




Using SelfQueryRetriever with LangChain to Query a Vector Database
LangChain is well-known for orchestrating interactions with large language models (LLMs). Recently, LangChain has introduced a way to perform self-querying, allowing them to query the “chain” or modules themselves using a user input query. This post will show you how to self-query on Milvus, the world’s most popular vector database. By interpreting a user query, the system can refine searches within vector stores, enhancing retrieval outcomes. You can find the code for this example on CoLab here.
Let’s set up self-querying on Milvus with LangChain. This process consists of four logical steps.
Set up the basics of LangChain and Milvus.
Obtain or create the necessary data.
Inform the model about the expected data format.
Demonstrate self-querying and explain how it works.
Introduction to Self-Querying
Self-querying is a powerful technique used in natural language processing (NLP) and information retrieval. It allows a system to query itself using a user’s input query, enabling more accurate and relevant results. In the context of LangChain, self-querying is used to retrieve information from a vector store, which is a database that stores vectors representing documents or data points. The self-query retriever is a key component of the LangChain framework, allowing for the creation of complex queries and retrievals using natural language.
By leveraging self-querying, LangChain can break down a user’s query into a structured format that the vector store can understand. This process ensures that the retrieved documents are highly relevant to the user’s query, making it easier to find the information they need. Whether you’re building a conversational AI model or a search engine, self-querying can significantly enhance the accuracy and relevance of your results.
Setting up LangChain and Milvus
The first step is to set up the necessary libraries. You can install the required libraries using pip install openai langchain milvus python-dotenv. If you have followed my previous tutorials, you are already familiar with python-dotenv, my preferred library for handling environment variables. We use the OpenAI library with LangChain to access GPT and utilize Milvus as our vector store.
Once you connect to the OpenAI API key, import the necessary LangChain modules. We need the following six modules:
Document: A LangChain data type for data storage.OpenAIandOpenAIEmbeddings: Two functionalities for accessing OpenAI and its embeddings.Milvus: A module for accessing Milvus from LangChain.SelfQueryRetriever: A retriever module.AttributeInfo: A module defining our data structure to LangChain.
After importing the modules, we set the variable embeddings to the default function of OpenAI Embeddings. The final step in the setup process is to use the milvus library to spin up an instance of Milvus Lite in our notebook.
Now, let's take a look at the data.
import os
from dotenv import load_dotenv
load_dotenv()
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
from langchain.schema import Document
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Milvus
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
embeddings = OpenAIEmbeddings()
from milvus import default_server
default_server.start()
Let's gather some data. You can scrape your data, use the provided data as-is, or use it as a template to create your data. I have prepared a list of documents about movies for this example, including Jurassic Park, Toy Story, Finding Nemo, The Unbearable Weight of Massive Talent, Lord of War, and Ghost Rider. Although I don't include the titles in our data, I want you to know which movies they refer to.
I store each of these movies as a LangChain Document object. It contains a page_content key corresponding to a string, in this case, the movie description. It also includes metadata, such as the year, rating, and movie genre.
docs = [
# jurassic park
Document(page_content="A bunch of scientists bring back dinosaurs and mayhem breaks loose",
metadata={"year": 1993, "rating": 7.7, "genre": "action"}),
# toy story
Document(page_content="Toys come alive and have a blast doing so",
metadata={"year": 1995, "genre": "animated", "rating": 9.3 }),
# finding nemo
Document(page_content="A dad teams up with a mentally disabled partner to break into a dentist\'s office to save his son.",
metadata={"year": 2003, "genre": "animated", "rating": 8.2 }),
# unbearable weight of massive talent
Document(page_content="Nicholas Cage plays Nicholas Cage in this movie about Nicholas Cage.",
metadata={"year": 2022, "genre": "comedy", "rating": 7.0 }),
# lord of war
Document(page_content="Nicholas Cage sells guns until he has enough money to marry his favorite model. Then he sells more guns.",
metadata={"year": 2005, "genre": "comedy", "rating": 7.6 }),
# ghost rider
Document(page_content="Nicholas Cage loses his skin and sets his skull on fire. Then he rides a motorcycle.",
metadata={"year": 2007, "genre": "action", "rating": 5.3 }),
]
Defining self-query metadata and self query retriever for LangChain and Milvus
We have completed the first two steps of the puzzle, and now it's time for the third.
First, let’s set up our vector database for ingestion. We can use the LangChain Milvus implementation to ingest our documents and create a vector database based on our existing documents. This step is also where the embedding function comes into play, using the embeddings variable we previously created. The comparison statement takes into account the specific formats and guidelines necessary for creating filter conditions that guide data retrieval processes.
The connection_args parameter is the only required parameter for connecting to Milvus. In this tutorial, I also use the collection_name parameter to assign a name to the collection where we store our data. Each collection in Milvus must have a name. By default, LangChain uses LangChainCollection.
vector_store = Milvus.from_documents(
docs,
embedding=embeddings,
connection_args={"host": "localhost", "port": default_server.listen_port},
collection_name="movies"
)
Next, let’s define the metadata information using the AttributeInfo functionality so that LangChain knows what to expect. This section will create a list of attribute information for the data. We will specify each attribute’s name, description, and data type. This is where a logical condition statement becomes integral to formulating comparisons and logical operations within the query construction process.
metadata_field_info = [
AttributeInfo(
name="genre",
description="The genre of the movie",
type="string",
),
AttributeInfo(
name="year",
description="The year the movie was released",
type="integer",
),
AttributeInfo(
name="rating",
description="A 1-10 rating for the movie",
type="float"
),
]
The last couple of pieces describe the document, initialize the LLM, and define the Self-Query Retriever. We define the self-query retriever by calling its ‘from_llm’ method. We must use this method to connect the LLM, vector store, document content description, and metadata field information. In this example, we also set ‘verbose = True’ to enable verbose output for this self-query retriever. The query string should only include relevant text matching the document contents, ensuring that any conditions in the filters are distinctly separated and not included in the query string itself.
document_content_description = "Brief summary of a movie"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm, vector_store, document_content_description, metadata_field_info, verbose=True
)
Self-querying results
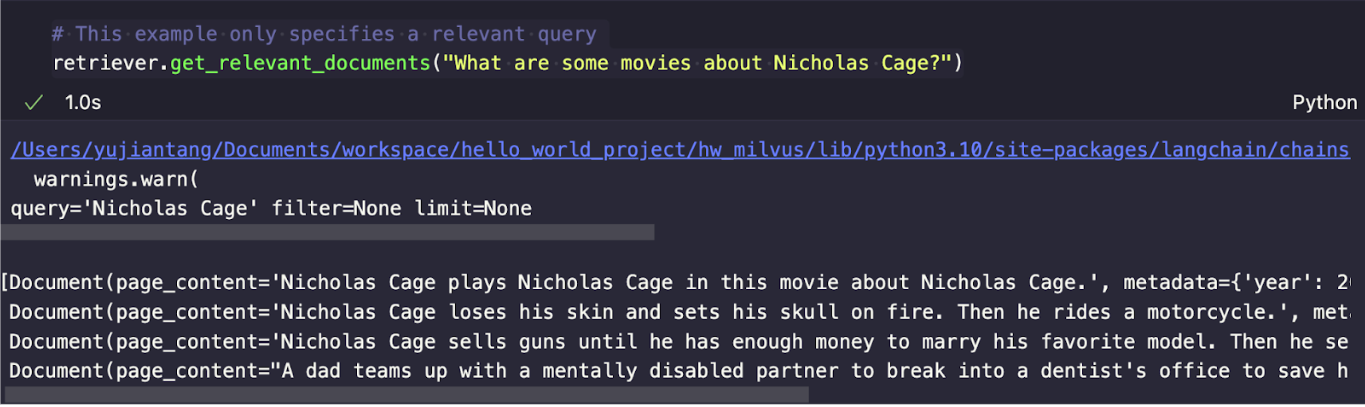
We’ve finished the setup for the self-query retriever. Now, let’s see how it works in action. In this example, I used three movie descriptions related to Nicholas Cage. So, the question we ask is: what are some movies about Nicholas Cage?
# This example only specifies a relevant query
retriever.get_relevant_documents("What are some movies about Nicholas Cage?")
We should get an output like the one below.
 langchain-query-vector-database.png
langchain-query-vector-database.png
By setting verbose=True, we can view the query, filter, and limit. The LLM converts our query from “What are some movies about Nicholas Cage?” to “Nicholas Cage.” Looking at the results, we can observe that the top three results are all movies featuring Nicholas Cage. However, the fourth result, Finding Nemo, is irrelevant because of the parameter set to retrieve four results.
Hopefully, the code walkthrough has clarified the concept of self-querying on a vector database. On the LangChain website, LangChain describes self-querying as a method for an LLM to query itself using the underlying vector store. In other words, LangChain is developing a simple retrieval augmented generation (RAG) app in the CVP framework that includes a self-querying function.
In this tutorial, we’ve explored LangChain’s self-query feature using Milvus as the underlying vector store. Self-querying allows you to create a simple RAG app by combining an LLM and a vector database. The LLM breaks down the natural language query into a string, then vectorized for querying.
In our example, we generated some sample data related to movies. One way to expand on this example is to collect your data. When defining the self-query retriever, remember to provide the descriptions for both the vector store and the metadata.
To get started and experiment with LangChain’s self-query feature, refer to the colab notebook.
Querying the Vector Store with Logical Operation Statements
When querying the vector store, logical operation statements are used to specify conditions for filtering documents. A logical operation statement takes the form of op(statement1, statement2, …), where op is a logical operator such as AND, OR, or NOT. Each statement can be a comparison statement, which takes the form of comp(attr, val), where comp is a comparator such as EQ, LT, or GT, and attr and val are the attribute and value being compared, respectively.
For example, a logical operation statement might look like this: AND(EQ(language, “English”), GT(rating, 4)). This statement would filter documents that have a language attribute equal to “English” and a rating attribute greater than 4. By using logical operation statements, you can create complex queries that combine multiple conditions, allowing for more precise filtering of documents in the vector store.
Handling the User’s Query
When a user inputs a query, the self-query retriever uses a query constructor to generate a structured query. The structured query is then translated into vector store queries, which are executed on the vector store to retrieve relevant documents. The query constructor uses a prompt and output parser to generate the structured query, which captures the filters specified by the user.
For example, if a user inputs the query “Find movies with a rating greater than 4 and a runtime less than 2 hours”, the query constructor might generate a structured query like this: AND(GT(rating, 4), LT(runtime, 120)). This structured query would then be translated into vector store queries and executed on the vector store to retrieve relevant documents. By handling the user’s query in this way, the self-query retriever ensures that the results are tailored to the user’s specific requirements.
Best Practices and Conclusion
When using the self-query retriever, it’s important to follow best practices to ensure accurate and relevant results. Here are some tips:
Use specific and concise language when inputting queries.
Use logical operation statements to specify conditions for filtering documents.
Use comparison statements to compare attributes and values.
Use the EQ comparator to specify exact matches.
Use the LT and GT comparators to specify range queries.
Use the AND and OR logical operators to combine conditions.
In conclusion, the self-query retriever is a powerful tool for building conversational AI models that can retrieve and process information from various sources. By using logical operation statements and comparison statements, users can specify complex queries and retrieve relevant documents from a vector store. By following best practices and using the self-query retriever effectively, developers can build more accurate and relevant AI models that can handle a wide range of user queries.

Keep Reading

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

How to Build an Enterprise-Ready RAG Pipeline on AWS with Bedrock, Zilliz Cloud, and LangChain
Build production-ready enterprise RAG with AWS Bedrock, Nova models, Zilliz Cloud, and LangChain. Complete tutorial with deployable code.

VidTok: Rethinking Video Processing with Compact Tokenization
VidTok tokenizes videos to reduce redundancy while preserving spatial and temporal details for efficient processing.