




Making Machine Learning More Accessible for Application Developers
Learn how Towhee, an open-source embedding pipeline, supercharges the app development that requires embeddings and other ML tasks.
Read the entire series
- Image-based Trademark Similarity Search System: A Smarter Solution to IP Protection
- HM-ANN Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory
- How to Make Your Wardrobe Sustainable with Vector Similarity Search
- Proximity Graph-based Approximate Nearest Neighbor Search
- How to Make Online Shopping More Intelligent with Image Similarity Search?
- An Intelligent Similarity Search System for Graphical Designers
- How to Best Fit Filtering into Vector Similarity Search?
- Building an Intelligent Video Deduplication System Powered by Vector Similarity Search
- Powering Semantic Similarity Search in Computer Vision with State of the Art Embeddings
- Supercharged Semantic Similarity Search in Production
- Accelerating Similarity Search on Really Big Data with Vector Indexing (Part II)
- Understanding Neural Network Embeddings
- Making Machine Learning More Accessible for Application Developers
- Building Interactive AI Chatbots with Vector Databases
- The 2024 Playbook: Top Use Cases for Vector Search
- Leveraging Vector Databases for Enhanced Competitive Intelligence
- Revolutionizing IoT Analytics and Device Data with Vector Databases
- Everything You Need to Know About Recommendation Systems and Using Them with Vector Database Technology
- Building Scalable AI with Vector Databases: A 2024 Strategy
- Enhancing App Functionality: Optimizing Search with Vector Databases
- Applying Vector Databases in Finance for Risk and Fraud Analysis
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
- Safeguarding Data: Security and Privacy in Vector Database Systems
- Integrating Vector Databases with Existing IT Infrastructure
- Transforming Healthcare: The Role of Vector Databases in Patient Care
- Creating Personalized User Experiences through Vector Databases
- The Role of Vector Databases in Predictive Analytics
- Unlocking Content Discovery Potential with Vector Databases
- Leveraging Vector Databases for Next-Level E-Commerce Personalization
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
Introduction
Attempts at hand-crafting algorithms for understanding human-generated content have generally been unsuccessful. For example, it is difficult for a computer to “grasp” the semantic content of an image - e.g. a car, cat, coat, etc… - purely by analyzing its low-level pixels. Color histograms and feature detectors worked to a certain extent, but they were rarely accurate enough for most applications.
In the past decade, the combination of big data and deep learning has fundamentally changed the way we approach computer vision, natural language processing, and other machine learning (ML) applications; tasks ranging from spam email detection to realistic text-to-video synthesis have seen incredible strides, with accuracy metrics on certain tasks reaching superhuman levels. A major positive side effect of these improvements is an increase in the use of embedding vectors, i.e. model artifacts generated by taking an intermediate result within a deep neural network. OpenAI’s docs page gives a great overview:
An embedding is a special format of data representation that can be easily utilized by machine learning models and algorithms. The embedding is an information dense representation of the semantic meaning of a piece of text. Each embedding is a vector of floating point numbers, such that the distance between two embeddings in the vector space is correlated with semantic similarity between two inputs in the original format. For example, if two texts are similar, then their vector representations should also be similar.
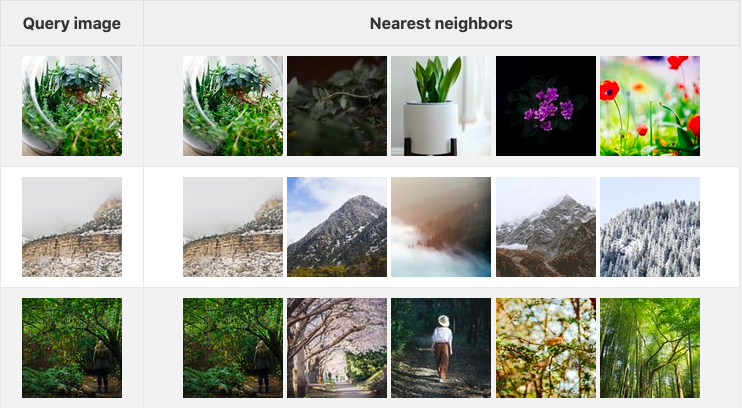
The table below shows three query images along with their corresponding top five images in embedding space (I used the first 1000 images of Unsplash Lite as the dataset):
 2022-04-20-104339.png
2022-04-20-104339.png
These results you see above were generated with an image embedding model based on resnet50, a well-known pure convolutional image classification model. Embeddings are not limited to images - they can also be generated for wide array of different types of unstructured data, including images, audio, time-series data, and molecular structures. Models which embed multiple different types of data into the same space, also more commonly known as multi-modal embedding models, also exist and are being used in an increasingly large number of applications.
As we’ll see in the next two sections, generating these high quality embeddings can be difficult, especially at scale.
Training a new model for embedding tasks
On paper, training a new ML model and generating embeddings with it sounds easy: take the latest and greatest pre-built model [1], backed by the newest architecture, and train it with some data. Easy, right?
Not so fast. On the surface, it may seem easy to use the latest model architecture to achieve state-of-the-art results [2]. This, however, could not be further from the truth. Let’s go over some common pitfalls related to training embedding models (these also apply to general machine learning models):
Not enough data: Training a new embedding model from scratch without enough data makes it prone to a phenomenon called overfitting. In practice, only the largest global organizations have enough data to make training a new model from scratch worthwhile; others must rely on fine-tuning, a process where an already-trained model with large amounts of data is then distilled using a smaller dataset.
Poor hyperparameter selection: Hyperparameters are constants which are used to control the training process, such as how quickly the model learns or how much data is used for training in a single batch. Selecting an appropriate set of hyperparameters is extremely important when fine-tuning a model, as small changes to certain values can result in vastly different results. Recent research in this area has also shown accuracy improvements on ImageNet-1k of over 5% (that’s a lot) training the same model from scratch with an improved training procedure.
Overestimating self-supervised models: The term self-supervision refers to a training procedure where “fundamentals” of the input data are learned by leveraging data itself without the need for labels [3]. In general, self-supervised methods are great for pre-training (i.e. training a model in a self-supervised fashion with lots of unlabelled data before fine-tuning it with a smaller labelled dataset) but directly using self-supervised embeddings can result in suboptimal performance.
A common way for tackling all three of the above problems is to first train a self-supervised model using a massive quantity of data before fine-tuning the model on labelled data. This has been shown to work great for NLP, but not so much for CV just yet.
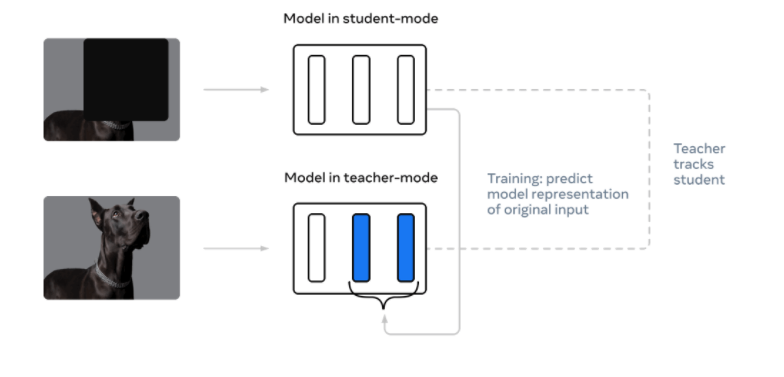 An illustration of Meta's data2vec training technique, a self-supervised method for training deep neural networks across a variety of unstructured data types. Source: Meta AI blog.
An illustration of Meta's data2vec training technique, a self-supervised method for training deep neural networks across a variety of unstructured data types. Source: Meta AI blog.
Using embedding models has its own pitfalls
These are just some of the many common mistakes associated with training embedding models. As a direct result of this, many developers looking to use embeddings make direct use of pre-trained models on academic datasets such as ImageNet (for image classification) and SQuAD (for question answering). Despite the abundance of pre-trained models available today, there are several pitfalls which should be avoided in order to extract maximum embedding performance:
Training and inference data mismatch: Using an off-the-shelf model trained by other organizations has become a popular way to develop ML applications without needing thousands of GPU/TPU-hours. Understanding the limitations of a particular embedding model and how that can impact application performance is extremely important; without understanding the model’s training data and methodology, it’s incredibly easy to misinterpret results. For example, a model trained to embed music will work poorly when applied to speech and vice versa.
Improper layer selection: When using a fully-supervised neural network as an embedding model, features are generally taken from the second-to-last layer (known formally as the penultimate layer) of activations. However, this can result in suboptimal performance, depending on the application. For example, when using a model trained for image classification to embed images of logos and/or brands, using earlier activations may result in improved performance. This is due to better retention of low-level features (edges and corners) which are critical to classifying non-complex images.
Nonidentical inference conditions: Train and inference conditions must be exactly the same to extract maximum performance out of an embedding model. In practice, this is often times not the case. A standard
resnet50model fromtorchvision, for example, generates two completely different results when downsampled using bicubic interpolation versus nearest neighbor interpolation (see below).
 An Eastern Towhee. Photo by Patrice Bouchard.
An Eastern Towhee. Photo by Patrice Bouchard.
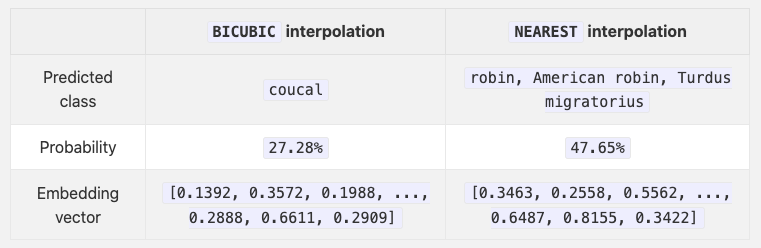 Table 1.
Table 1.
Deploying an embedding model
Once you’ve jumped through all of the hurdles associated with training and validating a model, scaling and deploying it becomes the next critical step. Again, embedding model deployment is easier said than done. MLOps, a field adjacent to DevOps, exists specifically for this purpose.
Selecting the right hardware: Embedding models, analogous to most other ML models, can be run on a variety of different types of hardware, ranging from standard everyday CPUs to programmable logic (FPGAs). Entire research papers have been written analyzing the tradeoffs in terms of cost versus efficiency, highlighting the difficulty most organizations face here.
Model deployment platform: There are numerous MLOps and distributed computing platforms available (including many open-source ones). Figuring out how these will fit into your application can be a challenge in and of itself.
Storage for embedding vectors: As your application scales, you’ll need to find a scalable and more permanent storage solution for your embedding vectors. This is where vector databases comes in.
I’ll learn how to do it myself!
I applaud your enthusiasm! A couple of key things to remember:
ML is very different from software engineering: Traditional machine learning derives its roots from statistics, a branch of mathematics that is very different from software engineering. Important machine learning concepts such as regularization and feature selection all have strong fundamental roots in mathematics. While modern libraries for training and inference (PyTorch and Tensorflow being two well-known ones) have made it significantly easier to train and productionize embedding models, understanding how different hyperparameters and training methodologies affect embedding model performance is still incredibly important.
Learning to use PyTorch or Tensorflow can be unintuitive: As previously mentioned, these libraries have greatly sped up the training, validation, and deployment of modern ML models. Building a new model or implementing an existing one can be very intuitive to seasoned ML developers or programmers who are familiar with HDL, but for most software developers, the underlying concepts can be difficult to grasp. There’s also the question of which framework to choose, as the execution engines used by these two frameworks have quite a few differences (personally, I recommend PyTorch).
Finding an MLOps platform that fits your codebase will take time: Here’s a curated list of MLOps platforms and tools. There’s hundreds of different options to choose from, and evaluating the pros and cons of each is a years-long research project in and of itself.
With all this being said, I’d like to amend my statement above to say: I applaud your enthusiasm, but I don’t recommend learning ML and MLOps. It’s a fairly long and tedious process that can take time away from what’s most important: developing a solid application that your users will love.
Supercharging data science with Towhee
Towhee is an open-source project that helps software engineers develop and deploy applications which utilize embeddings in just a few lines of code [4]. Towhee affords software developers the freedom and flexibility to develop their own ML applications without having to dive deep into embedding models and machine learning.
A quick example
A Pipeline is a single embedding generation task that is composed of several sub-tasks (also known as Operators in Towhee). By abstracting an entire task within a Pipeline, Towhee helps users avoid many of the embedding generating pitfalls mentioned above.
>>> from towhee import pipeline
>>> embedding_pipeline = pipeline('image-embedding-resnet50')
>>> embedding = embedding_pipeline('https://docs.towhee.io/img/logo.png')
In the example above, image decoding, image transformation, feature extraction, and embedding normalization are four substeps compiled into a single pipeline - no need to worry about the model and inference details yourself. Towhee provides pre-built embedding pipelines for a variety of tasks, including audio/music embeddings, image embeddings, face embeddings, and more. For a full list of pipelines, feel free to visit our Towhee hub.
Method-chaining API
Towhee also provides a Pythonic unstructured data processing framework called DataCollection. In short, DataCollection is a method-chaining API which allows developers to rapidly prototype embedding and other ML models on real-world data. In the example below, we use DataCollection compute embeddings using the resnet50 embedding model.
For this example, we’ll build an “application” that let’s us filter prime numbers with a ones digit of 3:
>>> from towhee.functional import DataCollection
>>> def is_prime(x):
... if x <= 1:
... return False
... for i in range(2, int(x/2)+1):
... if not x % i:
... return False
... return True
...
>>> dc = (
... DataCollection.range(100)
... .filter(is_prime) # stage 1, find prime
... .filter(lambda x: x%10 == 3) # stage 2, find primes that ends with '3'
... .map(str) # stage 3, convert to string
... )
...
>>> dc.to_list()
DataCollection can be used to develop entire applications in just a single line of code. The next section shows how to develop a reverse image search application using DataCollection - keep reading ahead to learn more.
Towhee trainer
As mentioned above, fully- or self-supervised trained models are often good at generic tasks. However, you’ll sometimes want to create an embedding model that’s good at something very specific, e.g. differentiating between cats versus dogs. Towhee provides a training/fine-tuning framework specifically for this purpose:
>>> from towhee.trainer.training_config import TrainingConfig
>>> training_config = TrainingConfig(
... batch_size=2,
... epoch_num=2,
... output_dir='quick_start_output'
... )
You’ll also need to specify a dataset to train on:
>>> train_data = dataset('train', size=20, transform=my_data_transformer)
>>> eval_data = dataset('eval', size=10, transform=my_data_transformer)
With everything in place, training a new embedding model from an existing operator is a piece of cake:
>>> op.train(
... training_config,
... train_dataset=train_data,
... eval_dataset=eval_data
... )
Once complete, you can use the same operator in your application with no changes to the rest of the code.
 Above: an attention heatmap showing the core areas of an image that an embedding model tries to encode. We'll be integrating attention heatmaps and other visualization tools directly into our fine-tuning framework in a future version of Towhee.
Above: an attention heatmap showing the core areas of an image that an embedding model tries to encode. We'll be integrating attention heatmaps and other visualization tools directly into our fine-tuning framework in a future version of Towhee.
An example application: reverse image search
To demonstrate how Towhee can be used, let’s quickly build a small reverse image search application. Reverse image search is a well-known. Let’s dive right in:
>>> import towhee
>>> from towhee.functional import DataCollection
For this example application, we’ll be using a small dataset along with 10 query images. Using DataCollection, we can then load both the dataset and query images:
>>> dataset = DataCollection.from_glob('./image_dataset/dataset/*.JPEG').unstream()
>>> query = DataCollection.from_glob('./image_dataset/query/*.JPEG').unstream()
The next step is to compute embeddings over the entire dataset collection:
>>> dc_data = (
... dataset.image_decode.cv2()
... .image_embedding.timm(model_name='resnet50')
... )
...
This step creates a local collection of embedding vectors - one for each image in the dataset. With this, we can now query for nearest neighbors:
>>> result = (
... query.image_decode.cv2() # decode all images in the query set
... .image_embedding.timm(model_name='resnet50') # compute embeddings using the `resnet50` embedding model
... .towhee.search_vectors(data=dc_data, cal='L2', topk=5) # search the dataset
... .map(lambda x: x.ids) # acquire IDs (file paths) of similar results
... .select_from(dataset) # get the result image
... )
...
We also provide a way to deploy your application using Ray. Simply specify query.set_engine('ray') and you’re good to go!
Closing words
One last note: we do not consider Towhee to be a full-fledged, end-to-end model serving or MLOps platform, nor is that what we set out to achieve. Rather, we aim to supercharge the development of applications that require embeddings and other ML tasks. With Towhee, our hope is to enable rapid prototyping of embedding models and pipelines on your local machine (Pipeline + Trainer), allow for development an ML-centric application in just a couple of lines of code (DataCollection), and allow for easy and rapid deployment to your own cluster (via Ray).
We’re constantly looking for for folks to join our open-source community - if this is something that interests you, please consider giving us a star on Github. You can also get in touch with us on Slack and Twitter.
That’s all folks - hope this post was informative. If you have any questions, comments, or concerns, feel free to leave a comment below. Stay tuned for more!
Footnotes
Using image classification as an example, we can see the rapid evolution of convolutional neural networks (CNNs): VGG architectures were deeper and had smaller kernel sizes when compared with AlexNet, ResNets introduced skip connections and batch normalization to facilitate backpropogation on ultra-deep models, and more recent Transformer-CNN hybrid architectures add self-attention to achieve state-of-the-art results.
Transformer-based models require more model- and dataset-specific hyperparameter tuning along with a larger dataset size (and/or more data augmentation) to prevent overfitting. More recent research has also shown that a pure convolutional model utilizing depth-wise convolutions can outperform transformers for vision tasks, but that’s a story for another day.
This is admittedly a gross oversimplification. I’ll elaborate what I mean by “fundamentals” in a future blog post.
Although our initial focus is on generating embeddings, Towhee can also be used to create and share generic machine learning pipelines such as machine translation, object detection, and image-to-image pipelines.
 Frank Liu
Frank LiuFrank Liu is the Director of Operations & ML Architect at Zilliz, where he serves as a maintainer for the Towhee open-source project. Prior to Zilliz, Frank co-founded Orion Innovations, an ML-powered indoor positioning startup based in Shanghai and worked as an ML engineer at Yahoo in San Francisco. In his free time, Frank enjoys playing chess, swimming, and powerlifting. Frank holds MS and BS degrees in Electrical Engineering from Stanford University.
- Introduction
- Training a new model for embedding tasks
- Using embedding models has its own pitfalls
- Deploying an embedding model
- I’ll learn how to do it myself!
- Supercharging data science with Towhee
- An example application: reverse image search
- Closing words
- Footnotes
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

HM-ANN Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory
An introduction to a novel HM-ANN algorithm for graph-based similarity search, which offers distinct advantages over existing ANN search solutions.

Enhancing Customer Experience with Vector Databases: A Strategic Approach
Understand how vector databases process data to enhance customer experience and drive business growth.
