




How to Make Your Wardrobe Sustainable with Vector Similarity Search
Learn how to use a vector database to build an intelligent outfit recommendation app that can search for similar garments.
Read the entire series
- Image-based Trademark Similarity Search System: A Smarter Solution to IP Protection
- HM-ANN Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory
- How to Make Your Wardrobe Sustainable with Vector Similarity Search
- Proximity Graph-based Approximate Nearest Neighbor Search
- How to Make Online Shopping More Intelligent with Image Similarity Search?
- An Intelligent Similarity Search System for Graphical Designers
- How to Best Fit Filtering into Vector Similarity Search?
- Building an Intelligent Video Deduplication System Powered by Vector Similarity Search
- Powering Semantic Similarity Search in Computer Vision with State of the Art Embeddings
- Supercharged Semantic Similarity Search in Production
- Accelerating Similarity Search on Really Big Data with Vector Indexing (Part II)
- Understanding Neural Network Embeddings
- Making Machine Learning More Accessible for Application Developers
- Building Interactive AI Chatbots with Vector Databases
- The 2024 Playbook: Top Use Cases for Vector Search
- Leveraging Vector Databases for Enhanced Competitive Intelligence
- Revolutionizing IoT Analytics and Device Data with Vector Databases
- Everything You Need to Know About Recommendation Systems and Using Them with Vector Database Technology
- Building Scalable AI with Vector Databases: A 2024 Strategy
- Enhancing App Functionality: Optimizing Search with Vector Databases
- Applying Vector Databases in Finance for Risk and Fraud Analysis
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
- Safeguarding Data: Security and Privacy in Vector Database Systems
- Integrating Vector Databases with Existing IT Infrastructure
- Transforming Healthcare: The Role of Vector Databases in Patient Care
- Creating Personalized User Experiences through Vector Databases
- The Role of Vector Databases in Predictive Analytics
- Unlocking Content Discovery Potential with Vector Databases
- Leveraging Vector Databases for Next-Level E-Commerce Personalization
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
This article is transcreated by Angela Ni.
When talking about fashion, people might immediately think of all those glamorous models walking on the runway wearing dashing haute-couture. Or they might think of those key influencers on social media posting different garments and tagging #ootd (outfit of the day) every day. But what about fashion and its impact on the environment? Nonetheless, the mindblowing fact is that the fashion industry actually contributes to a carbon footprint bigger than even the airline industry. It is reported that H&M sells as many as three billion pieces of clothing per year. Therefore, in order to save the planet, the British Fashion Council argues that "consumers should buy half as many clothes and retailers should offer in-store repairing services to combat fashion industry’s impact on the climate".
However, buying fewer garments does not necessarily mean turning away from being fashionable. Actually, by using an intelligent outfit planning app, consumers can still draw new aspirations for clothes matching solutions and discover new styles. They will still be able to come up with various styles by mixing and matching limited garments.
An intelligent outfit planning app, like Stylepedia, is a wardrobe app that helps users discover new styles. Its key features include the ability to curate a digital closet, personalized style recommendations, all powered by a reverse image search system.
This article serves as a tutorial on building an intelligent outfit planning app using a vector database for vector similarity search and data management.
System overview
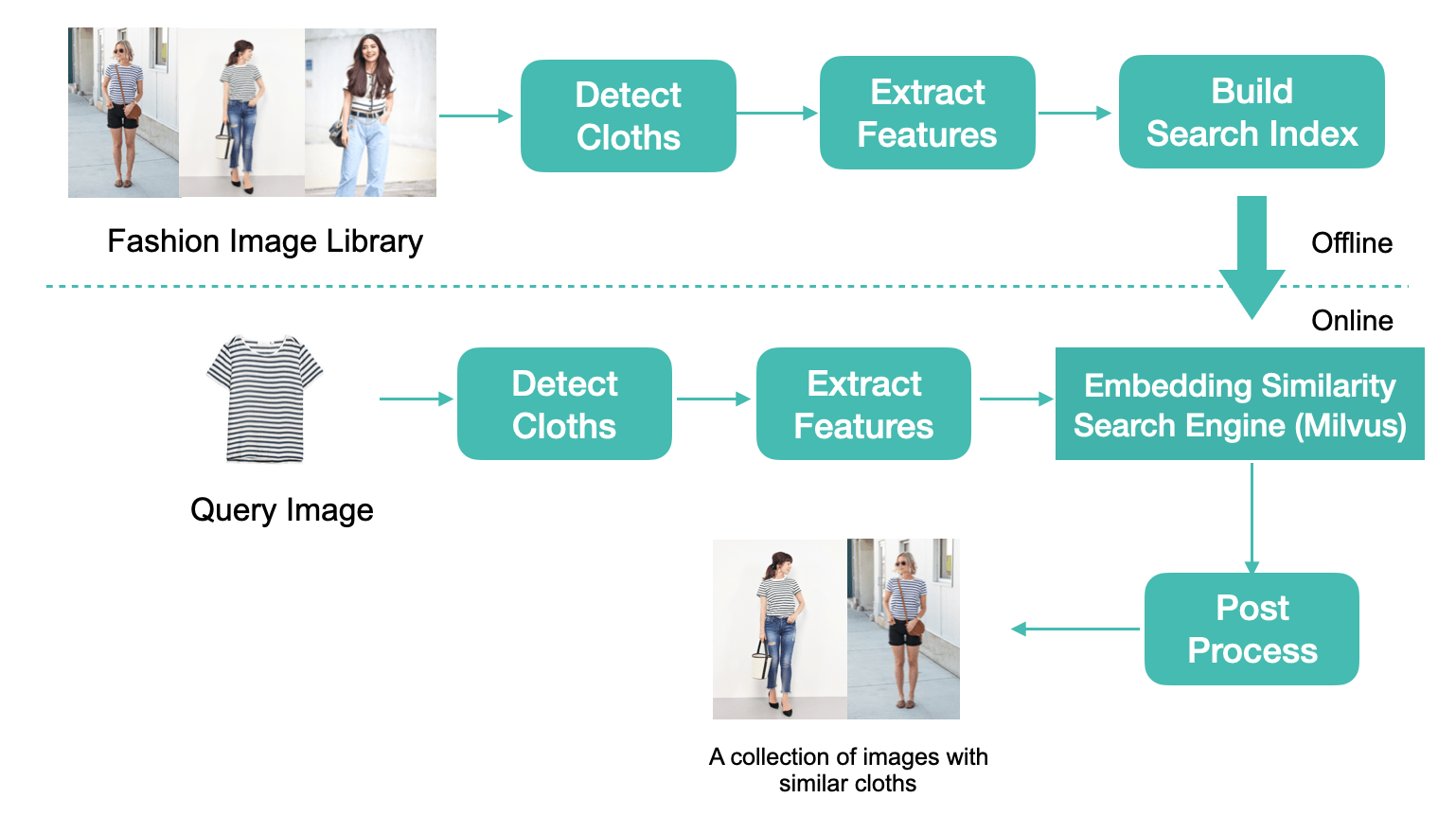 System process diagram.
System process diagram.
The reverse image search system is divided into offline and online components.
Offline, images are vectorized and inserted into a vector database. In the data workflow, fashion photographs are converted into 512-dimensional feature vectors using object detection and feature extraction models. The vector data is then indexed and added to the vector database.
Online, the image database is queried and similar images are returned to the user. Similar to the offline component, a query image is processed by object detection and feature extraction models to obtain a feature vector. Using the feature vector, the vector database searches for TopK similar vectors and obtains their corresponding image IDs. Finally, after post-processing (filtering, sorting, etc.), a collection of fashion photographs similar to the query image are returned.
The following sections are detailed explanations of the system workflow.
Implementation
The implementation breaks down into four modules:
- Garment detection
- Feature extraction
- Vector similarity search
- Post-processing
Garment detection
In the garment detection module, YOLOv5, a one-stage, anchor-based target detection framework, is used as the object detection model for its small size and real-time inference. It offers four model sizes (YOLOv5s/m/l/x), and each specific size has pros and cons. The larger models will perform better (higher precision) but require a lot more computing power and run slower. Because the objects in this case are relatively large items and easy to detect, the smallest model, YOLOv5s, suffices.
Clothing items in each image are recognized and cropped out to serve as the feature extraction model inputs used in subsequent processing. Simultaneously, the object detection model also predicts the garment classification according to predefined classes (tops, outerwear, trousers, skirts, dresses, and rompers).
Feature extraction
The key to similarity search is the feature extraction model. Cropped clothes images are embedded into 512-dimensional floating point vectors that represent their attributes in a machine readable numeric data format. The deep metric learning (DML) methodology is adopted with EfficientNet as the backbone model.
Metric learning aims to train a CNN-based nonlinear feature extraction module (or an encoder) to reduce the distance between the feature vectors corresponding to the same class of samples, and increase the distance between the feature vectors corresponding to different classes of samples. In this scenario, the same class of samples refers to the same piece of clothing.
EfficientNet takes into account both speed and precision when uniformly scaling network width, depth, and resolution. EfficientNet-B4 is used as the feature extraction network, and the output of the ultimate fully connected layer is the image features needed to conduct vector similarity search.
Vector similarity search
The app deals with two image types:
- User images
- Fashion photographs.
Each image can include one or more items, which further complicates the process of image similarity search. To be useful, an image search system must be accurate, fast, and stable, features that lay a solid technical foundation for adding new functionality to the app such as outfit suggestions and fashion content recommendations.
Milvus is an open-source vector database that supports create, read, update, and delete (CRUD) operations as well as near real-time search on trillion-byte datasets. In this tutorial, Milvus is used for large-scale vector similarity search because it is highly elastic, stable, reliable, and lightning fast. Milvus extends the capabilities of widely used vector index libraries (Faiss, NMSLIB, Annoy, etc.), and provides a set of simple and intuitive APIs that allow users to select the ideal index type for a given scenario.
In this tutorial, we choose the HNSW index. We can insert vectors of fashion photographs into one collection but divide them into six partitions based on the detection and classification results to narrow the search scope and enhance the efficiency of vector similarity search.
Milvus performs search on tens of millions of vectors in milliseconds, providing optimal performance while keeping development costs low and minimizing resource consumption.
Post-processing
To improve the similarity between the image retrieval results and the query image, we use color filtering and key label (sleeve length, clothes length, collar style, etc.) filtering to filter out ineligible images. In addition, an image quality assessment algorithm is used to make sure that higher quality images are presented to users first.
Application
Outfit suggestions for fashion inspiration
By conducting similarity search on the image database, users can find fashion photographs that contain a specific fashion item. These could be something from their own collection that could be worn or paired differently. Then, through the clustering of the items it is often paired with, outfit suggestions are generated. For example, a black biker jacket can go with a variety of items, such as a pair of black skinny jeans. Users can then browse relevant fashion photographs where this match occurs in the selected formula.
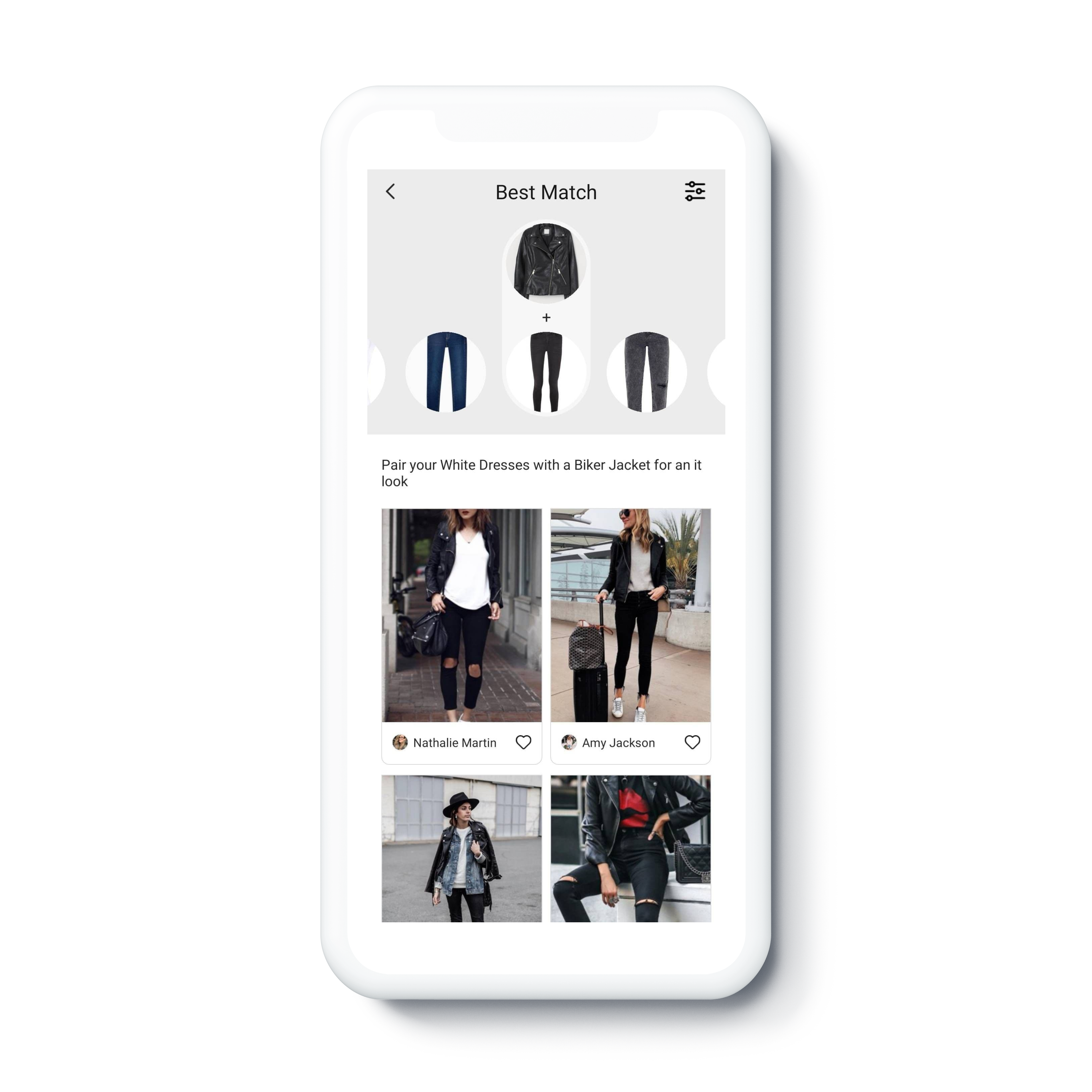 Outfit ideas for a black biker jacket.
Outfit ideas for a black biker jacket.
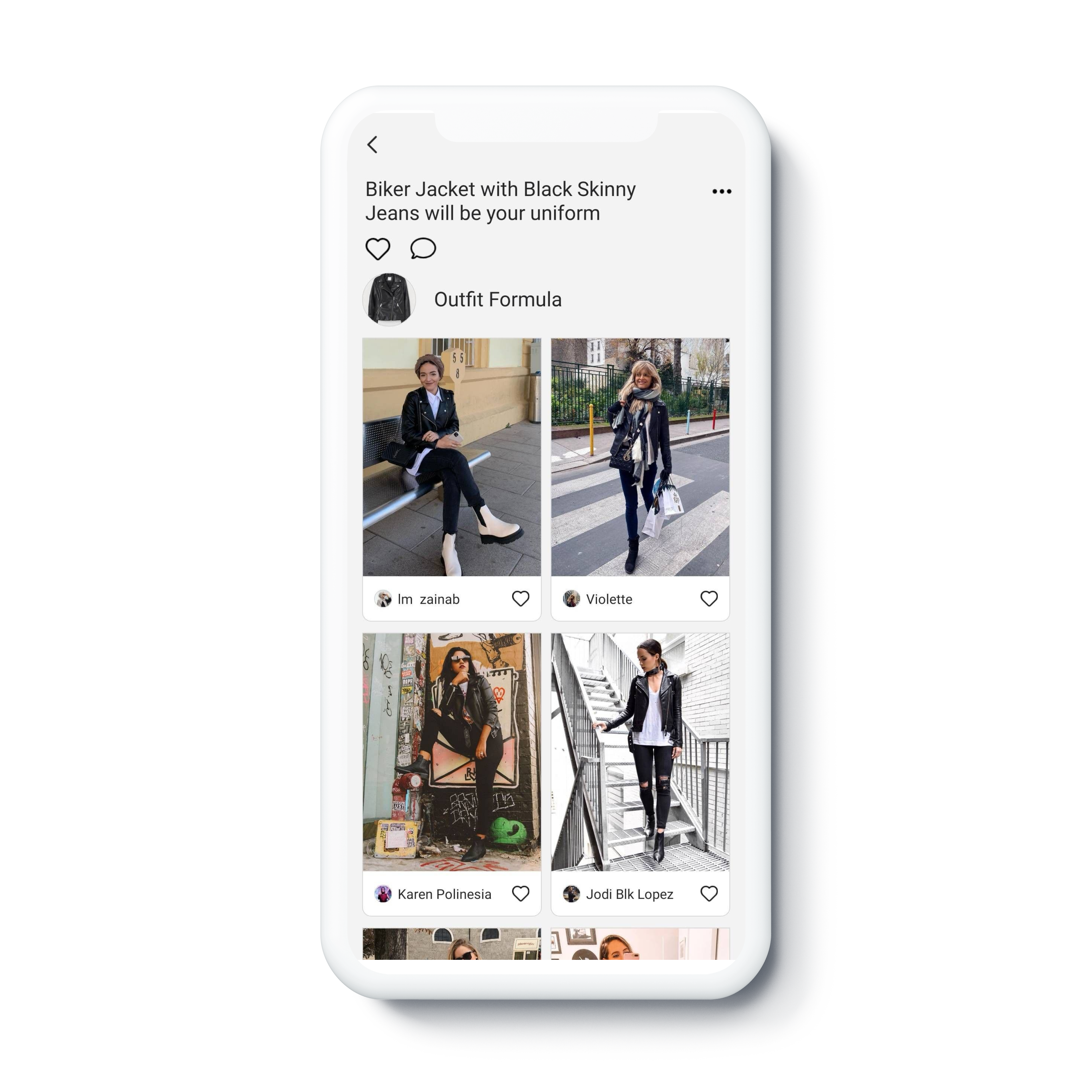 A spread of snapshots featuring a black biker jacket + black skinny jeans match.
A spread of snapshots featuring a black biker jacket + black skinny jeans match.
Fashion photograph recommendations
Based on a user's browsing history, likes, and the contents of their digital closet, the system calculates similarity and provides customized fashion photograph recommendations that may be of interest.
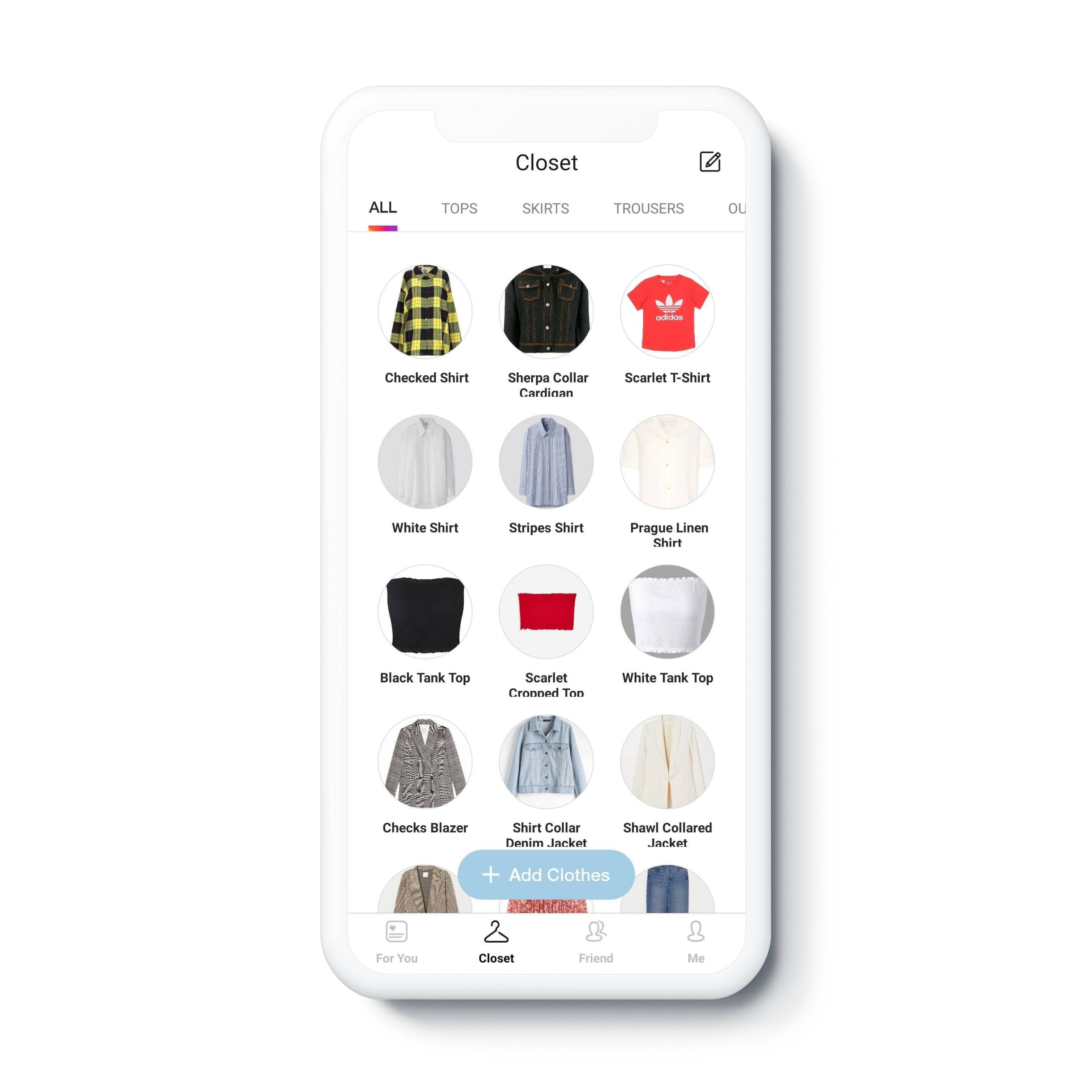 Items in user's digital closet.
Items in user's digital closet.
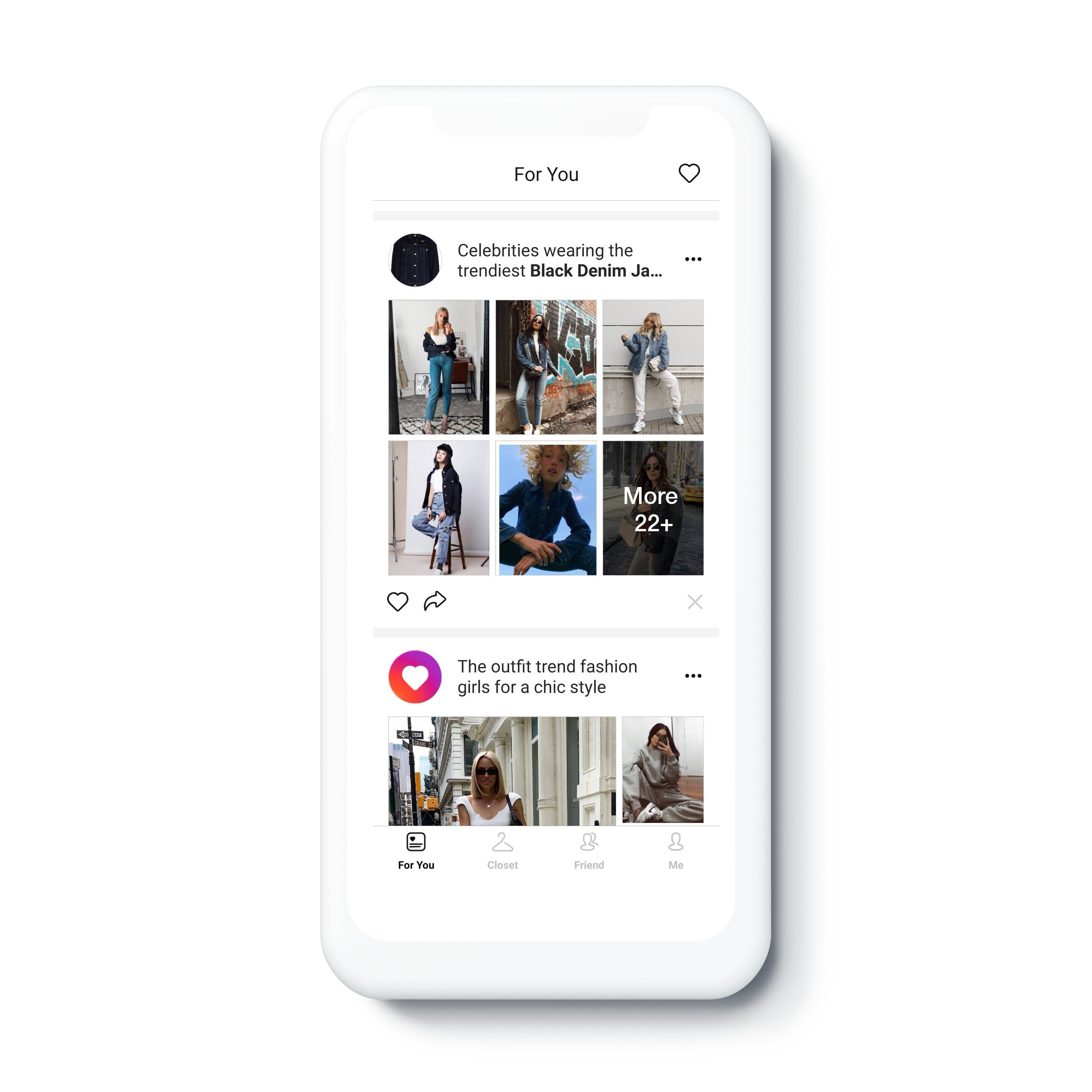 Fashion photograph recommendations that match user preferences and tastes.
Fashion photograph recommendations that match user preferences and tastes.
Looking for more resources?
- Learn about applications of vector similarity search in other industries:

Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Supercharged Semantic Similarity Search in Production

Everything You Need to Know About Recommendation Systems and Using Them with Vector Database Technology
How you can build an AI powered Recommendation System with Vector Search

Integrating Vector Databases with Existing IT Infrastructure
As businesses navigate this dynamic AI landscape, integrating vector databases emerges as a crucial strategy for unlocking the full potential of AI-driven initiatives.