




An Intelligent Similarity Search System for Graphical Designers
Learn how to use a vector database to build your own similarity search system for design assets that could help designers ramp up their creative production.
Read the entire series
- Image-based Trademark Similarity Search System: A Smarter Solution to IP Protection
- HM-ANN Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory
- How to Make Your Wardrobe Sustainable with Vector Similarity Search
- Proximity Graph-based Approximate Nearest Neighbor Search
- How to Make Online Shopping More Intelligent with Image Similarity Search?
- An Intelligent Similarity Search System for Graphical Designers
- How to Best Fit Filtering into Vector Similarity Search?
- Building an Intelligent Video Deduplication System Powered by Vector Similarity Search
- Powering Semantic Similarity Search in Computer Vision with State of the Art Embeddings
- Supercharged Semantic Similarity Search in Production
- Accelerating Similarity Search on Really Big Data with Vector Indexing (Part II)
- Understanding Neural Network Embeddings
- Making Machine Learning More Accessible for Application Developers
- Building Interactive AI Chatbots with Vector Databases
- The 2024 Playbook: Top Use Cases for Vector Search
- Leveraging Vector Databases for Enhanced Competitive Intelligence
- Revolutionizing IoT Analytics and Device Data with Vector Databases
- Everything You Need to Know About Recommendation Systems and Using Them with Vector Database Technology
- Building Scalable AI with Vector Databases: A 2024 Strategy
- Enhancing App Functionality: Optimizing Search with Vector Databases
- Applying Vector Databases in Finance for Risk and Fraud Analysis
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
- Safeguarding Data: Security and Privacy in Vector Database Systems
- Integrating Vector Databases with Existing IT Infrastructure
- Transforming Healthcare: The Role of Vector Databases in Patient Care
- Creating Personalized User Experiences through Vector Databases
- The Role of Vector Databases in Predictive Analytics
- Unlocking Content Discovery Potential with Vector Databases
- Leveraging Vector Databases for Next-Level E-Commerce Personalization
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
This article is transcreated by Angela Ni.
Graphical designers usually need to innovatively create all kinds of visual assets, including advertisement posters, promotional videos, and brochures, for printed or electronic media. More often than not, graphical designers have to assemble trendy visual elements and even texts together to make attractive images or videos. Looking for similar visual assets might be a good source of inspiration for designers.
Inspired by many image and video similarity search systems, we can also build an integrated similarity search system for all design assets to bring more innovative ideas to graphical designers. This type of similarity search system is a central hub that collects all design assets, including images, video clips, and texts. If the designer uploads an image to the system, the system will return several similar images or video clips or texts. Then the designer can leverage the assets to enrich his own creation.
System Implementation
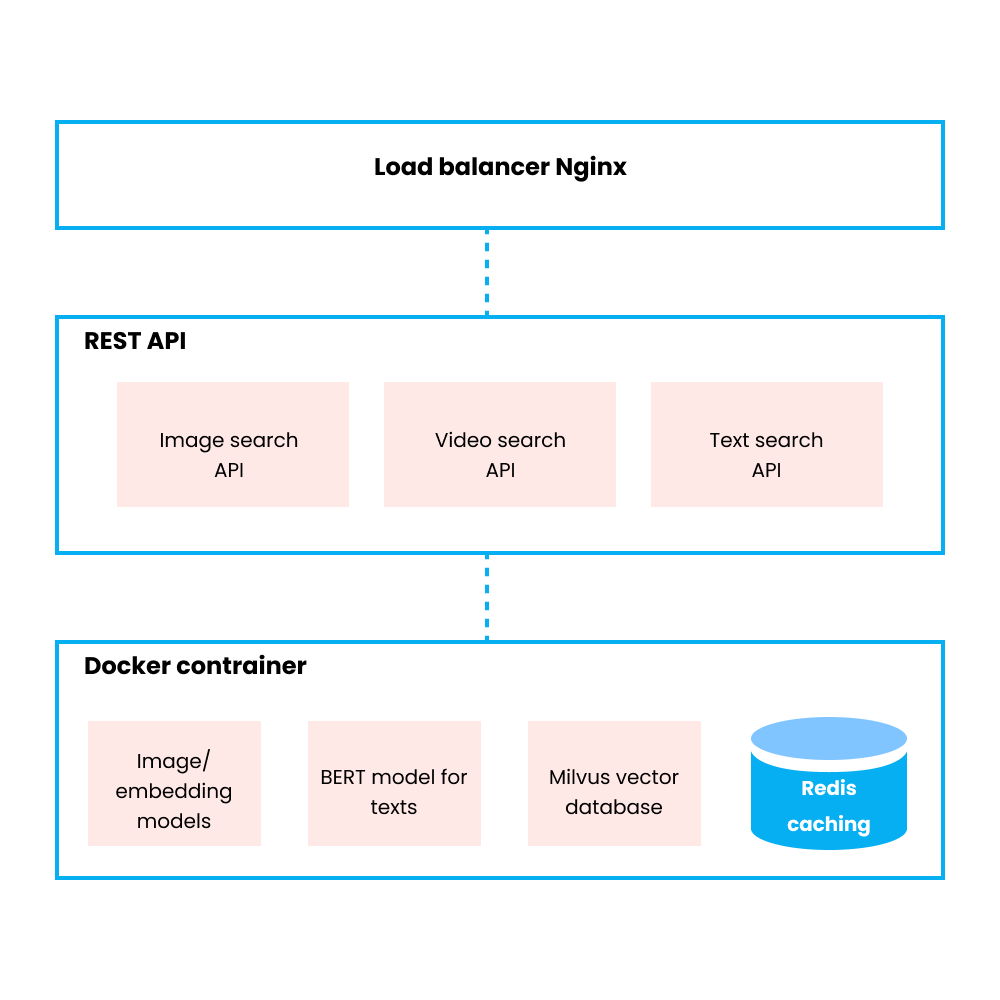 System architecture.
System architecture.
The diagram above is an illustration of the architecture of a similarity search system for graphical design. In the bottom layer, we use certain AI models to convert images, videos, and texts into vectors. Alternatively, we can also use Towhee, an open-source machine learning pipeline that helps you encode your unstructured data into embeddings. Then Milvus, the open-source vector database is adopted for vector management and vector similarity search. In addition, Redis caching layer is introduced here to store the corresponding information of the images and videos. These pieces of information are stored in Redis in the form of KVs (key-value) for the sake of accelerated information retrieval speed.
In terms of the web application service, we used Nginx, Flask, Gunicorn, and supervisor, considering that most of the users are proficient in the Python language.
Choosing the right index
In this article, we decided to choose the index type IVF_PQ, as it guarantees high-speed query under limited resources. PQ (Product Quantization) uniformly decomposes the original high-dimensional vector space into Cartesian products of m low-dimensional vector spaces, and then quantizes the decomposed low-dimensional vector spaces. Instead of calculating the distances between the target vector and the center of all the units, product quantization enables the calculation of distances between the target vector and the clustering center of each low-dimensional space and greatly reduces the time complexity and space complexity of the algorithm.
IVF_PQ performs IVF index clustering before quantizing the product of vectors. Its index file is even smaller than IVF_SQ8. The downside is the recall is correspondingly compromised.
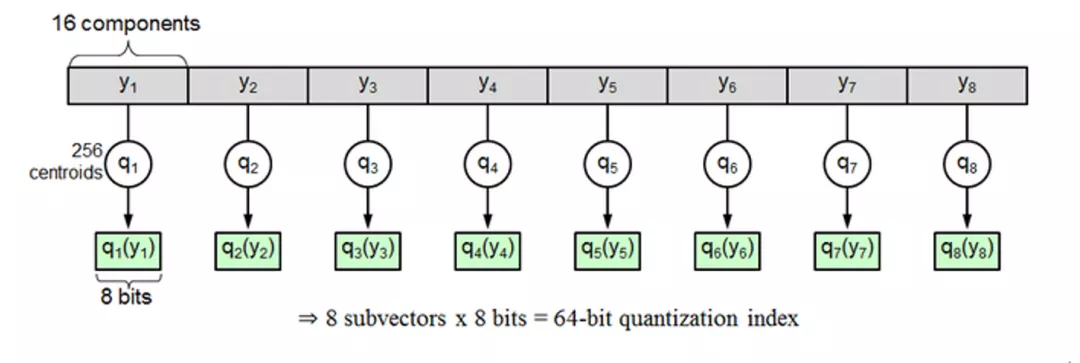 IVF_PQ index.
IVF_PQ index.
According to the Milvus doc,
- A = The computation of a single segment, which equals
target vector amount* (nlist+ (vector amount in the segment) /nlist) *nprobe). - B= The number of segments, which equals the
total data volume/index_file_size. - The computation of querying collections equals A * B.
Therefore, for this particular case in this article, the proper value for index parameters are
nlist=1024,m=8.
Using partitions to accelerate vector similarity search
To greatly improve search efficiency, partitions are necessary. The vector data are inserted into different partitions based on the Cartesian product value of their features.
For instance, the corresponding item of a vector has two features. Based on feature A, we divide the dataset into A1, A2, A3, A4. Based on feature B, we divide the dataset into B1, B2, B3. Then we create 12 partitions and name them A1_B1, A1_B2, A1_B3, A2_B1, A2_B2, A2_B3, ......, A4_B3, A4_B3. Each partition has no more than five million vectors, which is conducive to enhancing search performance.
Notably, the feature upon which we create partitions should not be something that changes easily. If not so, we will have to recreate partitions, reimport data, and rebuild indexes, complicating the whole process. Also, creating too many partitions based on too many features should be avoided. Or else, the Cartesian product generated by multiplying the value of each feature will be extremely bulky. As an alternative to filtering, you can leverage the function of hybrid search in Milvus.
Vector similarity search powered by Milvus
Since we expect the search results to be returned in real time, the system needs to be able to cope with high concurrency. Therefore, we decided to use Milvus, the open-source vector database, to power vector similarity search. With its out-of-the-box features, Milvus is easy to use. It also supports trade-off between search accuracy, and resource consumption by configuring the system parameters.
In addition, Milvus supports multiple data types, including vector, Int, Bool, float, and more. With Milvus, you can even conduct hybrid search - searching for similar assets while filtering the search results with certain conditions.
Performance
After testing, the performance of the similarity search system is as follows.
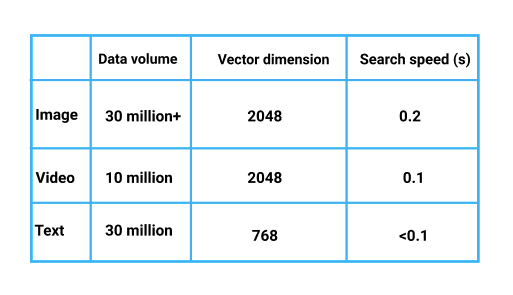 Performance
Performance
Looking for more resources?
- Application of vector similarity search in more industries:

- System Implementation
- Vector similarity search powered by Milvus
- Performance
- Looking for more resources?
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Supercharged Semantic Similarity Search in Production

Leveraging Vector Databases for Enhanced Competitive Intelligence
Vector databases emerge as a potent infrastructure solution for creating highly efficient competitive intelligence (CI) tools.

Leveraging Vector Databases for Next-Level E-Commerce Personalization
Explore the concepts of vector embeddings and vector databases and their role in improving the user experience in e-commerce.