




検索拡張世代(RAG)のためのチャンキング戦略ガイド
このガイドでは、RAG(Retrieval-Augmented Generation)システムにおけるチャンキング戦略の様々な側面を探った。
シリーズ全体を読む
- 検索拡張ジェネレーション(RAG)でAIアプリを構築する
- LLMの課題をマスターする:検索拡張世代の探求
- ディープラーニングにおける主要なNLPテクノロジー
- RAGアプリケーションの評価方法
- リランカーによるRAGの最適化:役割とトレードオフ
- マルチモーダル検索拡張世代(RAG)のフロンティアを探る
- ChatGPTをMilvusで強化する:長期記憶でAIを強化する
- RAGパイプラインのパフォーマンスを高める方法
- ChatGPTをMilvusで強化する:長期記憶でAIを強化する
- Pandas DataFrame:Milvusによるチャンキングとベクトル化
- Llama3、Ollama、DSPy、Milvusを使った検索支援生成(RAG)システムの作り方
- 検索拡張世代(RAG)のためのチャンキング戦略ガイド
- 仮説的文書埋め込み(HyDE)による情報検索とRAGの改善
- Milvus Lite、Llama3、LlamaIndexを使ったRAGの構築
- RA-DITによるRAGの強化:LLM幻覚を最小化する微調整アプローチ
Retrieval Augmented Generation(RAG)は、Natural Language Processing(NLP)における重要な革新として際立っており、膨大なデータベースからの関連情報の効率的な検索を統合することによって、テキスト生成を強化するように設計されている。パトリック・ルイスと彼のチームを含む研究者たちによって開発されたRAGは、事前に訓練された大規模な言語モデルのパワーと、ウィキペディアのような広範なソースからデータを取得し、その回答に反映させる検索システムを組み合わせたものである。
検索拡張世代(RAG)とは?
RAGは、生成ベースと検索ベースのNLPにおけるモデルの機能を融合したハイブリッド言語モデルである。このアプローチは、事前に訓練された言語モデルの限界に対処するもので、膨大な量の事実知識を記憶しているにもかかわらず、複雑で知識集約的なタスクのために、この情報に正確にアクセスし、操作する手助けを必要とすることが多い。RAGは、ウィキペディア(またはあなたのデータ)のようなデータソースの「密なベクトルインデックス」から関連情報をフェッチするために「ニューラル・リトリーバー」を使用することによってこれに取り組み、その後、モデルはより正確で文脈的に適切な応答を生成するために使用します。
NLPにおけるRAGの意義
RAGの開発は、特に意味的な意味と事実の正確さに関する深い知識を必要とするタスクにおいて、従来の言語モデルを大幅に改善した:
強化されたテキスト生成: **生成プロセス中に外部データを取り込むことで、RAGモデルは多様で具体的なテキストを生成するだけでなく、内部パラメータのみに依存する従来のseq2seqモデルと比較して、より事実に基づいた正確なテキストを生成する。
RAGは、オリジナルのRAG論文において、様々なNLPタスクについて微調整と評価を行い、特にオープンドメインの質問応答において優れています。RAGは新たなベンチマークを設定し、従来のseq2seqや、テキストから回答を抽出することのみに依存するタスク固有のモデルを凌駕しています。
質問回答だけでなく、RAGは、正確で事実に基づいた言語が重要なゲーム「Jeopardy」をモデルにしたシナリオのコンテンツ生成のような、他の複雑なタスクでも有望であることを示しています。この適応性により、NLPの様々な領域において強力なツールとなります。
さらなる詳細については、基礎概念とRAGの応用がLewisら(2020)の研究で徹底的に議論されており、彼らのNeurIPS論文やその他の出版物( Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, https://ar5iv.labs.arxiv.org/html/2005.11401 )から入手可能である。
チャンキング
「チャンキング"("llmチャンキング "と呼ばれることもある)とは、大きなテキストコーパスを管理しやすい小さな断片やセグメントに分割することである。各再帰的チャンキング部分は、個別に索引付けや検索が可能な独立した情報単位として機能する。例えば、Lewis et al. (2020)が説明したように、RAGモデルの開発では、ウィキペディアの記事を100単語のチャンクに分割し、検索データベースとなる合計約2100万件の文書を作成する。このチャンキング技術は、検索プロセスの効率と精度を高めるために極めて重要であり、その結果、以下のような様々な側面からRAGモデルの全体的な性能に影響を与える:
- 検索効率の向上:**テキストをより小さなチャンクに整理することで、RAGモデルの検索コンポーネントは、関連する情報をより迅速かつ正確に特定することができる。これは、小さなチャンクによって検索システムの計算負荷が軽減され、検索段階での応答時間が短縮されるためです。
- チャンキングは、RAGモデルが最も関連性の高い情報をより正確に特定することを可能にします。各チャンクは情報の凝縮された表現であるため、検索システムは与えられたクエリに対する各チャンクの関連性を評価しやすくなり、最も適切な情報を検索できる可能性が高まります。
- スケーラビリティと管理性:チャンキングにより、膨大なデータセットを扱うことがより現実的になる。各チャンクを個別にインデックス付けし、管理することができるため、システムはデータベースを効率的に管理・更新することができる。これは、正確で適切な出力を生成するために最新の情報に依存するRAGモデルにとって特に重要である。
- バランスの取れた情報分布:チャンキングは、情報がデータセットに均等に分布することを保証し、バランスの取れた検索プロセスを維持するのに役立つ。この均一な分布は、コーパスがチャンクされていない場合に検索結果を支配する可能性のある長い文書に検索モデルが偏るのを防ぐ。
RAGシステムにおけるチャンキング戦略の詳細探索
以下のチャンキング戦略のような高度なRAG](https://zilliz.com/blog/advanced-rag-apps-with-llamaindex)テクニックは、大きなテキストを処理し理解するRAGシステムの効率を最適化するために非常に重要です。ここでは、3つの主要なチャンキング戦略(固定サイズチャンキング、セマンティックチャンキング、ハイブリッドチャンキング)と、それらがRAGコンテキストでどのように効果的に適用されるかについて詳しく説明します。
1.固定サイズ・チャンキング: 固定サイズ・チャンキングでは、あらかじめ定義された文字数、単語数、トークン数に基づいて、テキストを均一の大きさに分割します。この方法は簡単であるため、迅速なデータ横断が必要とされる初期データ処理段階でよく使われる。
1.**この手法では、テキストを100単語ごとや500文字ごとなど、あらかじめ決められた大きさの塊に分割する。
2.**固定サイズのチャンキングの実装は、Pythonの基本的な文字列メソッドや、より構造化されたデータのためのNLTKやspaCyのような複雑なライブラリのような文字列操作を扱うプログラミングライブラリを使用して、簡単に行うことができます。例えば
def fixed_size_chunking(text, chunk_size=100):
return [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)].
1.**利点
1.実装がシンプルで予測可能なため、チャンクの管理とインデックス付けが容易。
2.高い計算効率と実装の容易さ。
2.**デメリット
1.重要な意味的境界が断ち切られ、脈絡のない情報が検索される可能性がある。
2.テキストの自然な構造に適応しないため、柔軟性に欠ける。
3.**この戦略は、詳細な意味理解がそれほど重要でない大規模データセットの予備分析時など、コンテキストの深さよりもスピードが重要なシナリオに最適である。
1.セマンティック・チャンキング: チャンキングは、意味のある内容単位に基づいてテキストをセグメント化し、センテンス、段落、テーマの区切りなどの自然言語の境界を尊重する。
1.戦略:* 固定サイズのチャンキングとは異なり、この方法は、段落、セクション、トピックなどのコンテンツの自然な区切りに基づいてテキストを分割します。
2.実装:spaCyやNLTK*のようなツールは、文末の句読点のようなテキスト内の自然な区切りを識別し、テキストを意味的に分割することができます。
3.**利点
1.各チャンク内の情報の整合性を維持し、チャンク内のすべてのコンテンツがコンテキストに関連していることを保証します。
2.検索されたデータの関連性と正確性を高め、生成されるレスポンスの品質に直接影響します。
4.**デメリット
1.テキストの構造と内容を理解する必要があるため、実装がより複雑になる。
5.**セマンティック・チャンキングは、文書の要約や法的文書分析のような内容に敏感なアプリケーションで特に有益である。
1.ハイブリッド・チャンキング: ハイブリッド・チャンキングは複数のチャンキング・メソッドを組み合わせ、固定サイズ・チャンキングとセマンティック・チャンキングの両方の利点を活用し、スピードと精度の両方を最適化します。
1.戦略:* 複数のチャンキング手法を組み合わせ、それぞれの利点を活用する。例えば、システムは最初のデータ処理に固定長チャンキングを使用し、より正確な検索が必要な場合にセマンティック・チャンキングに切り替えることができる。
2.実装:最初のパスでは、迅速なインデックス作成のために固定サイズのチャンキングを使い、検索段階では文脈の整合性を確保するためにセマンティック・チャンキングを使うかもしれない。意味解析のためのspaCyのようなツールを固定サイズのチャンキングのためのカスタムスクリプトと統合することで、様々なニーズに適応する強固なチャンキング戦略を作成することができる。
3.利点:*タスクの要件に基づいてチャンキング方法を適応させることで、速度と文脈の整合性のバランスをとる。
4.デメリット:*実装と維持にリソースがかかる。
5.**いつ使うか?
1.**顧客サービスのチャットボットでは、ハイブリッド・チャンキングによって、顧客からの問い合わせ関連情報を素早く取得することができる。
2.**ハイブリッド・チャンキングは、構造化された科学論文から非公式なインタビューまで、多様なデータタイプを扱う研究に使用され、詳細な分析と適切なデータ検索を保証します。
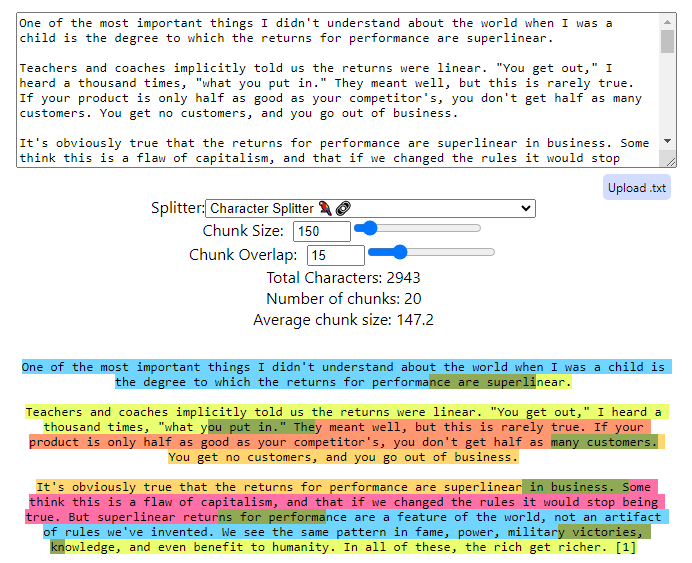 ChunkViz.pngを使ったチャンキングの例です
ChunkViz.pngを使ったチャンキングの例です
ChunkVizを使ったチャンキングの例です(https://chunkviz.up.railway.app/)
この例では、チャンクサイズとは、テキスト処理中に1つの単位または「チャンク」を構成するテキストの量(文字、1文、単語、または文のまったく同じサイズで測定)を指します。チャンクサイズの選択は、テキスト分析、ベクトル化、またはRAGのようなシステムなどのタスクにおいて、一度に処理される情報量を決定するため、非常に重要です。
より小さなチャンクサイズ:** 細かい分析に集中する場合や、テキストの詳細な側面が重要な場合に、一般的に使用されます。例えば、特定のフレーズやセンテンスを理解することが重要なセンチメント分析では、より小さなチャンクが使用されるかもしれません。
文書の要約やトピックの検出など、より広い文脈を把握したり、異なるテキスト部分間の相互作用が重要な場合に適しています。より大きなチャンクは、より細かいチャンキングで修正する必要があるような、テキストの物語的な流れやテーマ的な要素を保持するのに役立ちます。
チャンクサイズの選択は、メモリの計算効率と文脈の正確さの必要性のバランスに依存することが多い。小さいチャンクのメモリは高速に処理できるが、文脈が欠落する可能性がある。一方、大きいチャンクはより多くの文脈を提供するが、処理にかかる計算が重くなる可能性がある。
チャンクのオーバーラップにより、チャンクは隣接するチャンクと標準的なテキストを共有することができる。この技術により、チャンク間の境界で重要な情報が失われることがなくなります。特に、より意味のある2つのチャンク間の切断点が、重要な意味構造や構文構造を分割してしまう可能性がある場合に有効です。
- オーバーラップの役割:** オーバーラップはチャンク間の移行をスムーズにし、コンテキストの連続性を確保します。例えば、あるチャンクの最後で文が切れている場合、次のチャンクをその文の終わりから始めることで、連続性とコンテクストを提供することができます。
チャンクオーバーラップを使うことで、コンテキストロスのリスクを減らし、NLPアプリケーションの出力における意味検索の一貫性を向上させることで、分析の質を大幅に高めることができる。しかし、より多くのテキストが複数回処理されるため、計算と認知の負荷も増加し、このトレードオフはタスクの特定の要件に基づいて管理する必要があります。
RAGシステムでは、チャンキング戦略の選択が、検索プロセスの有効性、ひいては生成されるアウトプットの品質に大きな影響を与える可能性がある。固定サイズ、セマンティック、ハイブリッドのいずれのチャンキングであっても、チャンキングと呼ばれる目的は、効率的で正確な自然言語生成をサポートするために、情報がどのようにセグメント化され、インデックス化され、検索されるかを最適化することにある。チャンキングの戦略的な実装は、パフォーマンスの高いシステムと、待ち時間や関連性に苦労するシステムの違いとなり、高度な自然言語処理ソリューションのアーキテクチャにおける重要な役割を浮き彫りにします。
テキスト検索におけるチャンキングとベクトル化
チャンキングはテキスト検索システムにおけるベクトル化の効果に大きく影響します。適切なチャンキングは、テキストベクターが必要な意味情報をカプセル化することを保証し、検索精度と効率を向上させる。例えば、個々の文や段落を考慮するなど、テキストの自然な構造に沿ったチャンキング戦略は、ベクトル形式に変換されたときに情報の整合性を維持するのに役立ちます。この構造化されたアプローチにより、生成されたベクトルが実際のコンテンツの関連性を反映することが保証され、RAGのようなシステムにおいてより正確な検索が容易になる。
効率的なベクトル化のためのツールと技術
テキストの効果的なベクトル化は、使用するツールと埋め込みモデルに大きく依存します。一般的なモデルには、単語レベルの埋め込みに Word2Vec や GloVe があり、BERT や GPT は文や段落レベルの機能を提供し、より大きなテキストの塊に対応します。これらのモデルは、テキスト内の微妙な意味関係を捉えることに長けており、高度なテキスト検索システムに非常に適している。埋め込みモデルの選択は、性能を最適化するために、チャンキング戦略の粒度と一致させるべきである。例えば、センテントランスフォーマーは、センテンスレベルの情報を効率的に扱い処理するように設計されているため、チャンキングのセマンティックコンテキストで使用すると特に効果的である。
チャンキング戦略とベクトル化の連携による最適なパフォーマンス**。
チャンキング戦略とベクトル化の整合性には、いくつかの重要な考慮事項があります:
チャンクサイズとモデルの容量:** チャンクサイズとベクトル化モデルの容量を一致させることが重要です。短いテキストに最適化された BERT のようなモデルは、効果的に動作させるために、より小さく簡潔なチャンクが必要になる場合があります。
チャンクの内容に一貫性を持たせ、重複するチャンクを利用することで、チャンク間のコンテキストを維持し、境界で重要な情報が失われるリスクを減らすことができます。
反復的な改良: **システム性能のフィードバックに基づき、チャンキングとベクトル化アプローチを継続的に改良 することが不可欠です。これには、システムの検索精度と応答時間に基づいて、チャンクサイズやベクトル化モデルを調整することが含まれます。
RAG パイプラインにおけるチャンキングの実装
効果的なRAGシステムにチャンキングを実装するには、チャンキングがリトリーバやジェネレータなどの他のコンポーネントとどのように相互作用するかを理解する必要があります。この相互作用は、RAGシステムにおけるチャンキングの効率と精度を高める上で極めて重要です。
チャンキングとレトリーバ:レトリーバの機能は、ユーザークエリに基づいて、最も関連性の高いテキストのチャンクを特定し、フェッチすることです。効果的なチャンキング戦略は、膨大なデータセットを管理しやすいまとまりのある断片に分解し、簡単にインデックスを付けて検索できるようにする。例えば、単なるトークンの大きさではなく、タイトルやセクションのような文書要素によってチャンキングすることで、文脈に関連した情報を引き出す検索能力を大幅に向上させることができる。この方法は、各チャンクが完全で独立した情報をカプセル化することを保証し、より正確な検索を容易にし、無関係な情報の検索を減らします。
チャンキングとジェネレーター:** ジェネレーターは、関連するチャンクが検索されると、この情報を使ってレスポンスを作成します。チャンキングの質と粒度はジェネレーターの出力に直接影響します。明確に定義されたチャンクは、ジェネレーターが必要なコンテキ ストをすべて持っていることを保証します。チャンクの粒度が大きすぎたり、定義が不十分な場合、コンテキストから外れたり、連続性に欠ける応答が返される可能性があります。
チャンキング戦略を構築しテストするためのツールとテクノロジー
いくつかのツールとプラットフォームは、RAGシステム内でのチャンキング戦略の開発とテストを容易にします:
LangChainとLlamaIndex:** これらのツールは、チャンク間のコンテキストの連続性を維持するために重要な動的チャンクサイジングとオーバーラッピングを含む、様々なチャンキング戦略を提供します。これらのツールは、アプリケーションの特定のニーズに基づいてチャンクサイズとオーバーラップをカスタマイズすることができ、RAGシステムにおける検索と生成の両方のプロセスを最適化するために調整することができる。
Unstructuredによる前処理パイプラインAPI:**これらのパイプラインは、文書要素によるチャンキングのような洗練された文書理解技術を採用することにより、RAGのパフォーマンスを向上させます。この方法は、検索と生成のために関連するデータのみが考慮されることを保証し、RAGシステムの精度と効率の両方を向上させるため、様々な構造を持つ複雑なドキュメントタイプに特に効果的です。
Zilliz Cloud**:Zilliz Cloudにはパイプラインと呼ばれる機能があり、非構造化データをベクトル埋め込みデータに変換し、Zilliz Cloudのベクトルデータベースに格納することで、効率的なインデックス作成と検索を実現します。含まれるsplitterを選択またはカスタマイズできる機能があります。デフォルトでは、Zilliz Cloud Pipelinesは"˶", "˶", ", ""をセパレータとして使用します。また、文(セパレータとして"."、""を使用)、段落(セパレータとして"˶n"、""を使用)、行(セパレータとして"˶n"、""を使用)、またはカスタマイズした文字列のリストで文書を分割することもできます。
これらのツールをRAGパイプラインに組み込むことで、開発者は異なるチャンキング戦略を実験し、システム性能への影響を直接観察することができる。この実験により、情報の検索と処理方法を大幅に改善し、最終的にRAGシステムの全体的な有効性を高めることができる。
チャンキング戦略によるRAGシステムのパフォーマンス最適化
RAGシステムの最適化には、さまざまなチャンキング戦略がパフォーマンスにどのような影響を与えるかを注意深く監視し、評価することが含まれる。この最適化により、システムが関連情報を迅速に検索するだけでなく、情報を処理する際に首尾一貫した文脈に適した応答を生成することが保証される。
さまざまなチャンキング戦略の影響のモニタリングと評価
1.**チャンキング戦略を変更する前に、基本的なパフォーマンス指標を確立することが重要です。これには、応答時間、情報検索の精度、生成されたテキストの一貫性などの測定基準が含まれる。
1.実験:異なるチャンキング戦略(固定サイズ、セマンティック、ダイナミックチャンキングなど)を実施し、それぞれがパフォーマンスにどのような影響を与えるかを測定します。この実験段階は、チャンキングの効果を他の変数から切り離すために、コントロールされ、体系的であるべきである。
1.継続的なモニタリング:* ロギングとモニタリングツールを使って、時間をかけてパフォーマンスを追跡する。この継続的なデータ収集は、長期的な傾向や、様々な運用条件下での改善の安定性を理解するために不可欠である。
チャンキングの効果を評価するための指標とツール
指標:*
これらの測定基準は、RAGシステムによって検索された情報の正確さと完全性を評価するために重要である。
応答時間: **検索プロセスの効率を示す、問い合わせを受けてから回答を提供するまでにかかる時間を測定します。
チャンクされた入力に基づいて生成されたテキストの論理的な流れと関連性は、生成タスクにおけるチャンキングの有効性を評価する上で非常に重要です。
**ツール
分析ダッシュボード:GrafanaやKibana*のようなツールは、リアルタイムでパフォーマンスメトリックスを視覚化するために統合することができます。
プロファイリング・ソフトウェア: ProfilerやTensorBoardのような機械学習ワークフローに特化したプロファイリング・ツールは、チャンキングの段階でボトルネックを特定するのに役立ちます。
パフォーマンスデータに基づくチャンキングパラメータのチューニングと改良のための戦略
1.データ駆動型調整:* 収集したパフォーマンスデータを使用して、どのチャンキング・パラメーター(例:サ イズ、オーバーラップ)を調整するかを決定する。例えば、チャンクが大きいとシステムの動作が遅くなるが、精度は向上する場合、両方の側面を最適化するバランスを見つける必要がある。
1.A/Bテスト:異なるチャンキング戦略を使ってA/Bテストを実施し、システムパフォーマンスへの影響を直接比較する。このアプローチにより、横並びでの比較が可能になり、より確実な意思決定ができるようになります。
1.フィードバックループ: RAGのアウトプットがユーザーによって、または自動化されたシステムによって評価され、生成されたコンテンツの品質に関する継続的なフィードバックを提供するフィードバックシステムを実装します。このフィードバックは、チャンキングパラメータを動的に微調整するために使用することができる。
1.機械学習による最適化アルゴリズム:強化学習や遺伝的アルゴリズムなどの機械学習技術を利用し、パフォーマンス指標に基づいた最適なチャンキング構成を自動的に見つける。
RAGシステムのチャンキング戦略を注意深く監視、評価し、継続的に改良することで、開発者はシステムの効率と効果を大幅に向上させることができます。
革新的なチャンキング戦略によるRAG実装の成功事例
ケーススタディ1 - 動的な窓付き要約:*** RAGの実装で成功した一例として、窓付き要約と呼ばれる付加的な前処理技法がある。このアプローチは、より広いコンテキストを提供するために、隣接するチャンクの要約でテキストチャンクを強化する。この手法により、システムは「ウィンドウの大きさ」を動的に調整することができ、コンテキストの異なる範囲を探索することで、各チャンクの理解を深めることができた。コンテキストが強化されたことで、より適切でコンテキストに沿ったニュアンスの回答ができるようになり、回答の質が向上した。このケースは、RAGセットアップにおけるコンテキストを強化したチャンキングの利点を強調したものであり、検索コンポーネントは、回答の品質と関連性を高めるために、より広範なコンテキストの手がかりを活用することができる(Optimizing Retrieval-Augmented Generation with Advanced Chunking Techniques:比較研究)。
ケーススタディ2 - 高度なセマンティックチャンキング:** 高度なセマンティックチャンキング:成功したRAG実装のもう一つの成功例は、検索パフォーマンスを向上させるための高度なセマンティック・チャンキング技術を含んでいる。単にサイズやトークン数に基づくのではなく、文書を意味的に首尾一貫したチャンクに分割することで、システムは関連情報を検索する能力を大幅に向上させた。この戦略により、各チャンクは文脈の整合性を維持し、より正確で首尾一貫した生成出力が得られるようになった。このようなチャンキング技術を実装するには、コンテンツの構造と、RAGシステムに関わる検索と生成プロセスの特定の要求の両方を深く理解する必要があった(Mastering RAG: Advanced Chunking Techniques for LLM Applications )。
結論RAGシステムにおけるチャンキングの戦略的意義
ここまで、RAG(Retrieval-Augmented Generation)システムにおけるチャンキング戦略の様々な側面を探ってきた。チャンキングプロセスの基本を理解することから、RAGシステムのパフォーマンスにおいてチャンキングが果たす役割に重点を置きながら、高度なテクニックや実際のアプリケーションに飛び込んでいきます。
要点のまとめ
チャンキングとは、大規模なテキストデータセットを管理しやすい断片に分割することで、情報検索やテキスト生成プロセスの効率を向上させることである。
チャンキング戦略: **固定サイズ、セマンティック、ダイナミックチャンキングなど様々なチャンキング戦略を、ユースケース、利点、最適な使用シナリオ、欠点に基づいて実装することができます。
異なるチャンキングアプローチがシステム全体のパフォーマンスに影響を与える可能性があるため、チャンキングとリトリーバーやジェネレーターのような他のRAGコンポーネントとの相互作用を評価する必要があります。
チャンキング戦略の有効性を監視・評価するために使用できるツールや指標は、継続的な最適化の取り組みに不可欠です。
現実世界のケーススタディ: **革新的なチャンキング戦略がRAGシステムの大幅な改善にどのようにつながるかを、成功した導入事例から説明します。
適切なチャンキング戦略を選択するための最終的な考え方**
RAG システムの機能性と効率を高めるには、適切な高度 RAG テクニックを選択することが最も重要です。適切なチャンキング戦略は、システムが最も関連性の高い情報を検索するだけでなく、関連する文書に対して首尾一貫した文脈の豊かな応答を生成することを保証する。うまく実装されたチャンキング戦略がRAGのパフォーマンスに与える影響は、情報検索の精度とコンテンツ生成の質に影響を与える。
RAGとチャンキングに関する参考文献とリソース
基礎的な理解のためには、LewisらによるRAGの原著論文は不可欠である。この論文は、知識集約的なNLPタスクにおけるRAGのメカニズムや応用について深い説明を提供している。
Galileoの "Mastering RAG: Advanced Chunking Techniques for LLM Applications "では、様々なチャンキング戦略とRAGシステムのパフォーマンスへの影響について深く掘り下げており、検索と生成プロセスを強化するためのLLMsの統合に重点を置いている。
Stack Overflow、Reddit (r/MachineLearning)、Towards AIにあるようなAIやNLPのコミュニティに参加することで、継続的なサポートやディスカッションフォーラムを提供することができる。これらのプラットフォームでは、実務者がRAGやチャンキングメソッドに関する洞察を共有し、質問し、解決策を見つけることができる。

読み続けて

ディープラーニングにおける主要なNLPテクノロジー
ディープラーニングにおける主要な自然言語処理(NLP)技術の根底にある進化と基本原理を探る。

Pandas DataFrame:Milvusによるチャンキングとベクトル化
チャンクテキストとエンベッディングを含むすべてのデータをPandas DataFrameに格納すれば、Milvusベクトルデータベースに簡単に統合してインポートできる。
Llama3、Ollama、DSPy、Milvusを使った検索支援生成(RAG)システムの作り方
この記事では、4つの主要技術を使ったRAGシステムの構築を読者に案内することを目的としている:Llama3、Ollama、DSPy、Milvusである。まず、これらが何であるかを理解しよう。