Search System: A Smarter Solution to IP Protection
- HM-ANN Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory
- How to Make Your Wardrobe Sustainable with Vector Similarity Search
- Proximity Graph-based Approximate Nearest Neighbor Search
- How to Make Online Shopping More Intelligent with Image Similarity Search?
- An Intelligent Similarity Search System for Graphical Designers
- How to Best Fit Filtering into Vector Similarity Search?
- Building an Intelligent Video Deduplication System Powered by Vector Similarity Search
- Powering Semantic Similarity Search in Computer Vision with State of the Art Embeddings
- Supercharged Semantic Similarity Search in Production
- Accelerating Similarity Search on Really Big Data with Vector Indexing (Part II)
- Understanding Neural Network Embeddings
- Making Machine Learning More Accessible for Application Developers
- Building Interactive AI Chatbots with Vector Databases
- The 2024 Playbook: Top Use Cases for Vector Search
- Leveraging Vector Databases for Enhanced Competitive Intelligence
- Revolutionizing IoT Analytics and Device Data with Vector Databases
- Everything You Need to Know About Recommendation Systems and Using Them with Vector Database Technology
- Building Scalable AI with Vector Databases: A 2024 Strategy
- Enhancing App Functionality: Optimizing Search with Vector Databases
- Applying Vector Databases in Finance for Risk and Fraud Analysis
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
- Safeguarding Data: Security and Privacy in Vector Database Systems
- Integrating Vector Databases with Existing IT Infrastructure
- Transforming Healthcare: The Role of Vector Databases in Patient Care
- Creating Personalized User Experiences through Vector Databases
- The Role of Vector Databases in Predictive Analytics
- Unlocking Content Discovery Potential with Vector Databases
- Leveraging Vector Databases for Next-Level E-Commerce Personalization
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
Introduction
I introduced three simple methods to convert images into embeddings for similarity search applications using state-of-the-art neural networks in my previous post. In this post, let's discuss how we can use those embeddings together with Milvus, one of the most popular open-source vector search databases, to create a production scale Text-to-Image search application. Specifically, in this post, we'll cover
- Considerations for production-scale vector similarity search
- Setup the environment and download some data
- Implementing a text-to-image similarity search application using Milvus
For this post, we'll be using the H&M Personalized Fashion Recommendations competitions dataset from Kaggle to build a highly scalable text-to-image e-commerce product search service. The dataset is licensed under the Non-Commercial Purposes & Academic Research license.
Considerations for production-scale vector similarity search
In my previous post, we found similar images by calculating the cosine similarity between a query image's vector and all the other image vectors we had. While this approach worked well for the small dataset used in that post, it runs into trouble when scaling to production workloads.
To be clear, when I mention production workloads, I'm talking about a real-world e-commerce application that contains
- Total search space of tens or hundreds of millions or even billions of images
- Thousands of search queries per second
- Sub-second search speed for each query
If every query is required to scan the entire database of several millions of image vectors, there is no cost-effective way to return the results with sub-second latency. So what can we do here?
Approximate Nearest Neighbors
In my article KNN is Dead! I've introduced and empirically proved that finding nearest neighbors using an exhaustive pairwise distance computation is highly inefficient and takes too much time. Instead, the solution to scale similarity search to large data volumes is to sidestep the brute force distance computations entirely and instead use a more sophisticated class of algorithms called Approximate Nearest Neighbors (ANN).
ANN algorithms work by loading all the image vectors into an ANN index data structure, which allows for a fast and efficient nearest neighbors search. There are several kinds of ANN indexes such as Quantization-based, Graph-based, Tree-based and Hash-based. Please check the Milvus documentation for a comprehensive guide to various ANN indexes and recommendations on when to use each.
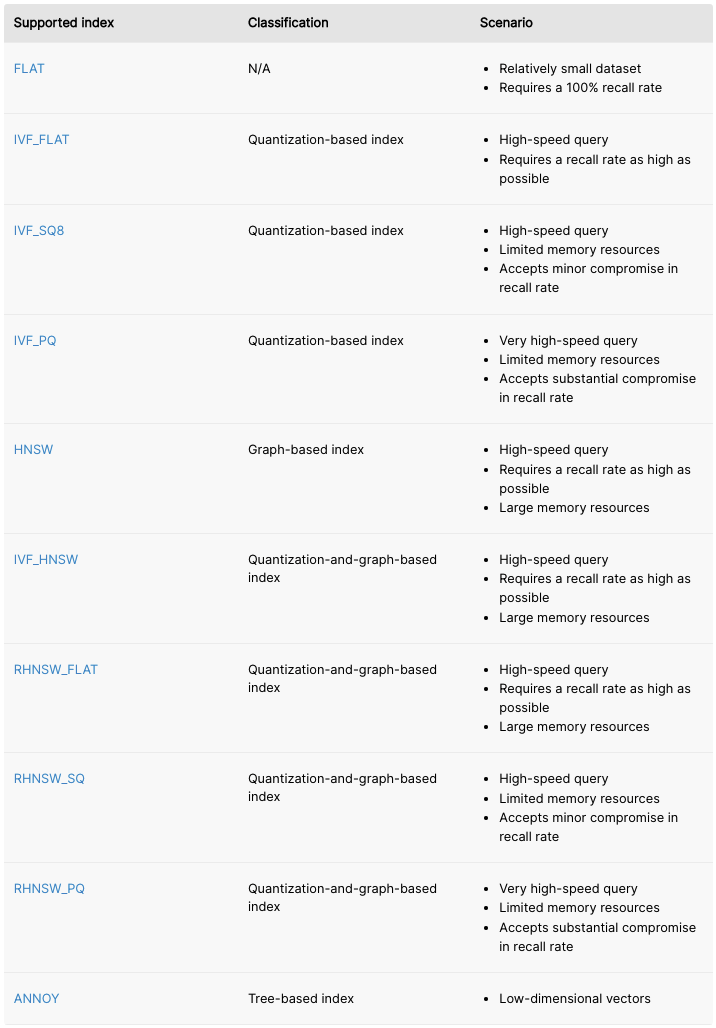 Indexes that Milvus supports.
Indexes that Milvus supports.
Several open-source libraries provide implementations of the various ANN indexes described above. Most libraries are limited to either running only on a single machine or implementing only a single ANN index. To truly execute a production-scale vector similarity search application, we need a robust vector search database that also provides a choice to select whichever ANN index best suits our needs. Milvus is such a database!
Milvus
Milvus is an open-source vector database built for scalable similarity search. From a Data Scientist point of view, Milvus provides some attractive benefits such as:
- Milvus is straightforward to install either locally or on a cluster in the cloud.
- Milvus provides ten of the most popular ANN indices, including FAISS indices, HNSW, ANNOY, etc.
- Milvus also provides seven types of similarity metrics, including IP, L2, Hamming, etc.
- Store scalar data and perform a hybrid search by combining scalar filtering with vector similarity search.
- High-level SDKs in Python, Java, Go, and Node.js
- Interactive GUI client called Attu
- Its similarity search is blazing fast for vectors from deep learning models!
For a more detailed understanding of Milvus and its architecture, please take a look at the Milvus overview documentation. Let's proceed to implement a text-to-image similarity search application using Milvus.
Setup the environment and download some data
In my previous post, I introduced how we can use OpenAI's CLIP (Contrastive Language-Image Pre-Training) to generate embeddings for Image-to-Text and Text-to-Image multimodal search. In other words, given a search text query, we can directly find top images that match this text query by embedding both the images and the text into the same vector space. This post will implement a text-to-image similarity search application containing a large dataset of 100K images. One great thing about Milvus is that we can use the same procedure to scale this application to hundreds of millions or even billions of images!
Setup the Environment
First, we need to load some image data to test the Milvus setup. For this post, let's use the H&M Personalized Fashion Recommendations competitions dataset. from Kaggle. The dataset contains images of more than 100K e-commerce products, perfect for testing a text-to-image product search service. Similar to my previous post, we'll be using Anaconda to manage a virtual environment for this project. The below code assumes you've already done the Kaggle environment setup mentioned in this blog about embedding generation. If you haven't done so, please head over to that post and set it up before proceeding.
# Create the necessary directories
mkdir -p milvus_image_search/notebooks milvus_image_search/data milvus_image_search/milvus
# CD into the data directory
cd milvus_image_search/data
# Create and activate a conda environment
conda create -n image_sim python=3.8 -y
conda activate image_sim
## Create Virtual Environment using venv if not using conda
# python -m venv image_sim
# source image_sim/bin/activate
# Pip install the necessary libraries
pip install jupyterlab kaggle matplotlib scikit-learn tqdm ipywidgets
pip install pandas==1.3.5 pymilvus==2.0.0
pip install sentence_transformers ftfy
# Download data using the kaggle API
kaggle competitions download -c h-and-m-personalized-fashion-recommendations
# Unzip the data into the local directory
unzip h-and-m-personalized-fashion-recommendations.zip
# Delete the Zip file
rm h-and-m-personalized-fashion-recommendations.zip
Read data into Python
Let's create a new jupyter notebook in the milvus_image_search/notebooks directory to generate embeddings and upload them to Milvus. First, let's import the necessary libraries.
from matplotlib import pyplot as plt
import pandas as pd
from pathlib import Path
from PIL import Image
from sklearn.preprocessing import normalize
import time
from tqdm import tqdm
The downloaded images are present in several sub-folders. Let's find out the paths for all of the images and store these paths with the corresponding product article_id in a pandas dataframe. We can see 105K image paths in this dataset from the shape!
# Path to all the downloaded images
img_path = Path('../data/images')
# Find list of all files in the path
images = [path for path in img_path.glob('**/*.jpg')]
# Load the file names to a dataframe
image_df = pd.DataFrame(images, columns=['img_path'])
image_df['article_id'] = image_df['img_path'].apply(lambda x: int(x.stem))
print(image_df.shape)
image_df.head()
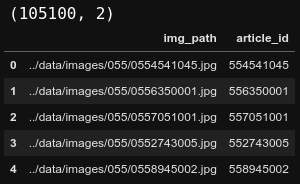 105K image paths in the dataset.
105K image paths in the dataset.
Next, as shown below, let’s map the product article_id to its img_path and prod_name in a Python dictionary. This product_mapping dictionary will come in handy when we visualize our search results later.
# Create a product mapping dict with product names
articles_df = pd.read_csv('../data/articles.csv')
product_mapping = image_df.merge(articles_df[['article_id', 'prod_name']],
on='article_id')
product_mapping = product_mapping.set_index('article_id')
product_mapping = product_mapping.to_dict(orient='index')
print(product_mapping[554541045])
 Product mapping.
Product mapping.
With that, we have everything we need to start working with Milvus.
Implementing a text-to-image similarity search application using Milvus
The general developmental workflow while using Milvus is as follows.
- Start the Milvus Server from a terminal
- Create a Milvus Collection
- Generate Embeddings in batches and upload them to the Milvus collection
- Create an ANN index on the uploaded data
- Run your queries!
Let's take a look at these steps in more detail.
Start the Milvus Server from a terminal.
We'll use the Milvus Standalone for this post since we're only running Milvus on our local machine. Installing Milvus is a breeze using Docker, so we'll first need to install the following:
- Install Docker following instructions from the official docker website
- Install Docker Compose following instructions from the official docker-compose page
Now that we have installed Docker, installing and starting the Milvus standalone server is as simple as downloading a docker-compose.yml and starting up the docker container as shown in the code snippet below. The usage of docker-compose makes the whole process super simple and efficient! The milvus.io website provides many other options to install both Milvus standalone and Milvus Cluster; please check it out if you need to install on a Kubernetes cluster, or install offline, etc.
# CD into the milvus directory
cd ../milvus
# Download the docker-compose.yml
wget https://github.com/milvus-io/milvus/releases/download/v2.0.0/milvus-standalone-docker-compose.yml -O docker-compose.yml
# Start the milvus standalone server
sudo docker-compose up -d
Create a Milvus Collection
Now that we have the Milvus server running on our local machine, we can interact with it using the pymilvus library. First, let's import the necessary modules and connect the session to the Milvus server running on localhost. Feel free to change the alias and collection_name parameters. The model we use to convert our images and text to embeddings determines the emb_dim parameter’s value. In the case of CLIP, the embeddings are 512d.
# Make sure a Milvus server is already running
from pymilvus import connections, utility
from pymilvus import Collection, CollectionSchema, FieldSchema, DataType
# Connect to Milvus server
connections.connect(alias='default', host='localhost', port='19530')
# Collection name
collection_name = 'hnm_fashion_images'
# Embedding size
emb_dim = 512
## Check for existing collection and drop if exists
# if utility.has_collection(collection_name):
# print(utility.list_collections())
# utility.drop_collection(collection_name)
Optionally, you can check if the collection specified by collection_name is already present in your Milvus server. For this example, if the collection is already available, I delete it. But in a production server, you would not do this and would instead skip the collection creation code below.
A Milvus collection is analogous to a table in a traditional database. To create a collection to store data, we first need to specify the collection's schema. In this example, we're only going to keep two fields in the collection. The primary key article_id has INT64 datatype while the img_embedding is a FLOAT_VECTOR field containing the emb_dim dimension embeddings.
# Create a schema for the collection
article_id = FieldSchema(name='article_id', dtype=DataType.INT64, is_primary=True)
img_embedding = FieldSchema(name='img_embedding', dtype=DataType.FLOAT_VECTOR, dim=emb_dim)
# Set the Collection Schema
fields = [article_id, img_embedding]
schema = CollectionSchema(fields=fields, description='H&M Fashion Products')
# Create a collection with the schema
collection = Collection(name=collection_name, schema=schema, using='default', shards_num=10)
Once a collection has been created, we are now ready to upload our vector and scalar data.
Generate Embeddings in batches and upload them to the Milvus collection
As mentioned previously, we'll use OpenAI's CLIP (Contrastive Language-Image Pre-Training) to generate embeddings for Text-to-Image multimodal search. First, let's import the necessary library and instantiate the pre-trained CLIP model.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('clip-ViT-B-32')
Next, let's loop over the image paths in our dataframe in batches of 512. We first create variable data with all the article_id for each batch as this is the primary key. Then, we open the images from their paths and embed them using the pre-trained model loaded above. We need to normalize the embeddings to use the IP distance specified in Milvus documentation. Finally, we append the normalized embeddings to the same variable data and insert it into the Milvus collection.
# Generate embeddings for batches of images on each iteration
batch_size = 512
clip_embeddings = []
for idx in tqdm(range(0, len(image_df), batch_size)):
subset_df = image_df.iloc[idx:idx+batch_size]
# Primary Key
data = [subset_df['article_id'].values.tolist()]
# Embedding
## Load the `batch_size` number of images
images = [
Image.open(img_path).convert('RGB')
for img_path in subset_df['img_path']
]
## Generate CLIP embeddings for the loaded images
raw_embeddings = model.encode(images)
## Normalize the embeddings to use IP distance
## https://milvus.io/docs/v2.0.0/metric.md#Inner-product-IP
norm_embeddings = normalize(raw_embeddings, axis=1).tolist()
## Append the embeddings
data.append(norm_embeddings)
clip_embeddings += norm_embeddings
# Insert data to milvus
collection.insert(data)
Optionally, since the embedding generation process is time-consuming, I'm also storing the embeddings into a local pickle file as a backup.
# Save the embeddings to a file
image_df['clip_embeddings'] = clip_embeddings
image_df.to_pickle('../data/image_embeddings_df.pkl')
Create an ANN index on the uploaded data
After we insert all the embeddings into Milvus, we need to create an ANN index to speed up the search. In this example, I'm using the FAISS IVF_PQ index type, one of the most scalable ANN indexes for enormous data sizes. For more information on the IVF_PQ index and its parameters, take a look at the Milvus documentation.
# Add an ANN index to the collection
index_params = {
"metric_type":"IP",
"index_type":"IVF_PQ",
"params":{"nlist":1024, "m":8}
}
collection.create_index(field_name='img_embedding', index_params=index_params)
Run your queries!
Finally, the data in our Milvus collection is ready to be queried. First, we need to load the collection into memory to run queries against it.
# Load the collection into memory
collection = Collection(collection_name)
collection.load()
Next, I've created a simple helper function that takes in a query_text, converts it to the CLIP embedding, and normalizes it so we can use IP distance. The function then uses the normalized embedding to execute an ANN search across the Milvus collection. We can control the search quality and speed using the search_params described on the IVF_PQ documentation. Finally, the helper function plots the search results and the time taken.
def query_and_display(query_text, collection, product_mapping, num_results=10):
# Embed the Query Text
raw_embeddings = [model.encode(query_text)]
## Normalize the embeddings to use Cosine Similarity
## https://milvus.io/docs/v2.0.0/metric.md#Inner-product-IP
query_emb = normalize(raw_embeddings, axis=1).tolist()
# Search Params
search_params = {"metric_type": "IP", "params": {"nprobe": 20}}
# Text to Image Milvus ANN Search
query_start = time.time()
results = collection.search(data=query_emb,
anns_field='img_embedding',
param=search_params,
limit=num_results,
expr=None)
query_end = time.time()
# Convert search results to products
result_products = [product_mapping[item] for item in results[0].ids]
result_similarities = results[0].distances
# Plot search results
ncols = 5
nrows = -(-len(result_products)//ncols)
fig = plt.figure(figsize=(20,5*nrows))
plt.suptitle('Search results')
for idx, product in enumerate(result_products):
plt.subplot(nrows, ncols, idx+1)
img = Image.open(product['img_path']).convert('RGB')
plt.imshow(img)
plt.title(f'Product Name: {product["prod_name"]}\nCosine Similarity:{result_similarities[idx]:.3f}')
plt.suptitle(f'Query Text: {query_text}. Query returned in {(query_end-query_start):.3f} seconds')
plt.tight_layout()
To run a Text-to-Image search against the 105K images stored in our Milvus collection, we can now use the helper function with just one line of code. To demonstrate the capability of CLIP embeddings on Milvus, in the below example, I'm searching for the term floral top. The top 10 products returned are all quite relevant to my search query as they are tops with a floral pattern! It's even more impressive that the entire search took only 13ms, which is well within typical usage requirements for most applications!
# Query for products that match "floral top" search term
query_and_display('floral top', collection, product_mapping, num_results=10)
 Image by Author using images from the H&M Personalized Fashion Recommendations competitions dataset from Kaggle licensed under Non-Commercial Purposes & Academic Research license.
Image by Author using images from the H&M Personalized Fashion Recommendations competitions dataset from Kaggle licensed under Non-Commercial Purposes & Academic Research license.
If we do not need to run any more queries, we can release the collection to free up our machine's memory. Releasing a collection from memory does not cause data loss as it is still stored on our disk and can be loaded again when needed.
# Release the collection from memory when it's not needed anymore
collection.release()
If you want to stop the Milvus server and delete all the data from the disk, you can follow the instructions from the stop-milvus documentation. Beware! This operation is irreversible, and it will delete all the data in your Milvus cluster.
Conclusion
In this post, we implemented an ultra-scalable Text-to-Image e-commerce product search service using CLIP embeddings and Milvus in a few easy steps. This approach is scalable in production to hundreds of millions or even billions of vectors. We tested the search using a sample text query that returned the top 10 results in just 13ms! Milvus' reputation as a highly scalable and blazing fast vector search database is well deserved!
For more inspiration on Milvus' applications in reverse image search, please head over to Milvus demos and Milvus bootcamp.

- Introduction
- Considerations for production-scale vector similarity search
- Setup the environment and download some data
- Implementing a text-to-image similarity search application using Milvus
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Proximity Graph-based Approximate Nearest Neighbor Search

Building Interactive AI Chatbots with Vector Databases
Vector database-powered AI chatbots deliver personalized, context-aware interactions, optimizing user experience through advanced NLP and tech integration.

Applying Vector Databases in Finance for Risk and Fraud Analysis
How to use the Milvus Vector Database in Finance